AI/ML Technical Content Strategist

NVIDIA GPUs (Graphics Processing Units) are powerful machines capable of performing numerous computations in parallel across hundreds to thousands of discrete computing cores. With the release of The Hopper microarchitecture last year, the NVIDIA H100 is among the most powerful, single computers ever made available to consumers, greatly outperforming the predecessor Ampere machines. With each microarchitecture, a term for the instruction set architecture of the processor, release, NVIDIA has introduced a substantial improvement in VRAM capacity, CUDA cores, and bandwidth over the previous generation. While the powerful Ampere GPUs, notably the A100, ushered in the AI revolution over the past 2 years; we have seen Hopper GPUs take this development rate to unprecedented levels of growth.
In this article, we will discuss and preview some of the incredible advancements in the latest and greatest Data Center GPU from Nvidia: the Hopper series H100.
Key takeaways:
- The NVIDIA H100 is a cutting-edge data center GPU based on the Hopper architecture, designed for AI and high-performance computing, and it delivers unprecedented compute power with innovations like 4th-generation Tensor Cores and a specialized Transformer Engine to accelerate large language model training.
- With up to 80 GB of ultra-fast HBM3 memory and support for new data types (such as FP8 along with FP16/FP32 precision), the H100 significantly increases memory bandwidth and computational throughput over its predecessor (the A100), enabling faster training and inference for very large neural networks.
- The H100 also introduces enhanced connectivity and efficiency features—such as higher-bandwidth NVLink for multi-GPU scaling and improved Multi-Instance GPU (MIG) capabilities to partition the GPU into smaller independent instances—making it a versatile solution that can handle both massive workloads and multitasking scenarios in enterprise AI deployments.
- As one of the most powerful GPUs available, NVIDIA H100 is used for cutting-edge applications like training state-of-the-art language models, running complex scientific simulations, and powering advanced cloud AI services, where its advanced hardware dramatically reduces time-to-results compared to previous generations.
Prerequisites
The content of this article is highly technical. We recommend this piece to readers experienced with both computer hardware and basic concepts in Deep Learning.
Machine Overview: NVIDIA H100
The NVIDIA H100 Tensor Core GPU represents a developmental step forward from the A100 in a number of key ways. In this section, we will break down some of these advancements in the context of Deep Learning utility.
To begin, the H100 has the second highest Peripheral Component Interconnect express (PCIe) card Memory Bandwidth, other than the more recent H200, of any commercially available GPU. At over 2 TB/s, the model is capable of loading and working with the largest datasets and models using its 80GB of VRAM at extremely high speeds. This gives the NVIDIA H100 exceptional performance, especially for large scale AI applications.
This incredible throughput is made possible through the 4th generation Tensor Cores of the H100, which are an order of magnitude leap from older GPUs. The H100 features an impressive 640 Tensor Cores and 128 Ray Tracing Cores, which facilitates the high-speed data processing signature to the machine. These supplement the 14592 CUDA cores to achieve an incredible 26 teraFLOPS on full precision (fp64) procedures.
Furthermore, the NVIDIA H100 Tensor Core technology supports a broad range of math precisions, providing a single accelerator for every compute workload. The NVIDIA H100 PCIe supports double precision (FP64), single-precision (FP32), half precision (FP16), and integer (INT8) compute tasks” (Source).
New Features in Hopper GPUs
There are a number of notable upgrades to the Hopper Microarchitecture, including improvements to the Tensor Core technology, the introduction of the Transformation Engine, and much more. Let’s look more closely at some of the more noticeable upgrades.
Fourth-Generation Tensor Cores with the Transformer Engine
Arguably the most important update for Deep Learning or Artificial Intelligence users, the Fourth-Generation of Tensor Cores promises incredible acceleration of up to 60x for peak performance efficiency from the Ampere Tensor Core release. To achieve this, NVIDIA has released the Transformer Engine. The dedicated transformer engine is a core component of each Tensor Core designed to accelerate models built with the Transformer block in their architecture, allowing for computation to occur dynamically in mixed FP8 and FP16 formats.

Since Tensor Core FLOPs in FP8 are twice that of 16-bit, it is highly desirable to run Deep Learning models in these formats to reduce cost. However, this can reduce the precision of the model significantly. The Transformer Engine innovation has made it possible to compensate for the loss in precision from using FP8 computer format while still benefiting massively from the throughput increase of FP16. This is possible because the Transformer Engine is able to dynamically switch between formats at each layer of the model, as needed. (Figure 1) Furthermore, “the NVIDIA Hopper architecture in particular also advances fourth-generation Tensor Cores by tripling the floating-point operations per second compared with prior-generation TF32, FP64, FP16 and INT8 precisions” (Source).
Second-Generation Secure MIG

MIG or Multi Instance GPU is the technology that allows for a single GPU to be partitioned into fully contained and isolated instances, with their own memory, cache, and compute cores (Source). In H100s, second generation MIG technology enhances this even further by enabling the GPU to be split into seven, secure GPU instances with multi-tenant, multi-user configurations in virtual environments.
In practice, this allows for the facilitation of GPU sharing with a high degree of built-in security, and is one of the key features that makes H100s so great for users on the cloud. Each of the instances has dedicated video decoders which serve to deliver intelligent video analytics (IVA) about the shared infrastructure directly to the monitoring systems, and administrators can monitor and optimize resource allocations to users using Hopper’s concurrent MIG profiling.
Fourth-Generation NVLink & Third-Generation NVSwitch
NVLink and NVSwitch are the NVIDIA GPU technologies that facilitate the connection of multiple GPUs to one another in an integrated system. With each subsequent generation, these technologies have only improved further and further. NVLink is the bidirectional interconnect hardware that allows GPUs to share data with one another, and NVSwitch is a chip that facilitates the connections between different machines in a multi-GPU system by connecting the NVLink interconnect interfaces to the GPUs.
In H100s, Fourth-generation NVLink effectively scales multi-instance GPU IO interactions up to 900 gigabytes per second (GB/s) bidirectional per GPU, which is estimated to be over 7X the bandwidth of PCIe Gen5 (Source). This means that GPUs are able to input and output information to one another at significantly higher speeds than was possible with Ampere, and this innovation is responsible for many of the reported speed ups being offered by H100 multi-GPU systems in marketing materials.
Next, Third-generation NVIDIA NVSwitch supports Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) in-network computing, and provides a 2X increase in all-reduce throughput within eight H100 GPU servers compared to the previous-generation A100 Tensor Core GPU systems (Source). In practical terms, this means that the newest generation of NVSwitch is able to more effectively and efficiently oversee the operations across the multi-GPU system, allocate resources where needed, and increase throughput dramatically on DGX systems.
Confidential Computing
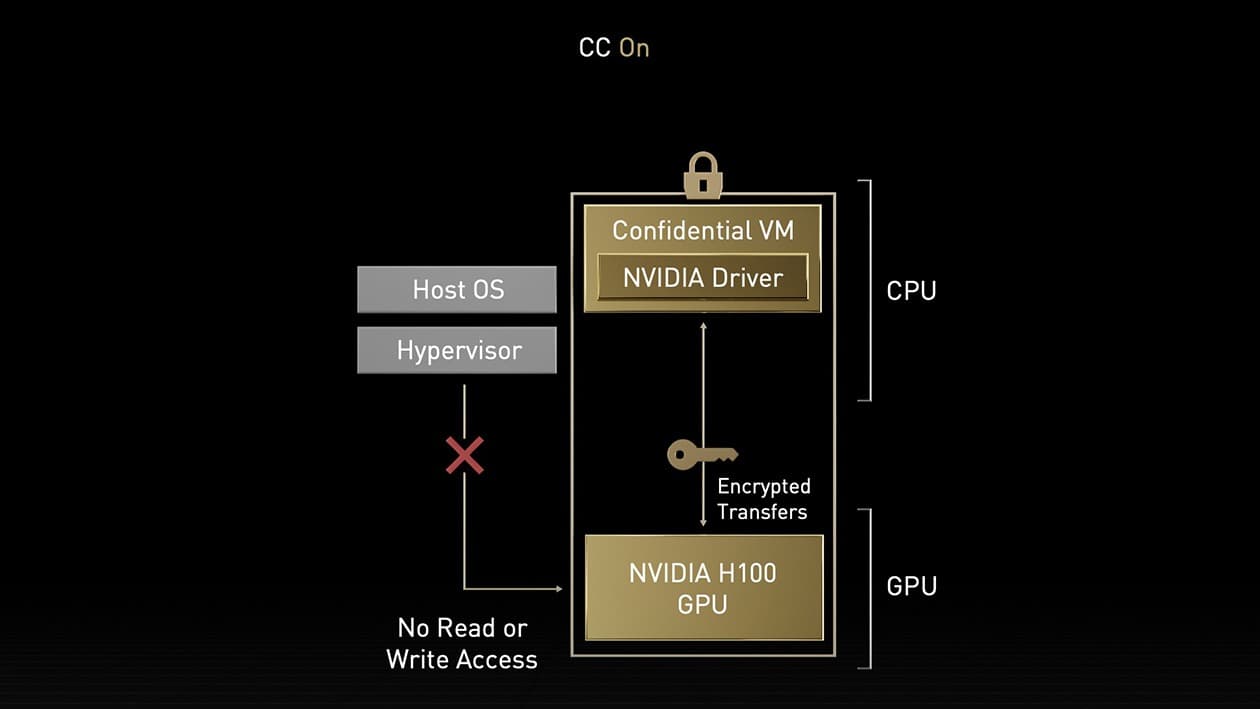
A common concern in the era of Big Data is security. While data is often stored or transferred in encrypted formats, this provides no protection against bad actors who can access the data while being processed. With the release of the Hopper microarchitecture, NVIDIA introduced a novel solution to this problem: Confidential Computing. This effectively removes much of the risk of data being stolen during processing by creating a physical data space where workloads are processed independently of the rest of the computer system. By processing all the workload in the inaccessible, trusted execution environment, it makes it much more difficult to access the protected data.
H100 vs A100
The NVIDIA H100 represents a notable step forward in every way from its predecessor, the A100. These improvements go deeper than the inclusions of the new technologies we discussed earlier, but also include general quantitative improvements to the processing power capable by a single machine.
Info: Experience the power of AI and machine learning with DigitalOcean GPU Droplets. Leverage NVIDIA H100 GPUs to accelerate your AI/ML workloads, deep learning projects, and high-performance computing tasks with simple, flexible, and cost-effective cloud solutions.
Sign up today to access GPU Droplets and scale your AI projects on demand without breaking the bank.
Let’s see how the H100 and A100 compare in terms of pertinent GPU specifications:
| GPU Features | NVIDIA A100 | NVIDIA H100 PCIe1 |
|---|---|---|
| GPU Architecture | NVIDIA Ampere | NVIDIA Hopper |
| GPU Board Form Factor | SXM4 | PCIe Gen 5 |
| SMs | 108 | 114 |
| TPCs | 54 | 57 |
| FP32 Cores / SM | 64 | 128 |
| FP32 Cores / GPU | 6912 | 14592 |
| FP64 Cores / SM (excl. Tensor) | 32 | 64 |
| FP64 Cores / GPU (excl. Tensor) | 3456 | 7296 |
| INT32 Cores / SM | 64 | 64 |
| INT32 Cores / GPU | 6912 | 7296 |
| Tensor Cores / SM | 4 | 4 |
| Tensor Cores / GPU | 432 | 456 |
| GPU Boost Clock (Not finalized for H100)3 | 1410 MHz | Not finalized |
| Peak FP8 Tensor TFLOPS with FP16 Accumulate1 | N/A | 1600/32002 |
| Peak FP8 Tensor TFLOPS with FP32 Accumulate1 | N/A | 1600/32002 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 | 312/6242 | 800/16002 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 | 312/6242 | 800/16002 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 | 312/6242 | 800/16002 |
| Peak TF32 Tensor TFLOPS1 | 156/3122 | 400/8002 |
| Peak FP64 Tensor TFLOPS1 | 19.5 | 48 |
| Peak INT8 Tensor TOPS1 | 624/12482 | 1600/32002 |
| Peak FP16 TFLOPS (non-Tensor)1 | 78 | 96 |
| Peak BF16 TFLOPS (non-Tensor)1 | 39 | 96 |
| Peak FP32 TFLOPS (non-Tensor)1 | 19.5 | 48 |
| Peak FP64 TFLOPS (non-Tensor)1 | 9.7 | 24 |
| Memory Size | 40 or 80 GB | 80 GB |
| Memory Bandwidth1 | 1555 GB/sec | 2000 GB/sec |
(Source)
First, as we can see from the table above, the H100 has a slightly higher count of Streaming Multiprocessors (SM) and TPC (Texture Processing Centers) than the A100, but a significantly higher count of tensor cores for each computer number format and on each SM. The H100 actually has double the number of FP32 cores per SM as the A100, over double the FP64 cores per SM, around 300 additional INT32 cores, and an additional 24 Tensor Cores. In practice, these increases translate directly to each processing unit in the H100 individually being much more powerful than the comparative apparatus in the A100.
It is apparent that this directly effects the metrics which correlate to processing speed, namely the peak performances across different computer number formats and the memory bandwidth itself. Regardless of context, the H100 outperforms the A100. Furthermore, the extension of capabilities to FP8 with FP16 or FP32 gradient accumulation with the Transformer Engine means it is possible to perform mixed precision computations the A100 would not be able to handle. This translates to a direct increase of nearly 450 GB/sec to the memory bandwidth, which measures the volume of data that can be transferred across a machine in GB/sec.

Putting this in the context of training Large Language Models, the cumulative improvements in the H100 allow for a reported 9x speedup on training and 30x increase on inference throughputs, respectively.
When to use the NVIDIA H100
As we have shown in this H100 breakdown, the H100 represents a step forward in every direction for NVIDIA GPUs. In every use case, it outperforms the previous best in class GPU (A100) at a relatively minimal increase to power draw, and it is able to work on a wider variety of number formats in mixed precision to boost this performance even further. This is apparent both from the novel technologies in Hopper GPUs, the improvements to existing technologies, and the general increase to the amount of available computing units on the machine.
The H100 represents the apex of current GPUs, and is designed for wide range of use cases. It has exceptionally powerful performance and we recommend it for anyone looking to train artificial intelligence models and perform other tasks that require a GPU.
FAQ’s
Q: H100 vs A100 vs RTX 4090: which GPU to choose for AI development in 2025?
Choose H100 for cutting-edge research, large language model training, and maximum performance with 80GB HBM3 memory and specialized Transformer Engine - ideal when budget isn’t constrained. A100 offers excellent price-performance for most enterprise AI workloads with 40-80GB memory options and broad software support. RTX 4090 provides outstanding value for individual developers and small teams with 24GB memory, supporting most modern AI workloads at significantly lower cost. For 2025 development, RTX 4090 suits most projects, A100 for production deployments, and H100 for state-of-the-art research requiring maximum capability.
Q: What are the real-world performance benchmarks for H100 in AI training?
H100 performance benchmarks show substantial improvements over previous generations: 2-3x faster training for large language models compared to A100, with GPT-3 style models training in days rather than weeks. Computer vision tasks see 2-4x speedups for ResNet and EfficientNet training. The specialized Transformer Engine provides up to 6x improvements for attention-heavy architectures. FP8 precision support enables larger models to fit in memory while maintaining accuracy. Multi-GPU scaling efficiency reaches 90%+ for well-optimized workloads. Real applications report 40-60% reduction in training time and costs, with some transformer workloads achieving 80% time reduction through architectural optimizations.
Q: How much does it cost to run H100 GPUs for AI training and inference?
H100 costs vary significantly by deployment method: Cloud providers charge $2-4 per hour for H100 instances (AWS P5, Google Cloud A3), making it expensive for long training runs but cost-effective for short experiments. On-premises H100 cards cost $25,000-40,000 with additional infrastructure requirements. For cost optimization, use spot instances for fault-tolerant training, implement efficient batching and model parallelism, and consider mixed approaches using H100 for critical training phases and cheaper GPUs for development. Total cost of ownership includes power, cooling, and management overhead. Many organizations find cloud deployment more economical for sporadic usage and on-premises for consistent heavy workloads.
Q: What are the power and cooling requirements for H100 deployment?
H100 power and cooling requirements are substantial: Each H100 SXM5 module consumes up to 700W under full load, requiring robust power delivery and cooling infrastructure. Data center deployments need 1000W+ per GPU including system overhead. Cooling requires liquid cooling solutions or high-performance air cooling with significant airflow. Power infrastructure must support high-density configurations with appropriate redundancy. Typical 8-GPU systems require 8-10kW power capacity and industrial-grade cooling solutions. Plan for additional infrastructure costs including PDUs, cooling systems, and monitoring equipment. Many organizations leverage cloud providers to avoid infrastructure complexity and capital expenditure.
Q: How to optimize software for H100 Tensor Cores and Transformer Engine?
Optimizing for H100 requires leveraging its specialized features: Use FP8 precision where supported for maximum Transformer Engine benefits. Implement attention optimization techniques like FlashAttention for memory efficiency. Ensure tensor dimensions align with Tensor Core requirements (multiples of 8, preferably 16+). Use mixed precision training with appropriate loss scaling. Leverage specialized libraries like FasterTransformer and DeepSpeed for optimized transformer implementations. Implement efficient data loading to prevent GPU starvation.
Closing Thoughts
The H100 is the gold standard for GPUs today. While the incipient proliferation of the newest generation, Blackwell, of NVIDIA GPUs will soon reach the cloud, the H100 and its beefy cousin the H200 remain the best available machines for any Deep Learning task. For those who want to try on-demand H100s themselves, sign up for DigitalOcean’s GPU Droplets today.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
