By Adrien Payong and Shaoni Mukherjee

Large language model inference isn’t just about running a model. It’s also about scheduling work on that model. When users send prompts to an LLM app, the inference server must choose which requests run on the GPU, which ones should keep generating tokens, how much KV cache memory to allocate, and how to balance raw throughput with user-facing latency.
This is where batching becomes important. Batching is the process of allowing the inference server to handle multiple requests concurrently rather than running them independently. Batched inference is simple in traditional machine learning: collect several inputs, run them through the model, and return the outputs. Batching for LLM inference is more complex because each request has two phases: The prefill phase processes the input prompt and creates the initial KV cache. The decode phase generates output tokens step by step.
LLM requests can have widely varying prompt lengths, output lengths, and arrival times. This means the way requests are batched has a large impact on performance. The two important approaches are static batching and continuous batching.
In this article, we examine why batching matters, compare static and continuous batching, explain prefill/decode and iteration‑level scheduling, detail how vLLM and TGI implement continuous batching, and discuss practical implications and scenarios for both techniques.
Key Takeaways
- LLM inference performance is a scheduling problem, not only a model execution problem. The server must decide how to allocate GPU work, KV cache memory, prefill tasks, and decode steps under real traffic.
- Static batching is simple but inefficient for variable-length LLM workloads. It waits for the slowest request in the batch, causing idle GPU slots, head-of-line blocking, higher TTFT, and wasted compute.
- Continuous batching improves throughput by updating the active batch at each generation step. When one request finishes, another waiting request can enter the batch, keeping the GPU better utilized.
- vLLM improves continuous batching with PagedAttention and KV cache-aware scheduling. PagedAttention reduces KV cache fragmentation, while iteration-level scheduling helps vLLM admit new requests as resources become available.
- TGI remains useful, but vLLM is often the stronger choice for new high-throughput deployments. TGI supports continuous batching and production serving features, but Hugging Face now recommends alternatives such as vLLM or SGLang for future deployments.
Why Batching Matters in LLM Inference
GPUs are designed for highly parallelized matrix operations. So dispatching requests together enables better utilization. Without batching, each request would pull the model’s weights, perform all its matrix multiplies and attention operations, and release the GPU promptly. This will cause significant under‑utilization. By batching requests together, the server can reuse the same loaded weights for multiple requests, amortizing memory bandwidth and compute overhead.
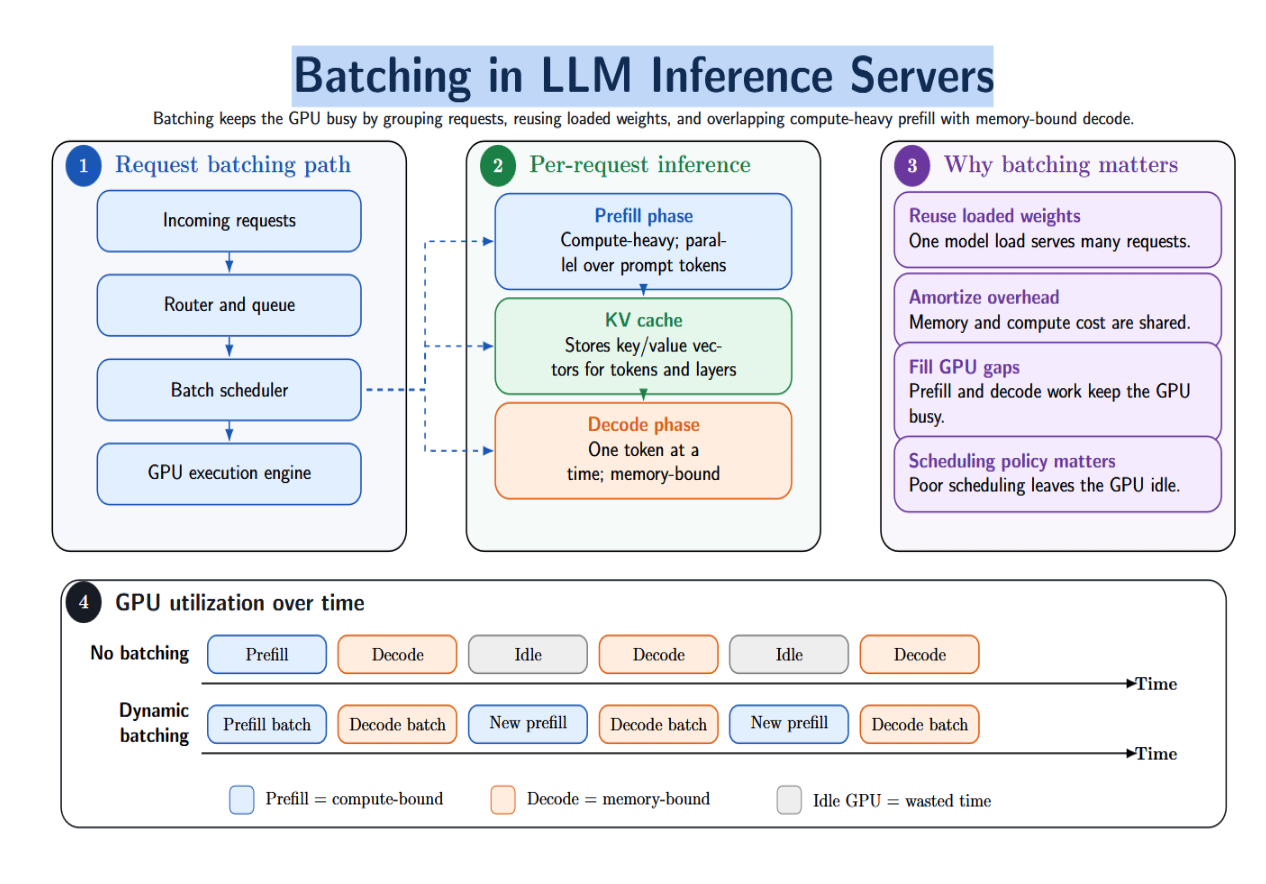
LLM inference isn’t batch matrix multiplication like image classification. Each incoming request consists of a prefill phase (which is compute‑heavy and highly parallelizable) and a decode phase (which is sequential and memory‑bound). During prefill, the model looks at every token in the prompt simultaneously and prepares the KV cache. The KV cache stores key and value vectors for each position in each layer.
During decoding, the model generates one token at a time conditioned on previously generated tokens and the KV cache. Prefill is compute‑bound, so parallelizing many tokens simultaneously allows high GPU utilization. Decode, however, is memory‑bound and shows lower GPU utilization. Batching helps overlap the gaps between prefill and decode: prefill ops can be batched together, and multiple decodes can execute in parallel. But the batch scheduling policy will determine if the GPU sits around idle while long sequences finish decoding.
What Is Static Batching?
Static batching is the process where multiple requests are batched together, prefilled, and decoded. They are then queued together and must wait for every request in the batch to complete before the next batch can start.
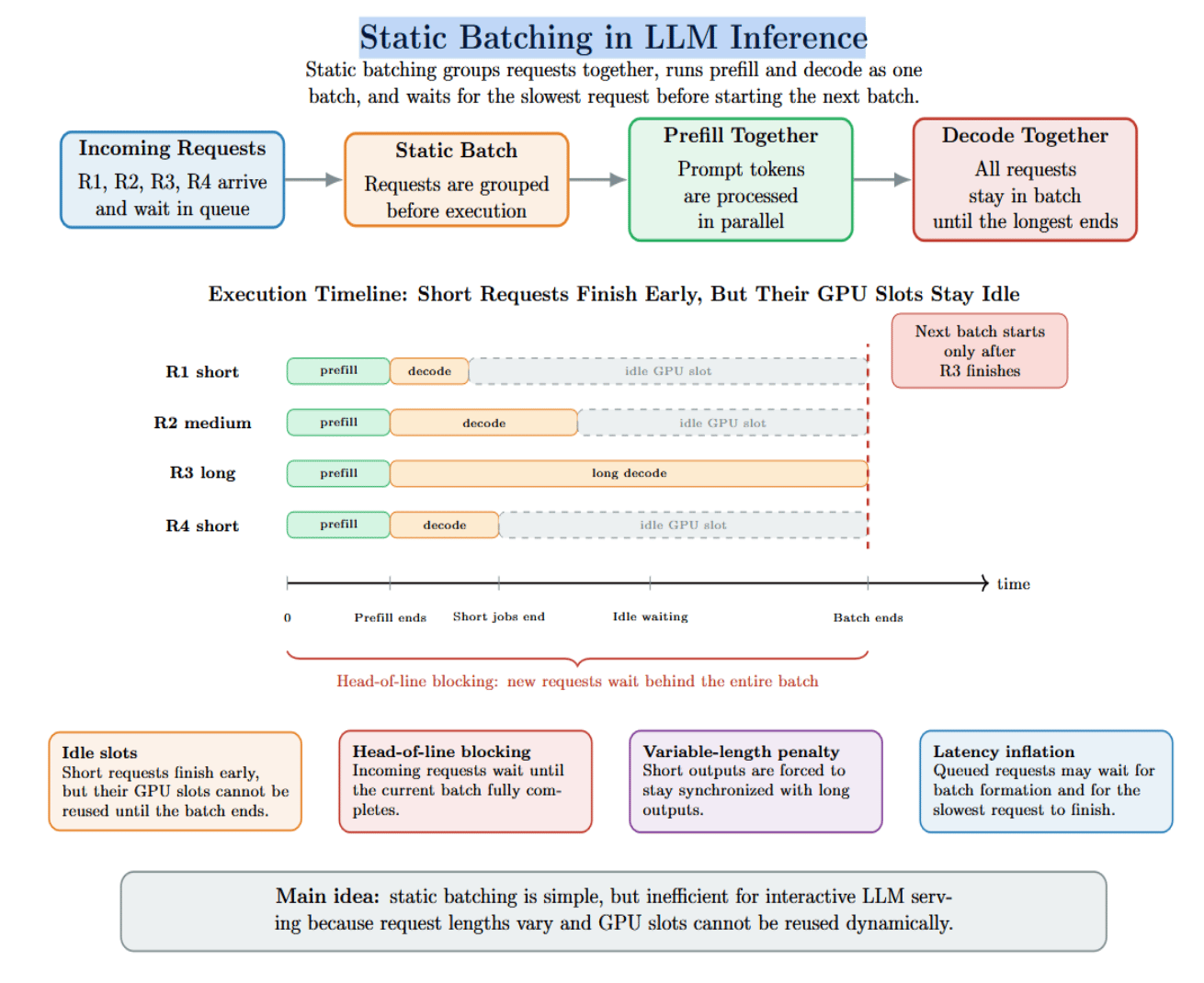
Think of static batching like a bus that won’t leave until everyone on it has reached their destination. This sounds simple enough, but it has some inefficiencies:
- Idle slots: When some requests complete early, their GPU slots remain idle until the slowest request finishes.
- Head‑of‑line blocking: Incoming requests must wait until the entire batch completes. This adds to the queueing delay.
- Variable‑length output penalty: Because LLM outputs are variable in length, static batching causes shorter requests to be stuck waiting for longer ones. This results in wasted compute cycles.
- Latency inflation: Static batching can increase TTFT for requests in the queue because the batching process forces each batch to wait until it is full before starting, and then to wait until the request taking the longest to complete finishes.
What Is Continuous Batching?
Continuous batching is achieved through iteration-level scheduling. Rather than locking a static batch until it completes generation, the server updates the current active batch on each generation step. As soon as a request has finished computing its final token, it is ejected from the active batch and replaced by one of the requests waiting in the queue.
The key benefits of continuous batching are:
- Higher GPU utilization: Empty slots left by completed sequences are immediately replaced, keeping the GPU busy.
- Lower queueing delay: New requests don’t have to wait for the entire batch to complete before entering the pipeline. Instead, they can queue up whenever slots become available.
- Better throughput: Thanks to reduced idle time, continuous batching can deliver 2–4× higher throughput than static batching in high‑concurrency workloads.
- Improved latency distribution: Long sequences no longer block short ones, tightening the p95/p99 latency tail.
Recent releases of Hugging Face Transformers include documents for ContinuousBatchingManager and generate__batch for continuous batching. Leading inference frameworks like vLLM, SGLang, TensorRT‑LLM, and LMDeploy provide continuous or in‑flight batching built in.
Static vs. Continuous Batching: Core Difference
The distinction between static and continuous batching can be summarized along several dimensions. The table below provides a concise comparison.
| Factor | Static batching | Continuous batching |
|---|---|---|
| Scheduling unit | Fixed batch | Token iteration |
| Request admission | After the batch ends | When the slot opens |
| Batch behavior | Fixed until completion | Updated continuously |
| Blocking risk | High | Low |
| GPU utilization | Often underused | Better saturated |
| TTFT | Higher under queues | Usually lower |
| Throughput | Limited by the slowest request | Higher with mixed lengths |
| Latency profile | Wider tail latency | Smoother tail latency |
| Best fit | Offline, uniform jobs | Online, variable traffic |
| Typical use case | Batch evaluation | Chatbots, APIs, agents |
Prefill and Decode: The Two Phases Behind LLM Scheduling
To appreciate continuous batching, let’s review two phases of LLM inference. Large language model inference consists of two phases: prefill and decode. Prefilling ingests the entire prompt in a single forward pass. During prefill, the model computes attention weights and feed-forward operations for all tokens in parallel. Prefill is compute‑bound and has high GPU utilization. The results of prefill are stored in the KV cache that stores key and value tensors for each layer and token.
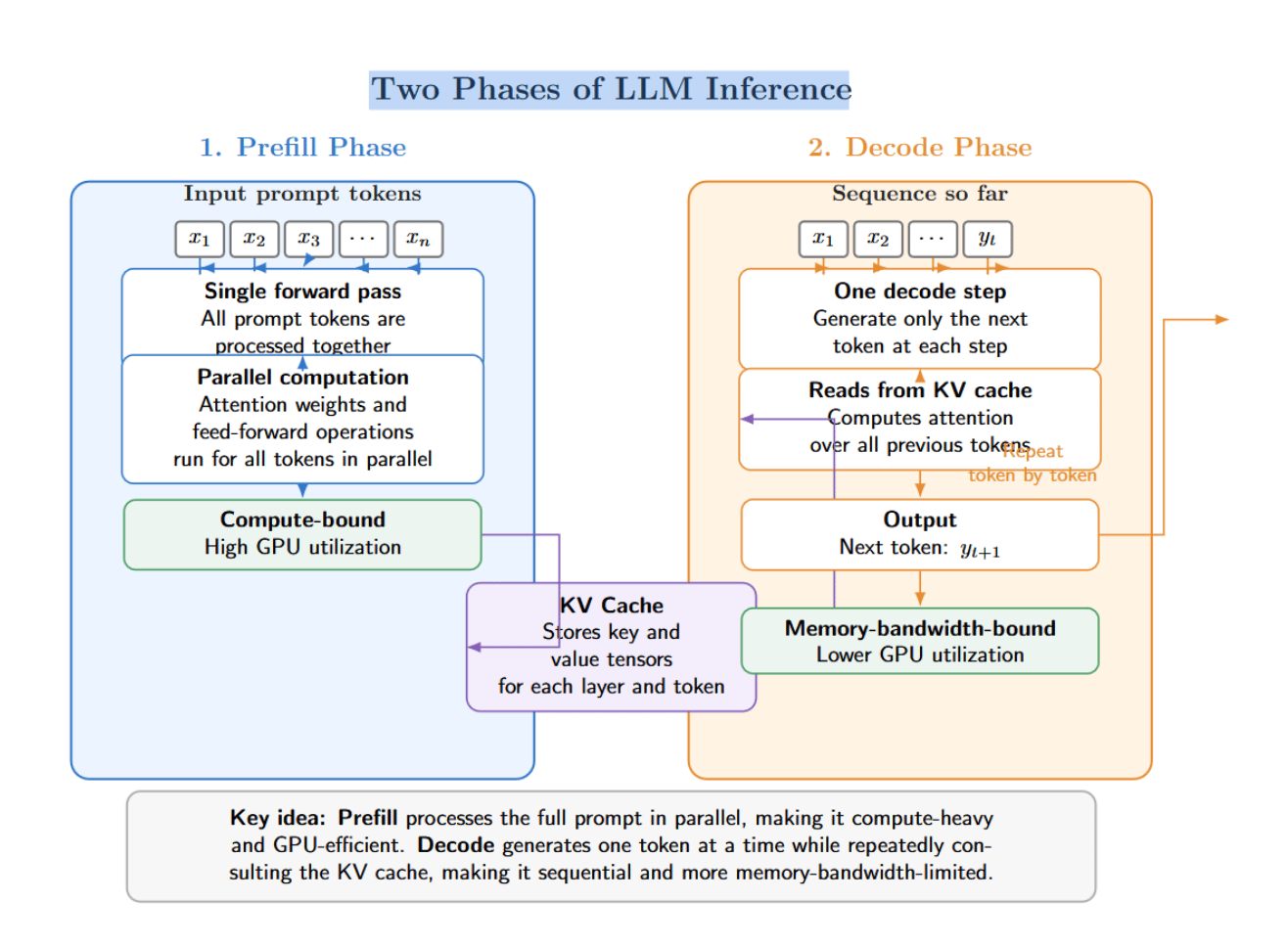
The decode phase generates one token at a time. Each step of decode reads from the KV cache to compute attention over all previously generated tokens, then outputs the next token. Because decode is inherently sequential and memory‑bandwidth‑bound, it has significantly lower GPU utilization.
Prefill is expensive, but it occurs once per request. As a result, several optimization strategies focus on reducing the cost of prefill, or amortizing it across requests. Prefix caching and chunked prefill are two examples. Prefix caching eliminates redundant work by reusing prefill results between shared system prompts and few‑shot examples. Chunked prefill breaks up large prefill operations into smaller, independently executable chunks that can be interleaved with decode.
What Is Iteration‑Level Scheduling?
Iteration‑level scheduling is how continuous batching is achieved. Rather than constructing a static batch and running until completion, the scheduler makes decisions at each forward pass. Our scheduler maintains three queues: waiting (requests that have not started prefill), running (requests that are currently decoding), and swapped (requests whose KV blocks have been evicted to host memory).
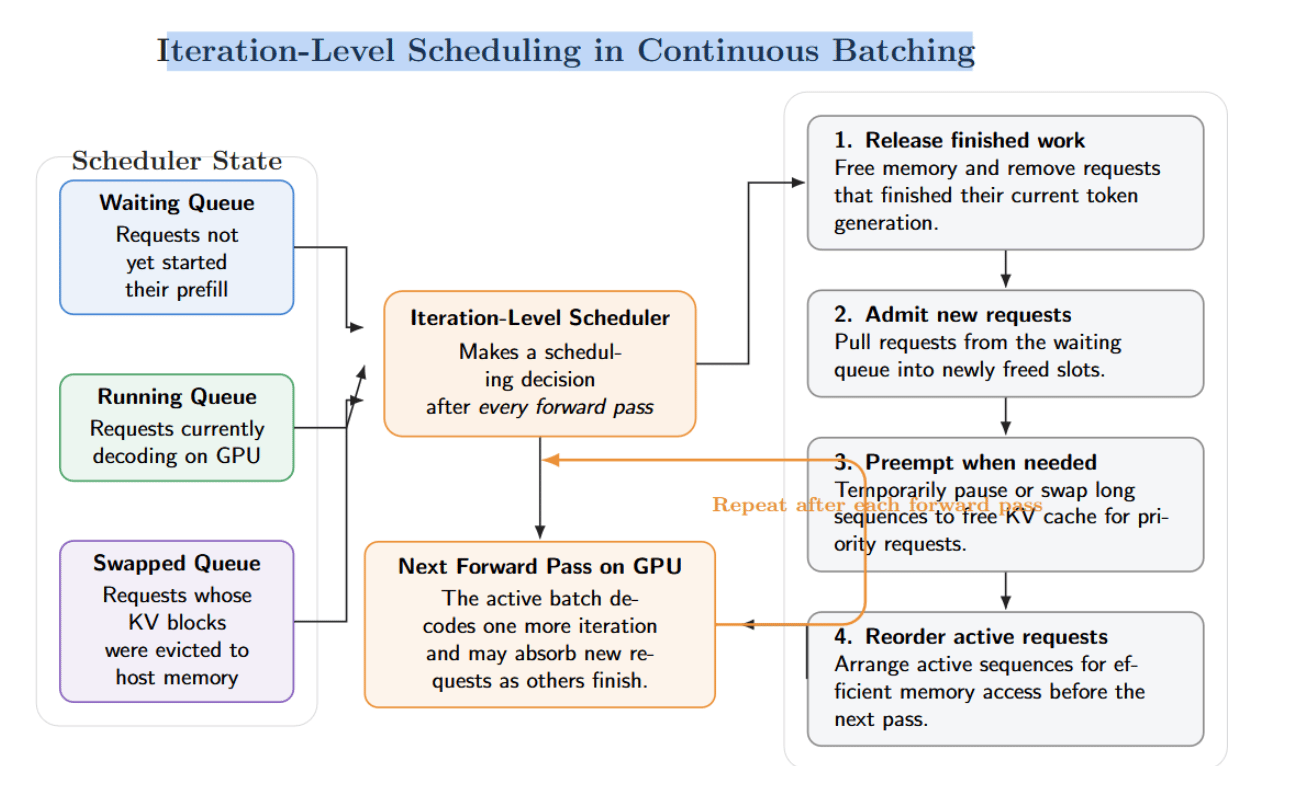
After each forward pass, the scheduler will:
- Releases memory and removes requests that have finished their current token generation.
- Admits new requests from the waiting queue into freed slots.
- Potentially preempt long sequences to free up KV cache for priority requests.
- Reorders active requests for optimal memory access before the next forward pass.
Iteration-level scheduling allows fine‑grained control over what’s running on the GPU. This keeps GPU occupancy high and avoids longer sequences blocking the completion of shorter ones. In the vLLM/PagedAttention paper, vLLM improved serving throughput by 2–4× at similar latency compared with earlier serving systems such as FasterTransformer and Orca.
How vLLM Handles Continuous Batching
vLLM is an open‑source inference engine. It combines continuous batching and efficient memory management, allowing for high throughput with low latency. There are two failure modes in naive LLM serving: KV cache fragmentation and static batching. Standard implementations reserve a contiguous memory block per request equal to the maximum sequence length. This implies that 60–80% of the reserved KV cache memory could be wasted in that condition. Static batching also leaves the GPU idle while short sequences wait for the longest batch to finish processing.
vLLM addresses these issues with PagedAttention and continuous batching. PagedAttention implements the KV cache as virtual memory: keys/values are stored in non‑contiguous physical pages (16 tokens each by default per block), which a page table maps a sequence’s logical KV cache onto.
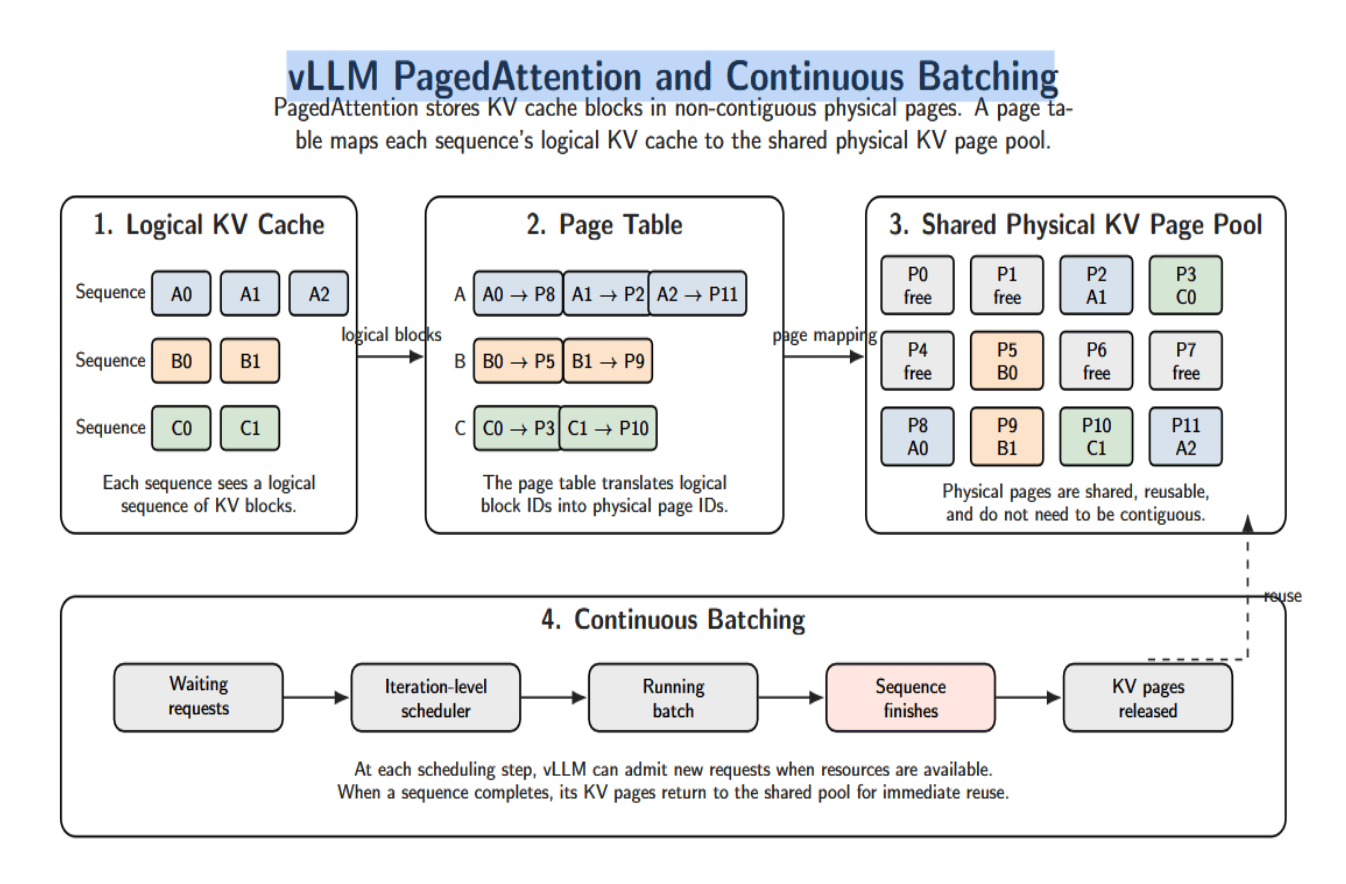
This approach removes internal and external fragmentation and enables us to share a single KV cache pool across many sequences. When a sequence completes, its blocks are released back into the pool for immediate reuse.
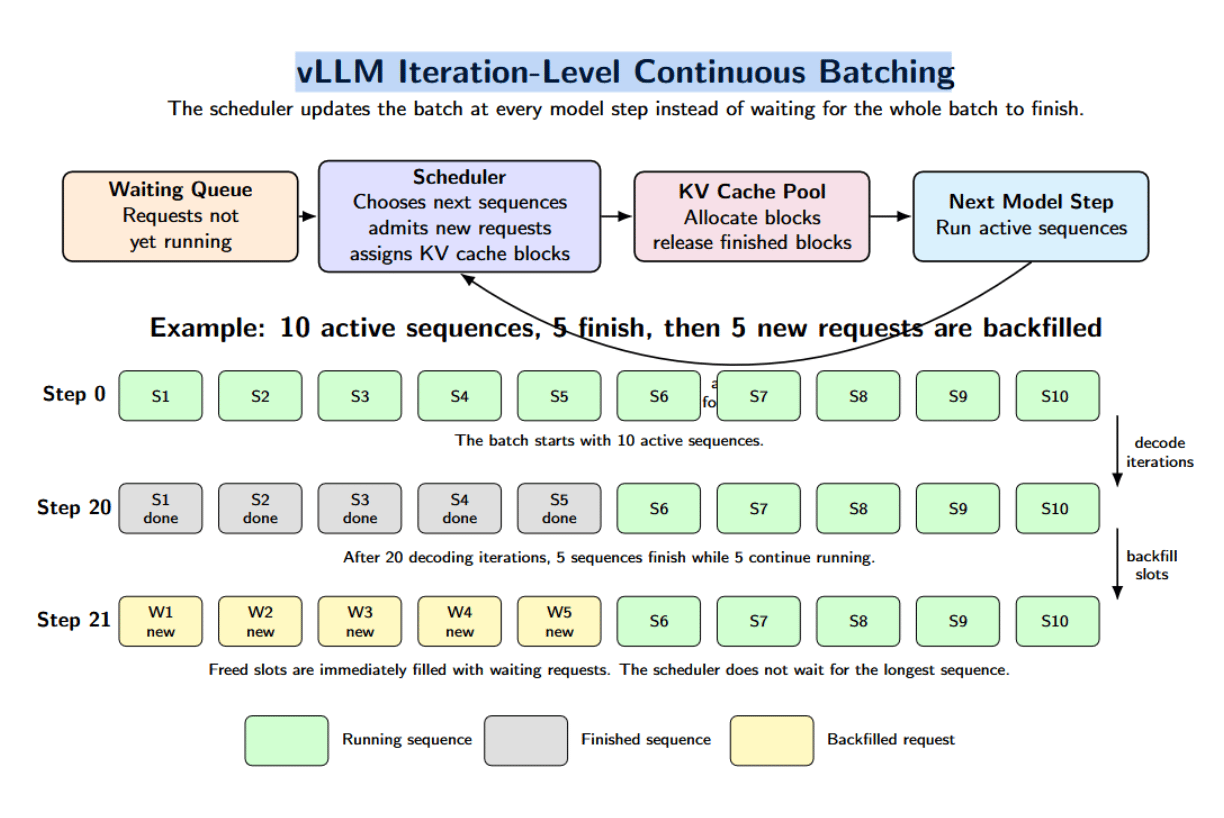
On the scheduling side, vLLM uses iteration-level continuous batching. The scheduler does not wait for an entire batch to finish. Instead, it iteratively determines which requests to run in the next model step, admits requests when resources are available, and determines KV cache allocation for sequences currently being processed.
For instance, we may begin a batch with 10 sequences, but only 5 of them finish after 20 decoding iterations. Instead of waiting for the longest sequence to complete, we can backfill those slots with waiting requests in the next scheduling step. Additional optimizations in vLLM’s optimization stack include PagedAttention, continuous batching, chunked prefill, prefix caching, speculative decoding, quantization, and CUDA graphs.
How TGI Handles Continuous Batching
Hugging Face Text Generation Inference has also been used extensively for production LLM serving. TGI supports continuous batching, streaming, tensor parallelism, quantization, and other production-ready serving features.
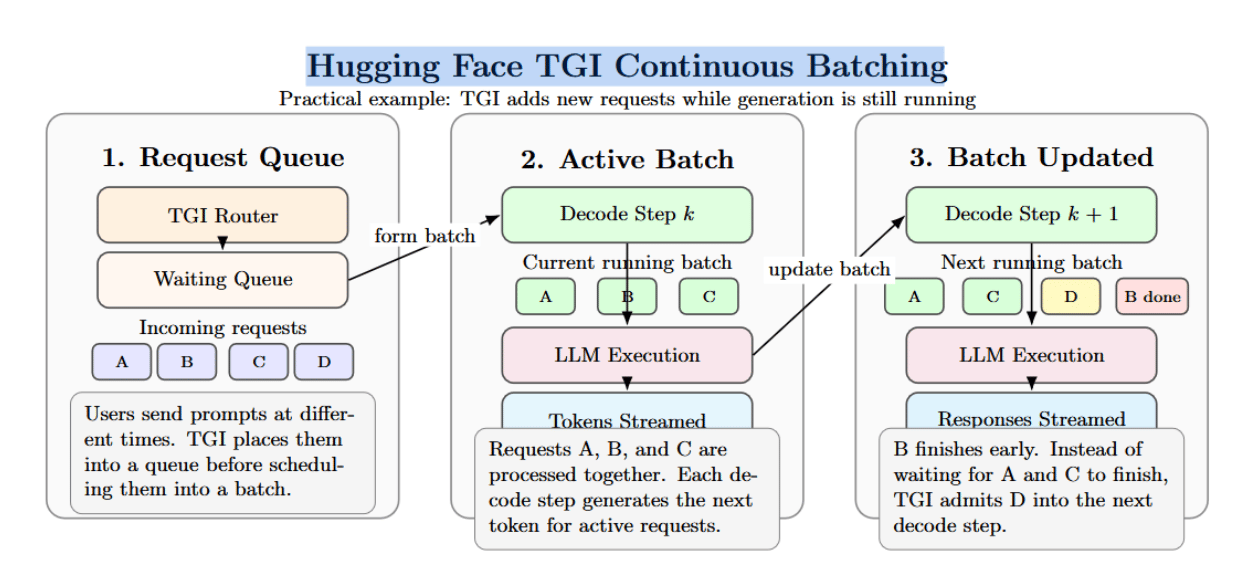
Incoming requests are routed into a queue, where they are dynamically grouped into batches for efficient processing. This helps avoid memory-related failures. TGI uses a continuous batching algorithm that can dynamically add requests to a running batch to maximize performance.
Hugging Face updated their docs to say TGI is in maintenance mode. They suggest using inference engine options such as vLLM or SGLang for Inference Endpoints. If you currently have a running deployment with TGI, that doesn’t suddenly make it useless. It still can be important for current deployments. However, if you’re planning a new high-throughput serving deployment, your team may want to explore whether vLLM or SGLang provides a more future-proof path.
Throughput Implications
Throughput refers to the amount of useful work completed by the inference server per unit time. For LLM serving, this may be measured in tokens processed per second, requests per second, or generations completed per second.
Static batching can limit throughput because the server is forced to wait for the slowest request in each batch. As shorter requests are completed, their batch slots may become inactive. The GPU may still run the batch, but the amount of useful work decreases.
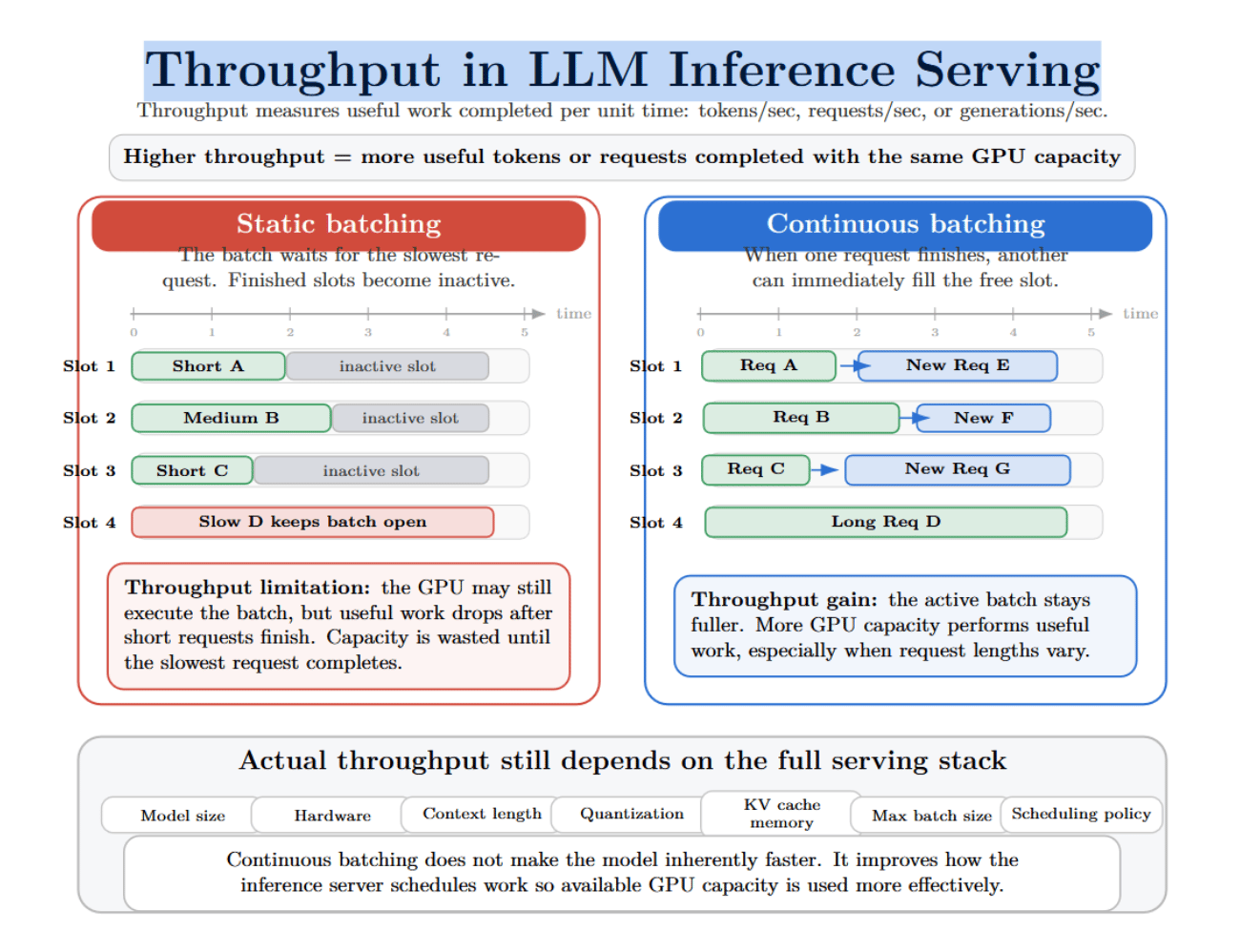
Continuous batching can increase throughput by keeping the active batch fuller. As soon as a request ends, another can start filling its slot. This improves GPU occupancy, reducing wasted time on the GPU. Continuous batching can also make it easier on the server when requests have variable lengths.
Continuous batching optimizes how the server schedules work so that available GPU capacity is used more effectively. Actual throughput will still vary with model size, hardware, context length, quantization method, KV cache footprint in memory, max batch size, and scheduling policy.
Latency Implications: TTFT, TPOT, and Tail Latency
Latency is more subtle than throughput since latency can be experienced differently by users. Let’s consider the following metrics:
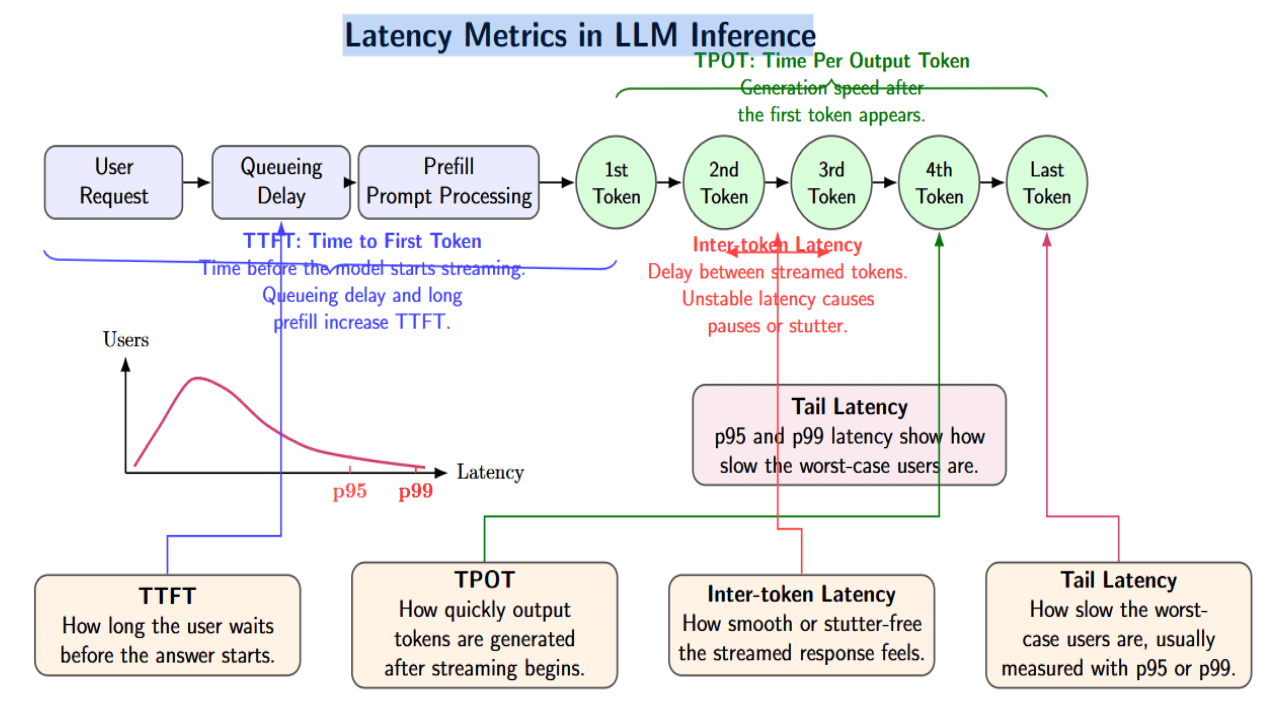
- TTFT, or time to first token. It measures how long the users have to wait before the model starts streaming their answer back to them. Queueing delays and long prefills both contribute to a high TTFT.
- TPOT, or time per output token. This measures the speed with which tokens are generated after the first token.
- inter-token latency. This refers to the delay between streamed tokens. If inter-token latency is unstable, users may see the answer pause or stutter.
- Tail latency. It is often expressed as p95 latency or p99 latency and shows how slow the worst-case users are.
Continuous batching can reduce TTFT by admitting new requests sooner than static batching. But there is a tradeoff. If a scheduler aggressively inserts long prefills into the active batch, existing users may experience slower token streaming.
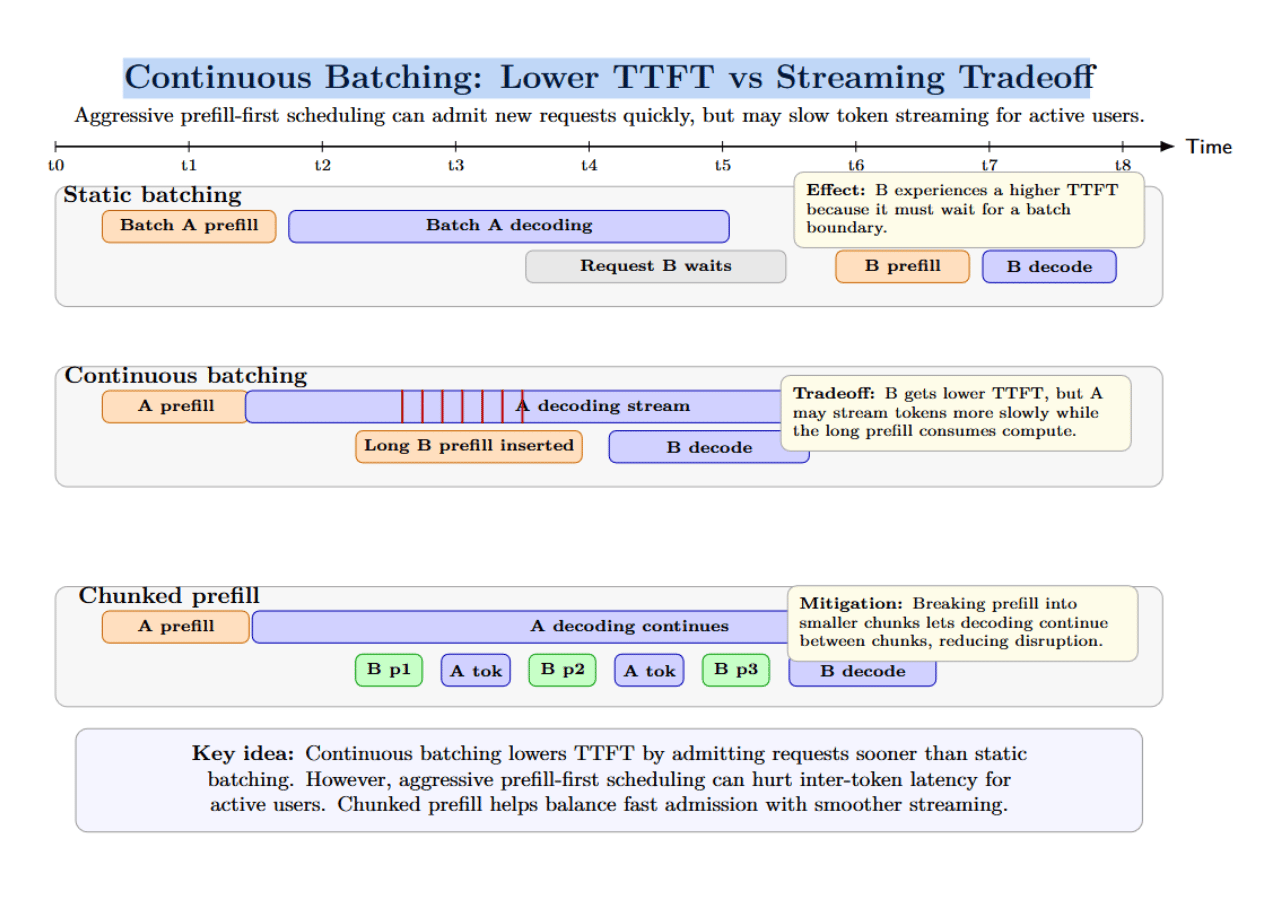
HuggingFace suggests: “prefill-first” scheduling strategies can reduce TTFT for incoming requests at the cost of slowing down or even interrupting decoding on already-running requests; chunked prefill can help avoid this issue by breaking large prefills into smaller units.
This is why the best inference engines do more than continuous batching. They also implement chunked prefill, KV cache-aware scheduling, prefix caching, and careful queue management.
When Static Batching Still Makes Sense
Static batching is not always wrong. It is fine when your workload is predictable, and latency is not critical. Examples include:
- offline evaluation;
- synthetic benchmarks;
- batch document summarization;
- translation jobs with similar input lengths;
- internal data processing pipelines;
- research experiments where reproducibility matters more than serving efficiency.
If requests are available in advance and are relatively uniform in length, static batching can be easy and effective. There’s no need to dynamically schedule.
When Continuous Batching Is Better
Continuous batching is best for online, multi-user LLM serving.
It is especially useful for:
- chat applications;
- coding assistants;
- AI agents;
- customer support bots;
- developer APIs;
- SaaS AI features;
- high-concurrency inference endpoints;
- streaming text generation;
- workloads with variable prompt and output lengths.
Requests don’t arrive in these environments in convenient batches. They come in at different times and request varying amounts of compute and memory. Continuous batching allows a server to adapt to that reality.
When deploying these systems, operators shouldn’t ask, “Does my server support batching?” They should ask: “How does my server schedule prefill and decode work under real traffic?”
vLLM vs. TGI: Which Should You Choose?
TGI and vLLM play complementary roles in the LLM inference ecosystem. TGI pioneered many features that made text generation practical, especially for teams already invested in Hugging Face tooling. TGI enabled continuous batching and other convenient serving features.
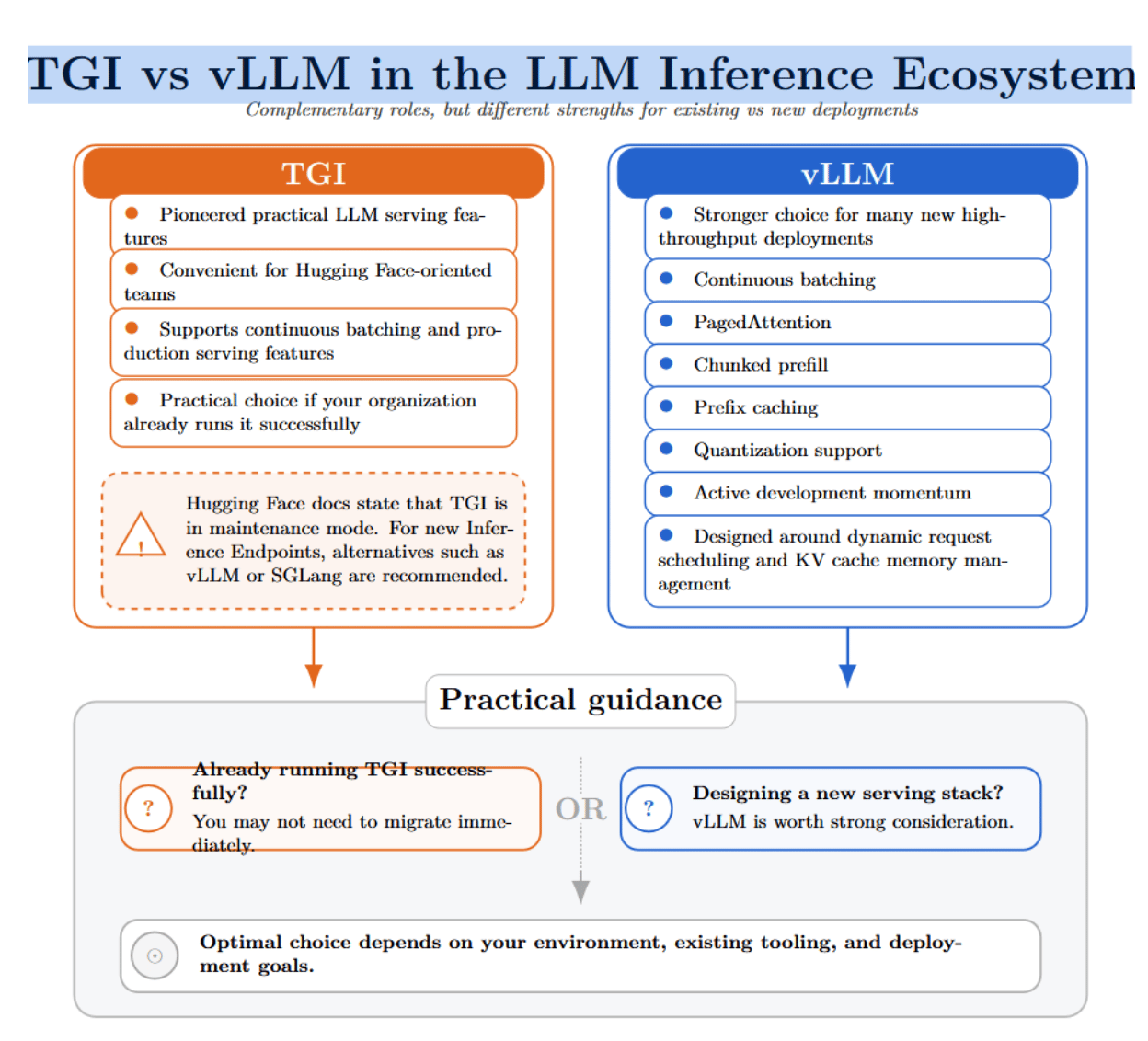
Typically, vLLM will be the stronger choice for new high-throughput deployments. vLLM offers continuous batching, PagedAttention, chunked prefill, prefix caching, quantization support, and active development momentum. vLLM is designed around the two primary bottlenecks of LLM serving: dynamic request scheduling and KV cache memory management.
That being said, the optimal choice depends on your specific environment. If your organization is already running TGI successfully, there may not be a need to migrate away. However, if you are architecting a new serving solution from scratch, we think vLLM is worth your consideration.
FAQ SECTION
1. What is the main difference between static batching and continuous batching?
Static batching forms a fixed batch and waits until all requests finish. Continuous batching updates the active batch during generation and admits new requests as soon as capacity becomes available.
2. Why does continuous batching improve throughput?
It keeps GPU slots active. When one request finishes, another request can enter the running batch instead of waiting for the longest request to complete.
3. Does continuous batching always reduce latency?
Not always. It can reduce queueing delay and TTFT, but poor scheduling of long prefills can hurt inter-token latency for active users.
4. How does vLLM improve continuous batching?
vLLM combines continuous batching with PagedAttention, which manages KV cache memory efficiently using block-based allocation. This helps the server fit more active requests and reduce memory waste.
5. Is TGI still relevant?
Yes, especially for existing Hugging Face-based deployments. But Hugging Face documentation states that TGI is now in maintenance mode and recommends alternatives such as vLLM or SGLang for future Inference Endpoint deployments.
Conclusion
Continuous batching is one of the important LLMs inference serving optimizations. Static batching works well if your traffic is predictable and well-behaved. Unfortunately, traffic rarely behaves like this in production for LLM requests due to differing prompt lengths, output lengths, and arrival distributions. Static batching will completely waste GPU cycles waiting for the slowest request to finish in a batch.
Continuous batching attempts to address this by batching requests at the iteration level. As requests finish, they graduate out of the active batch, while incoming requests take their place. This keeps the GPU fed while improving throughput, slot utilization, and potentially reducing queueing delay experienced by new users.
However, batching is only one part of the inference stack. Production-grade LLM serving also requires efficient KV cache management, chunked prefill, prefix caching, observability, quantization, and careful latency monitoring. vLLM and TGI both support continuous batching, but vLLM has become a stronger forward-looking option for many new deployments because of its combination of scheduling and memory optimizations.
The central lesson is clear: in LLM inference, performance is not only about the model. It is also about how intelligently the server schedules work.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
