The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
By Piyush Srivastava and Simon Mo, CEO of Inferact
- Updated:
- 13 min read
Introduction
Inference demand is growing fast, and it’s only accelerating. By 2030, inference is expected to account for the majority of AI compute globally. But scaling inference isn’t just a hardware problem. Most teams discover too late that a significant portion of their compute spend is avoidable, primarily because their systems are silently repeating work they have already done, recomputing the same prompt prefixes and system instructions over and over again.
We’ve seen this from two vantage points. From the infrastructure layer, the cost curve becomes visible at scale with clusters that look busy but aren’t efficiently utilized. From the engine layer, the picture is just as clear. Without the right caching and scheduling primitives, even a well-optimized model wastes cycles on redundant computation. The root cause is the same regardless of where you’re standing. The system lacks the memory and coordination to recognize when it’s already done the hard part.
Fixing this requires work at every layer of the stack. DigitalOcean has invested in GPU optimization across multiple fronts, from vLLM parallelism and quantization tuning to hardware-level kernel work. But one technique has had an outsized impact on cost efficiency at scale: prefix-aware routing and caching. In this post, we walk through how vLLM enables advanced prefix caching, how DigitalOcean’s inference gateway uses prefix awareness to make smarter routing decisions, and how we plan to make this available to everyone on Serverless Inference in the coming weeks.
The Cost Cliff and the Hidden Culprit
Inference now accounts for roughly 70% of total AI compute costs. For most teams, a significant share of that is avoidable. It’s not due to hardware limits. Instead, it’s because the system keeps recomputing work it has already done, also known as redundant prefill.
Every LLM inference request has two distinct computational phases. The first phase is prefill, where the model processes the entire input sequence and builds the KV (key-value) cache that represents its state. The second phase is decode, where the model generates output tokens one at a time, attending back to that cached state. Prefill is where the structural inefficiency hides. Its computation scales quadratically with input length: attention computation quadruples with doubling of input length.
Consider a real-world customer support workload running on NVIDIA H200 or AMD Instinct™ MI325X GPUs. A typical deployment carries a 2,000-token system prompt (defining persona, policies, response format) that is identical across every request. With an average user message of 200 tokens, roughly 91% of every input is shared context.
On AMD Instinct™ MI325X GPUs or NVIDIA H200, prefilling 2,000 tokens takes approximately 45–50ms and costs in the range of 100-120 GFLOPs per request. At 10,000 requests per hour, that’s over 1 trillion redundant FLOPs per hour. Compute spent reconstructing the state the system has already built, discarded, and is now rebuilding from scratch.
The pattern is even more pronounced in coding assistants or document Q&A tools, where the same API documentation or reference material is prepended to nearly every request. A 5,000-token shared context costs roughly 600 GFLOPs to prefill, which is nearly 25× more than a 1,000-token prefix, due to that quadratic relationship. When hundreds of users are querying the same underlying documents, the redundant computation compounds rapidly.
This is precisely the redundant “prefill tax” that we will focus on how to eliminate in the rest of this post.
How Prefix Caching Works at the Engine Layer
The redundant prefill problem has a clean structural solution, but landing it at production scale takes several mechanisms working in concert. Here’s what’s happening inside the engine when a cache hit lands.
Block-Based KV Storage
During prefill, every input token produces a key and value tensor at every attention layer, and storing these per-token would be a memory-management nightmare. The engine instead groups them into fixed-size blocks (16 tokens by default on CUDA, though configurable) allocated out of a pre-reserved GPU memory pool sized at engine startup. Each layer maintains its own pool of blocks. A single block holds the K and V tensors for block_size tokens for one layer’s KV heads, laid out so PagedAttention kernels can read them with coalesced memory accesses. A 2,000-token system prompt occupies 125 block positions (allocated per layer under the hood); once those blocks are sitting in the pool, any future request that begins with the same 2,000 tokens can point at them rather than recomputing. PagedAttention is the kernel technique that operates on this block-based layout, and the same memory machinery underlies both prefix caching and paged attention’s batching benefits, described in more detail in the engine anatomy writeup.
Prefix Hashing and Cache Lookup
Recognizing that two requests share a prefix is a string-matching problem on potentially very long inputs, and doing it naively would defeat the point. The engine instead hashes prefixes block by block, with each block’s hash depending on its own tokens, the hash of the previous block, and any extra inputs that affect the computation, including LoRA adapter IDs, multimodal image hashes, and optional cache salts for multi-tenant isolation. Identical prefixes under identical conditions produce identical hash chains, and the first divergent block is also the first point where the hashes disagree. Only full blocks are hashed and cached, so a partial trailing block at the end of a prefix doesn’t get reused and is recomputed along with the rest of the suffix. These hashes live in a lookup table mapping hash to cached block, and finding “the longest prefix of this request that’s already cached” reduces to walking the request’s block hashes against the table. The lookup is small and cheap, and the KV data itself lives in the GPU memory pool. Memory pressure comes from the pool, not the index.
From Cache Miss to Cache Hit: The FLOP Savings
The payoff shows up in compute terms. On a full cache miss, the engine runs prefill across the entire input, processing every token across every layer at full quadratic attention cost. On a full hit on the prefix, the engine skips nearly all of that work: the KV state for the prefix is already materialized in GPU memory, and only the trailing token needs to run through prefill so the first generated token has somewhere to attend from. Partial hits land in the middle, with prefill running only over the un-cached suffix and cached blocks treated as pre-computed context. On the customer-support workload from Section 1, a partial hit covering the 2,000-token system prompt turns a 45–50ms prefill into something dominated by the much shorter user message, and the structural FLOP savings show up directly as time to first token (TTFT) improvement.
A single engine instance can only cache what it has personally seen, which is the routing problem Section 3 picks up. The engine publishes KV cache events (block stored, block removed, with their associated hashes) over ZeroMQ on a PUB/SUB channel, while utilization metrics like batch size and free-block count flow through the StatLogger path. A router consumes both to make decisions. The interface is deliberately neutral: any compatible consumer can subscribe, whether that’s NVIDIA Dynamo, llm-d, or a custom gateway built in-house. Session-affinity routing handles the easy case of sending a user back to the instance that served their previous turn, but the event stream enables much more. A router can build its own global prefix tree from KV block events, balance load against per-instance batch size and cache utilization, and make routing decisions that account for cache locality and instance pressure rather than treating them as separate problems.
Hardware Headroom: AMD and NVIDIA
These mechanism benefits compound on the AMD Instinct™ MI325X GPUs. 192GB of HBM3 per GPU means the KV pool can hold substantially more cached blocks than on comparable hardware, resulting in more cached prefixes, higher hit rates, longer-lived cache entries before eviction. Layered on top, FP8 KV cache quantization roughly doubles effective cache capacity again (though combining FP8 KV cache with prefix caching has historically required specific kernel support, so it’s worth checking compatibility for your vLLM version), and the attention kernels on the read path have been tuned for AMD Instinct™ MI325X GPUs memory hierarchy so a cache hit doesn’t trade prefill cost for a slow cache read. The mechanism works universally, but on AMD Instinct™ MI325X GPUs it has more room to operate, which is what makes the routing layer in the next section worth building.
The picture is similar to NVIDIA Hopper, with different shapes of headroom. NVIDIA H200’s 141GB of HBM3e per GPU expands the KV pool considerably over H100’s 80GB, which translates directly into more cached prefixes and longer-lived entries before eviction. FP8 KV cache lands on Hopper through FlashAttention 3 and FlashInfer kernels. The same caveat about checking prefix-caching compatibility for your vLLM version applies, and the read-path attention kernels have been tuned around TMA loads and the Hopper memory hierarchy, so a cache hit doesn’t trade prefill cost for a slow KV read. Blackwell stretches this further, with 192GB of HBM3e per B200, and on GB200 NVL72 the NVLink domain collapses 72 GPUs into a single shared-memory fabric, opening up cross-instance KV reuse that single-node caching can’t touch. The underlying mechanism is the same across vendors, and what changes is how much room it has to operate, which is exactly what the routing layer in the next section is built to exploit.
The Routing Problem: Why Single-Instance Caching Isn’t Enough
Once the KV state for a shared prefix is computed, subsequent requests that share that prefix can reuse the cached blocks directly, bypassing prefill entirely. But production workloads don’t run on a single instance. They run across fleets of GPU workers behind a load balancer, and this is where naive deployments silently destroy the cache hit rate they worked to build. The DigitalOcean Inference Gateway (which is a fork of llm-d) embeds an Endpoint Picker (EPP), a component that intercepts every inference request via Envoy’s external processing (ext_proc) callback before it reaches any vLLM instance. The EPP is where all routing intelligence lives.
The Write Path: Publishing KV Cache Events
On the write path, each vLLM instance is configured with --kv-events-config to publish KVEvent messages over a ZMQ socket (tcp://*:5557) every time a KV cache block is allocated or evicted. Each event carries the block hash - computed using sha256_cbor_64bit over the token IDs in that block, using the same algorithm vLLM uses internally. The EPP subscribes to all instances, consuming this high-throughput stream and continuously updating a KV-Block Index: a low-level map of block_hash → {pod, memory_medium (GPU/CPU)}. memory_medium is the storage tier the block currently lives in on that pod. In our current implementation, KV blocks are always in GPU memory, but this will soon change as we look into multi-tiered storage architecture for KV blocks. From this index, the indexer builds and maintains a per-pod prefix tree - a radix structure of consecutive block hashes that reflects exactly what prefix state is warm in each pod’s GPU memory at this moment.
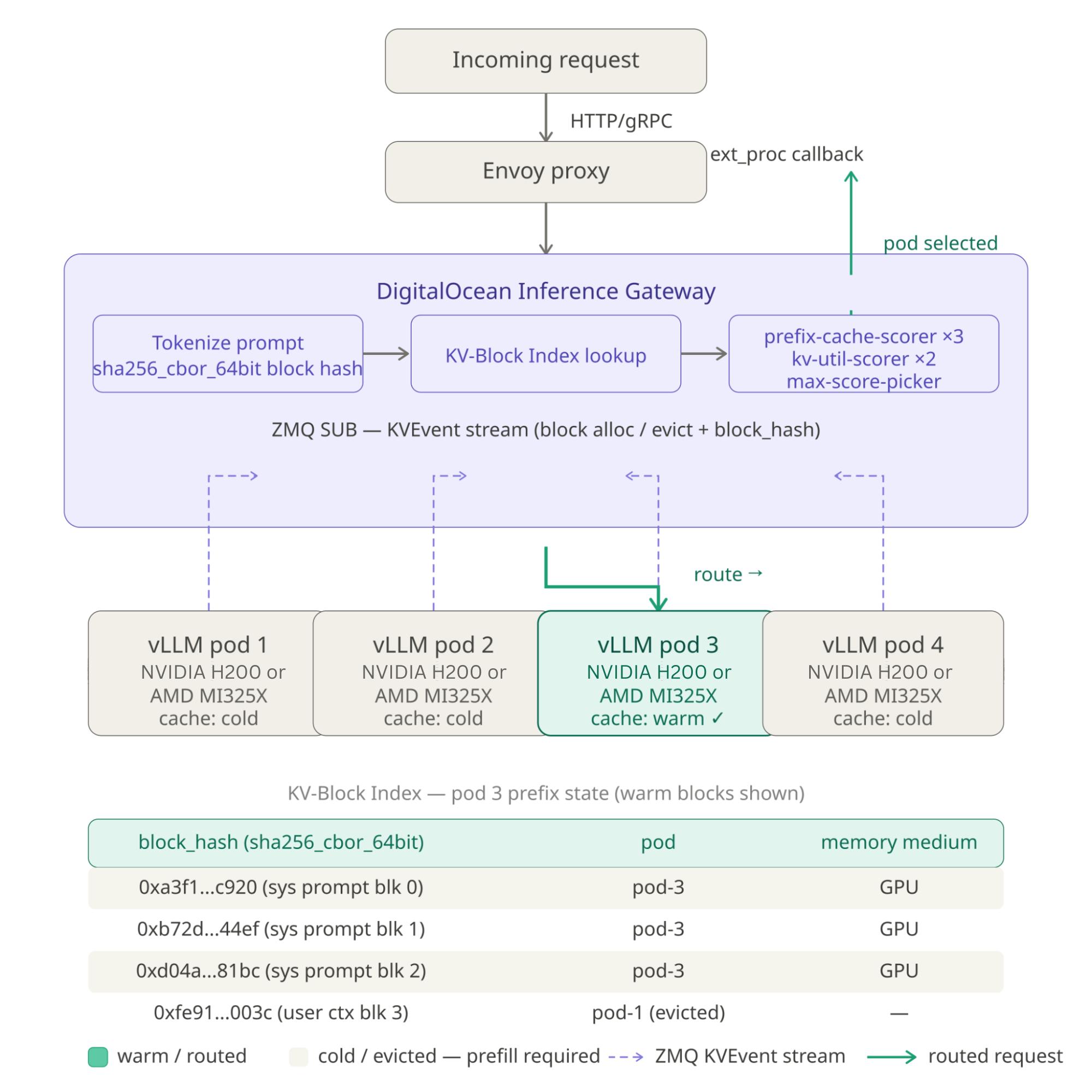
The Read Path: Prefix-Aware Request Scoring
On the read path, when a new request arrives, the gateway tokenizes the incoming prompt and computes its prefix block hashes using the identical sha256_cbor_64bit algorithm. It then walks the KV-Block Index, querying how many consecutive prefix blocks each pod holds for this request. The result is a cache affinity score per pod: a pod holding 90% of the prompt’s prefix blocks scores 0.9 × 3 = 2.7 on the prefix-cache-scorer (weight 3, the dominant signal). This is combined with a kv-cache-utilization-scorer (weight 2) that down-scores pods whose GPU vRAM is near capacity, preventing the router from routing to a pod that would have to evict blocks to accommodate the new request, negating any cache benefit. The max-score-picker selects the highest combined score, and Envoy forwards the request to that pod. As we get into multi-tiered KV cache, we are also looking at “tier-aware” prefix scoring where a GPU resident match scores higher than a CPU-resident or lower tiers. In general, there are multiple cost functions with varying priorities taken into account while making the routing decision.
The result: cache hit rates flip from ~25% under round-robin to 75%+ on workloads with shared prefixes - on the same hardware, with no model changes.
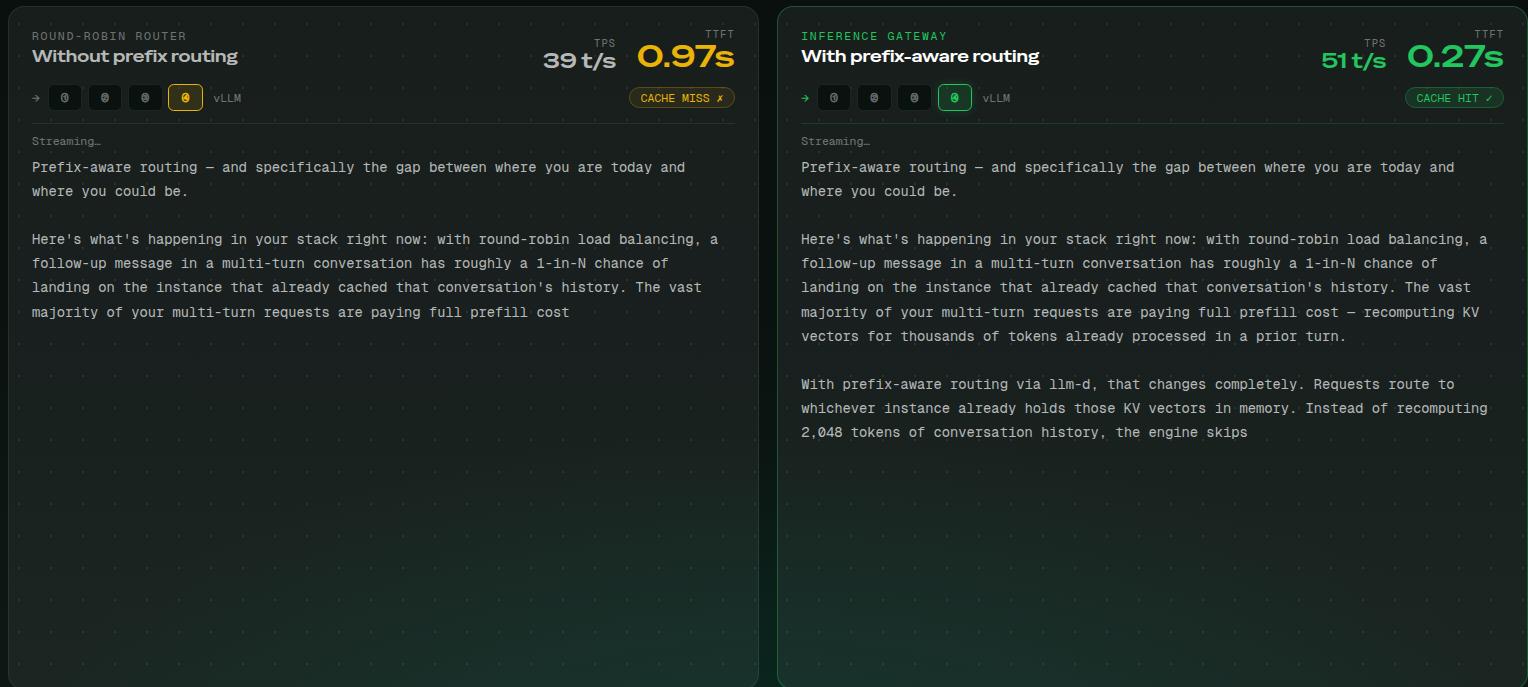
The Math: What Cache Hits Mean at Scale
The impact becomes concrete when you put real numbers behind it. At 1 million requests per day, a modest scale for a production deployment, assume 70% of requests share a common system prompt. Without prefix-aware routing, cache hits are essentially random: roughly 1-in-4 requests land on an instance with that prefix already warm. With prefix-aware routing, that flips to 3-in-4.
That delta, 350,000 additional cache hits per day, doesn’t sound dramatic until you attach the compute cost. Each cache hit skips roughly 350ms of prefill work. Across those 350,000 requests, that’s 34 GPU-hours saved every single day. Scale to 10 million requests per day and you’re recovering 340 GPU-hours daily, compute that was previously being silently wasted on work the system had already done.
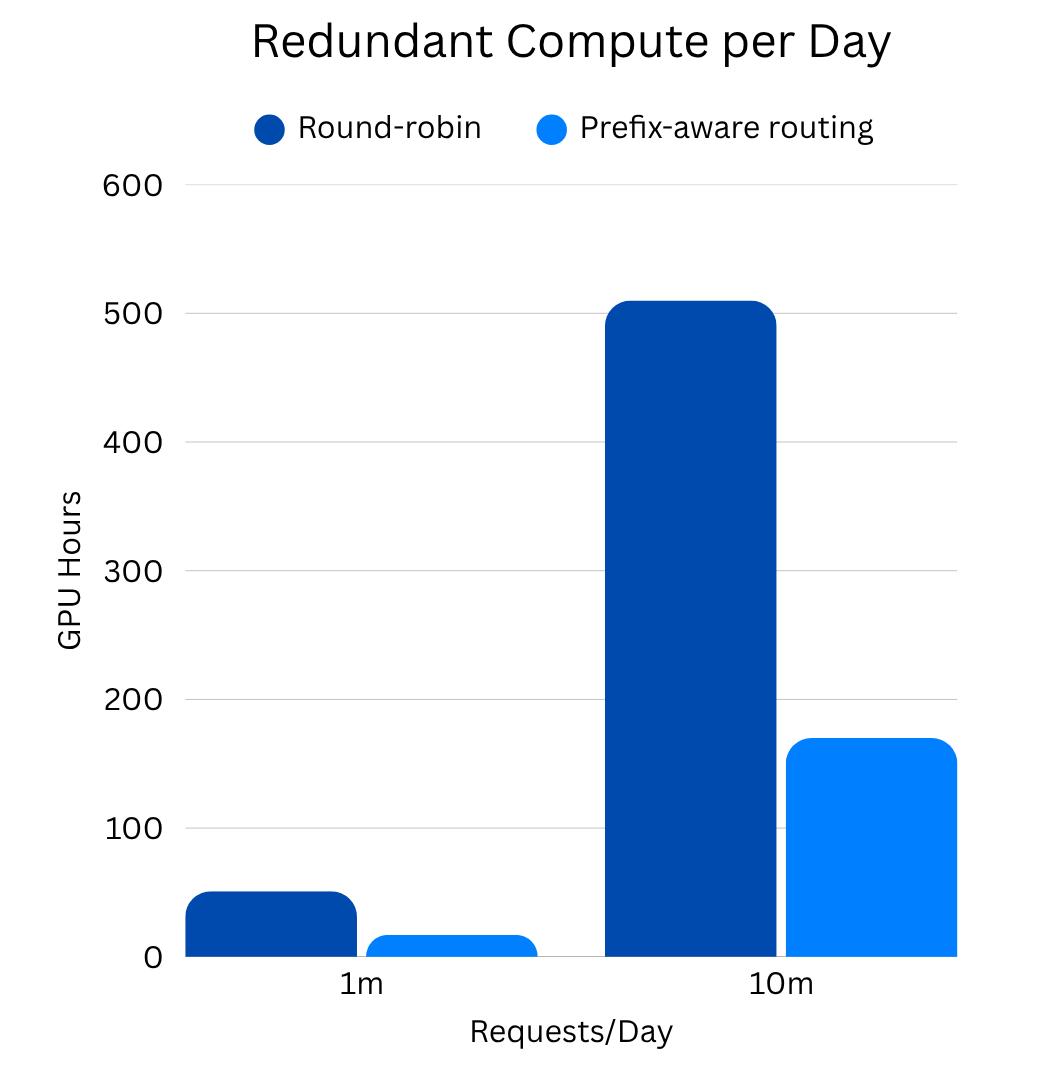
For the right workload profile, multi-turn conversations with persistent context, shared system prompts, RAG pipelines querying the same document sets, the economics compound further. The same prefix appears not just frequently, but across long sessions where every turn benefits. In these cases, prefix-aware routing can reduce effective compute cost by up to 4x per request on identical hardware.
The Engine Work Inferact Is Building
Prefix caching is one piece of a larger problem. Inference engines are evaluated on a lot of dimensions: raw speed, model coverage, and increasingly, how well they handle the messy shape of real production traffic. Closing the gap on all three, on frontier hardware, is the problem Inferact is organized around.
Inferact is a company built on vLLM, and in practice Inferact’s roadmap and vLLM’s roadmap are virtually identical. The work happens upstream, in the open, in the same repository everyone else uses.
The work falls into a few themes, each building on the last.
The first is pushing vLLM toward SOTA performance on frontier models on frontier hardware. The clearest external signal here is Artificial Analysis, whose independent benchmarks have become a common reference point across engines and providers. vLLM’s recent top rankings on DeepSeek V3.2 and DeepSeek V4 reflect work that is increasingly a community effort: kernel and fusion optimizations, large-scale serving improvements for disaggregated and wide-EP setups, speculative decoding, quantization, and torch.compile integration are all being pushed forward by contributors across vendors.
The second is day-0 model support, which is one of vLLM’s structural strengths. When a new frontier model drops, running it well on vLLM is the default, with recent launches like Gemma 4 and DeepSeek V4 supported on the engine from day one. Our goal is to continue this trend. The bar isn’t just accuracy on day zero. It’s continued accuracy and high performance on day zero.
The third part is optimizing vLLM for areas that benchmarks don’t measure well yet. Top-of-leaderboard token throughput on a single prompt is a real signal, but it isn’t the same as performance on the workloads that actually run in production. Real inference traffic, and agentic traffic especially, looks very different from what most benchmarks capture: long shared prefixes from system prompts and tool definitions, multi-turn conversations with rich cache-hit structure, and bursty arrival patterns that don’t resemble a steady stream of independent prompts.
Optimizing prefix caching is the clearest example of what this means in practice. On agentic traffic, the bottleneck isn’t raw decode throughput on a fresh prompt — it’s whether the engine recognizes that most of the prompt is identical to something it processed seconds ago, and reuses the KV cache accordingly. Getting this right can be the difference between a model feeling fast and a model feeling unusable in an agent loop, and on a standard benchmark it barely shows up at all. The same pattern holds for the rest of the production-traffic stack: scheduler design under bursty arrival, KV cache layout under high reuse, and the prefill/decode connector path all matter disproportionately on real workloads relative to what benchmarks reward.
None of this is work vLLM does alone, and none of it is work Inferact does alone either. The performance and workload story leans on cross-project, cross-vendor effort, and on the hundreds of vLLM contributors and downstream users who surface real problems and keep the project honest about what production actually looks like.
Inferact’s role in that ecosystem is to invest deeply in vLLM as a maintainer and contributor, not to fork it or wrap it. The bet is on an open, broadly-owned inference engine as the right foundation for the next several years of inference work.
These Optimizations Will Soon Ship to Everyone
Everything described in this post was originally built in the context of deep partnerships with large customers on DigitalOcean’s Dedicated Inference platform, but these optimizations will soon ship with every Serverless Inference deployment as well.
- Prefix-aware routing via the Inference Gateway (live on Serverless Inference now)
- Prefix caching with cached token pricing (launching on Serverless Inference in the coming weeks)
- vLLM runtime with optimizations on AMD Instinct™ MI325X GPUs as well as NVIDIA Hopper
- The same benchmark performance Simon and Inferact helped achieve
Prefix caching and routing are just part of the picture. DigitalOcean’s GPU hardware collaboration goes deeper across the stack, from FP8 quantization to parallelism tuning, and those gains flow through to Serverless Inference customers as well.
You won’t need a custom contract to benefit from these results. You will only need a DigitalOcean Serverless Inference endpoint.
Conclusion
Delivering best-in-class inference performance requires optimization at every layer of the stack, and no single team owns all of it. That’s the foundation of our partnership with Inferact.
Inferact brings deep expertise at the engine and kernel layer by optimizing vLLM internals, tuning GPU kernels for NVIDIA and AMD hardware, and squeezing maximum throughput out of the compute itself. DigitalOcean brings the infrastructure layer, virtualizing state-of-the-art AMD and NVIDIA GPUs at scale, building large GPU clusters purpose-built for serverless inference, and baking serving optimizations directly into the platform. That means auto-scaling, prefix-aware routing through our Inference Gateway, parallelism tuning, KV cache tiering across GPU and CPU memory to maximize effective cache capacity, disaggregated serving over a high-speed RoCE network, dynamic load rebalancing across model endpoints, and fleet-wide utilization optimization that continuously shifts capacity to where demand is highest.
Together, the two layers close the loop. Engine-level efficiency means nothing if the infrastructure routes requests poorly. Infrastructure-level routing means nothing if the engine is leaving performance on the table. This partnership is about making both layers aware of each other, so the gains compound.
Start using Serverless Inference today. Prefix caching with cached token pricing launches in the coming weeks. Sign up now to be among the first to benefit.
About the author(s)
Principal Engineer, AI Infrastructure
Related Articles

Built for Mass Scale: Hard-Won Lessons from Teams Running High Volume Inference Workloads in Production
- July 2, 2026
- 5 min read
Run Codex in the cloud – DigitalOcean for Codex is now available
- June 25, 2026
- 3 min read

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read