At Deploy 2026, we introduced the DigitalOcean AI-Native Cloud, built for the inference era. Batch Inference on the DigitalOcean Inference Engine enables high-volume asynchronous workloads. As developers move from AI prototypes to production-scale applications, the challenges of cost and rate limits often become a bottleneck. Batch Inference addresses these hurdles by allowing you to process high-volume workloads asynchronously at a fraction of the cost of synchronous requests.
Whether you are performing large-scale data transformation, content generation, building embeddings or offline evaluations, Batch Inference provides a unified, consistent way to leverage the world’s leading models from OpenAI and Anthropic, all through a single DigitalOcean interface.
The AI Scaling Bottleneck
Real-time inference is essential for interactive AI applications such as chatbots, copilots, and search-as-you-type experiences. However, when the task involves processing 10,000 support tickets for sentiment analysis, generating SEO metadata for an entire product catalog, or benchmarking a new system prompt against a test suite, real-time inference becomes an expensive and inefficient tool for the job.
Each of those requests competes for the same rate-limited throughput as your production traffic. Teams spend engineering time writing retry logic, managing backpressure, and monitoring scripts that work through sequential API calls for hours. If you use models from multiple providers, such as OpenAI for embeddings and Anthropic for generation, you are managing separate credentials, separate billing dashboards, and separate error-handling strategies, even though the core workflow is the same: submit requests, wait, retrieve results.
Processing thousands of synchronous requests is not only slow, it is an architectural challenge. At scale, synchronous inference becomes inefficient requiring thousands of open connections, creating constant rate-limit pressure and wasting compute while waiting for responses. It also introduces throughput bottlenecks, retry storms, and inconsistent latency, while pushing complex orchestration logic (queuing, retries, backoff) onto the client. Across multiple providers, this fragmentation only compounds the operational burden.
Introducing DigitalOcean Batch Inference
With Batch Inference, you can submit up to 50k requests for OpenAI or 100k for Anthropic in a single .jsonl file and let DigitalOcean handle the orchestration: queuing, execution, and result delivery.
What distinguishes this approach is its unified interface. Instead of working with each provider individually, OpenAI and Anthropic models are accessible through a single DigitalOcean API. One set of endpoints, one authentication flow, and one billing account allows you to monitor every job in one place, regardless of which provider executes it.
This single control plane manages the operational complexity while preserving full access to each provider’s native model capabilities.
DigitalOcean Batch Inference provides a single control plane
The upload, submission, and retrieval workflow is identical regardless of which model you use. By using one set of endpoints and a single authentication flow, you can switch between (or combine) providers without rewriting your orchestration logic or reconciling separate invoices.
Significant Cost Savings
Batch requests are billed at a significant discount compared to standard real-time inference rates, for both input, output, and cache tokens. If you are running background workloads at real-time prices today, switching to batch can reduce that cost by up to 50%
Example: 50,000 requests using Claude Opus 4.6 Assumes an average of 1,000 input and 500 output tokens per request.**
| Metric | Rea-time Inference | Batch Inference |
|---|---|---|
| Input Cost (50M tokens @ $5/M) | $250.00 | $125.00 |
| Output Cost (25M tokens @ $25/M) | $625.00 | $312.50 |
| Total Cost | $875.00 | $437.50 |
| Pricing information current as of May 2026 |
By switching to Batch in this example, you save $437.50 on a single run. This enables you to use top-tier intelligence for massive data processing tasks that might otherwise be cost-prohibitive, while also creating new opportunities to optimize inference budgets across high-volume workloads.
Bypass Rate Limits
Batch jobs run on a dedicated throughput lane, completely separate from your real-time inference quota. Your production endpoints remain healthy while a 40,000-request batch job processes in the background across either provider. This helps reduce 429 Too Many Requests errors in your data pipelines.
Asynchronous Processing
Submit a job and continue with other work. DigitalOcean manages the queue, retries, and delivery. You can poll for results when the job completes, or configure a webhook to receive notifications automatically (webhook delivery is coming soon).
Deeply Integrated with DigitalOcean
Batch inferencing is built into the DigitalOcean platform. Every part of the workflow, from file storage to job monitoring to usage analytics, runs on infrastructure you already use.
Powered by DigitalOcean Spaces
Input files (up to 200 MB) are uploaded directly to DigitalOcean Spaces via presigned URLs. There is no external storage to configure, no S3 buckets to provision, and no cross-account IAM policies to manage. The API generates a presigned upload URL, you PUT your .jsonl file, and Spaces handles the rest.
Results are delivered the same way. When a job completes, the results endpoint returns a presigned Spaces download URL. Result files are retained up to 30 days, so you can retrieve them on your own schedule.
This is the same Spaces object storage that powers the rest of the DigitalOcean ecosystem, now integrated into your AI batch pipeline.
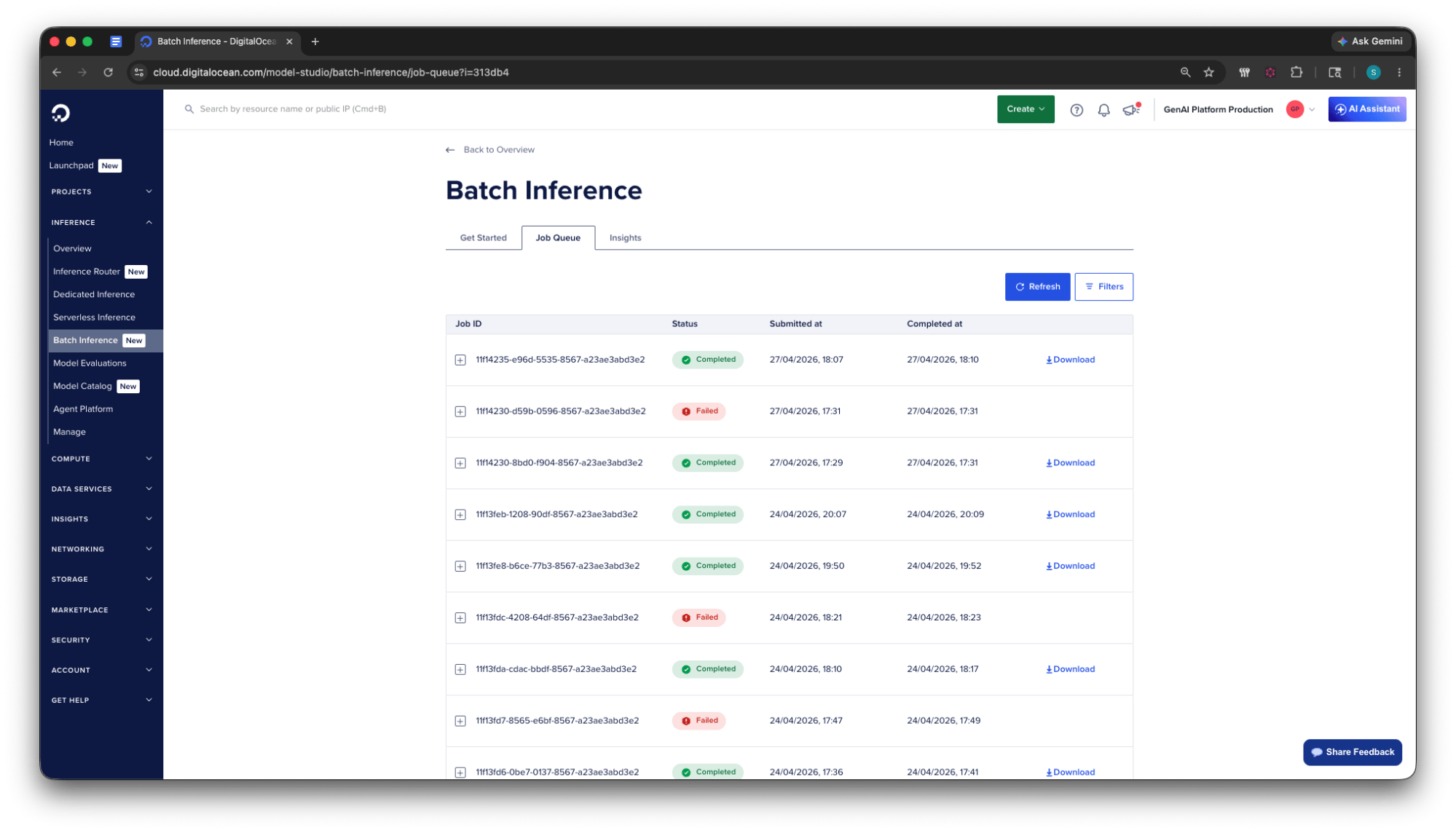
Job Queue: Track Every Job in Real Time
The Batch Inference Job Queue in the DigitalOcean Control Panel provides a live view of every batch job, with OpenAI and Anthropic jobs displayed side by side in a single list. For each job, you can view:
- Status:
awaiting_processing, in_progress, completed, failed, cancelled - Progress: total requests, completed, and failed counts, updated as the job runs
- Timestamps: when the job was submitted, started, and completed
- Provider: which provider is executing the batch
This eliminates the need to poll the API during development. You can monitor your jobs directly from the same Control Panel you use for Droplets, Databases, and Kubernetes.
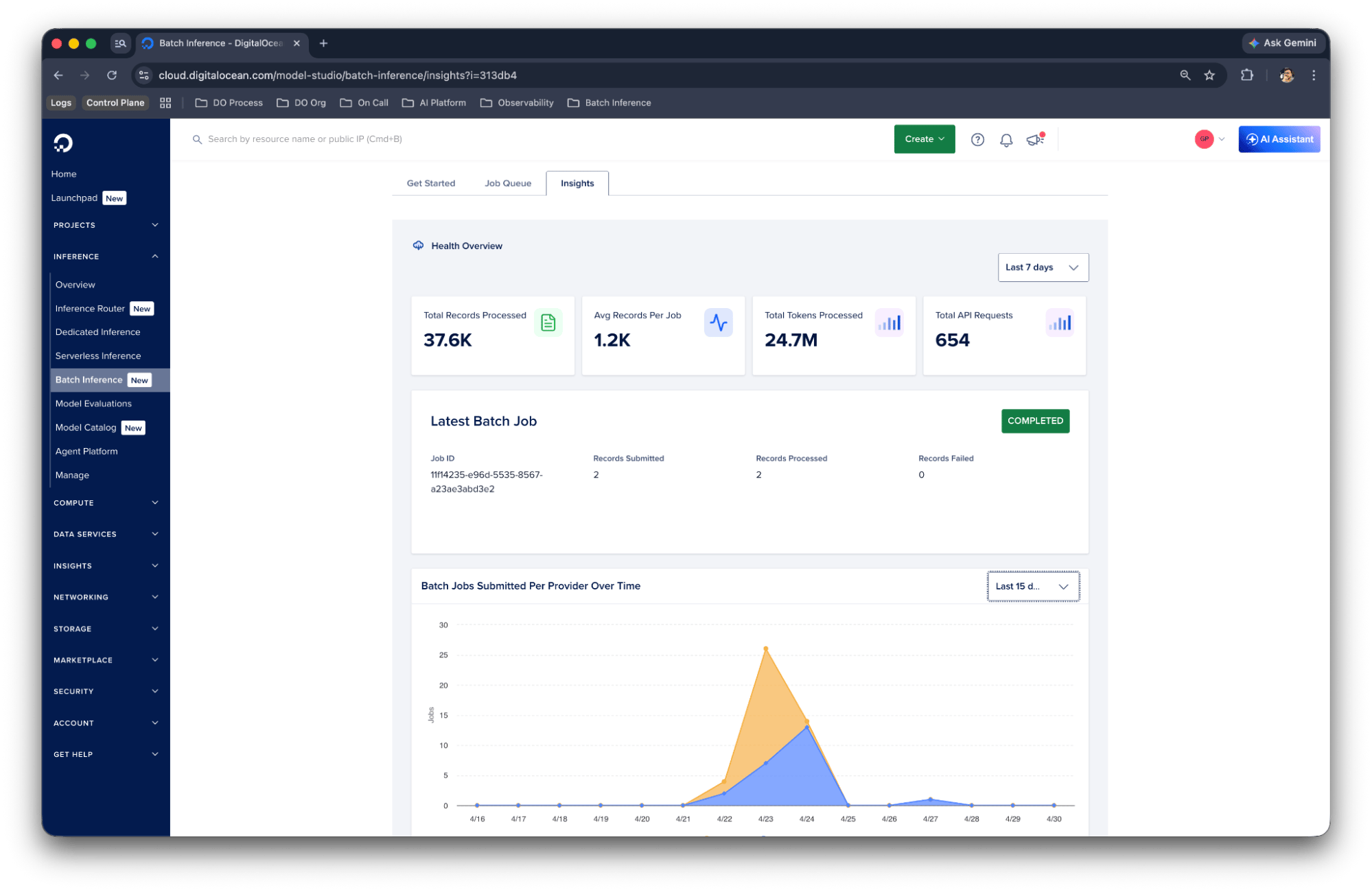
Insights: Understand Your Usage
The Batch Inference Insights page provides a centralized view of batch usage across both providers. You can track token consumption, job volumes, and completion trends over time, all in one place rather than across separate OpenAI and Anthropic dashboards.
Use Batch Inference Insights to understand cost patterns, identify peak usage periods, and plan capacity for your batch pipelines.
Unified Billing
Token usage and job costs for both OpenAI and Anthropic batch workloads appear on a single DigitalOcean invoice. There are no separate bills to reconcile across providers and no additional payment methods to manage.
MCP Server Support
Batch Inference is also available as an MCP (Model Context Protocol) server, enabling seamless integration with AI-powered IDEs, agent frameworks, and any MCP-compatible client. This allows developers to create batch jobs, monitor their status, and retrieve results directly within their existing workflows.
Agents can be instructed to operate on input files, such as JSONL files for batch inference, by referencing a specified file path. Based on this context, the agent autonomously selects and invokes the appropriate MCP tools to handle file upload and initiate batch job creation. It can monitor status and upon completion, users can prompt the agent to retrieve the final job results and corresponding download URL, providing a seamless, end-to-end workflow with minimal manual intervention.
How It Works
The workflow is the same whether you are targeting OpenAI or Anthropic: prepare, upload, submit, and retrieve. All requests are sent to https://inference.do-ai.run/v1 and authenticate with your Model Access Key.
- Prepare your input file. Create a
.jsonlfile where each line is a single inference request in the provider’s native format. OpenAI lines includecustom_id, method, url,andbody. Anthropic lines includecustom_idandparams. The model is specified per request inside the file, giving you full flexibility within a single batch. - Upload your file. Call
POST /v1/batches/fileswith your file name to get a file_id and a presigned Spaces upload URL. ThenPUTyour.jsonlfile to that URL. The presigned URL is valid for 15 minutes. - Create the batch job. Call
POST /v1/batcheswith yourfile_id, provider(openaioranthropic), andcompletion_window (24h). The endpoint, authentication, and response shape are identical for both providers. The only difference is theproviderfield. - Monitor and retrieve results. Poll
GET /v1/batches/{batch_id}for status, or monitor progress through the Job Queue in the Control Panel. Once the job reaches completed status, callGET /v1/batches/{batch_id}/resultsto get presigned download URLs for your output and error files. Result files are retained for 30 days.
You can also list all jobs with GET /v1/batches and cancel a running job with POST /v1/batches/{batch_id}/cancel.
For full API details, code samples (cURL and Python), and input file format examples, see the Batch Inference documentation.
Use Cases
Batch Inference is well-suited for any high-volume, non-latency-sensitive workload. The following examples are some of the most common patterns.
E-Commerce Catalog Enrichment
An e-commerce platform with 50,000 products needs SEO-friendly titles, marketing descriptions, and metadata tags for each listing. Rather than processing them through sequential API calls over several days, the entire catalog can be submitted as a single batch. You can use gpt-4o-mini for the English copy, then run a second batch through Claude for localized translations, all through the same pipeline with a different provider field.
Support Ticket Classification and Triage
Organizations can process a year’s worth of support tickets in a single batch, classifying them by category, urgency, and sentiment while extracting structured fields like product name, issue type, and customer tier. The output is a clean .jsonl file ready to import into an analytics pipeline or CRM.
Content Moderation at Scale
Platforms with user-generated content, such as marketplaces, forums, and review sites, often need to scan thousands of posts, images, and listings for policy violations. Batch Inference allows you to process the entire backlog overnight without competing with your production moderation endpoint’s rate limits.
Model Evaluation and Prompt Engineering
When developing a new system prompt, you can benchmark it against thousands of test cases by running the same evaluation suite against both OpenAI and Anthropic models through the same API. This enables side-by-side comparison of results at batch pricing, which is significantly lower than running the same evaluation in real time.
Document Processing and Data Extraction
Batch Inference can summarize thousands of legal contracts, research papers, or financial filings. It can also extract structured data such as dates, amounts, parties, and clauses from unstructured documents, or classify a backlog of invoices and receipts. These jobs can be large in volume but are rarely time-sensitive.
Getting Started
Batch Inference is available now on the DigitalOcean AI Platform.
Polling for job status is currently supported, with webhook notifications arriving soon for automated workflows. As the platform grows, expect expanded provider and model support.
The Bigger Picture
Inference has become the center of gravity in modern AI systems. Applications no longer make a single model call. They orchestrate multiple models, retrieve and synthesize data, execute tools, and repeat the cycle in production. This is a stack problem, not a model problem.
DigitalOcean’s AI-Native Cloud was built to address exactly this. Five layers, one platform, open at every layer: GPU compute, inference, data and storage, agents, and the tools to connect them. Batch Inference is the latest addition to the inference layer, sitting alongside real-time Serverless Inference, the new Inference Router, Dedicated Inference, and a catalog of 25+ models across text, image, audio, and video.
Where real-time inference powers interactive experiences, Batch Inference handles the heavy lifting that happens behind the scenes. Together with GPU Droplets, Knowledge Bases, and Managed Databases (including Managed Weaviate (Private Preview) for vector workloads), they form a complete system for building production AI without stitching together services from multiple vendors.
The goal is to simplify the stack so you can focus on building.
Ready to get started? Launch your first batch job or visit the product documentation to learn more.
About the author(s)
Related Articles

Scale Faster with Managed Weaviate: Now in Public Preview on DigitalOcean
- July 9, 2026
- 4 min read

DigitalOcean Evaluations: Production Model and Router Testing for the Inference Stack
- July 1, 2026
- 3 min read
Run Codex in the cloud – DigitalOcean for Codex is now available
- June 25, 2026
- 3 min read