AI/ML Technical Content Strategist

Most AI applications start with one model hardcoded into the app. That works well for a prototype, but it breaks down the moment a single endpoint has to handle multiple complex task categories; classification, urgency scoring, customer-facing drafting, and long-form summarization all benefit from different model choices. Those tasks do not share the same cost, latency, or quality requirements.
Support triage is the cleanest example of this. A user types “how do I reset my password?” and you spend the same per-token rate as you do on a multi-paragraph escalation from an enterprise customer with logs pasted in. You can branch on ticket type in your app code and pick a different model per branch, but now your model selection logic lives inside your handler, your fallback strategy is a try/except, and every pricing change means a redeploy. The consequences include a 70B model classifying one-word tickets, no fallback when that model is slow, and a redeploy every time pricing shifts.
In this tutorial, we’ll use serverless inference via DigitalOcean’s Inference router to easily and quickly build a FastAPI support triage endpoint that solves all these problems at once. By the end, you’ll route classification, urgency scoring, customer replies, and escalation summaries to the right model for each job — automatically, with built-in fallback, and without a single model name in your application code. By the end, you’ll have a production-ready API that’s 71% cheaper than running everything on a frontier model.
What you’re building
Let’s construct a single endpoint, POST /triage, that takes a ticket payload and returns:
- Classification: the issue category (billing, bug, how-to, account, etc.)
- Urgency + sentiment: a severity score and a read on customer mood
- Drafted reply: a short, customer-facing response
- Escalation summary: a structured brief for a human agent, generated only when the ticket is complex enough to need one
The architecture moves from this:
App → hardcoded model (one model handles every task)
to this:
App → Serverless inference via Inference Router → best-fit model per task
The router is what makes the second diagram possible without your app knowing anything about which models exist.
Serverless Inference and DigitalOcean’s Inference Router
The Inference Router lets you define tasks and model pools, then routes incoming prompts to the best-fit model based on those task definitions and selection policies. A task is a named job with a description: classify_ticket, for example. A model pool is the set of candidate models the router can choose from for that task, governed by a selection policy: lowest cost, lowest latency, a manually set ranking, or a fallback order. You configure all of this once at the router level, and your app calls the router instead of any specific model.
Serverless inference lets you send API requests to models without having to create an AI agent or worry about managing infrastructure. This allow you to get started quickly without managing any components behind an inference endpoint.
The API surface is OpenAI-compatible. The base URL is https://inference.do-ai.run/v1/, and a single model access key covers both foundation models and routers.
Project setup
In order to continue, you need Python 3.10+, a DigitalOcean account with Serverless Inference enabled, and a model access key. We have already configured the full project in this repository for your convenience, but follow along in this next section to build out your own version of the API and learn why we made specific choices for the API.
The project layout is intentionally small:
support-triage/
├── main.py
├── sample_tickets.json
├── requirements.txt
└── .env
main.py holds the application code, requirements.txt the required packages, sample_tickets.json is a sample for testing the router, and .env holds the required secrets, keys, and URL base values.
To get started, clone the repo onto your machine and install everything by pasting the following into your terminal:
git clone https://github.com/Jameshskelton/triage_app
cd triage_app
python3 -m venv venv_triage
source venv_triage/bin/activate
pip install -r requirements.txt
The OpenAI SDK works as-is for DigitalOcean’s Serverless Inference: you just point base_url and api_key at DigitalOcean instead of OpenAI.
Step 1: The baseline - direct model calls
Before we touch the router, let’s build the version most developers would write first: one model, hardcoded, doing all four jobs. The next few step sections outline the work we did to build the application demo. If you would like to just test the final version, check out our repository where we stored this project.
To get started, we created main.py:
import os
import re
from openai import OpenAI
from fastapi import FastAPI
from pydantic import BaseModel
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url=os.environ["DO_INFERENCE_BASE_URL"],
api_key=os.environ["DO_MODEL_ACCESS_KEY"],
)
MODEL = "llama3.3-70b-instruct" # one model for everything
app = FastAPI()
class Ticket(BaseModel):
subject: str
body: str
def call_model(system: str, user: str) -> str:
resp = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
)
return resp.choices[0].message.content.strip()
@app.post("/triage")
def triage(ticket: Ticket):
text = f"Subject: {ticket.subject}\n\n{ticket.body}"
category = call_model(
"Classify this support ticket into one of: billing, bug, how-to, account, other. Reply with one word.",
text,
)
urgency = call_model(
"Score urgency from 1 (low) to 5 (critical) and note sentiment. Reply as 'score: N, sentiment: X'.",
text,
)
reply = call_model(
"Write a short, professional reply to this customer. Maximum 4 sentences.",
text,
)
summary = call_model(
"Summarize this ticket for a human agent. Include the problem, what's been tried, and recommended next steps.",
text,
)
return {
"category": category,
"urgency": urgency,
"reply": reply,
"escalation_summary": summary,
}
If we have set up our .env file correctly with the right API keys and values, we can run it using the code below:
uvicorn main:app --reload
Let’s test it with two tickets (one trivial, one complex), and audit the results.
Example input 1:
curl -X POST localhost:8000/triage -H "Content-Type: application/json" -d '{
"subject": "Password reset",
"body": "How do I reset my password?"
}'
Example output 1:
{
"category": "account",
"urgency": "score: 1, sentiment: neutral",
"reply": "You can reset your password by selecting the Forgot password link on the sign-in page and following the email instructions. If you do not receive the reset email, check your spam folder or contact support for help.",
"escalation_summary": "The customer is asking how to reset their password. No signs of account compromise, outage, or escalation risk. Recommended next step: provide standard password reset instructions."
}
Example input 2:
curl -X POST localhost:8000/triage -H "Content-Type: application/json" -d '{
"subject": "Production outage on enterprise account",
"body": "Our team has been unable to access the dashboard since 09:14 UTC. We have ~200 internal users blocked. Attached are logs showing 502s from the API gateway..."
}'
This gives us something like the corresponding example output 2:
{
"category": "bug",
"urgency": "score: 5, sentiment: frustrated",
"reply": "Thank you for reporting this. We understand that a production dashboard outage affecting around 200 users is urgent, and we are escalating this to our engineering team immediately. Please continue to share any relevant logs or timestamps while we investigate.",
"escalation_summary": "Enterprise customer reports a production dashboard outage beginning at 09:14 UTC. Approximately 200 internal users are blocked. Logs indicate 502 responses from the API gateway. Recommended next steps: escalate to engineering, inspect gateway and upstream service health, correlate errors around 09:14 UTC, and provide the customer with frequent status updates."
}
Both responses are useful. That is exactly why this baseline is tempting.
But look at what just happened: the same 70B model handled everything. The model classified “How do I reset my password?” into a simple category, scored urgency, drafted a short reply, and wrote an escalation summary that the ticket did not really need. Then it handled the enterprise outage, where the larger model actually makes sense.
That is the problem. The trivial ticket and the production outage have very different cost, latency, and quality requirements, but the app treats them the same. You are paying overkill rates for simple work, there is no fallback if the model is slow or unavailable, and any model-selection change means editing application code and redeploying. Let’s fix that.
Step 2: Configure the Inference Router

In the DigitalOcean control panel, navigate to the Inference Router using the left-hand sidebar. Then, create a new Inference Router. Name your Router appropriately, and give it a descriptive description of what it will do. For example, we named ours triage-router, and described it as “Demo Triage API for DO tutorial”.
The router then needs its four tasks, each with a description and a model pool with a selection policy. Each of these is outlined below. If you want to copy them to recreate this experiment, copy and paste the values within to the Router tasks individually. This will make probabilistically similar results to what we have.

| Task name | Description (fed to the router) | Model pool strategy |
|---|---|---|
| classify_ticket | Categorize short support messages into issue types (billing, bug, how-to, account). | Lowest cost |
| urgency_detection | Detect severity, sentiment, and escalation risk in a single pass. | Lowest latency |
| draft_customer_reply | Generate a short, professional customer-facing reply. | Manual ranking |
| escalate_complex_issue | Summarize complex tickets into structured briefs for a human agent. | Manual ranking |
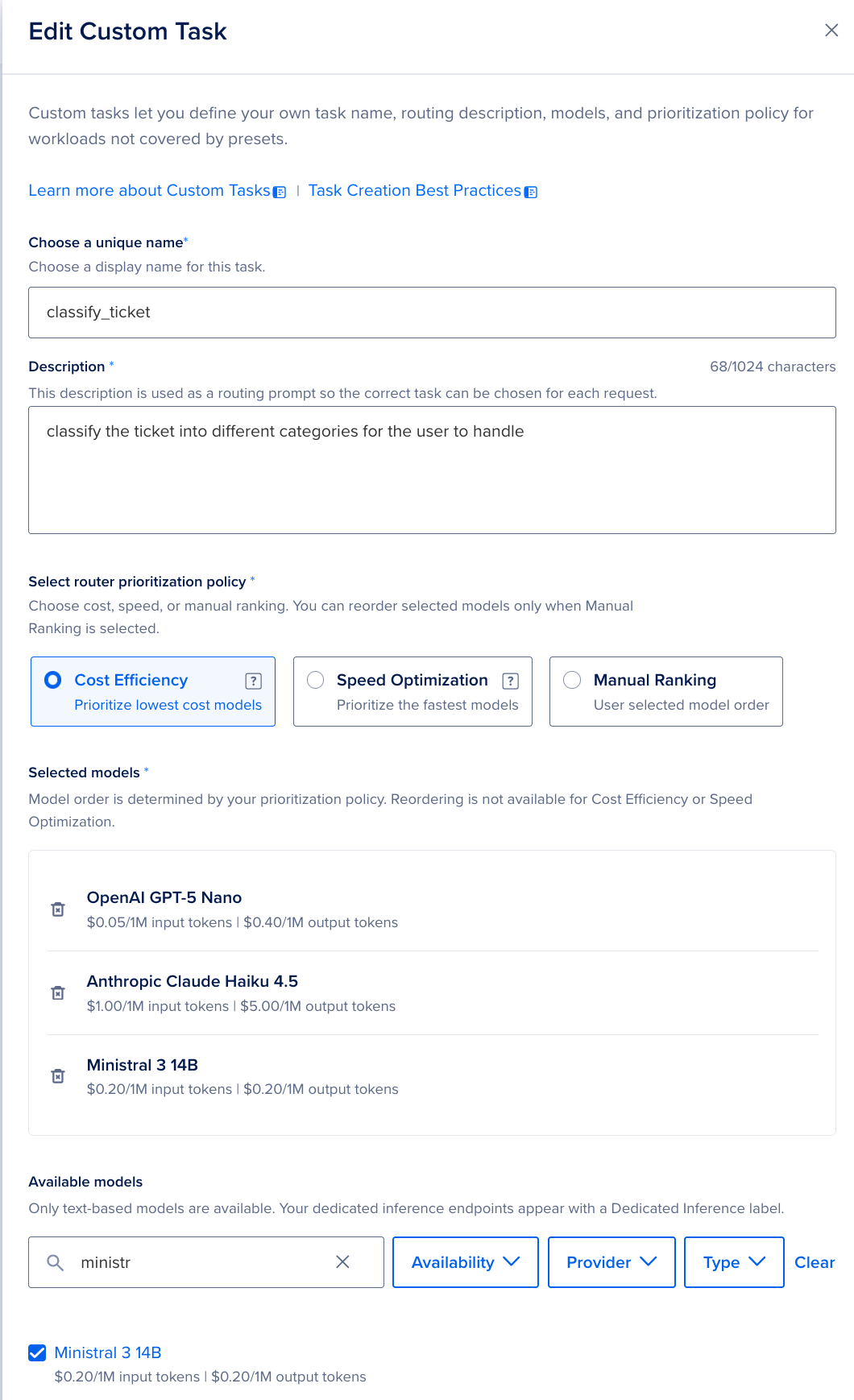
When we are creating the description, selecting the router prioritization policy, and selecting the model, we need to consider the exact task we want completed to optimize our results. Here are a few things worth noting as you configure these:
- Task descriptions matter. The router uses them to match incoming requests to the right task. Be specific about what the task does, what kind of input it expects, and the format of the output.
- Put at least two models in every pool. A pool of one is a single point of failure. Even your “lowest cost” pool should have a fallback in case the primary is unavailable.
- The selection policy is enforced inside the pool, not across pools. “Lowest cost” means “the cheapest model in this pool that’s currently healthy,” not “the cheapest model on the platform.”
Once the router is saved, you’ll get a router ID. That’s what your app will call.
Step 3: Refactor the app to use the router
Now the satisfying part. Replace the hardcoded MODEL constant with the router ID, and pass the task name through the request. Below is an example of what you could do to make it work, though not exactly what we did in our final release.
ROUTER = "your-router-id" # from the DigitalOcean control panel
def parse_urgency(urgency_text: str) -> int:
"""Extract the integer score from 'score: N, sentiment: X'. Defaults to 3 if unparseable."""
match = re.search(r"score:\s*(\d)", urgency_text, re.IGNORECASE)
return int(match.group(1)) if match else 3
def call_router(task: str, system: str, user: str) -> dict:
resp = client.chat.completions.create(
model=ROUTER,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
extra_body={"task": task}, # router uses this to pick the pool
)
return {
"content": resp.choices[0].message.content.strip(),
"served_by": resp.model, # the model the router actually picked
}
@app.post("/triage")
def triage(ticket: Ticket):
text = f"Subject: {ticket.subject}\n\n{ticket.body}"
category = call_router(
"classify_ticket",
"Classify this support ticket into one of: billing, bug, how-to, account, other. Reply with one word.",
text,
)
urgency = call_router(
"urgency_detection",
"Score urgency from 1 (low) to 5 (critical) and note sentiment. Reply as 'score: N, sentiment: X'.",
text,
)
reply = call_router(
"draft_customer_reply",
"Write a short, professional reply to this customer. Maximum 4 sentences.",
text,
)
# Only escalate when urgency warrants a human brief
urgency_score = parse_urgency(urgency["content"])
summary = None
if urgency_score >= 4:
summary = call_router(
"escalate_complex_issue",
"Summarize this ticket for a human agent. Include the problem, what's been tried, and recommended next steps.",
text,
)
return {
"category": category["content"],
"urgency": urgency["content"],
"urgency_score": urgency_score,
"reply": reply["content"],
"escalation_summary": summary["content"] if summary else None,
"routing": {
"classify_ticket": category["served_by"],
"urgency_detection": urgency["served_by"],
"draft_customer_reply": reply["served_by"],
"escalate_complex_issue": summary["served_by"] if summary else None,
},
}
That’s the whole change. It’s already done for you in the GitHub version, so there’s no need to manually do it yourself.
With this, there are no model names anywhere in the app. The router decides which model handles each task, using the policies you configured. If you want to swap the underlying model for draft_customer_reply next month, you do it in the router, not in this file.
The app triages one ticket by breaking it into smaller AI jobs instead of asking one model to do everything at once. When you call POST /triage, main.py builds the ticket text, then sends separate router calls for:
- classify_ticket: decides the ticket category, like billing, bug, how-to, account, or other.
- urgency_detection: scores severity from 1 to 5 and detects sentiment; the code uses the score to decide whether to escalate.
- draft_customer_reply: writes a short customer-facing response.
- escalate_complex_issue: Tickets scoring 4 or 5 on urgency trigger the escalation summary; lower scores skip it entirely, which is where most of the cost savings live.
The key thing: the app always calls your DigitalOcean router ID from .env as the model, and the router decides which underlying model should handle each prompt.
Step 4: Run mixed tickets through the router
With the router wired in, let’s test it. The interesting behavior shows up when you feed the endpoint a mix of simple and complex examples. Here’s a small batch of simple to complex examples in sample_tickets.json:
[
{"subject": "Password reset", "body": "How do I reset my password?"},
{"subject": "Invoice question", "body": "Why was I charged twice on invoice INV-3382?"},
{"subject": "This is ridiculous", "body": "Third time this week your dashboard has gone down during our standup. We're seriously evaluating alternatives."},
{"subject": "Dashboard weird", "body": "the dashboard is weird since yesterday"},
{"subject": "Production outage", "body": "Our team has been unable to access the dashboard since 09:14 UTC. ~200 internal users blocked. Logs attached show 502s from the API gateway, traced to..."},
{"subject": "Feature request + complaint", "body": "Can you add bulk export? Also the existing export is too slow and crashes on >10k rows."},
{"subject": "API auth", "body": "Getting 401s after rotating my key. Following the docs at /auth/rotate but the new key returns invalid."}
]
In order to test them in sequence, we have provided run_batch.py to facilitate this test. You can run it yourself with the following command:
python3 run_batch.py sample_tickets.json --json
Loop through them and you’ll see the routing do its job. The one-line “how do I reset my password?” hits the lowest-cost pool for classification and a small, fast model for urgency. The angry churn-risk message gets flagged high-urgency quickly, but the drafted reply comes from the higher-quality pool because that response is going to a real customer. The production outage gets routed to the higher-quality pool for the escalation summary, because that summary is what a human engineer is going to read at 09:15 UTC.
Because call_router surfaces resp.model as served_by, every response now tells you exactly which model handled each task. Here’s what the production outage ticket returns:
{
"category": "bug",
"urgency": "score: 5, sentiment: frustrated",
"urgency_score": 5,
"reply": "Thank you for reporting this...",
"escalation_summary": "Enterprise customer reports a production dashboard outage...",
"routing": {
"classify_ticket": "openai-gpt-5-nano",
"urgency_detection": "anthropic-claude-haiku-4.5",
"draft_customer_reply": "anthropic-claude-sonnet-4.6",
"escalate_complex_issue": "anthropic-claude-opus-4.7"
}
}
One request, four different models, zero model names in your application code. The cheap classifier handled the one-word category decision, Haiku scored urgency in a single fast pass, Sonnet drafted the customer-facing reply, and Opus produced the brief your on-call engineer reads. Run the password-reset ticket and the routing.escalate_complex_issue field comes back as null — the urgency score didn’t clear the threshold, and that null is real money saved.
What this actually saves you
Let’s put numbers on it. Assume an average ticket is 300 input tokens, with output tokens varying by task (40 for classification, 30 for urgency, 150 for a reply, 250 for an escalation summary). In our 7-ticket sample, 2-3 score high enough to escalate; we use 20% as a steady-state estimate.
Using DigitalOcean’s published serverless inference rates:
| Task | Model | Per-ticket cost |
|---|---|---|
| classify_ticket | GPT-5 Nano | $0.000031 |
| urgency_detection | Claude Haiku 4.5 | $0.000450 |
| draft_customer_reply | Claude Sonnet 4.6 | $0.003150 |
| escalate_complex_issue (fires ~20% of tickets) | Claude Opus 4.7 | $0.007750 |
At 100,000 tickets/month, three strategies compared:
| Strategy | Monthly cost |
|---|---|
| Hardcoded Llama 3.3 70B for everything | $109 |
| Router (cost-aware) | $518 |
| Hardcoded Claude Opus 4.7 for everything | $1,775 |
The honest result: the router isn’t the cheapest option. Hardcoded Llama 70B is. But Llama 70B writing your enterprise outage reply is the cost. You’re only saving money by treating a churn-risk ticket the same as a password reset.
The fair comparison is against the realistic alternative: once you decide Llama’s customer-facing replies aren’t good enough, the choice is Opus-for-everything or the router. The router is 71% cheaper than all-Opus while only routing the expensive Opus 4.7 model to the tickets that actually need it.
Run this math on your own ticket mix before committing. The ratio of trivial-to-complex tickets is the biggest lever: a queue that’s 80% password resets saves far more than one that’s 80% escalations.
Production checklist
Before you put this in front of real tickets:
- Log task type, latency, token usage, and selected model on every call. You can’t tune what you can’t see, and the router’s value is invisible without per-task metrics.
- Build a small eval set per task. Maybe 20 tickets per task with known-good outputs. Run it before changing pool composition. The whole point of the router is that you can swap models without code changes, but you still want to know whether the swap was an improvement.
- Keep at least one fallback in every pool. A pool of one defeats half the reason to use a router.
- Use direct model calls for controlled benchmarks. When you’re measuring a specific model’s behavior, you don’t want the router making your benchmark non-deterministic.
- Revisit routing rules quarterly. Model pricing and quality shift. The pool that was “lowest cost” six months ago might not be today.
- Treat task descriptions as production config. Version them, review changes, don’t edit them in the UI without a record.
Closing thoughts
The app you ended up with isn’t bigger than the one you started with: it’s actually smaller, because the model selection logic moved out of the code and into the router. The router is doing the work that used to be a match statement: matching tasks to models, falling back when something’s unavailable, and giving you a single place to change strategy. Serverless inference via DigitalOcean’s Inference Router enables your app more flexibility and efficiency without any of the hassle of a hardcoded setup.
From here, a few natural next steps: stream the draft_customer_reply task back to the client so agents can start reading before generation finishes; wire the escalation summaries into your real ticketing system; or stand up a second router for an unrelated workflow and reuse the same access key.
The full sample code is available in the companion repo, and the router configuration takes about five minutes in the DigitalOcean control panel.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
