Scaling Autonomous Site Reliability Engineering: Architecture, Orchestration, and Validation for a 90,000+ Server Fleet
By Najmus Saqib
- Updated:
- 6 min read
As Cloudways scaled from a bootstrapped startup to a leading managed PHP hosting service, one of the biggest challenges we encountered was the growing support load. Managing a fleet of over 90,000 servers and half a million applications means thousands of support requests, requiring a team of hundreds of human support agents. The rise of LLMs and AI agents provided an ideal opportunity to rethink our support operations. Early on, we recognized that an AI-based SRE agent could significantly reduce the burden on our support teams.
At Cloudways, we deeply care about our customers’ applications and websites because they are the backbone of their businesses and livelihoods. Every minute of downtime matters, and our priority has always been to ensure their apps come back online as quickly as possible. An AI SRE agent helps customers to receive timely, in-depth investigation and troubleshooting for their web applications delivering faster diagnosis and quicker resolution.
Cloudways Copilot, an AI-powered Site Reliability Engineer in its current state is a result of over a year of constant efforts to achieve these goals. It has features like Insights and SmartFix which provide users access to a detailed diagnosis and resolution steps for web apps incidents. These AI-powered insights are significantly faster and more consistent than those provided by a human agent.
How does CW Copilot work?
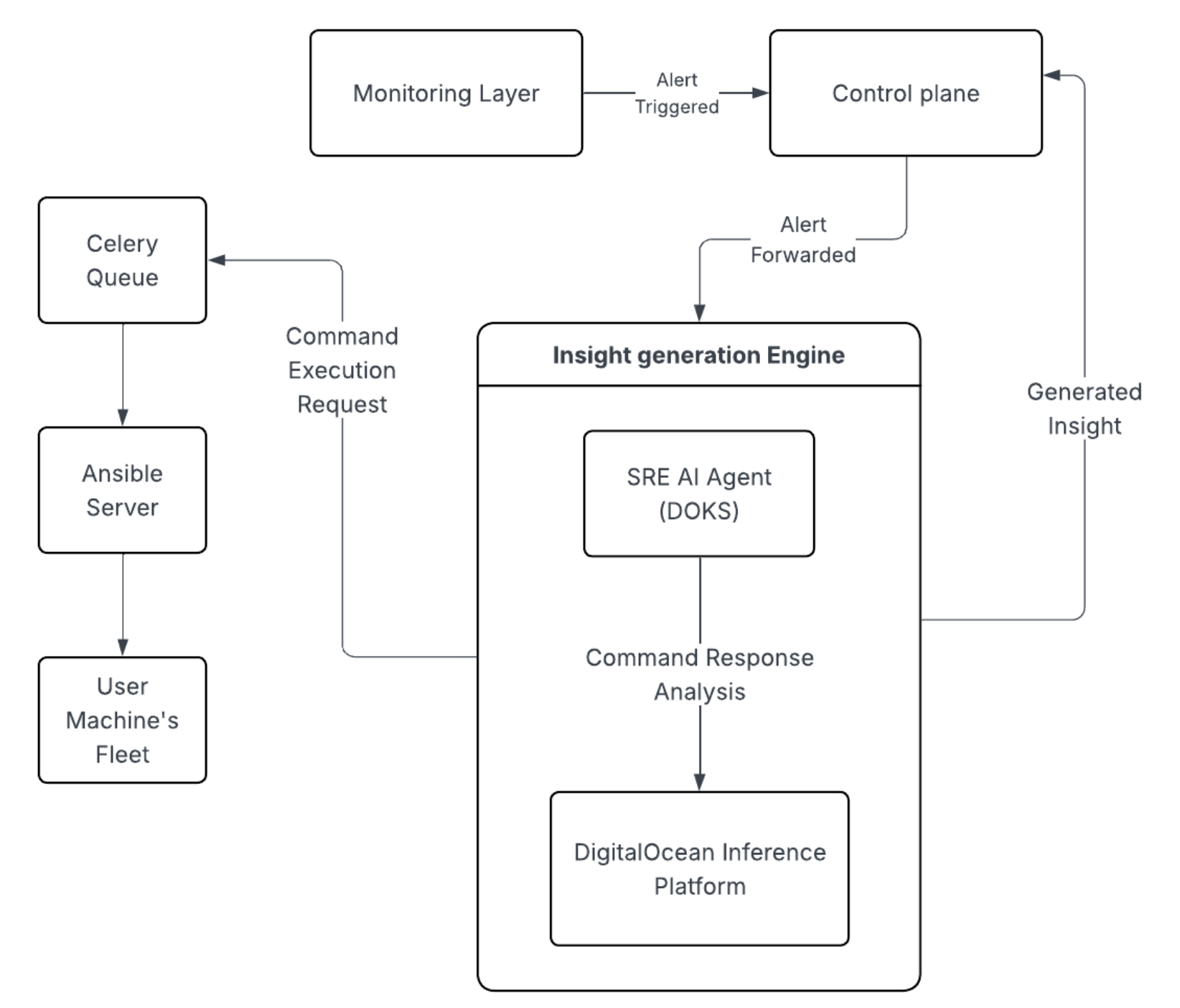
The monitoring layer continuously observes each user machine for Webstack issues and excessive. When an anomaly is detected, it triggers an alert and forwards it to the control plane. The control plane then routes the alert to the Insight Generation Engine, which consists of following components:
AI SRE Agent
The effectiveness of an AI agent depends heavily on the context it is provided. The agent is made aware of the customizations done by Cloudways on top of Debian so that it can work in an optimized way. It includes details like:
- File structure details (e.g., where configuration and web application files live)
- Locations of log files
- The commands used to navigate and inspect the system
- Core services needed for the web apps to run
The AI Agent is hosted on the DigitalOcean Kubernetes platform.
Orchestration Layer
A dedicated server orchestration layer had to be set up to connect AI Agent with the fleet of 90K servers. Cloudways manages this using Ansible Server. Whenever the AI Agent initiates a SSH command, it is stored on Redis and is picked sequentially through a celery queue. Once picked from the queue, Ansible runs the command on the client machine using a dedicated Linux user. This dedicated user has only access to specific commands and files ensuring data security on user machines. Response from the machine is sent back to the AI SRE Agent.
DigitalOcean serverless inference
Despite being a critical part of the system, this is fairly easy to set up. From an implementation perspective, inference is similar to invoking a single API endpoint. No infrastructure to manage, no scaling concerns to worry about.
curl https://inference.do-ai.run/v1/chat/completions \\
\-H "Authorization: Bearer $MODEL\_ACCESS\_KEY" \\
\-H "Content-Type: application/json" \\
\-d '{
"model": "digitalocean-anthropic-claude-sonnet-4”,
"messages": \[{"role": "user", "content": "What is the capital of France?"}\],
"temperature": 0.7,
"max\_tokens": 50
}'
These 3 components work in a loop until sufficient information is gathered and an insight is gendered for the user. An insight is a JSON object comprising of following parts:
- Investigation Summary
- Remediation Steps
- Fixes
- Related KB Links
This insight is sent back to the control plane, which then forwards it to the user.
Post generation insight review
At scale, application diversity is a major challenge. Cloudways hosts WordPress applications with countless plugin and theme combinations and Laravel apps with varied LAMP stack customizations.
This variation increases the risk of hallucinated investigations and remediation steps. To help mitigate this, we implemented two levels of validation.
1) Manual Review → Human review remains essential to ensure insights are consistent and helpful for users, and to facilitate continuous improvement. However, over long periods, this process can become repetitive and tiring for reviewers. We maintain a structured random sampling and issue tracking process to keep reviews sustainable and effective.
2) LLM as a Judge → We built a secondary evaluation layer where another AI Agent reviews outputs for quality and correctness. This system is continuously updated from the findings of the manual review process.
What we learned during this journey
Identifying the Right Problems to Get the Most Out of AI
The key to extracting real value from AI is choosing the right problems. For Cloudways, the best candidates were the tasks that were repetitive, time-consuming for humans, and operationally critical.
For Cloudways, the most impactful use cases were:
- Finding directories that can be safely deleted to recover disk space
- Tracing bots and IPs generating excessive requests
- Identifying problematic rules in configuration files that cause downtime
- Detecting processes that are hogging server resources
Fine-Tuning is (almost) always an overkill
Fine-tuning is often unnecessary for common SRE and infrastructure problems. Modern SOTA models already understand these domains well. In most cases, a comprehensive and well-structured prompt is enough to achieve reliable results.
Use the Right Tool for the Right Job
An AI agent is essentially a program where LLM outputs control parts of the workflow but that doesn’t mean every step must be handled by the model.
Deterministic tasks should be implemented in code, not delegated to the LLM. Use AI for reasoning and pattern recognition and use traditional logic for predictable operations.
Accept Non-Determinism
LLMs are inherently non-deterministic. Trying to force deterministic behavior and language from them leads to frustration and poor system design. Instead, build systems that tolerate variability and validate outputs.
Don’t Underestimate the AI
AI agents can replicate what human operators do and do it at scale.
Modern models have context windows large enough to retain more domain-specific information than a human expert can memorize. With the right setup, they become powerful operational assistants.
Don’t Overestimate AI Either
AI is not a magical hat. It cannot reason without patterns or prior signals.
If the environment is too novel, poorly documented, or inconsistent, performance will drop. The agent still depends on structured knowledge and historical context.
Avoid the Sunk Cost Trap
AI agents based tooling is still an evolving field. Its strengths and its limits are not fully defined yet. You might begin resolving a problem using LLM and subsequently discover that LLMs are not the right solution for this problem. Be pragmatic in these situations. Ruthlessly double down on what delivers value and abandon what doesn’t.
Why choose DigitalOcean Gradient™ AI Platform
Running an AI agent at this scale requires an inference partner that is not only powerful, but also highly reliable, flexible, and easy to operate. That’s where the DigitalOcean Gradient™ AI Platform comes in.
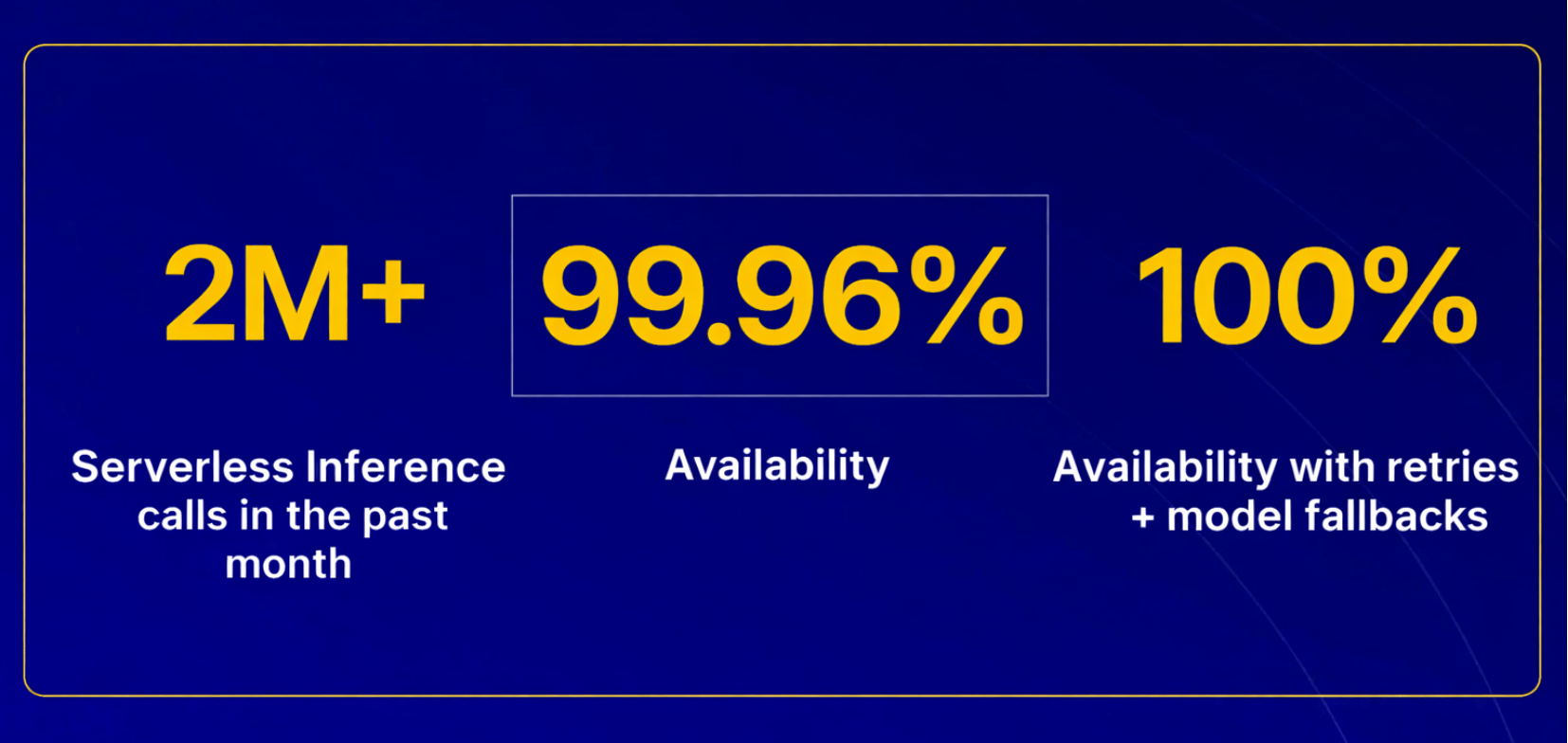
The simplicity of Serverless inference feature of the Gradient™ AI Platform allows Cloudways engineers to focus on improving Copilot’s intelligence rather than operating inference infrastructure or making it autoscalable to handle traffic spikes.
Its support for both open-source and closed-source models within a single environment is a game changer. All models are exposed through a uniform API schema, dramatically simplifying integration.
The platform is easy to set up with Pay-Per-Token Pricing without any upfront commitments, provisioning delays, or long-term contracts. This results in faster innovation with low operational complexity.
In addition to Serverless Inference, Cloudways leverages the Knowledge Bases feature of the DigitalOcean Gradient™ AI Platform. It’s used to fetch relevant Cloudways Knowledge Base articles alongside AI-generated insights. This capability plays a key role in delivering contextual, actionable guidance to users.
Implementation was straightforward. Cloudways engineers simply ingested Knowledge Base articles into the Gradient™ AI Platform, which automatically indexed the content and exposed it through a dedicated API endpoint. This enables the Copilot AI Agent to seamlessly retrieve and apply curated knowledge in real time.
Powering AI Agents at Scale
If you’re building AI agents to support critical business or operational workflows and need high flexibility, reliability, and simplicity, the Gradient™ AI Platform offers the same production-grade inference layer that powers Cloudways Copilot. It scales seamlessly from early experimentation to large-scale deployment, making it attractive to both early-stage startups and mature platforms. Startups can move fast without managing GPU hardware, model hosting, or scaling infrastructure, while growing teams benefit from unified model access, high availability, and operational simplicity as their workloads scale.
About the author
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read