Load Balancing and Scaling LLM Serving
Senior Software Engineer
- Updated:
- 7 min read
Load balancing for LLMs is fundamentally different from load balancing for traditional services like web servers, APIs, or databases. Prompt caching is the reason. Prompt caching typically cuts input token costs by 50-90% and can reduce Time to First Token (TTFT) latency by up to 80%, but those gains assume your request lands on the replica that already has the relevant prefix cached. Under naive round-robin load balancing across N replicas, that probability is 1/N. The cache hit rate that made caching so attractive at one replica degrades almost linearly as your fleet grows.
Solving this requires rethinking how requests are routed at the infrastructure level. This article covers the load balancing strategies and specialized routers that preserve cache efficiency at scale, starting with why standard approaches fall short and progressing to precise, cache-aware routing techniques.
Inferencing engines
To achieve large-scale inferencing, we use inference engines. These engines simplify the complexities of serving LLMs and offer improved resource utilization on the underlying GPUs. They also enable higher concurrency and allow for customization to suit diverse inference workloads, such as real-time chat completions and long-form document summarization. Noteworthy engine options include vLLM, SGLang, and TensorRT.
The inferencing process is largely consistent across different engines. Sending an HTTP request to an engine initiates a standard sequence of steps.
- Prefill Phase:
- The input prompt is first converted into token IDs using the model’s tokenizer.
- Requests are grouped into batches for efficient concurrent processing by the engine.
- During this initial processing, special Key (K) and Value (V) tensors are computed.
- This phase concludes after the first forward pass, resulting in the generation of the first output token.
- Decode Phase:
- This phase involves an auto-regressive loop, continuing until an end-of-sequence token is generated or the maximum sequence length is reached.
- For every subsequent token generated, the K and V tensors are incrementally updated.
Optimizations:
- To improve efficiency and avoid redundant computation, the engine uses advanced techniques like Paged Attention and Prefix Caching. These methods employ and access K/V tensors efficiently from GPU memory, especially when new requests might share common prefixes.
NOTE: This is a highly simplified description of token processing; in reality, inference engines perform much more significant optimizations, such as Fusing Tensor operations, capturing CUDA graphs, and tuning for various batch sizes.
For conversational workloads with a Large Language Model (LLM), every new message requires sending the entire conversation history to the engine. To improve efficiency, the use of pre-computed Key-Value (KV) caches reduces the “prefill” stage by reusing older caches. This ultimately decreases the TTFT.
Routing in homogeneous instances
If we are running the same model on n independent inference engines, the router policies typically include several popular options, such as:
| Strategy | Description | Drawbacks |
|---|---|---|
| Random or round robin | Each request is sent to a randomly selected engine or in a sequential, round robin manner. | Suboptimal performance and inconsistent results because random routing hinders the effective utilization of engine-specific KV caches. |
| Consistent hashing | Uses a “sticky session” or user_id routing, ensuring requests from the same user consistently hit the same engine. | While an improvement over random, the first request from a new user may land on any engine, potentially an engine without the required prompt’s KV cache. This is better suited for long conversational workloads. |
| Cache-aware load balancing | Routes requests to the engine with the maximum prompt prefix overlap, unless the load is uneven, in which case it routes to minimize imbalance. | If the engines lack support for KV events, routing decisions are made solely based on the request. This can lead to routing a request to an engine whose cache has been invalidated, making the decision inaccurate. |
The standard approach for load balancing is typically cache-aware load balancing. A more sophisticated version of this is known as precise prefix cache-aware routing. In this advanced strategy, the router captures KV cache events emitted by the engine. This information is then used to make routing decisions, specifically directing the request to the engine that offers the greatest overlap with the existing prefix cache.
To highlight the impact of routing on inference performance, we can compare a precise-prefix-cache-aware routing strategy with a standard k8s service employing a round-robin or random policy.
Benchmarking details and results, provided by the LLM-d community, are available on the LLM-d routing benchmark page.
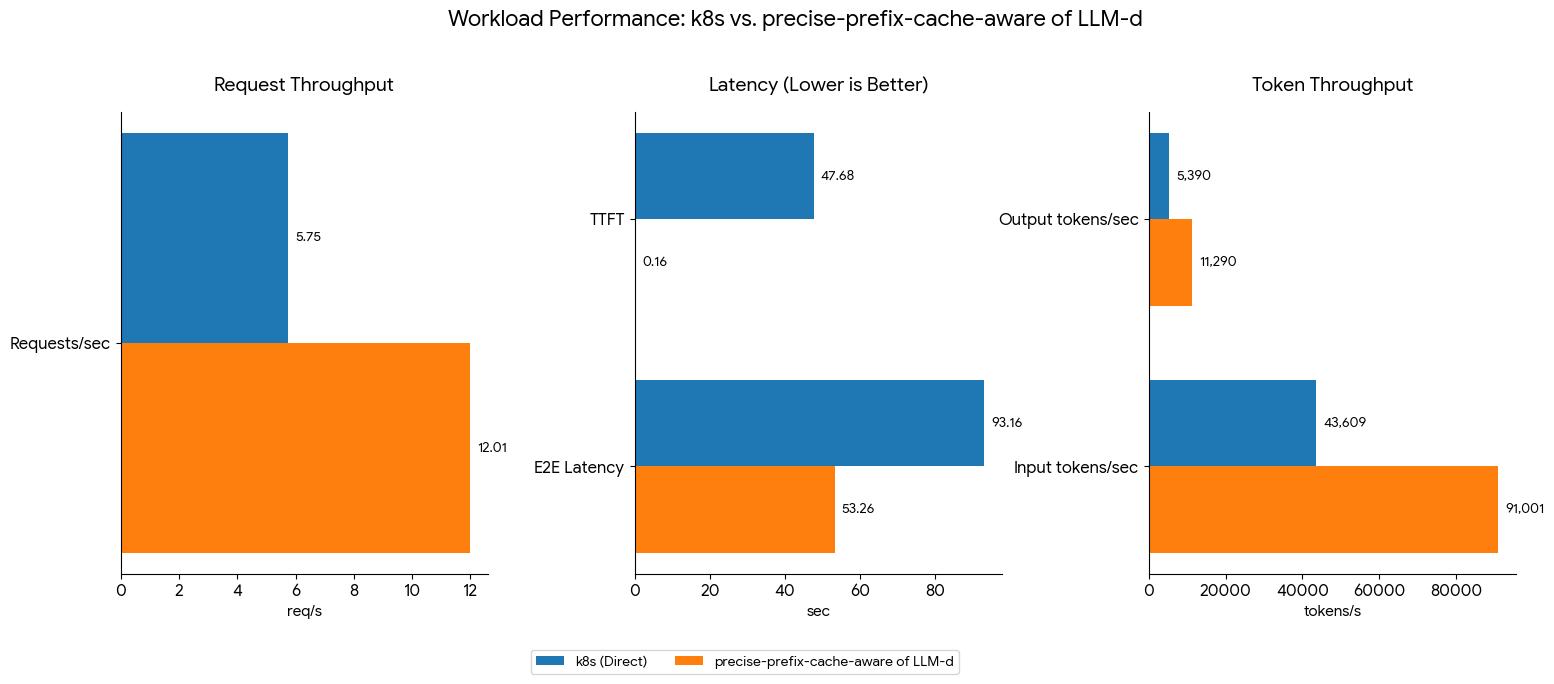
Cache-aware routing achieves an improvement in throughput of up to 108% for the same hardware configuration and workload. To understand cache-aware routing, we will start with its simpler form before progressing to a more advanced routing technique.
Cache-aware routing fundamentally relies on a data structure, often a Radix tree, that facilitates rapid insertion, removal, and prefix matching. The methodology is straightforward: a separate radix tree is maintained for each engine instance. When a new request arrives, its prompt is extracted. The system then iterates through all the instance-specific radix trees to identify the one with the longest matching prefix. This instance is then selected to handle the request. Additionally, the new prompt is inserted into the radix tree of the chosen instance for future routing considerations.
To prevent excessive radix tree growth, it implements a Least Recently Used (LRU) policy for purging its contents. Our routing strategy is not solely based on cache; we also incorporate a load-balancing mechanism that employs a balance threshold. This dynamic approach switches between pure load balancing and cache-aware routing because relying only on cache-aware routing has proven to be suboptimal for ensuring even load distribution across all instances.
The current design stores the entire prefix cache state within the router, without direct feedback from the individual engines regarding their actual prefix cache status. This lack of synchronization is why this method is not always accurate.
Inaccuracies can occur in two main ways:
- Stale Router State (Engine Evicts Cache): An engine might evict a prefix cache due to memory pressure, yet the router’s radix tree still incorrectly lists it as present. Consequently, the router routes the request to that engine, forcing the entire K/V cache to be re-computed.
- Stale Engine State (Router Evicts Cache): Conversely, the router might evict a cache entry based on an LRU policy, but the actual K/V cache might still exist within the engine.
Due to these inconsistencies, a more precise, cache-aware routing algorithm is often necessary.
In precise prefix cache aware routing, the router is able to make a more informed routing decision because it receives up-to-date K/V cache values from each engine via K/V cache events. This method differs from the simpler cache aware routing because it requires the router to first tokenize the input text prompt before performing the prefix match using a radix tree. While this adds a computation step during the routing process, the overall approach offers significant speed advantages and is much more precise, as tokenization is faster than the prefill or decoding phases.
To achieve high availability (HA) and independent scaling of the router, an external source like Redis can be used. Alternatively, a mesh architecture backed by Conflict-Free Replicated Data Types (CRDTs) can be employed. This approach allows each router to maintain a replicated data structure (the “tree”) such that they can independently handle KV events and process requests without needing to maintain individual, separate trees. This inherent capability enables the horizontal scaling of the router layer.
Dis-aggregated serving for large sequence lengths
Arithmetic intensity is the ratio of arithmetic operations to memory operations for a particular hardware. This ratio is key in determining whether an operation is constrained by computation power (compute-bound) or memory access speed (memory-bound).
Prefill Stage (No Batching):
- All tokens in the prompts are processed in one forward pass.
- Predominantly compute bound.
Decode Stage (Per-Token Generation):
- Tokens are generated sequentially, one at a time.
- Even with batching applied, the decode stage remains memory-bound because the KV cache must be updated after the generation of each individual token of a sequence before the next token can be produced.
Optimal performance requires selecting hardware based on workload characteristics: higher TFLOPs are needed for efficient prefill, while high memory bandwidth is crucial for faster decode operations. This is because different hardware exhibits varying arithmetic intensity.
The final consideration is the method for transferring the calculated KV cache from the pre-fill engines to the decode engines, as the latter requires this cache to generate subsequent tokens. Crucially, the KV cache transfer must be executed with maximum speed, minimizing any additional memory movement.
Several solutions exist for transferring KV cache, including NCCL (Nvidia), RCCL (AMD), NVIDIA NIXL, Mooncake TE (Transfer Engine), and UCCL P2P. For a comprehensive comparison and performance analysis of these different KV cache transfer engines, a benchmark is available here.
Disaggregated serving, while possible, is not always the most efficient choice for every request due to the overhead of KV transfer. Although the KV transfer uses advanced, high-speed technologies like RDMA, its bandwidth is still lower than the on-GPU memory bandwidth. Therefore, disaggregated serving is generally recommended for larger models with demanding workloads, specifically those with long sequences, such as a 100K Input Sequence Length (ISL) and a 1K Output Sequence Length (OSL). The ratio between Prefill and Decode nodes should be dynamically adjusted based on the specific ISL/OSL workload.
For smaller ISL, prefill/decode (P/D) dis-aggregation can be entirely omitted. In these cases, the decode worker can handle both the prefill and decode operations. We usually have a threshold that dynamically switches between proper P/D and non dis-aggregate serving.
The routing strategies described here assume KV cache state remains local to individual replicas. The logical next step (and where the industry is actively headed) is a shared cache layer accessible across replicas, likely backed by a high-bandwidth CPU DRAM pool. This would allow any replica to serve a cache hit regardless of which replica originally computed it. The challenge is latency: moving KV tensors across a network boundary is significantly slower than reading from local GPU VRAM, even with RDMA. Until that tradeoff is resolved at acceptable latency for production workloads, session affinity and prefix-aware routing remain the practical state of the art.
Performance metrics and savings (including TTFT and token costs) are based on specific benchmarks; actual results vary by configuration and are not guaranteed. References to third-party tools (e.g., vLLM, SGLang) are for informational purposes and do not imply any endorsement. This content is provided “as-is” for educational use and does not constitute a technical warranty or a binding Service Level Agreement (SLA).
About the author
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read