Your Model Doesn't Matter. Your Infrastructure Does.
By adagonese and Amit Jotwani
- Published:
- 7 min read
Everyone calling an LLM API has access to the same models. So what actually sets technical teams apart?
It’s everything around the model like the routing logic, the live data pipelines, and the ability to scale from prototype to production without ever rewriting your code. Which LLM tops a benchmark matters less than what becomes possible when infrastructure stops being an afterthought, when one platform owns the full stack from GPU to API.
Our Deploy 2026 session walked through this with live demos: serverless inference with web search and MCP tools added in a few lines, a break-even calculator for serverless versus dedicated, and a router built in the console in two minutes that cut costs by ~80% across a batch of eight support tickets. Moving between serverless, dedicated, and routed setups didn’t require re-platforming, rewriting code, or switching providers, which is where most inference setups leave money on the table.
Watch the full talk below, or keep reading for the rundown.
Key takeaways from the Deploy Session:
- Models are increasingly a commodity. What sets teams apart now is everything around the model: routing, data access, observability, and cost control. Choosing a model is no longer the hard part.
- The infrastructure you start with should scale with you. The workflow should not force you to re-platform, renegotiate contracts, or rewrite code at every growth milestone.
- DigitalOcean owns its GPUs, networks, and data centers. As efficiency improves, your cloud bill decreases. As the hardware gets better, your workloads run faster.
Your AI journey in three stages
Most AI workloads move through three stages. You start small and serverless, you grow into dedicated GPUs when volume justifies it, and somewhere along the way, you want a router making per-request decisions for you.
On most platforms, each of those stages means a new product, a new API, and a new contract. On DigitalOcean, there are three configurations of the same platform. The code you write on day one still works on day five hundred.

Mode 1 - Serverless: One API key, many models
For teams getting started, DigitalOcean’s serverless inference is the obvious entry point. One API key. One endpoint. Fifty-plus models. It’s OpenAI-compatible, which means your existing code works on day one: no rewrites, no migrations.
-
Per token billing, where you only pay for what you use
-
Proprietary models (GPT-5.2, Claude Opus 4.7) and open weights (Llama 4, Mistral, DeepSeek) under one roof
-
Pricing from $0.05 to $25 per million tokens across cost, latency, and capability tiers
Built-in MCP tools connect models to real services like your DigitalOcean account, knowledge bases, and third-party APIs with no integration code

Mode 2 - Dedicated GPUs: Private endpoint, your GPUs
For most apps, serverless will do just fine. But there are cases where sometimes you need more. If you’re running an expensive model at high volume, at some point, paying per hour instead of per token starts to make more sense. That’s where dedicated inference comes in.
You get your own GPU. Private endpoint. Predictable hourly pricing. Nobody else shares your hardware. And switching from serverless to dedicated? It’s two lines of code.

The GPU fleet
DigitalOcean’s GPU lineup spans AMD and NVIDIA, from the MI300X and MI350X for large model inference to the H100, H200, and B300 for training and long-context reasoning. Pick your model, pick your GPU, pick a region. You can find the full fleet details in the GPU docs.

When should you use dedicated inference versus serverless inference for your workload?
The math comes down to three variables:
-
The model you are running
-
The GPU you would move it onto
-
Your requests per hour.
On serverless, you pay per token. Every request costs you based on how many tokens go in and come out, multiplied by that model’s per-token rate. On dedicated, you pay a flat hourly rate for the GPU regardless of how much you use it. The question is: at what request volume does the flat hourly rate become cheaper than the accumulated per-token cost?
The break-even is not a single number. It shifts based on which model you are running and which GPU you would move it onto. Running Claude Opus 4.7 at $5 per million tokens against an AMD MI300X at $1.99 per hour, the break-even lands at around 234 requests per hour. Below that, serverless wins. Above it, dedicated pulls ahead because the per-token cost compounds faster than the hourly rate.
The variables shift that number significantly. A cheaper model like GPT-oss-120b at $0.10 per million tokens has a much higher break-even because each request costs so little on serverless. A more expensive model on the same GPU tips toward dedicated much sooner. A more powerful GPU at $7.99 per hour needs far higher throughput to justify the cost compared to the MI300X at $1.99.
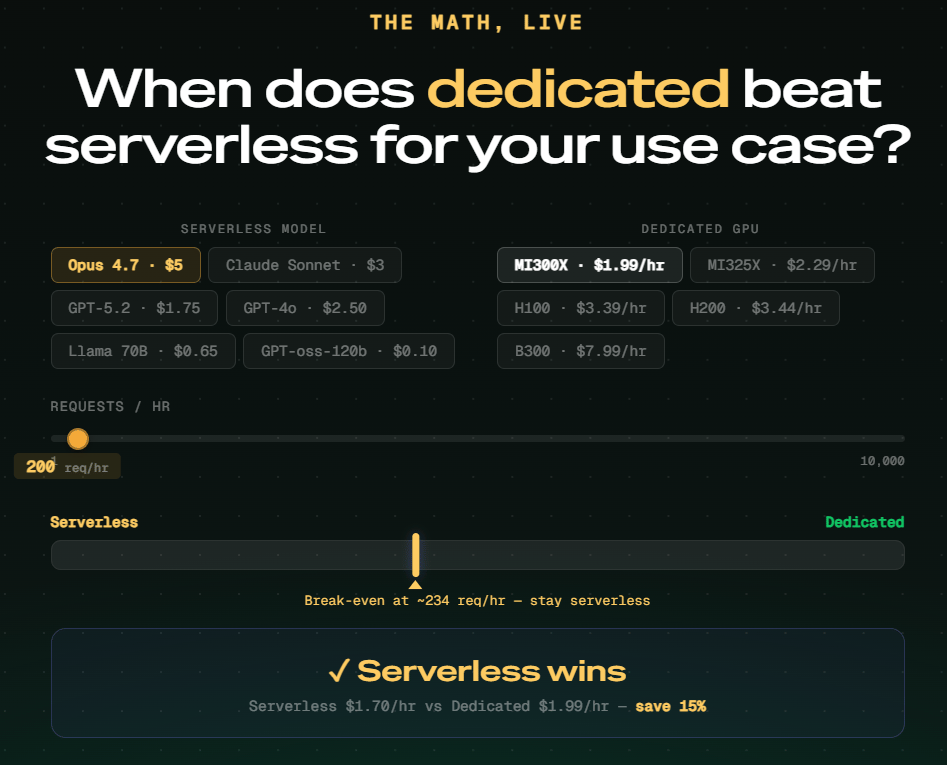
The practical starting point: start serverless, watch your request volume, and move to dedicated when the math works for your model and traffic combination.
What does the router save you in practice?

The same code generation prompt was run through two paths simultaneously during the session:
-
Direct to Claude Opus 4.7: $0.00556 and 3.9 seconds
-
Via the Inference Router (routed to openai-gpt-oss-20b): $0.00019 and 3.3 seconds
The router selected a lighter model for a task that did not need a frontier model, automatically, within the same API call. No code change. No manual model selection. 97% cheaper and faster.
Mode 3 - Inference routing: The platform picks for you
You’ve got options: multiple models, serverless inference, and dedicated inference. But every request is different. A password reset doesn’t need the same model as a code review. You shouldn’t be making that decision for every request. So who decides? That’s the DigitalOcean Intelligent Router.
The router operates in this order:
-
The router reads the incoming prompt.
-
The router matches the prompt against the tasks you’ve configured.
-
The router picks the right model from the pool of options and automatically applies your selection policy.
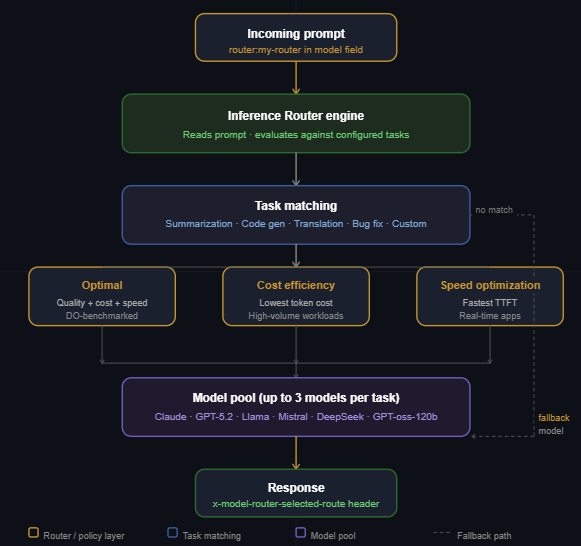
It works as a drop-in replacement for any direct model call. The router gives you three policies to choose from: Optimal for the best balance of quality, cost, and speed using DigitalOcean’s own benchmarking; Cost Efficiency for high-volume workloads where you want to avoid paying frontier model rates for tasks that don’t need them; and Speed Optimization for real-time, latency-sensitive apps where response time matters most.
Beyond the policy, the router handles the operational stuff that usually falls on you. Pre-configured task presets cover the most common workflows so you’re not starting from scratch. Custom tasks let you define your own. Fallback models make sure no request gets dropped. Model Affinity keeps agentic loops pinned to the same model across turns, which cuts input token costs by 45 to 80% in long sessions. And the Analyze tab gives you visibility into every routing decision after the fact.

Mix and match, no lock-in
On most inference platforms, every growth milestone forces a switch: new provider, new API, new contract. The serverless setup that worked on day one stops making sense once workloads vary, and per-token billing stops making financial sense once traffic is sustained.
DigitalOcean treats those milestones as building blocks rather than a progression. Serverless, dedicated, and the router combine in whatever mix fits your workload, on the same API format and the same bill, with no migration in between.
Day 1: Serverless - You’re building. You’re not thinking about GPUs. One endpoint, 50+ models, pay per token. The fastest way to go from idea to a working AI application without infrastructure overhead, with no upfront commitment. Just ship.
Day 50: Serverless + Router - Your workloads are getting varied. Some requests need a frontier model; most don’t. The Intelligent Router steps in and picks the best model per request automatically, still per token, but now every token is working harder. You get smarter cost allocation without changing a single line of application code.
Day 500: Dedicated + Router - Volume has tipped the math. Core traffic moves to dedicated GPU instances at predictable hourly pricing. Overflow and bursty traffic stay on serverless. The router handles the split automatically. You don’t manage it, you don’t think about it. It just works.

Model selection is a moving target. Different requests want different models, and the lineup itself keeps changing every few months. The infrastructure underneath that decision is something you live with every day. That means through every request, every scaling milestone, and every contract renewal. Building on a platform that treats inference as one continuous surface rather than a series of products to graduate between means the choices you make on day one don’t become the constraints you fight on day five hundred.
Start and scale with DigitalOcean
From your first API call to GPUs handling millions of requests, DigitalOcean Inference Engine is one platform, one bill, and one team. As your workloads grow, your infrastructure grows with you without vendor switches, no contract renegotiations, no code rewrites, and no migration headaches at every milestone.
About the author(s)
Amit is a Developer Advocate at DigitalOcean 🐳, where he helps developers build and ship better apps on the cloud. Compulsive Seinfeld quoter. LEGO nerd. 🧱 AMA.
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read