Update on the March 24, 2016 DNS Outage
By DigitalOcean
- Published:
- 5 min read
Yesterday, DigitalOcean’s DNS infrastructure was unavailable for two hours and four minutes. During this time we were only able to respond to a small fraction of the DNS requests sent to ns1, ns2, and ns3.digitalocean.com. We know how much you rely on DigitalOcean, and we take the availability and reliability of our services very seriously. We would like to apologize and share more details about our DNS system in general, this specific attack, and what we are doing to make our systems more resilient from here on.
Some background
The resolvers which compose our authoritative DNS infrastructure are fronted by a well-known DDoS mitigation company. The service they offer uses anycast to move traffic from clients all across the world to DigitalOcean’s nearest datacenter. We then have authoritative resolvers in all of our facilities to process and respond to DNS queries. One of the most significant advantages to this approach is it allows for simple load distribution across our global footprint and makes it easy to add more resolvers to deal with increased capacity needs.
The incident
At 2:34 pm UTC (10:34 am EDT) on March 24, 2016, we began to receive alerts from our monitoring system that all the resolvers were failing to respond to DNS queries. As we investigated the issue, we noticed that the resolvers were receiving orders of magnitude more queries than normal. Although there was significantly more capacity available than is required during typical peak operation, it was still not enough to answer this unusually large quantity of inbound queries. We started to take a closer look at the queries which were being sent to the resolvers in an attempt to differentiate normal traffic from that of a bad actor. The traffic patterns and source IP addresses matched what we would expect — just at much larger volumes than normal. You can see uncached (the yellow line) and cached traffic (the green line) below.
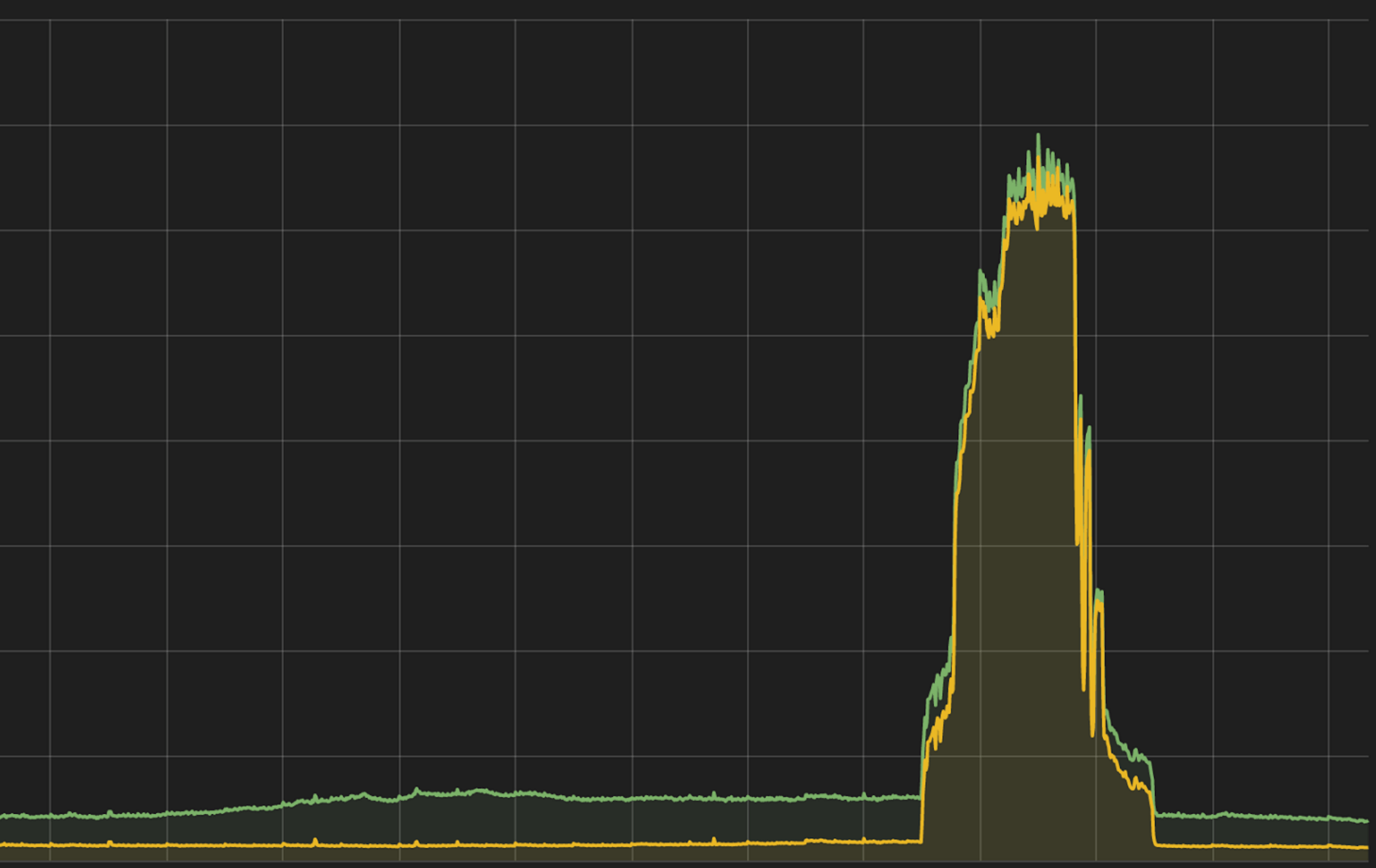
At this point, our DDoS mitigation provider was engaged. All of our DNS traffic flows through their network, which has numerous protections in place to both identify and mitigate attacks. However, neither of us were able to find anything abnormal about this traffic beyond its volume at that point.
Our DNS daemon was configured to empty the queue of unanswered queries at a certain threshold to ensure the daemon would be able to answer future inbound queries. This inadvertently caused cache invalidation. We rolled out a new configuration that solved this issue, but the caches failed to repopulate. Although the system can withstand all the resolvers losing their query caches under normal conditions, the vastly increased number of queries made it impossible for the resolvers to rebuild their cache. This all took place while the resolvers were already under abnormally high load, causing them further stress.
At this point, we further engaged with our DDoS mitigation provider to help identify the source and types of traffic and recognized a higher-than-normal percentage of queries for PTR records. We began blocking them to allow us to respond to other queries. They were also able to reduce the number of queries reaching our resolvers by blocking some autonomous system numbers (ASNs) from which the most significant volumes of traffic were originating. Finally, we increased the TTL for cached DNS records, which is the length of time for which the edge caches responses before allowing new queries to hit the origin resolvers. As we looked through the traffic to find patterns, it became clear that the attacker knew a large number of domains managed with our DNS infrastructure. All of our public subnets are available via ARIN, which means it’s possible to find domains which are hosted on our service, infer they are using our DNS, and then send large volumes of legitimate-looking queries. Although the ASN blocking certainly prevented some legitimate DNS lookups from being answered, it almost immediately allowed the system to begin answering most queries.
The service began responding to queries with normal latencies starting at 4:40 pm UTC (12:40 pm EDT). Caches began to repopulate and query volume returned to normal levels. At 5:30 pm UTC (1:30 pm EDT), the vast majority of traffic ingressing to our resolvers was clean. In the first graph below, it’s possible to see the dramatic increase in query cache hit rate as the service begins to recover.
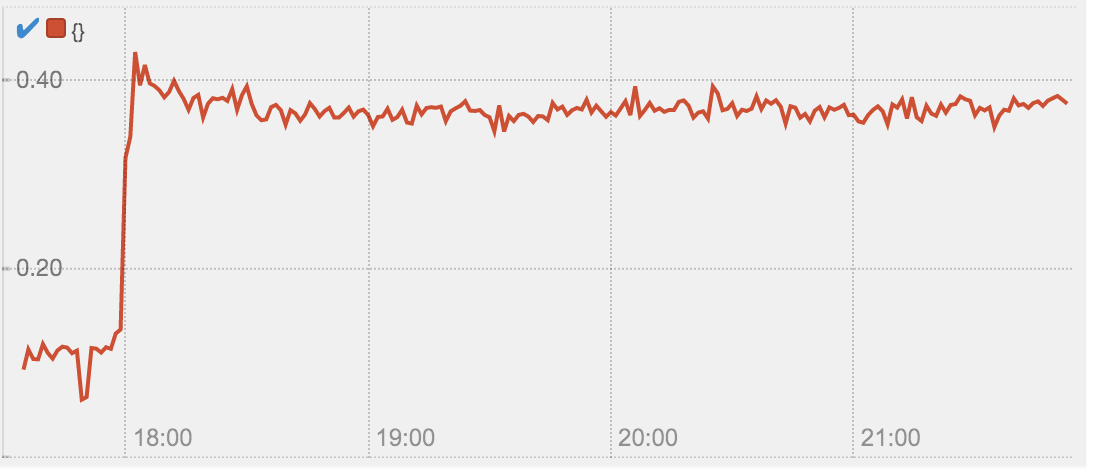
The graph below shows SERVFAILs in green, 50th percentile latencies between the edge and our resolvers in blue, and 90th percentile latencies in yellow.

At 7:22 pm UTC (3:22 pm EDT), the majority of the filtering was removed.
Future measures
There are a number of pieces of infrastructure we are reviewing and improving. Most notably, we will be building better means of moving DNS traffic around within our infrastructure. One of the things which caused this incident to span two hours was the lack of control we had over the traffic which was reaching our network. Although we’ll continue to work with the DDoS mitigation provider, we will also be improving our own DNS network by creating means to internally move, rate limit, and shape traffic in order to continue to respond to most requests even while under attack. We already have robust tooling in place for mitigating attacks on the Droplet network and will extend that to support DNS as well.
We will be decoupling the provisioning of additional capacity from the DDoS mitigation provider entirely. External communications with our DDoS mitigation provider meant that we had a fairly constant back-and-forth during the incident, making it harder for us to test mitigation techniques on our own. They transparently send through requests to the resolvers, which means our ability to provision more resolver capacity is dependent upon the provider’s speed of response. This caused adding additional nodes to the pool to take much longer than is ideal, which subsequently slowed our return to normal operation. We’re planning to change how we present our network to the proxies run by our DDoS mitigation provider to make dynamically changing the capacity of the pool easier.
In Conclusion
First and foremost, we know that our service is critical in the success of your projects and businesses. All of us at DigitalOcean would like to apologize for the impact of this outage. We will continue to analyze this incident, hone our internal communications, and take steps to improve the reliability and resilience of the systems which power DigitalOcean.
About the author
Related Articles

Technical Deep Dive: How DigitalOcean and AMD Delivered a 2x Production Inference Performance Increase for Character.ai
- January 13, 2026
- 13 min read

Currents Report: How Growing Tech Businesses Use AI Today
- February 6, 2025
- 3 min read

Introducing the DigitalOcean Netlify Extension
- October 3, 2024
- 2 min read