The Glue Problem in Modern AI Development
AI/ML Technical Content Strategist
- Updated:
- 10 min read
AI is now central to modern software development. Teams across industries are turning to AI to solve product and workflow problems in software. But building production systems is still complex. The hardest part of deploying AI isn’t the model, it’s everything around it. That complexity becomes a glue-code problem when storage, compute, orchestration, networking, authentication, and inference live in separate systems with different operating models. The more seams a workflow crosses, the more developer effort shifts from building product logic to wiring services together.
A more integrated platform model reduces that burden. This article examines what it takes to deploy and operate AI applications in today’s cloud landscape. Using two examples, we will compare the process in two landscapes: a neocloud combined with a hyperscaler versus a vertically integrated cloud stack. While surface-level costs may look similar, the integrated model offers clear advantages in efficiency by reducing the time developers spend writing glue code and managing the problems that emerge as AI products scale.
Key Takeaways
- The biggest cost in AI systems isn’t infrastructure: it’s integration. Fragmented, multi-provider stacks force developers to spend time writing and maintaining glue code instead of building product features, turning engineering effort into the real cost center.
- Raw infrastructure pricing is no longer the differentiator; total cost of ownership is. Even when platform costs are nearly identical, the added complexity of cross-cloud orchestration increases operational overhead, failure points, and staffing requirements at scale.
- The future of AI platforms is vertical integration, not more tools. Platforms that unify compute, storage, and inference reduce friction, accelerate development, and allow smaller teams to build and scale AI applications more efficiently.
The Real Problem Is Fragmentation
Consider the modern landscape for AI deployment. AI applications rely on far more than inference alone. Real workflows span object storage, compute, prompt transformation, model endpoints, persistence, and monitoring, each of which requires its own operational expertise.
Naturally, these pieces are usually not connected natively. That’s just the current state of the cloud: siloed products, resources, and services that are often only able to connect to one another through APIs. As a result, developers spend valuable time setting up and maintaining those connections. Bridging the gaps between services and products operating in different clouds requires real, manual work. The separated system is harder to scale, secure, and debug.
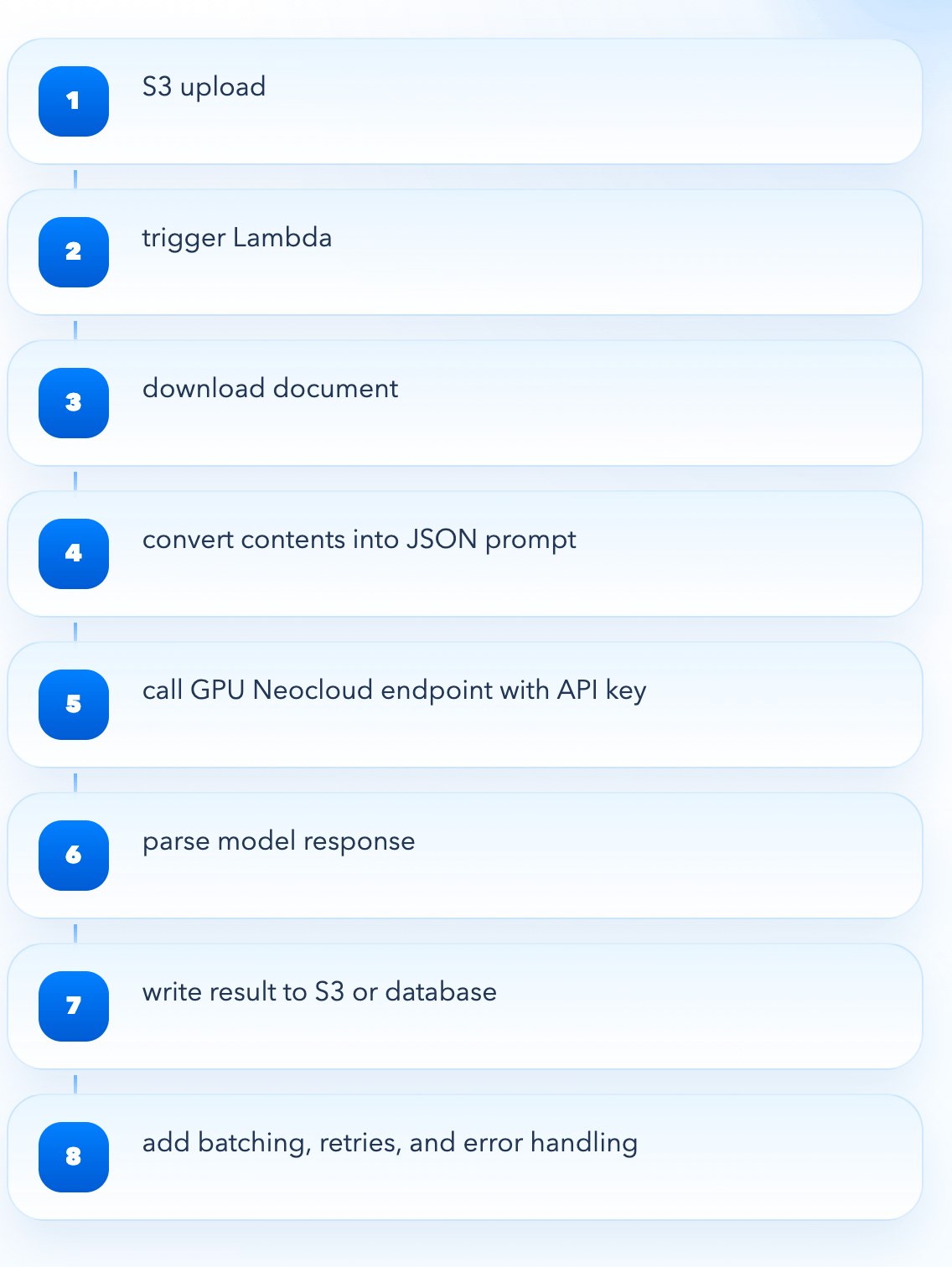
Consider a neocloud like Baseten or Fireworks.AI paired with a hyperscaler like AWS. In this setup, the neocloud hosts the model while the hyperscaler orchestrates the surrounding application or workflow. We could have an application that processes user-uploaded documents stored in a storage service like S3 and uses an LLM to summarize them. Developers often manage authentication via API keys instead of shared cloud identity primitives. In AWS, a file upload could trigger a function such as Lambda through an S3 event. In this example, Lambda would download the file, convert its contents into a JSON prompt format, and send it via an HTTP request to the neocloud’s model endpoint using an API key. The model returns a response, which the Lambda then parses and writes back to S3 or a database.
If the model is scaled to zero, the request may experience additional latency, and if processing large batches, the developer must implement their own batching, retries, and error handling. None of this pipeline is managed natively by the neocloud, so the developer is responsible for orchestrating every step between AWS services and the external inference layer. None of this orchestration is the product’s differentiator, but it still has to be built and maintained.
Developer time and compute resources are consumed by connecting services and maintaining the code that bridges them. That complexity directly increases cost.
What This Means for Developers
The operational consequences become clearer at scale. First, scaling gets harder. Each custom handoff adds another failure point that teams must monitor and maintain. As usage grows, queues, retries, timeouts, and concurrency limits all come under pressure, forcing teams to spend more time keeping the system stable.
Next, networking gets objectively messier. Hosting an LLM often means exposing it through a public API endpoint. That makes the model behave more like an external SaaS dependency than native infrastructure, increasing concerns around security, egress, latency, and network boundaries.
Finally, data pipelines are not integrated. Without native connections to services like AWS’s S3 or Step Functions, developers must move and reshape data themselves. Teams must spend engineering time moving data between services and ensuring those connections work reliably. Batch and event-driven workflows may require extra orchestration layers, as well.
In practice, this shows how costs become fragmented. Different billing models across providers make spending harder to track. Furthermore, forecasting and debugging cost spikes become more difficult when usage spans multiple systems. In practice, this can force companies to dedicate entire teams to operating a fragmented stack.
The Hidden Cost of Glue Code
A typical AI pipeline may require 5–10 integration points, each introducing latency, failure risk, and engineering overhead. At scale, teams often have to dedicate developers or even entire teams to maintaining these connections. This is where the hidden cost of glue code becomes unavoidable: not in infrastructure or inference, but in people.
Once a certain scale is achieved, inference will eventually need to be migrated from serverless to dedicated providers. As you scale, serverless inference can become less efficient because you trade simplicity for less control over cost, performance, and capacity. It works well for low or unpredictable traffic, but at higher volumes, cold starts, concurrency limits, variable latency, and per-request pricing can make it more expensive and less predictable than dedicated infrastructure. A dedicated provider gives you reserved capacity, steadier performance, and more room to optimize GPU utilization, which matters once inference becomes a core, always-on part of your product. True dedicated services are usually concentrated on hyperscaler platforms, which often means investing even more developer time to learn, configure, and manage their infrastructure. That added operational complexity can make the developer experience significantly more difficult, especially compared with the simplicity that made serverless attractive in the first place.
Multi-cloud AI systems demand specialized expertise to manage failures, retries, networking issues, and inconsistent behavior across services. Building and retaining teams capable of operating these systems is expensive and difficult. In many cases, the cost of maintaining the system exceeds the cost of running it.
What the Ideal AI Cloud Should Actually Do
The best AI cloud should do more than host models; it should unify compute, storage, networking, inference, and persistence under one platform. This means that authentication, permissions, deployment, logging, and cost visibility should behave consistently across the stack. Common workflow steps should feel like built-in platform features, not expensive custom wiring.
Vertical integration is not a buzzword. It is a developer experience advantage.
Reframing the Problem with DigitalOcean
DigitalOcean’s vertically integrated cloud offers a practical alternative to this fragmented model by reducing the number of seams developers must manage. Instead of relying on a neocloud for inference and a hyperscaler for everything else, DigitalOcean brings compute, storage, and AI inference closer together under a unified platform model. This does not eliminate every dependency, but it significantly reduces the integration burden that defines modern AI development.
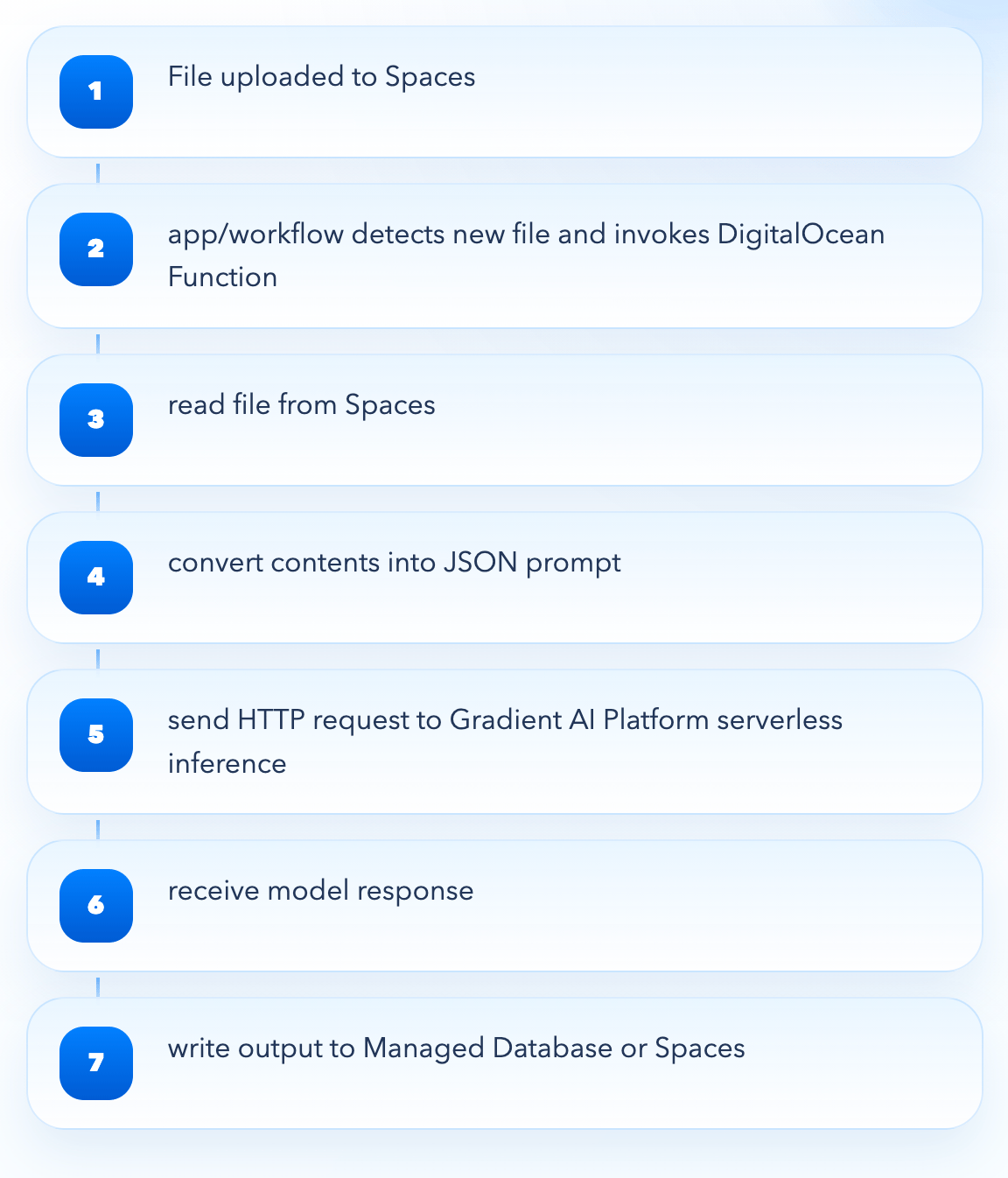
The same architecture can run on DigitalOcean with fewer moving parts. A file can land in Spaces, and your application or workflow can then detect the new object and invoke a Function that reads it, converts its contents into a JSON prompt payload, and sends an authenticated HTTP request to a Gradient AI Platform Serverless Inference endpoint using a model access key. Once the model responds, the application can persist the result in a Managed Database or write it back to Spaces.
That difference compounds over time. Fewer integration points mean fewer failure modes, lower latency, clearer cost visibility, and reduced operational overhead. Most importantly, smaller teams can build and scale AI applications without dedicating engineers to maintaining glue code.
The advantage is not just convenience: it is leverage. By minimizing the need for glue code, DigitalOcean allows developers to focus on building intelligent applications rather than wiring infrastructure together. In a landscape where complexity is the default, reducing seams is a competitive advantage.
Building the Demo for Cost Analysis
To validate this architecture, we built the demo described above and deployed it entirely on DigitalOcean. The goal was to compare the cost of running this application at scale on an integrated platform like DigitalOcean versus a split stack using a hyperscaler for infrastructure and a neocloud for inference.
For this updated analysis, we use a more apples-to-apples model comparison by assuming openai-gpt-oss-120b on DigitalOcean on a competing inference provider, like Baseten, paired with a cloud hyperscaler. We also keep the rest of the workflow assumptions the same:
| Assumption | Value |
|---|---|
| Input tokens per document | 10,000 |
| Output tokens per document | 500 |
| Preprocessing runtime per document | ~2 sec at 1 GB |
| Stored data per document | ~210 KB |
| Retention window | 30 days |
| Model used | gpt-oss-120b |
Under those assumptions, the two approaches come out to be effectively in the same cost range at scale. The key takeaway is that once the model comparison is normalized around GPT OSS 120B, neither platform is dramatically cheaper on infrastructure and inference alone. On public rate cards, the two are essentially at parity, with only a narrow single-digit spread between them at each volume tier. In practice, the two are close enough to treat as near-parity on raw platform spend.
Cost Analysis (before accounting for labor overhead)
| Monthly Volume | DigitalOcean-only | Baseten + AWS | Model API | Difference % |
|---|---|---|---|---|
| 1M summaries/month | ~$1,391 | ~1,306 | ~$85 | ~6% |
| 10M summaries/month | ~$13,910 | ~$13,060 | ~$850 | ~6% |
| 50M summaries/month | ~$69,550 | ~$65,300 | ~$4,250 | ~6% |
| 100M summaries/month | ~$139,100 | ~$130,600 | ~$8,500 | ~6% |
The real economic difference appears in labor. Consider a simple example: if a company needs to hire even one junior software engineer at roughly $7,000 per month to build and maintain the integrations required in a neocloud-plus-hyperscaler stack, that added labor cost can erase the apparent infrastructure savings at volumes below 50 million summaries per month. And that burden compounds quickly as systems grow more complex. A team of four junior engineers plus one senior engineer earning roughly $4,000 more per month can push infrastructure-management labor costs to nearly half the cost of the inference itself. At that point, the cost story is no longer about GPUs or API pricing alone. It is about how much engineering effort your platform demands just to keep the system running.
A multi-provider stack built across a neocloud paired with a hyperscaler introduces a real glue-code problem: more connective code, more integration points, more auth boundaries, more observability surfaces, and more failure modes spanning vendors. At enterprise scale, the engineering effort required to build, maintain, monitor, and evolve that connective tissue becomes a real cost center of its own. By contrast, running the same pattern on a single integrated platform like DigitalOcean reduces that cross-cloud orchestration burden. Storage, functions, managed database, app hosting, and model access all live inside one environment, which materially lowers the operational complexity and therefore the long-term labor cost of owning the system.
So the updated conclusion is not that DigitalOcean wins by a massive margin on raw usage pricing alone. Rather, it is that the two approaches are broadly cost-equivalent on infrastructure and model spend, while DigitalOcean’s integrated platform has the potential to be meaningfully cheaper in total cost of ownership once the human cost of maintaining cross-cloud glue code is taken into account.
Conclusion
The AI industry has made models easier than ever to access, but building production systems around them remains genuinely hard. The next wave of platform differentiation won’t come from expanding model catalogs or adding more configuration options. It will come from reducing the number of seams developers have to manage just to keep a system running.
The teams that scale AI fastest won’t necessarily be the ones with the most GPU access or the broadest model selection. They’ll be the ones who spent the least engineering effort on plumbing – and who chose infrastructure who let them move from serverless to dedicated capacity without rebuilding everything from scratch. That transition point is where most of the hidden cost lives, and it’s where platform decisions made early tend to compound in ways that are painful to undo later.
The winning platform may not be the one with the most capabilities. It may be the one that requires the least effort to actually use them.
About the author
Related Articles

Built for Mass Scale: Hard-Won Lessons from Teams Running High Volume Inference Workloads in Production
- July 2, 2026
- 5 min read
Run Codex in the cloud – DigitalOcean for Codex is now available
- June 25, 2026
- 3 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read