AI/ML Technical Content Strategist

At DigitalOcean, we have strived to bring our users the best and latest technologies to our cloud. This has extended from basic cloud services like storage all the way to our incredible DigitalOcean AI Platform.
Powering our AI systems are some of the most potent GPUs available, such as the NVIDIA H200 or the AMD MI350X. But these technologies are always developing further, with physical releases more potent than the last by substantial metrics with each generation of technological advancements.
NVIDIA is an excellent example of where this is happening. Last year, we covered their NVIDIA Hopper H100 and NVIDIA H200 GPUs in detail on this platform. NVIDIA has since released an even newer microarchitecture: NVIDIA Blackwell. Blackwell boasts impressive improvements over Hopper in several notable ways, but the first and foremost is the creation of the NVIDIA DGX B300 GPU. One of the most powerful pieces of hardware ever made for sale to the consumer, the NVIDIA DGX B300 “is the powerhouse for AI innovators, delivering the hyperscaler performance needed to build a modern AI factory” (Source).
In this tutorial, we will look at the NVIDIA DGX B300 in detail, outlining its technical specifications, breaking down its key new features, and finally concluding with a discussion on when the best time to use the NVIDIA B300 might be. Follow along for a detailed look at one of the hottest new pieces of AI technology - coming soon to DigitalOcean!
Machine Overview: NVIDIA B300
In this section, we will look at the NVIDIA DGX B300 in detail. First we will look at the component architecture and hardware that makes the NVIDIA DGX B300 so powerful. Next, we will look at the new features of its component GPUs and the Blackwell microarchitecture that enhances the machine over previous generations even further.
NVIDIA B300 Hardware Specs and Architecture Overview
| Category | Specification |
|---|---|
| System | NVIDIA DGX B300 |
| GPUs | 8× NVIDIA Blackwell Ultra SXM |
| CPU | Intel® Xeon® 6776P Processors |
| Total GPU Memory | 2.1 TB |
| Performance | FP4 Tensor Core: 144 PFLOPS (sparse) | 108 PFLOPS (dense) FP8 Tensor Core: 72 PFLOPS (sparse) |
| NVIDIA NVLink™ Switch System | 2× |
| NVIDIA NVLink Bandwidth | 14.4 TB/s aggregate bandwidth |
| Networking | 8× OSFP ports (8× single-port NVIDIA ConnectX-8 VPI, up to 800 Gb/s InfiniBand/Ethernet) 2× dual-port QSFP112 NVIDIA BlueField-3 DPU (up to 400 Gb/s InfiniBand/Ethernet) |
| Management Network | 1GbE onboard NIC with RJ45 1GbE RJ45 Host BMC |
| Storage | OS: 2× 1.9 TB NVMe M.2 Internal: 8× 3.84 TB NVMe E1.S |
| Power Consumption | ~14 kW |
| Software | NVIDIA AI Enterprise NVIDIA Mission Control (with NVIDIA Run:ai) NVIDIA DGX OS |
| Operating System Support | Red Hat Enterprise Linux, Rocky Linux, Ubuntu |
| Rack Units | 10U |
| Support | Three-year business-standard hardware and software support |
Let’s take a look at just what technical components comprise the NVIDIA Blackwell DGX B300. At its core are 8 NVIDIA Blackwell Ultra SXM GPUs paired with Intel® Xeon® 6776P Processors. This combines for a total 2.1 TB of Total GPU memory (288 GB of HBM3e memory each). The performance is an awesome 144 PFLOPS (sparse) and 108 PFLOPS (dense) for FP4 Tensor Core calculations, and for FP8 Tensor Core: 72 PFLOPS (sparse). All of this is carried by a massive 14.4 TB/s bandwidth. Finally, it only requires a (admittedly still high) ~14 kW to run.
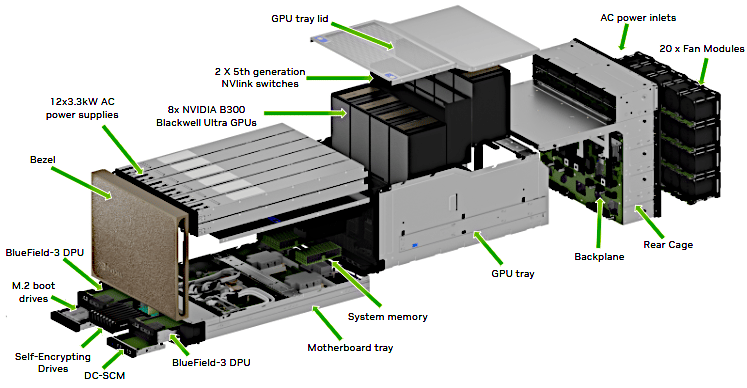
Let’s take a look at an exploded view of the NVIDIA DGX B300, shown above. Here we can see attached to the front bezel are 12 3.3 kW AC PSUs, above the GPU tray. This holds 8 of the individual, component Blackwell Ultra SXM GPUs. These are slotted above the system memory. At the front, below the bezel, are 2 BlueField 3 DPUs, M.2 Boot Drives, Self-Encrypting Drives, and a DC-SCM. At the back of the unit is a backplane with 20 attached AC Units and inputs for AC power. Image above sourced from here.
Features of the NVIDIA B300
In this section, we will outline some of the features of Blackwell GPUs and the B300 specifically that we think highlight the potential of this machine.
NVFP4 Quantization
4-bit quantization reduces the numerical precision of model weights and activations to just four bits, a significant decrease from the standard 16-bit or 32-bit floating-point representations. With Blackwell GPUs, we can process inference and training loads at this low computer number format. This allows for an exponential increase in training inference times with minimal loss in capability. For more details on how NVFP4 is revolutionizing AI training loads, check out this article from NVIDIA.
Second-Generation Transformer Engine
The second-generation NVIDIA Transformer Engine pairs Blackwell-class Tensor Core hardware with software advances in NVIDIA TensorRT-LLM and the NeMo Framework to significantly boost both training and inference performance for large language models and Mixture-of-Experts architectures. Built on NVIDIA Blackwell Ultra Tensor Cores, the platform delivers roughly twice the acceleration in attention layers and 1.5× higher overall AI compute throughput compared to standard Blackwell GPUs. These Tensor Cores introduce new precision modes, including community-defined microscaling formats, which enable seamless substitution for higher-precision data types while preserving numerical fidelity. By applying fine-grained micro-tensor scaling, the Blackwell Transformer Engine efficiently supports 4-bit floating-point (FP4) computation, allowing models to run faster and scale to larger sizes within the same memory footprint, all while maintaining high accuracy. (needs paraphrasing)
Decompression Engine
Historically, data analytics and database workloads have been dominated by CPU-based processing, but GPU-accelerated data science can significantly improve end-to-end performance by shortening time-to-insight and lowering overall costs. Modern analytics platforms and databases—such as Apache Spark—are foundational for ingesting, transforming, and querying large-scale datasets. NVIDIA Blackwell enhances these workflows through its dedicated Decompression Engine and its ability to tap into the large memory pool of the NVIDIA Grace™ CPU via an ultra-fast interconnect delivering up to 900 GB/s of bidirectional bandwidth. Together, these capabilities accelerate the entire lifecycle of database queries and analytics operations, while providing native support for modern compression standards including LZ4, Snappy, and Deflate, resulting in higher throughput and more efficient data processing.(needs paraphrasing)
Reliability, Availability, and Serviceability (RAS) Engine
Here is a single, fully rewritten paragraph with substantial wording changes while preserving technical accuracy: NVIDIA Blackwell introduces advanced system robustness through a dedicated Reliability, Availability, and Serviceability (RAS) Engine designed to detect emerging hardware and software issues before they impact operations. Leveraging AI-driven predictive management, the platform continuously analyzes thousands of telemetry signals across the system stack to assess overall health and proactively prevent failures, inefficiencies, and unplanned outages. The RAS Engine delivers detailed diagnostic insights that help pinpoint potential problem areas, enabling faster troubleshooting and more effective maintenance planning. By rapidly isolating faults and supporting targeted remediation, Blackwell’s intelligent resiliency capabilities significantly reduce downtime, operational overhead, and energy and compute waste. (Source)
Additional Features
| Feature | Description |
|---|---|
| GPU | 8 × NVIDIA B300 Blackwell Ultra GPUs |
| GPU Memory | 8 × 288 GB = 2.3 TB total |
| Performance | 72 PFLOPS FP8 (training) 144 PFLOPS FP4 (inference) |
| NVSwitch | 2 × 5th-generation NVIDIA NVLink™ interconnects |
| CPUs | 2 × Intel® Xeon® Platinum 6776P processors |
| System Memory | 2 TB default (up to 4 TB) |
| Networking Connectivity & Speed | 8 × OSFP ports connected to 8 × NVIDIA® ConnectX®-8 cards (cluster network) 8 × 800 Gb/s InfiniBand/Ethernet 2 × dual-port NVIDIA® BlueField®-3 DPUs (storage & management networks) 2 × 400 Gb/s InfiniBand/Ethernet |
| Cache Storage | 8 × E1.S 3.84 TB NVMe self-encrypting drives |
| Boot Storage | 2 × 1.92 TB M.2 NVMe (software-encryptable) |
| Host Management | On-board 1 GbE RJ-45 Ethernet |
| Remote System Management | Baseboard Management Controller (BMC) 1 GbE RJ-45 network connectivity Remote keyboard, video, mouse (KVM) Remote storage Redfish and IPMI management |
| Operating System | DGX OS 7 based on Ubuntu 24.04 LTS Additional support for Ubuntu, Red Hat Enterprise Linux 8 & 9, and Rocky Linux |
Powered by NVIDIA Blackwell Ultra GPUs, the DGX B300 is engineered as a unified platform for high-throughput large language model inference and training. With up to 144 petaFLOPS of inference performance, the system delivers hyperscale-class capabilities in an enterprise-ready form factor, enabling organizations of any size to deploy real-time, production-grade AI. Designed with flexibility in mind, DGX B300 offers multiple power configuration options and is optimized for exceptional performance per watt, positioning it as one of the most energy-efficient AI supercomputers available. Its redesigned architecture supports deployment in NVIDIA MGX racks for the first time, establishing a new infrastructure standard that simplifies modern data center integration while unlocking higher efficiency and scalability (Source).
At the core of this platform are NVIDIA Blackwell GPUs, each built with 208 billion transistors using a custom TSMC 4NP process and composed of dual reticle-limited dies connected by a unified 10 TB/s chip-to-chip interconnect. Blackwell also introduces industry-leading security through NVIDIA Confidential Computing, delivering hardware-enforced protection for sensitive data and AI models with minimal performance overhead. As the first GPU to support TEE-I/O, Blackwell enables secure training, inference, and federated learning while maintaining near-native throughput, even over protected NVIDIA NVLink connections. To support exascale-scale AI, fifth-generation NVIDIA NVLink enables fast, balanced communication across up to 576 GPUs. The NVLink Switch Chip provides up to 130 TB/s of bandwidth within a 72-GPU NVLink domain and extends that same 1.8 TB/s interconnect across multi-node clusters, delivering up to nine times the GPU throughput of a single eight-GPU system while maintaining communication efficiency with SHARP FP8 acceleration (Source).
When to use the NVIDIA B300
To summarize, this machine is one of the most powerful pieces of HPC technology ever created for the consumer. With that, we can make several key assumptions:
- First, as it is the most powerful consumer machine available today, it is also the best machine. That means that you can throw just about any problem at it, and it will reach a conclusion more quickly than any other machine.
- NVFP4 makes it the best machine for low-precision tasks like large pre-training jobs
- It is is notably more expensive to run than previous generation GPUs run today based on initial investment and energy requirements
Based on these assumptions, we can conclude that the NVIDIA B300 is an ideal GPU for almost every situation. We particularly recommend it when training or deploying particularly large AI models. The increased bandwidth and memory capacity of the B300 over all competition make it truly the best choice for dealing with any large model, in our opinion.
Closing Thoughts
As we broke down in this article, the NVIDIA B300 represents a clear inflection point in modern AI infrastructure. It brings together unprecedented compute density, massive memory capacity, and cutting-edge architectural advances that redefine what is possible for both training and inference at scale. While its power and cost profile place it firmly in the category of serious enterprise and research-grade hardware, for teams pushing the limits of model size, throughput, and latency, the B300 delivers unmatched capability per system.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
