By Dillon and Aadil Hayat
 using TensorFlow")
Introduction
Generative Adversarial Networks or GANs are one of the most active areas in deep learning research and development due to their incredible ability to generate synthetic results. In this blog, we will build out the basic intuition of GANs through a concrete example. This post is broken down in following way:
- Basic idea and intuition behind workings of Generative Adversarial Networks
- Implementing a GAN-based model that generates data from a simple distribution
- Visualizing and analyzing different aspects of the GAN to better understand what’s happening behind the scenes.
The code for this blog can be found here.
Generative Adversarial Networks
The basic idea behind GANs is actually very simple. At its core, a GAN includes two agents with competing objectives that work through opposing goals. This relatively simple setup results in both of the agent’s coming up with increasingly complex ways to deceive each other. This kind of situation can be modeled in Game Theory as a minimax game.
Let’s take a theoretical example of the process of money counterfeiting. In this process, we can imagine two types agents: a criminal and cop. Let us look into their competing objectives:
- Criminal’s Objective: The main objective of the criminal is to come up with complex ways of counterfeiting money such that the Cop cannot distinguish between counterfeited money and real money.
- Cop’s Objective: The main objective of the cop is to come up with complex ways so as to distinguish between counterfeited money and real money.
As this process progresses the cop develops more and more sophisticated technology to detect money counterfeiting and criminal develops more and more sophisticated technology to counterfeit money. This is the basis of what is called an Adversarial Process
Generative Adversarial Networks take advantage of Adversarial Processes to train two Neural Networks who compete with each other until a desirable equilibrium is reached. In this case, we have a Generator Network G(Z) which takes input random noise and tries to generate data very close to the dataset we have. The other network is called the Discriminator Network D(X) which takes input generated data and tries to discriminate between generated data and real data. This network at its core implements a binary classification and outputs the probability that the input data actually comes from the real dataset (as opposed to the synthetic, or fake data).
In the formal sense the objective function of this whole process can be written as:
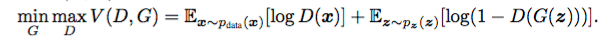
The usual desirable equilibrium point for the above defined GANs is that the Generator should model the real data and Discriminator should output the probability of 0.5 as the generated data is same as the real data – that is, it is not sure if the new data coming from the generator is real or fake with equal probability.
You might be wondering why such a complex learning process is even required? What are the advantages of learning such a model? Well, the intuition behind this and all the generative approaches follow a famous quote from Richard Feynman:
What I cannot create, I do not understand.
This is relevant because if we are able to generate real data distribution from a model then it means that we know everything that this to know about that model. A lot of time these real distributions include millions of images and we can generate them using a model that has thousands of parameters then these parameters capture the essence of the given images.
GANs have many other real-life short-term applications also which we will discuss in a later section.
Implementing GANs
In this section, we will generate a very simple data distribution and try to learn a Generator function that generates data from this distribution using GANs model described above. This section is broadly divided into 3 parts. Firstly we will write a basic function to generate a quadratic distribution (the real data distribution). Secondly, we write code for Generator and Discriminator networks. Then we will use the data and the networks to write the code for training these two networks in an adversarial way.
The objective of this implementation is to learn a new function that can generate data from the same distribution as the training data. The expectation from the training is that our Generator network should start producing data which follows the quadratic distribution. This is explained and demonstrated more in the next section. Although we are starting with very simple data distribution, this approach can be easily extended to generate data from the much more complex dataset. Few example GANs have successfully generated images of handwritten digits, faces of celebrities, animals, etc.
Generating Training Data
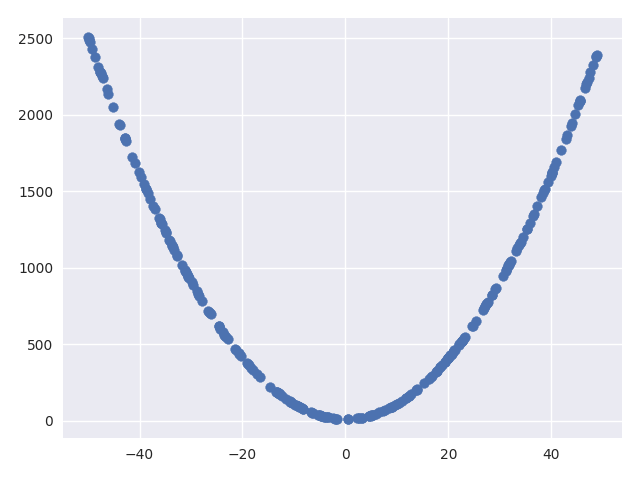
We implement our true dataset by generating random samples using numpy library and then generating the second coordinate using some kind of function. For the purpose of this demo, we have kept the function as a quadratic function for simplicity. You can play with this code to generate a dataset with more dimensions and/or more complex relation between its features such as higher degree polynomial, sine, cosine, etc.
import numpy as np
def get_y(x):
return 10 + x*x
def sample_data(n=10000, scale=100):
data = []
x = scale*(np.random.random_sample((n,))-0.5)
for i in range(n):
yi = get_y(x[i])
data.append([x[i], yi])
return np.array(data)
The generated data is very simple and can be plotted as seen here:
Generator and Discriminator Networks Implementation
We will now implement the Generator and Discriminator networks using tensorflow layers. We implement the Generator network using the following function:
def generator(Z,hsize=[16, 16],reuse=False):
with tf.variable_scope("GAN/Generator",reuse=reuse):
h1 = tf.layers.dense(Z,hsize[0],activation=tf.nn.leaky_relu)
h2 = tf.layers.dense(h1,hsize[1],activation=tf.nn.leaky_relu)
out = tf.layers.dense(h2,2)
return out
This function takes in the placeholder for random samples (Z), an array hsize for the number of units in the 2 hidden layers and a reuse variable which is used for reusing the same layers. Using these inputs it creates a fully connected neural network of 2 hidden layers with given number of nodes. The output of this function is a 2-dimensional vector which corresponds to the dimensions of the real dataset that we are trying to learn. The above function can be easily modified to include more hidden layers, different types of layers, different activation and different output mappings.
We implement the Discriminator network using the following function:
def discriminator(X,hsize=[16, 16],reuse=False):
with tf.variable_scope("GAN/Discriminator",reuse=reuse):
h1 = tf.layers.dense(X,hsize[0],activation=tf.nn.leaky_relu)
h2 = tf.layers.dense(h1,hsize[1],activation=tf.nn.leaky_relu)
h3 = tf.layers.dense(h2,2)
out = tf.layers.dense(h3,1)
return out, h3
This function takes input placeholder for the samples from the vector space of real dataset. The samples can be both real samples and samples generated from the Generator network. Similar to the Generator network above it also takes input hsize and reuse. We use 3 hidden layers for the Discriminator out of which first 2 layers size we take input. We fix the size of the third hidden layer to 2 so that we can visualize the transformed feature space in a 2D plane as explained in the later section. The output of this function is a logit prediction for the given X and the output of the last layer which is the feature transformation learned by Discriminator for X. The logit function is the inverse of the sigmoid function which is used to represent the logarithm of the odds (ratio of the probability of variable being 1 to that of it being 0).
Adversarial Training
For the purpose of training we define the following placeholders X and Z for real samples and random noise samples respectively:
X = tf.placeholder(tf.float32,[None,2])
Z = tf.placeholder(tf.float32,[None,2])
We also need to create the graph for generating samples from Generator network and feeding real and generated samples to the Discriminator network. This is done by using the functions and placeholders defined above:
G_sample = generator(Z)
r_logits, r_rep = discriminator(X)
f_logits, g_rep = discriminator(G_sample,reuse=True)
Using the logits for generated data and real data we define the loss functions for the Generator and Discriminator networks as follows:
disc_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=r_logits,labels=tf.ones_like(r_logits)) + tf.nn.sigmoid_cross_entropy_with_logits(logits=f_logits,labels=tf.zeros_like(f_logits)))
gen_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=f_logits,labels=tf.ones_like(f_logits)))
These losses are sigmoid cross entropy based losses using the equations we defined above. This is a commonly used loss function for so-called discrete classification. It takes as input the logit (which is given by our discriminator network) and true labels for each sample. It then calculates the error for each sample. We are using the optimized version of this as implemented by TensorFlow which is more stable then directly taking calculating cross entropy. For more details, you can check out the relevant TensorFlow API here.
Next, we define the optimizers for the two networks using the loss functions defined above and scope of the layers defined in the generator and discriminator functions. We use RMSProp Optimizer for both the networks with the learning rate as 0.001. Using the scope we fetch the weights/variables for the given network only.
gen_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope="GAN/Generator")
disc_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope="GAN/Discriminator")
gen_step = tf.train.RMSPropOptimizer(learning_rate=0.001).minimize(gen_loss,var_list = gen_vars) # G Train step
disc_step = tf.train.RMSPropOptimizer(learning_rate=0.001).minimize(disc_loss,var_list = disc_vars) # D Train step
We then train both the networks in an alternating way for the required number of steps:
for i in range(100001):
X_batch = sample_data(n=batch_size)
Z_batch = sample_Z(batch_size, 2)
_, dloss = sess.run([disc_step, disc_loss], feed_dict={X: X_batch, Z: Z_batch})
_, gloss = sess.run([gen_step, gen_loss], feed_dict={Z: Z_batch})
print "Iterations: %d\t Discriminator loss: %.4f\t Generator loss: %.4f"%(i,dloss,gloss)
The above code can be modified to include more complex training procedures such as running multiple steps of the discriminator and/or generator update, fetching the features of the real and generated samples and plotting the generated samples. Please refer to the code repository for such modifications.
Analyzing GANs
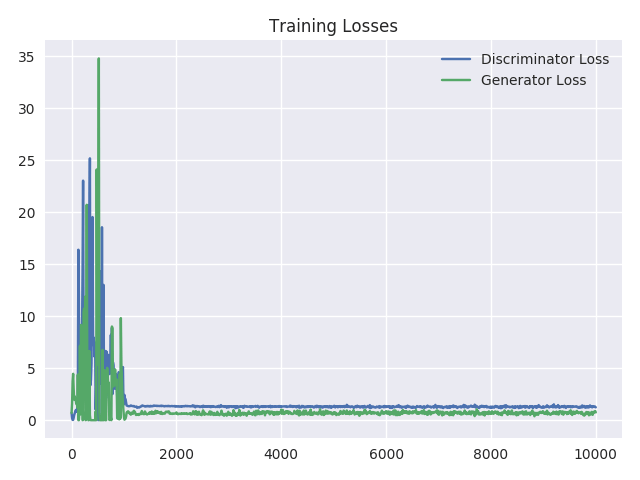
Visualizing the Training losses
To better understand what is happening in this process, we can plot the training losses after every 10 iterations. From the plot below we can see how changes in loss decrease gradually and that loss becomes almost constant towards the end of training. This negligible change in the loss of both Discriminator
and Generator indicates equilibrium.
Visualizing Samples during Training
We can also plot the real and generated samples after every 1000 iterations of training. These plots visualize how the Generator network starts with a random initial mapping between the input and dataset vector space and then it gradually progresses to resemble the real dataset samples. As you can see, the “fake” sample starts looking more and more like the “real” data distribution.
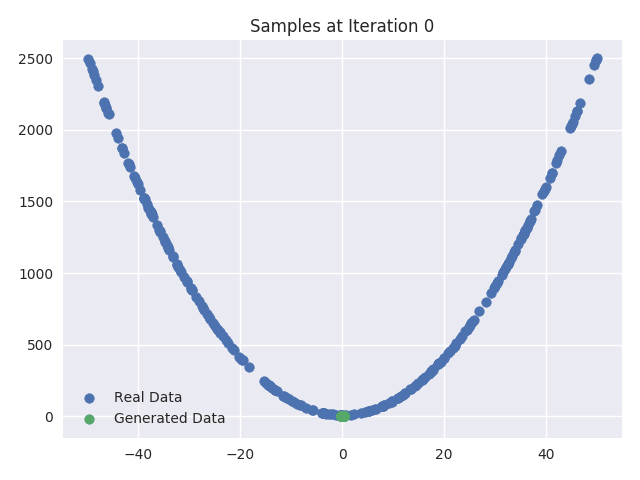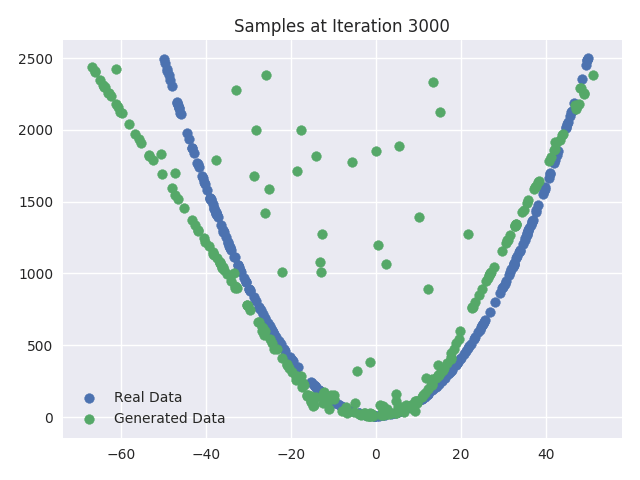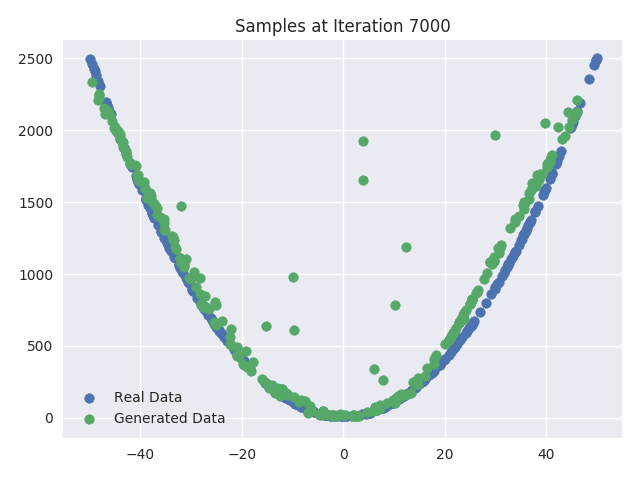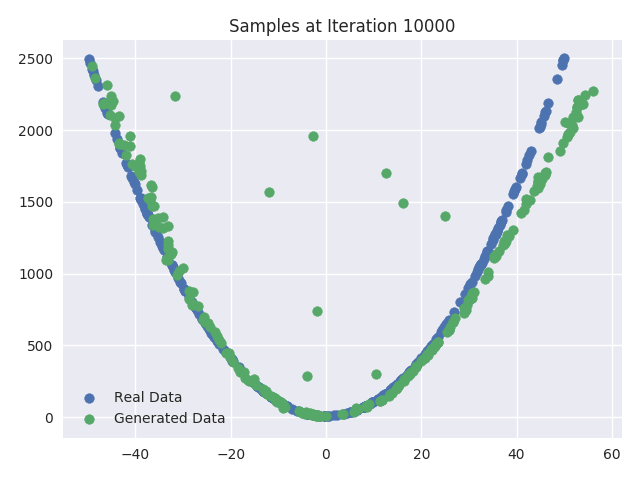
Visualizing the Generator Update
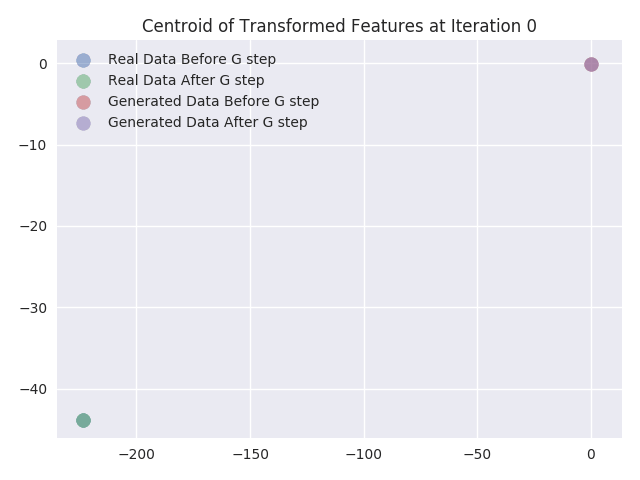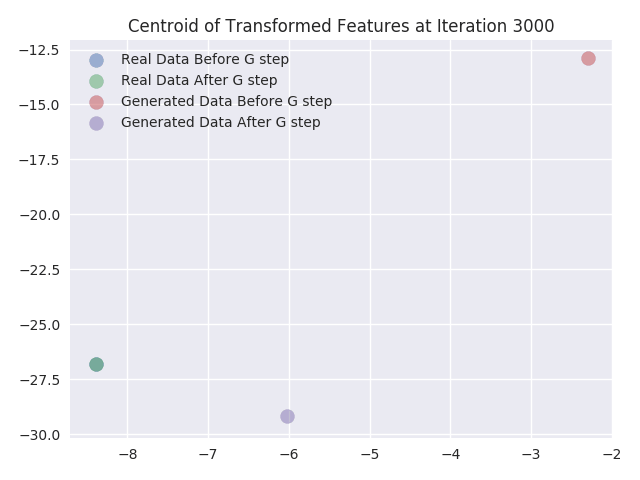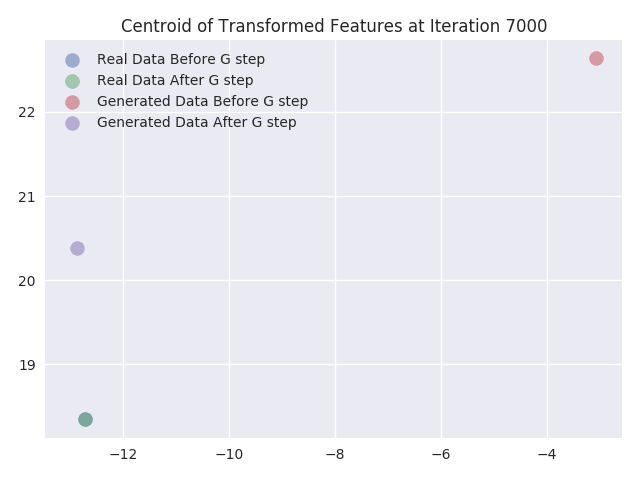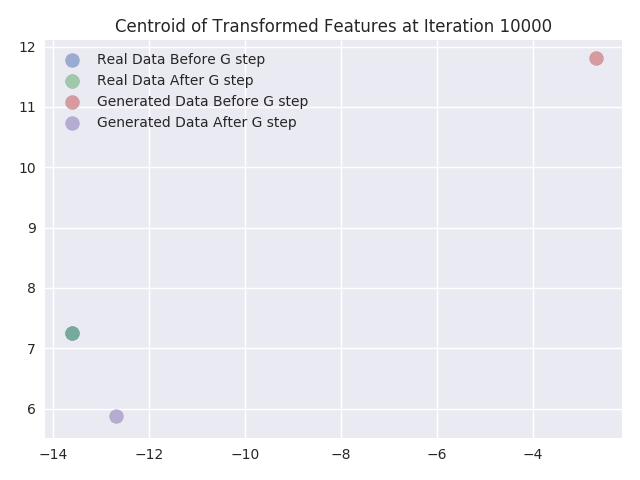
In this section, we visualize the effect of updating the Generator network weights within the adversarial trainingprocess. We do this by plotting the activations of the last hidden layer of Discriminator network. We chose the last hidden layer to be of size 2 so that it would be easy to plot without requiring dimensionality reduction (i.e. the transformation of the input sample to a different vector space). We are interested in visualizing the feature transformation function learned by the Discriminator network. This function is what our network learns so that the real and fake data are separable.
We plot the feature transform of the real and generated samples as learned by the Discriminator network’s last layer before and after we update the weights of the Generator network. We also plot the centroids of the points that we obtain after the feature transformation of the input samples. Finally, we calculate the centroids of the points separately for both real and fake data, before and after the generator update. From the plots we can infer following things:
- As expected there is no change in the transformed features of the real data samples. From the plots, we can see they totally coincide.
- From the centroids, we can see that centroid of the features of generated data samples almost always moves towards the centroid of the features of real data samples.
- We can also see that as the iterations increase the transformed features of real samples get more and more mixed with transformed features of generated samples. This is also expected because at the end of training the Discriminator network should not be able to distinguish between real and generated samples. Hence at the end of training transformed features for both the samples should coincide.

Conclusion and Future Work
We have implemented a proof-of-concept GAN model for generating data from a very simple data distribution. As an exercise for the curious reader, we recommend modifying the above code to do the following:
- Visualize the before and after of the Discriminator update.
- Change the activation functions of the layers and see the difference in training and generated samples.
- Add more layers and different types of layers and see the effect on the training time and the stability of the training.
- Modify the code for generating data to include data from 2 different curves
- Modify the above code to work with more complex data such as MNIST, CIFAR-10, etc.
In future work, we will discuss limitations of the GANs and the modifications that are required to solve them.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
This was good overall, I just think we need to also know how this code will be deployed to a server on Digital ocean and use it to train more GAN models
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
