By Jeff Fan and Anish Singh Walia

A practitioner argument about hidden inference cost multipliers, with live-run measurements from DigitalOcean Serverless Inference. Cross-provider patterns apply everywhere. DO-specific numbers below come from documented API runs on inference.do-ai.run, not from marketing claims.
The gap is structural, not a billing bug
Your LLM bill in production rarely equals input_tokens × input_rate. Providers quote input because it is the smaller number. Production traffic pays for output, hidden reasoning tokens, repeated prefixes, non-prod replay traffic, and context tiers you crossed without noticing.
Teams budget from the pricing page and get surprised at invoice time. That surprise is predictable once you map the five multipliers below. The multipliers stack. Fixing one while ignoring the others leaves most of the gap intact.
Pricing note: Token rates cited here reflect June 2026 list prices from provider docs and DigitalOcean Inference pricing. Confirm live rates before you budget.
Five multipliers between the sticker price and the invoice
Output tokens dominate the blend
Claude Sonnet 4.6 lists $3.00 per million input tokens and $15.00 per million output tokens. DigitalOcean Serverless Inference lists the same split at the time of writing.
A conversational workload at a 1:2 input-to-output ratio already blends to 3× the headline input rate before any other multiplier applies. Pull your last 30 days of usage. If output runs 2x or 3x input volume, your effective rate is nowhere near the number on the pricing page.
Reasoning tokens bill as output and stay invisible
Models with extended thinking (Claude adaptive thinking, OpenAI o3/o4-mini) emit tokens users never see. Providers bill them at output rates.
On Claude Opus 4.8 at $25 per million output tokens, 500 visible output tokens plus 2,000 thinking tokens cost 5× what 500 visible tokens alone would cost. Opus 4.8 and Opus 4.7 require adaptive thinking. You control depth with effort, not a fixed cap:
{
"model": "claude-opus-4-8",
"max_tokens": 16000,
"thinking": { "type": "adaptive" },
"output_config": { "effort": "low" },
"messages": [{ "role": "user", "content": "Classify this support ticket." }]
}
This request sends a short classification prompt to Claude Opus 4.8 with adaptive thinking enabled, but sets effort to low so the model spends fewer hidden reasoning tokens before answering. Opus 4.8 always thinks; you cannot turn that off, but you can match depth to the task. A ticket label does not need the same reasoning budget as a multi-step agent workflow. Pairing low effort with a simple prompt keeps invisible thinking tokens from inflating a bill that should stay near the visible output count.
Inspect usage on every response. Reasoning models often dominate spend on simple tasks when effort defaults high.
Non-production traffic shares one API account
CI pipelines replay prompts on every pull request. Staging mirrors production. Load tests hit the model endpoint to validate app scale, not model cost. Without environment tags, all of it bills like production.
Speedscale’s enterprise analysis documents teams discovering non-prod share only after the invoice arrives. Tag every call:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MODEL_ACCESS_KEY"],
base_url="https://inference.do-ai.run/v1",
)
response = client.chat.completions.create(
model="anthropic-claude-4.6-sonnet",
messages=[{"role": "user", "content": "Summarize this log line."}],
extra_body={
"metadata": {
"environment": os.environ.get("APP_ENV", "local"),
"service": "ci-test-runner",
}
},
)
print(response.usage)
This snippet calls DigitalOcean Serverless Inference through the OpenAI-compatible SDK and attaches metadata tags for environment and service on every request. Those tags ride in extra_body so you can slice usage logs by source—CI runners, staging, production—instead of treating every token as prod spend. Printing response.usage gives you the token counts to reconcile against your bill once tagged traffic is grouped.
First-time environment splits often show CI and staging at 30% to 50% of total token volume.
Verbosity varies 2x to 4x by model for the same prompt
The same classification prompt on a thorough model returns paragraphs. On a terse model it returns a label. You pay for every output token either way. This is the volume channel of model selection: same task, different output token counts.
Prompt constraints (“respond with the label only, no explanation”) cut output 60% to 80% on structured tasks. Long term, match model verbosity to task type and measure output tokens per endpoint, not per model catalog entry.
Long-context surcharges apply to the whole request
GPT-5.5 (OpenAI docs): $5/$30 per million input/output below 272K input tokens. Above 272K input, $10/$45 per million for the full session.
Gemini 3.1 Pro Preview (Google pricing): $2/$12 per million up to 200K context. Above 200K, $4/$18 per million on all tokens in the request.
| Model | Standard rate (input / output per M) | Threshold | Long-context behavior |
|---|---|---|---|
| GPT-5.5 | $5 / $30 | >272K input | 2× input / 1.5× output, full session |
| Gemini 3.1 Pro Preview | $2 / $12 | >200K input | $4 / $18 per M, whole request |
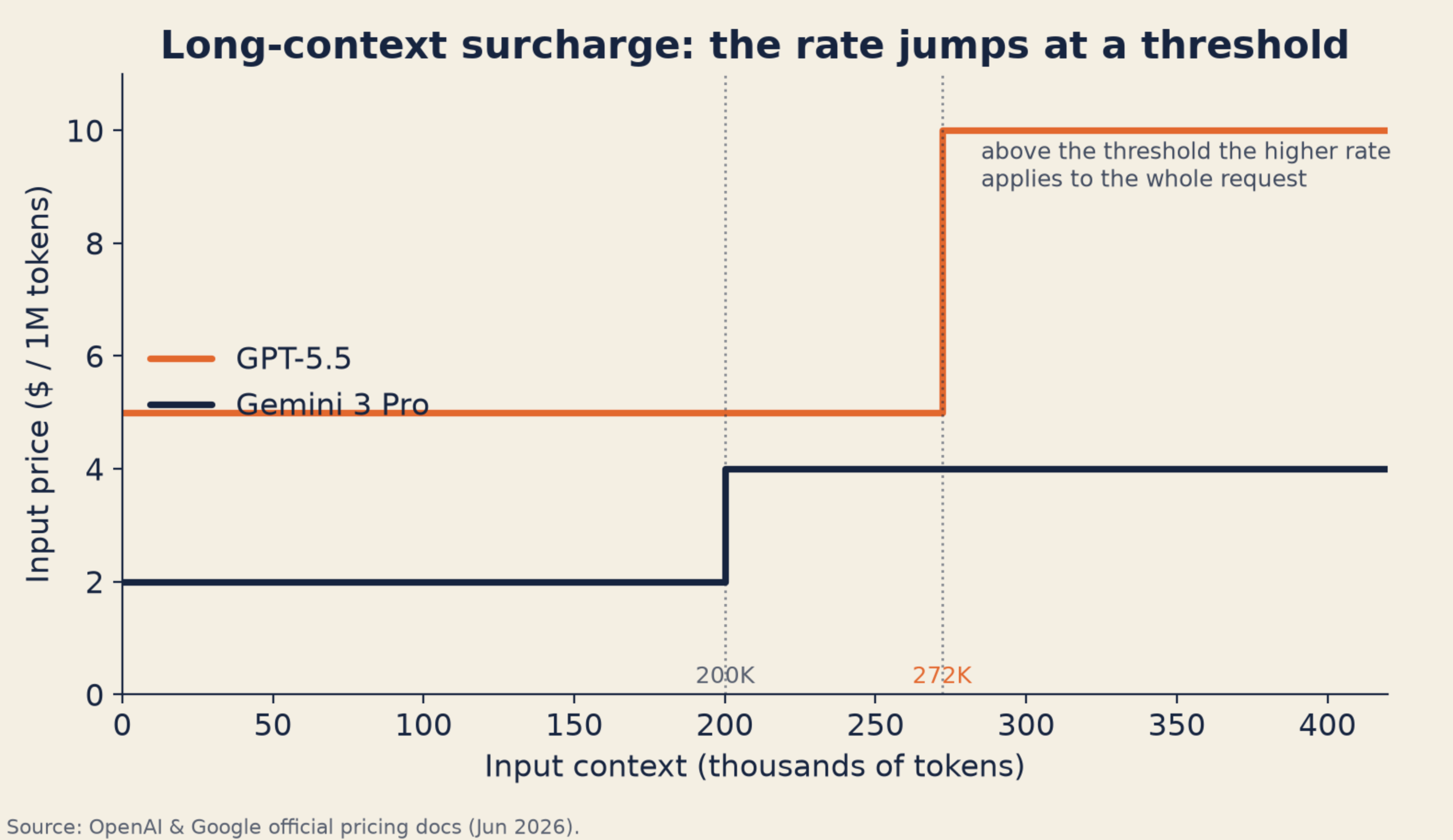
RAG pipelines and multi-turn agents cross these thresholds on a meaningful share of requests. Audit p95 and p99 input context length against each provider’s tier boundary.
What we measured on DigitalOcean Serverless Inference
The multipliers above are provider-agnostic. The numbers in this section come from live API runs on https://inference.do-ai.run/v1 documented in Multi-Model API Cost Governance with the Inference Router (as of June 16, 2026). Methodology: fixed prompts, temperature=0, token counts read from response usage, costs computed from published DigitalOcean Inference rates at the time of the run.
The model-selection tax: identical tokens, 36× cost spread
Model choice moves cost through two separate channels: the per-token rate the model charges, and the output volume it produces (verbosity, multiplier #4). This first measurement isolates the rate channel. Same classification prompt, three models, identical token shape (94 input / 80 output) — output ratio (multiplier #1) and verbosity (multiplier #4) are held constant, so the only variable is price:
| Model | Per-request cost (June 16, 2026 run) | vs cheapest path |
|---|---|---|
openai-gpt-oss-20b |
$0.00004070 | baseline |
openai-gpt-5 |
$0.00091750 | 22.5× |
anthropic-claude-4.6-sonnet |
$0.00148200 | 36× |
Calculation for openai-gpt-oss-20b: (94 × $0.05 + 80 × $0.45) / 1,000,000 = $0.00004070.
Sending every classify call to Sonnet when openai-gpt-oss-20b clears the accuracy bar is a 36× per-request tax — paid purely on rate, before verbosity adds anything. At 700,000 classify requests per month, that gap is $28.49 vs $1,037.40 on routing alone. No volume discount fixes model mismatch.
This aligns with the broader DO benchmark in Metrics that Matter with Serverless Inference: cost per completed answer swings roughly 230× across the model catalog on the same provider. Provider list price moves cost by percents. Model choice moves it by orders of magnitude.
Reasoning output volume: ~840× the classify cost
Same provider, different task, June 16 live runs:
| Path | Model | Tokens (in / out) | Per-request cost |
|---|---|---|---|
| Classify | openai-gpt-oss-20b |
94 / 80 | $0.00004070 |
| Customer Q&A | anthropic-claude-4.6-sonnet |
412 / 292 | $0.00445200 |
| Reasoning | openai-gpt-5 |
891 / 3,411 | $0.03417625 |
The reasoning path costs ~840× more per request than classify ($0.03417625 vs $0.00004070). GPT-5’s input rate ($1.25/M) is lower than Sonnet’s ($3.00/M), so this is not a rate-channel effect — the bill explodes because reasoning generates 3,411 output tokens vs 80 on classify. This is multiplier #2 and the volume channel of multiplier #1 in numeric form: output volume, including thinking tokens billed before the visible answer, dominates the cost.
Reproduce the measurement
Run this against your own Model Access Key. It logs the usage block you need for cost attribution:
curl -s -X POST "https://inference.do-ai.run/v1/chat/completions" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai-gpt-oss-20b",
"temperature": 0,
"messages": [
{"role": "system", "content": "Classify the ticket. Reply with one word: billing, bug, how-to, or account."},
{"role": "user", "content": "I was charged twice for my subscription last month."}
]
}' | python3 -c "import sys,json; u=json.load(sys.stdin)['usage']; print(u)"
This one-liner posts a fixed classify prompt to openai-gpt-oss-20b with temperature=0 and prints the response usage block. Run it with your Model Access Key to see the exact prompt_tokens and completion_tokens DigitalOcean bills against. Repeat the same call with anthropic-claude-4.6-sonnet on the identical prompt and the usage delta is the model-selection tax your bill carries today, same task shape, but different per-token rate.
Full router setup, task policies, and the x-model-router-selected-route response header are in the Inference Router how-to and the cost governance tutorial.
Visibility comes before optimization
Most billing dashboards show total tokens and total spend. They omit environment split, cache hit rate, thinking vs visible output, long-context tier exposure, and per-task output distribution.
Without that breakdown, you optimize blind. The script below estimates blended cost from usage counters using DigitalOcean/Anthropic list rates. Wire it to your inference logs:
#!/usr/bin/env python3
"""Estimate blended LLM cost from token usage counters."""
from dataclasses import dataclass
@dataclass
class ModelRates:
input_per_m: float
output_per_m: float
cache_read_per_m: float = 0.0
RATES = {
"anthropic-claude-4.6-sonnet": ModelRates(3.00, 15.00, 0.30),
"openai-gpt-oss-20b": ModelRates(0.05, 0.45),
}
def estimate_cost(model, input_tokens, output_tokens, cache_read_tokens=0, thinking_tokens=0):
rates = RATES[model]
billable_output = output_tokens + thinking_tokens
input_cost = (input_tokens / 1_000_000) * rates.input_per_m
cache_cost = (cache_read_tokens / 1_000_000) * rates.cache_read_per_m
output_cost = (billable_output / 1_000_000) * rates.output_per_m
total = input_cost + cache_cost + output_cost
headline = (input_tokens / 1_000_000) * rates.input_per_m
return {
"total_usd": round(total, 4),
"input_only_usd": round(headline, 4),
"multiplier_vs_input_rate": round(total / headline, 2) if headline else 0.0,
}
# 1M input, 2M output, 500K thinking: multiplier ~13.5× vs input-only estimate
print(estimate_cost("anthropic-claude-4.6-sonnet", 1_000_000, 2_000_000, thinking_tokens=500_000))
This helper turns raw token counters into a dollar estimate that includes output and thinking tokens, not just input. The multiplier_vs_input_rate field surfaces the gap between pricing-page math and what you actually pay: the example at the bottom—1M input, 2M output, 500K thinking—returns a multiplier of roughly 13.5× against an input-only estimate. Wire it to your inference logs to flag endpoints where blended cost diverges from what you budgeted.
Four levers, ordered by leverage
Prompt caching cuts repeated prefix cost. Anthropic cache reads bill at 10% of base input (pricing docs). A 1M-token system prompt with 80% cache hit rate changes input economics materially. Mechanics: Advanced Prompt Caching.
Batch inference offers ~50% off for async workloads with a 24-hour SLA. If your job tolerates delay and you still call sync endpoints, you are leaving the easiest discount on the table.
Volume discounts kick in at high monthly spend. Many teams who qualify never ask.
Model routing is the largest lever when traffic mixes simple and complex tasks. The June 16 DO live runs above show a 36× spread on identical classify prompts. Inference Router automates task-to-model dispatch on inference.do-ai.run without application-side routing logic. At a 700K / 250K / 50K classify / Q&A / reasoning split, documented router routing reduced monthly cost 39.6% vs a Sonnet-only baseline and 63.7% vs Opus-only using the same per-request measurements (see cost governance tutorial for the full traffic model).
Why per-token billing and routing map to the multipliers
Multiplier #3 (non-prod leakage) is an observability problem. Per-token billing on a shared API key does not separate environments by default. You fix it with tags in request metadata and a dashboard that groups usage by environment. DigitalOcean Serverless Inference bills from the same usage block the API returns, so your log pipeline and your invoice share one source of truth.
Model selection drives multiplier #4 (verbosity) and the rate spread together, and both are architecture problems. When one frontier model serves classify and reasoning, you pay frontier prices on one-word labels through two channels at once: the higher per-token rate (the measured 36× classify premium) and, for chattier models, higher output volume on the same task.
Routing by task complexity keeps average cost proportional to task value. Classify traffic stays on openai-gpt-oss-20b. Q&A stays on Sonnet with session pinning for KV-cache warmth. Reasoning escalates to GPT-5 only when output volume justifies the rate. That architecture directly attacks multipliers #1, #2, and #4. It does not replace environment tagging for multiplier #3.
For hosting mode tradeoffs (when per-token serverless yields to GPU-hour dedicated), see Serverless vs Dedicated vs Batch Inference and Dedicated vs Serverless Inference as You Scale. Cache-hit-rate benchmarking on DigitalOcean infrastructure is tracked separately in the serverless benchmarking pipeline.
References
- Multi-Model API Cost Governance with the Inference Router (DigitalOcean, June 2026 live runs)
- Metrics that Matter with Serverless Inference (DigitalOcean cost-per-answer benchmarks)
- Why Serverless Inference Consistency Varies on the Same Model (DigitalOcean internal TTFT testing)
- Anthropic API Pricing
- DigitalOcean Inference Pricing
- GPT-5.5 Model Documentation (OpenAI)
- Gemini API Pricing (Google)
- I Analyzed 60+ LLM Models and Found Companies Overpay by 50-90% (third-party overpayment analysis)
- The Hidden AI Bill: Why Non-Prod LLM Costs Spiral (Speedscale)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I’m a Senior Solutions Architect in Munich with a background in DevOps, Cloud, Kubernetes and GenAI. I help bridge the gap for those new to the cloud and build lasting relationships. Curious about cloud or SaaS? Let’s connect over a virtual coffee! ☕
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
