By Amit Jotwani
Developer Educator
 with the OpenAI SDK")
DigitalOcean recently launched Serverless Inference - a hosted API that lets you run large language models like Claude, GPT-4o, LLaMA 3, and Mistral, without managing infrastructure.
It’s built to be simple: no GPU provisioning, no server configuration, no scaling logic to manage. You just send a request to an endpoint.
The API works with models from Anthropic, OpenAI, Meta, Mistral, Deep Seek, and others - all available behind a single base URL.
The best part is that it’s API-compatible with OpenAI.
That means if you’re already using tools like the OpenAI Python SDK, LangChain, or LlamaIndex, or any of the supported models, they’ll just work. You can swap the backend without rewriting your application.
This same approach works with DigitalOcean Agents too — models that are connected to your own documents or knowledge base.
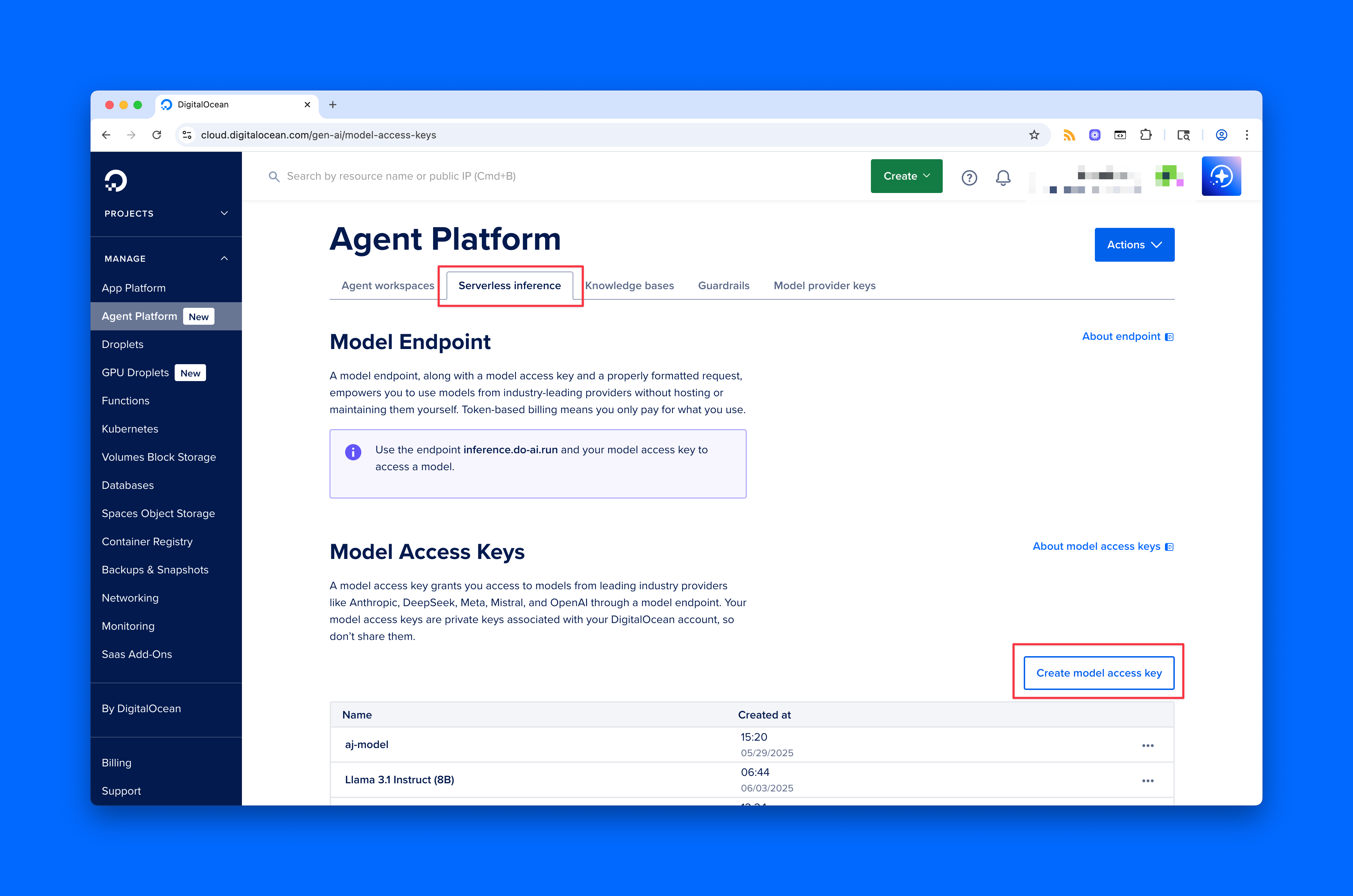
Why Use DigitalOcean Inference?
There are a few reasons this approach stands out—especially if you’re already building on DigitalOcean or want more flexibility in how you use large language models.
- One key for everything: You don’t have to manage separate keys for OpenAI, Anthropic, Mistral, etc. One DigitalOcean API key gives you access to every model—Claude, GPT-4o, LLaMA 3, Mistral, and more.
- Lower costs: For many workloads, this is significantly more cost-effective than going direct to the provider.
- Unified billing: All your usage shows up in one place. Everything shows up in your DO bill, alongside your apps, spaces, databases, whatever else you’re running on DO. No surprise charges across different platforms.
- Privacy for open models: If you’re using open-weight models (like LLaMA or Mistral), your prompts and completions aren’t logged or used for training.
- *No SDK changes: The OpenAI SDK just works. You can also use libraries like LangChain or LlamaIndex the same way—just change the base URL.
How it Works
Under the hood, everything runs through the OpenAI method:
client.chat.completions.create()
The only thing you need to change is the base_url when you initialize the client
- Serverless Inference (for general models):
https://inference.do-ai.run/v1/ - Agents (for context-aware inferencing over your own data):
https://.agents.do-ai.run/api/v1/
That’s it - let’s walk through how this looks in practice.
Install the OpenAI SDK
Run the following command to install the OpenAI SDK to your machine:
pip install openai python-dotenv
Example 1: List Available Models
This lists all available models from DigitalOcean Inference. Same code you’d use with OpenAI—you’re just pointing it at a DigitalOcean endpoint (base_url).
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# List all available models
try:
models = client.models.list()
print("Available models:")
for model in models.data:
print(f"- {model.id}")
except Exception as e:
print(f"Error listing models: {e}")
Example 2: Run a Simple Chat Completion
We’re using the same .chat.completions.create() method. Only the base_url is different.
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion
try:
response = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error during completion: {e}")
Example 3: Stream a Response
Want a response that streams back token by token? Just add stream=True, and loop through the chunks.
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion with streaming
try:
stream = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
],
stream=True
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # Add a newline at the end
except Exception as e:
print(f"Error during completion: {e}")
What about Agents?
DigitalOcean also offers Agents - these are LLMs paired with a custom knowledge base. You can upload docs, add URLs, include structured content, connect a DigitalOcean Spaces bucket or even an Amazon S3 bucket as a data source. The agent will then respond with that context in mind. It’s great for internal tools, documentation bots, or domain-specific assistants.
You still use .chat.completions.create() — the only difference is the base_url. But now your responses are grounded in your own data.
Note: With Inference, the base URL is fixed. With Agents, it’s unique to your agent, and you append /api/v1.
python
client = OpenAI(
base_url="https://your-agent-id.agents.do-ai.run/api/v1/",
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
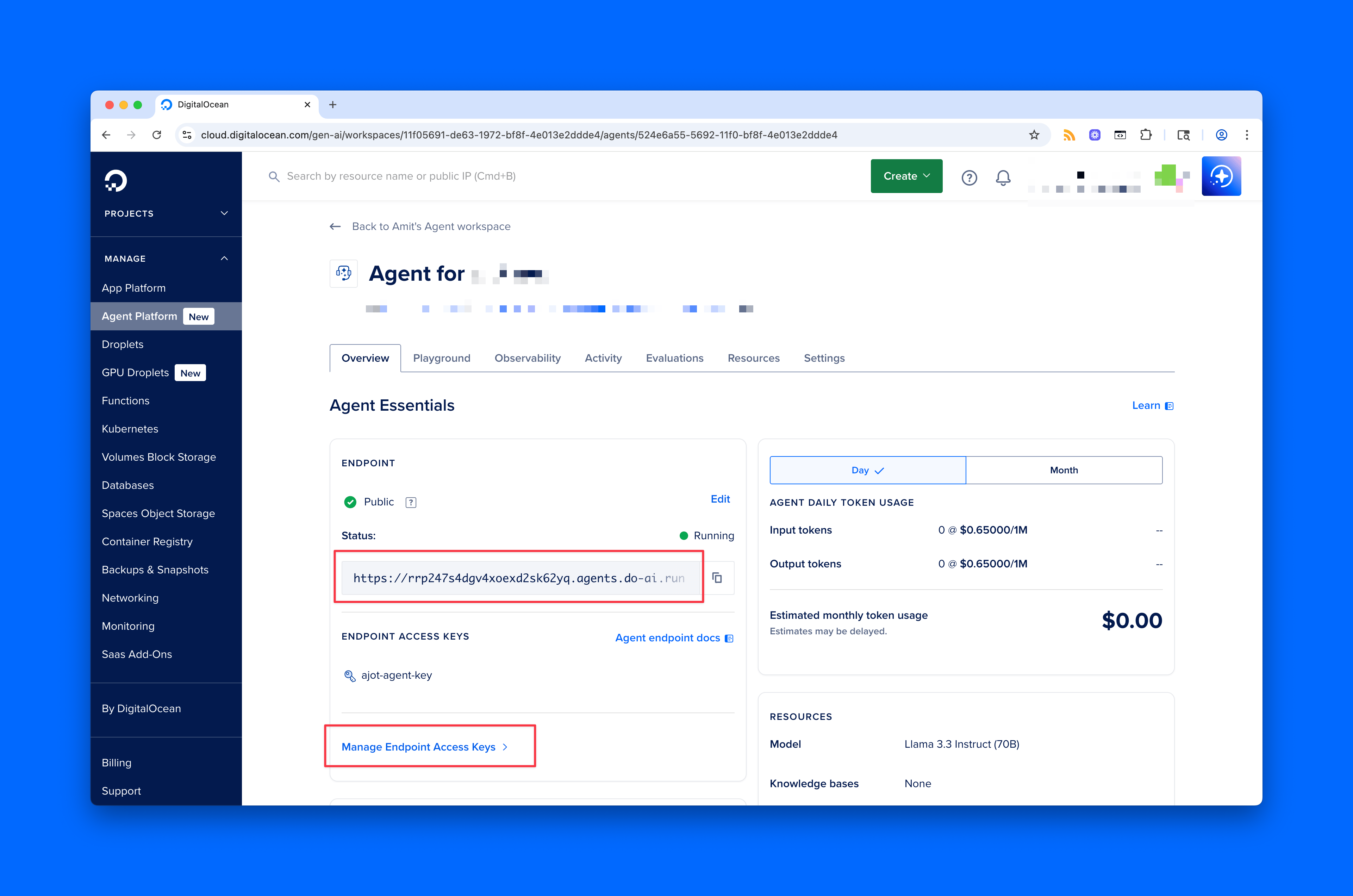
Example 4: Use an Agent (No Stream)
This is a standard Agent request using .chat.completions.create() - same method as before.
The only real change is the base_url, which points to your Agent’s unique endpoint (plus /api/v1). With Inference, the base URL is fixed. With Agents, it’s unique to your agent, and you just append /api/v1 to it.
Here we’ve also added include_retrieval_info=True to the body. This tells the API to return extra metadata about what the Agent pulled from your knowledge base to generate its response.
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# Create a new client with the agents endpoint
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# Try a simple text request with the agents endpoint
stream = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "Hello! WHo is Amit?"
}],
extra_body = {"include_retrieval_info": True}
)
print(f"\nAgents endpoint response: {agents_response.choices[0].message.content}")
for choice in response.choices:
print(choice.message.content)
response_dict = response.to_dict()
print("\nFull retrieval object:")
print(json.dumps(response_dict["retrieval"], indent=2))
except Exception as e:
print(f"Error with agents endpoint: {e}")
Example 5: Use an Agent (With Streaming and Retrieval)
The only change here is that we’ve enabled stream=True to get the response back as it generates. Everything else is the same.
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# Create a new client with the agents endpoint
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# Try a simple text request with the agents endpoint
stream = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "Hello! WHo is Amit?"
}],
extra_body = {"include_retrieval_info": True},
stream=True,
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # Add a newline at the end
except Exception as e:
print(f"Error with agents endpoint: {e}")
Conclusion
To recap:
- You can use the OpenAI SDK directly with DigitalOcean’s Serverless Inference and Agents.
- The only thing you need to change is the base_url—everything else stays the same.
- Use
https://inference.do-ai.run/v1/for general-purpose models like LLaMA 3, GPT-4o, Claude, etc.\ - Use your Agent’s URL (plus
/api/v1) to connect to your own docs or knowledge base. - Everything runs through
.chat.completions.create()—no new methods to learn. - You can enable streaming with
stream=True, and get retrieval info withinclude_retrieval_info=True.
This makes it easy to test multiple models, switch backends, or ground a model in your own content—all without changing your existing code.
Further Resources
- What is Serverless Inference?: A simple overview of how Serverless Inference works and where it fits.
- How to Use Serverless Inference: Documentation for Serverless Inference
- List of Supported Models: Full breakdown of all models available (OpenAI, Claude, LLaMA, Mistral, etc.).
- Create and Configure a DigitalOcean Agent: Walkthrough for building agents that respond using your own knowledge base.
- Inference API Reference: Schema, endpoints, and everything under the hood.
- OpenAI Python SDK: The official SDK this entire guide is built on.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Amit is a Developer Advocate at DigitalOcean 🐳, where he helps developers build and ship better apps on the cloud. Compulsive Seinfeld quoter. LEGO nerd. 🧱 AMA.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
How about image inputs?
Error at "/messages/0/content": doesn't match schema due to: value must be a string
Schema:
{
"description": "The text contents of the message.",
"title": "Text content",
"type": "string"
}
Value:
[
{
"text": "What's in this image?",
"type": "text"
},
{
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
},
"type": "image_url"
}
]
Or Error at "/1": doesn't match schema due to: value must be a string
Schema:
{
"description": "Text content as a string",
"type": "string"
}
Value:
{
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
},
"type": "image_url"
}
Or Error at "/type": value is not one of the allowed values ["text"]
Schema:
{
"description": "The type of content part",
"enum": [
"text"
],
"type": "string"
}
Value:
"image_url"
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
