Advanced Prompt Caching at Scale
By Andrew Dugan
Senior AI Technical Content Creator II
- Updated:
- 6 min read
Introduction
Prompt caching is the process of reusing already computed KV states across inference requests in order to save money and reduce latency. Within a single replica, modern inference engines like vLLM, SGLang, and TensorRT-LLM handle it automatically. Incoming prompts are matched against cached prefixes and recomputed only where necessary, without requiring user configurations
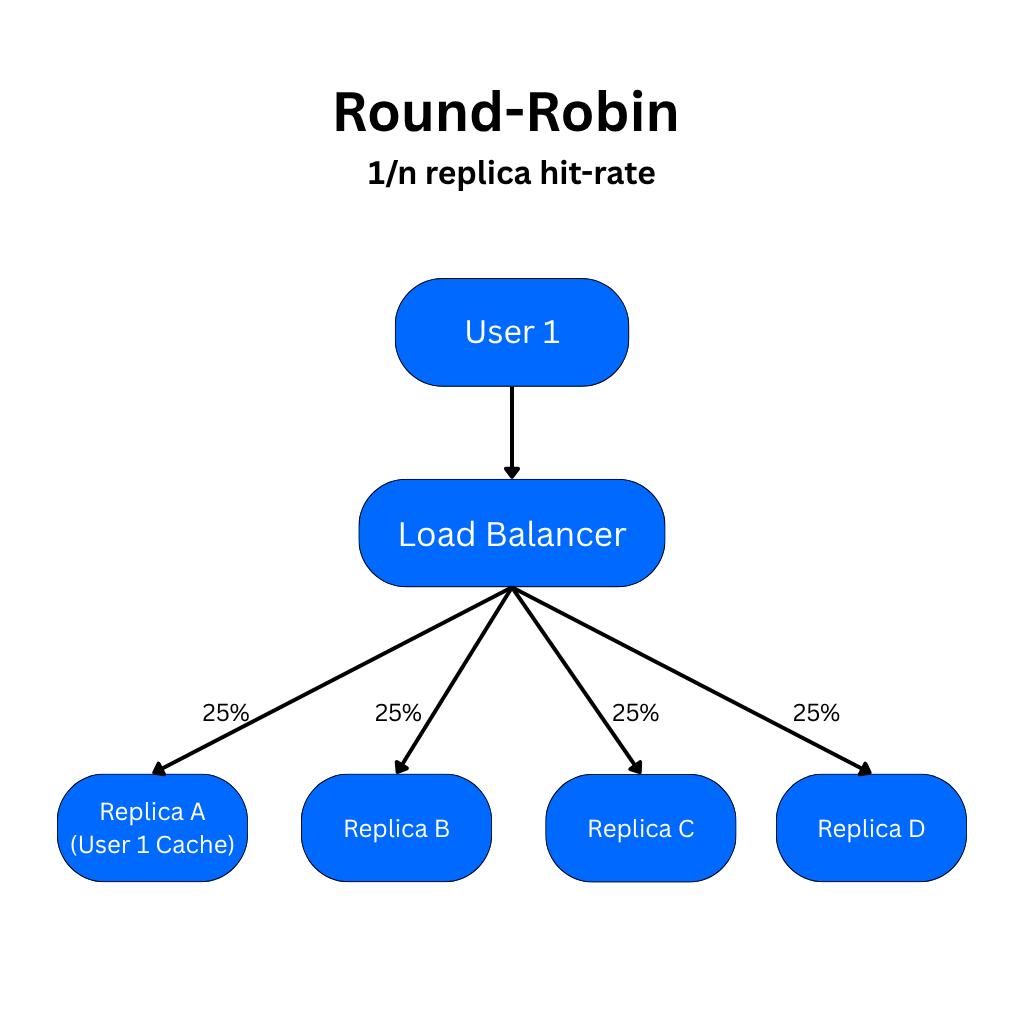
The problem nobody talks about is what happens when you scale to many replicas. Under round-robin load balancing, a request with an identical prefix has only a 1/N chance of hitting the replica where that prefix is already cached. The cache hit rate that made prompt caching so attractive at one replica degrades almost linearly as your fleet grows, unless you architect around it deliberately.
Done right, prompt caching at scale offers 50–90% discounts on cached input tokens and can reduce time-to-first-token (TTFT) latency by up to 80%. This article covers the architectural strategies that make that possible.
The Single-Replica Ceiling
Refer to our previous prompt caching article for a detailed explanation of how KV caching works under the hood. Every transformer-based LLM uses KV caching to store key and value vectors from the attention layers in GPU VRAM during decoding. This intra-request caching is baked into the model architecture to increase throughput and maximize efficiency. Within a single replica, modern open-source engines like vLLM, SGLang (via RadixAttention), and TensorRT-LLM support automatic prefix caching out of the box, matching incoming prompts against previously cached prefixes to maximize KV reuse without any user configuration. Reusing KV states across requests from many users and replicas is where inference frameworks differ significantly.
In the simplest architecture, the cache lives on individual replicas in VRAM. It is not shared across model instances at all. When a user makes an inference request, the prompt from their request is cached on a single replica. If the service is scaled up to multiple replicas, requests with identical prefixes can expect a cache hit rate of 1/N under uniform distribution across replicas that are routed with a load balancer. The likelihood of hitting the cache and benefitting from prompt caching decreases as the number of replicas increases.
Session Affinity
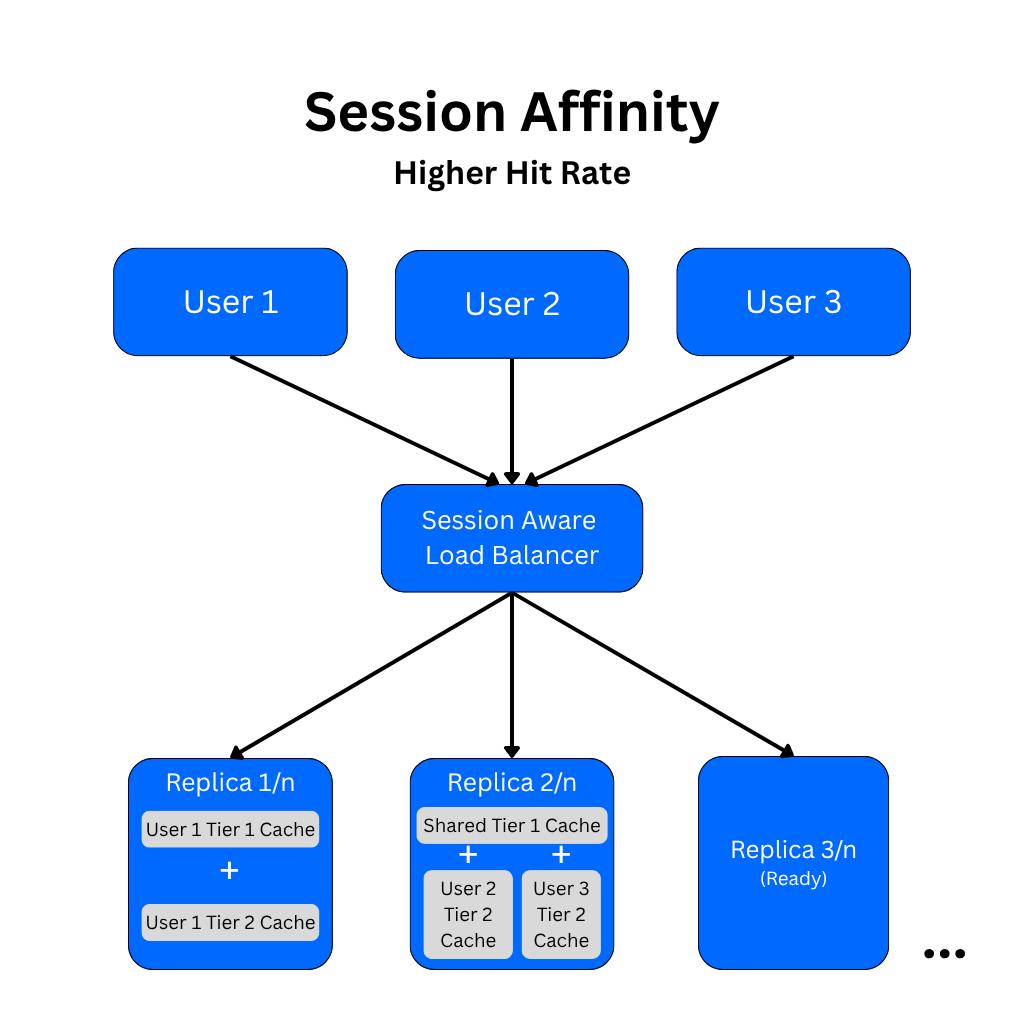
This scaling problem can be solved using session affinity to route requests from a user session to the same replica each time. This allows the cached prompt prefix to remain local and reusable across turns by effectively pinning sessions to replicas. The user’s inference requests then have consistent access to the cache, which is updated with every subsequent request.
With a simple session affinity architecture, scaling and failure events can cause some load imbalances or lost prompt caches. In practice, a resilient routing policy is necessary to keep most sessions on their current replicas over time, so only a small share of traffic loses warm cache during changes. This ultimately preserves latency and cost benefits as the fleet grows.
At the engine layer, prompt caches are generally organized to maximize prefix reuse, not just exact full-prompt matches. For example, prompt caches may be broken into tiers, where Tier 1 prompts are shared instruction prefixes and Tier 2 prompts are separated for session-specific prefixes. The Tier 1 prompts are reused broadly, while session-specific branches are reused within each session. The result is that each request computes only the uncached suffix instead of recomputing the entire prompt.
For most single-task deployments, this two-layer model is the default architecture, offering stable session-level routing plus strong engine-level prefix reuse. It is simple to operate, scales well, and captures most of the practical gains from prompt caching without additional architectural complexity.
Tiered Prompt Caching for Multi-Task Deployments
When an application serves many distinct tasks, each with its own system prompt (for example, a summarization task, a code generation task, etc.), the strategies above leave performance on the table. With session affinity alone, sessions for different tasks may land on the same replicas, filling the KV cache with unrelated prefixes and evicting useful entries.
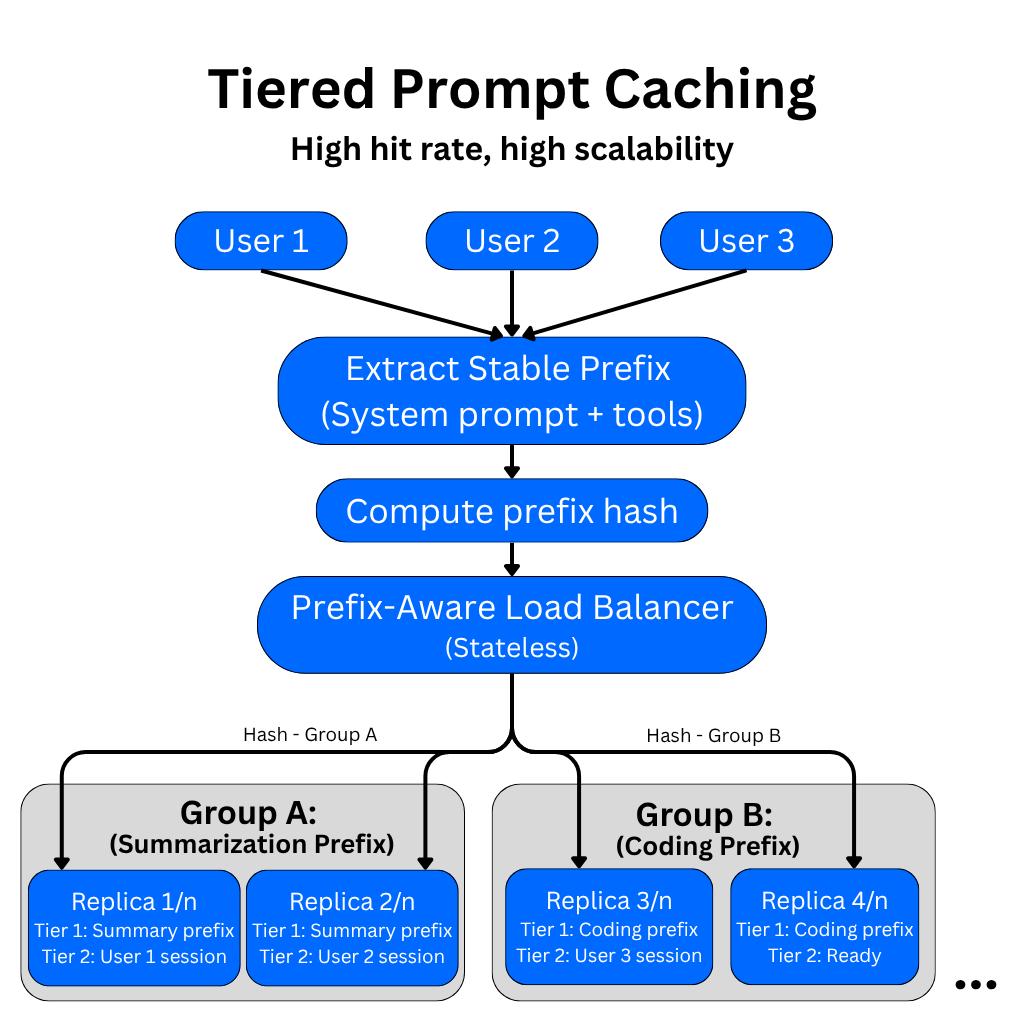
Having a prefix-aware load balancer solves this by grouping replicas by task. Commonly used prefix prompts including the system prompt, tool instructions, or anything baked into the service (Tier 1 prompts) are cached on dedicated groups of replicas. Each group independently computes and caches the system instructions prefix for its assigned task. Each replica in a group builds its own local copy of the Tier 1 prefix cache. There is still no cross-replica cache transfer. Then each session-specific prompt cache (Tier 2 prompts) extends beyond the Tier 1 prefix, and a prefix-aware load balancer uses a hash of the stable prefix to route the request to the correct replica group.
Within that group, consistent hashing pins the request to a specific replica that likely already has the longest matching prefix from previous turns. This shortens the amount of session-specific tokens that need to be recomputed because the Tier 1 prefix cache is already warm on every replica in that group.
The Ideal Prompt Caching Architecture
In the ideal prompt caching architecture, there would be a shared prompt cache that all replicas have access to, similar to a shared caching layer like Redis. The problem is that achieving near-local GPU performance over networked cache is difficult. KV tensors are large, making them slower to move over the network than local GPU VRAM access. It may decrease compute costs, but it can add latency.
One way this could be possible is to cache the prompts in VRAM on individual replicas and cache them on a shared CPU DRAM pool. On a cache miss, the GPU pulls the cached prefix from the shared pool. This could cost milliseconds of latency and avoid full recomputation.
For applications where latency is not a concern, this could be the sole prompt caching architecture for multiple replicas. If low-latency is a priority, it could be added to the other architectures. This is likely the direction the industry will head.
In the best case, a local GPU VRAM hit may add ~0-2ms to the request for a 1k token prefix on a small model. The same cache on a shared CPU DRAM cache on the same machine can add ~10-40ms. For a cross-node shared cache for replicas across machines, ~40-120 ms can be added. A cross-node shared cache with faster fabric might bring that down to ~25-50ms.
A good rule of thumb is that if the time for a model to recompute the prefix is greater than 100-300ms, shared caching is likely a good choice. If the prompts are shorter than 300-500 tokens, the transfer overhead is not likely to be necessary, and session affinity caching is probably all you need. For most use-cases, the added latency is acceptable for the compute and price-saving benefits of hitting the cache consistently.
There are currently no providers that publicly advertise this ideal prompt caching architecture yet, but it is likely that some major inference providers, like OpenAI, Google, etc. have either already implemented similar advanced architectures or are in the process of building them out for their own inference endpoints.
Teams today can capture most prompt caching gains by focusing on session-affinity routing, ordered prompt-templates, tiered task-level routing, and good observability and monitoring. The key factors to monitor in an advanced prompt caching system are the cache hit rate over time, TTFT, and the per-replica cache utilization. If the hit rate drops, it could indicate a scaling event or prompt structure change. Visibility is key. If you’re interested in adding cross-replica KV synchronization, start by baselining your cache hit rate and TTFT with your current session-affinity setup. Then make sure you’re exercising good prompt discipline, and standardize the prompt order so static tokens always come first. Then based on your cache hit rate, determine if a shared-cache strategy would really help.
Notes on Prompt Structure Best Practices
In all prompt caching architectures, the prompt structure will determine your hit rate. Static content is first, and variable content is last. The prompt order should always be: system prompt, tool definitions, few-shot examples, conversation history, and current user message. Do not add timestamps or request IDs at the top of the system prompts, and avoid adding dynamic messages that change per-request. In multi-task architectures, these will limit the prefix-aware router from correctly routing the request.
Prompt caching only caches input prompt prefixes, not model outputs. Each response is still generated fresh. As a separate application-layer optimization at high scale, an exact-match response cache (like Redis) can be used to skip inference entirely for identical repeated requests at temperature zero. A semantic cache using embeddings can extend this to near-duplicate prompts. It can also be pragmatic to add a limited lifetime (TTL) parameter to your cache that is set by the user during inference.
Conclusion
For most teams, the right call right now is session affinity with strong engine-level prefix reuse and careful prompt structure. But the shared cache layer is coming, and the teams that will benefit most from it are the ones who’ve already structured their prompts and routing logic to take advantage of it. The architecture decisions you make at two replicas will determine how much you capture when that layer becomes available.
About the author
Andrew is an NLP Scientist with 8 years of experience designing and deploying enterprise AI applications and language processing systems.
Related Articles

Built for Mass Scale: Hard-Won Lessons from Teams Running High Volume Inference Workloads in Production
- July 2, 2026
- 5 min read
Run Codex in the cloud – DigitalOcean for Codex is now available
- June 25, 2026
- 3 min read

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read