AI Technical Writer
: Alternative to Multi-Layer Perceptron?")
Introduction
Every once in a while, a new idea comes along in machine learning that challenges and opens up a new way of thinking. Kolmogorov-Arnold Networks (KANs) are one of those ideas. Introduced in the year 2024 paper, KANs offer a fresh alternative to the widely used Multi-Layer Perceptrons (MLPs)—the classic building blocks of deep learning.
MLPs are powerful because they can model complex, nonlinear relationships between inputs and outputs. They’ve been the go-to architecture for many problems in computer vision, natural language processing, and more. But they rely heavily on matrix multiplications and fixed activation functions, which can limit their flexibility and interpretability.
KANs take a different path. Instead of using weights and activations in the traditional way, they apply learnable functions directly to individual connections between neurons. This simple shift leads to models that are not only more interpretable but can also outperform MLPs on certain tasks, with fewer parameters and better generalization.
In this article, we’ll break down the core ideas behind KANs, understand how they work, and explore why they could represent a new chapter in the evolution of deep learning.
But are KANs the ultimate solution for building models that understand and predict things?
Despite their widespread use, MLPs do have some downsides. For instance, in models like transformers, MLPs use up a lot of the parameters that aren’t involved in embedding data. Plus, they’re often difficult to understand, making them a black box model, compared to other parts of the model, like attention layers, which can make it harder to figure out why they make certain predictions without additional analysis tools.
Prerequisites
- Basic Calculus and Linear Algebra: Understanding differentiation, integration, and matrix operations.
- Elementary Real Analysis: Familiarity with continuous functions, series, and function spaces.
- Multivariable Calculus: Knowledge of partial derivatives and multivariable functions.
- Dynamical Systems: Exposure to basic concepts such as phase spaces, stability, and fixed points.
- Machine Learning Basics: Understanding of neural networks, activation functions, and training algorithms.
These concepts will help you better grasp the concept of KANs.
Why is it considered an alternative to MLP?
While MLPs are all about fixed activation functions on nodes, KANs flip the script by putting learnable activation functions on the edges. This means each weight parameter in a KAN is replaced by a learnable 1D function, making the network more flexible. Surprisingly, despite this added complexity, KANs often require smaller computation graphs than MLPs. In fact, in some cases, a simpler KAN can outperform a much larger MLP both in accuracy and parameter efficiency, like in solving partial differential equations (PDEs).
As stated in the research paper, for PDE solving, a 2-Layer width-10 KAN is 100 times more accurate than a 4-Layer width-100 MLP (10−7 vs 10−5 MSE) and 100 times more parameter efficient (102 vs 104 parameters). As stated in the research paper, for PDE solving, a 2-Layer width-10 KAN is 100 times more accurate than a 4-Layer width-100 MLP (10−7 vs 10−5 MSE) and 100 times more parameter efficient (102 vs 104 parameters).
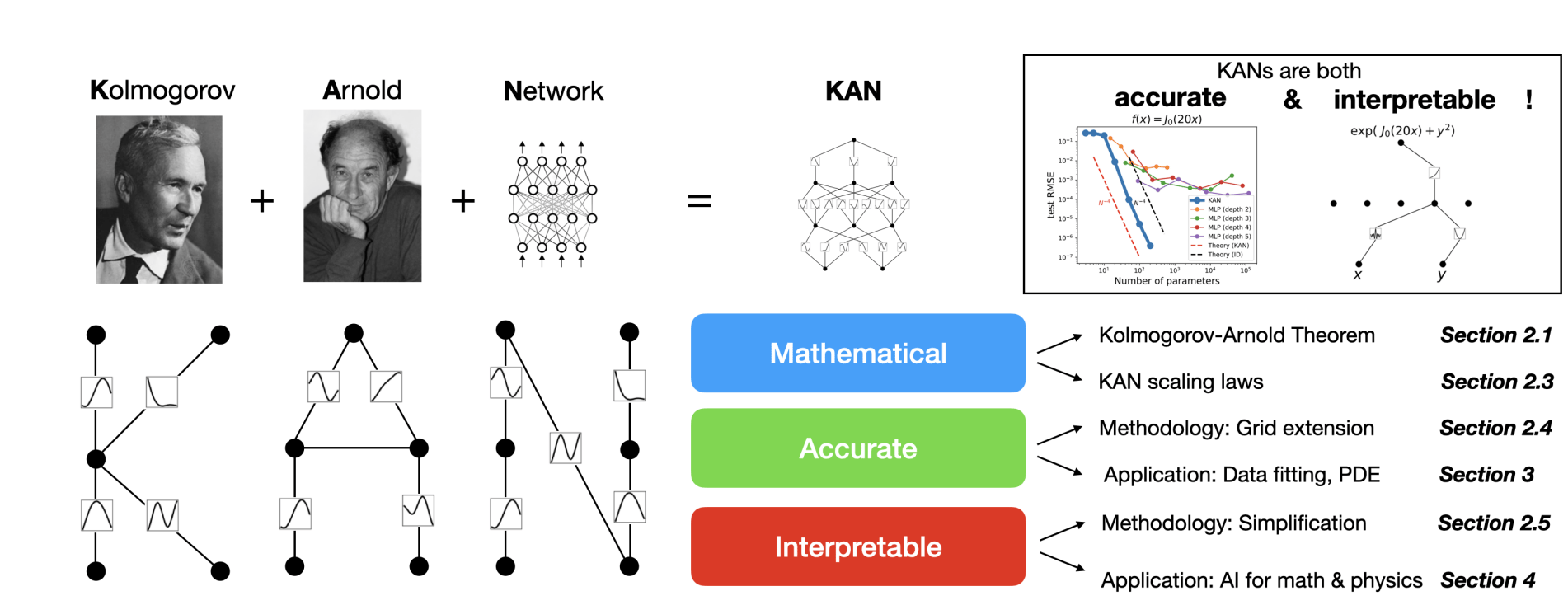
Kolmogorov-Arnold networks are in honor of two great late mathematicians, Andrey Kolmogorov and Vladimir Arnold (Source)
Other research papers have also attempted to apply this theorem to train machine learning models in the past. However, this particular paper takes a step further by expanding the idea. It introduces a more generalized approach so that we can train neural networks of any size and complexity using backpropagation.
What is KAN?
KANs are based on the Kolmogorov-Arnold representation theorem. If f is a multivariate continuous function on a bounded domain, then f can be written as a finite composition of continuous functions of a single variable and the binary operation of addition.
More specifically, for a smooth:
f : [0, 1]n → R,
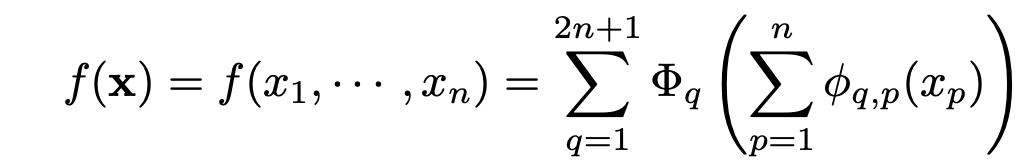
To understand this, let us take an example of a multivariate equation like this,
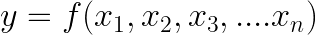
This is a multivariate function because here, y depends upon x1, x2, …, xn.
According to the theorem, we can express this as a combination of single-variable functions. This allows us to break down the multivariable equation into several individual equations, each involving one variable and another function of it, and so forth. Then sum up the outputs of all of these functions and pass that sum through yet another univariate function, f, as shown here.
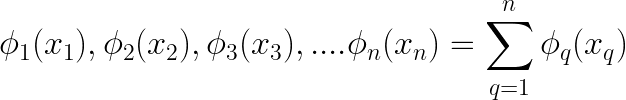
Univariate Function
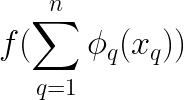
Passing the summed output to another function (Single composition)
Further, instead of making one composition, we do multiple compositions, such as `m` different compositions and sum them up.
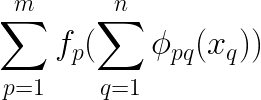
Also, we can rewrite the above equation to,
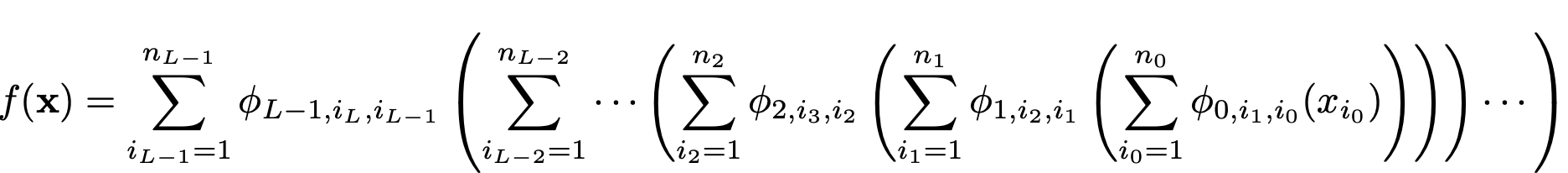
Overview of the Paper
The KAN’s research paper shows that addition is the only real multi-input operation we need because any complicated function can be broken down into simple one-variable functions and then added together.
To put it simply, even if a problem depends on many different things, we can break it into smaller, easier pieces—each focusing on just one thing at a time. Once we understand these small pieces, we can add them up to solve the bigger problem. Machine learning techniques, like backpropagation, help us figure out the best way to learn and combine these smaller parts.
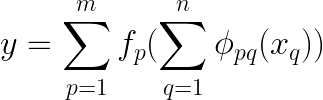
The original Kolmogorov-Arnold representation equation aligns with a 2-layer KAN having a shape of [n, 2n + 1, 1].
It’s worth noting that all operations within this representation are differentiable, enabling us to train KANs using backpropagation.
The above equation shows that the outer sum loops through all of the different compositions from 1 to m. Further, the inner sum loops through each input variable x1 to xn for each outer function q. In matrix form, this can be represented below.
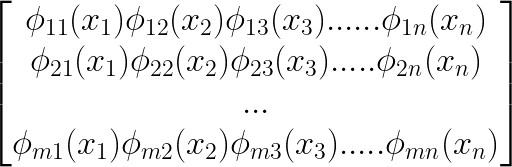
Here, the inner function can be depicted as a matrix filled with various activation functions (denoted as ɸ). Additionally, we have an input vector (x) with `n` features, which will traverse through all the activation functions. Please note here that ɸ represents the activation function and not the weights. These activation functions are called B-Splines. To add here, each of these functions is a simple polynomial curve. The curves depend on the input of `x.`
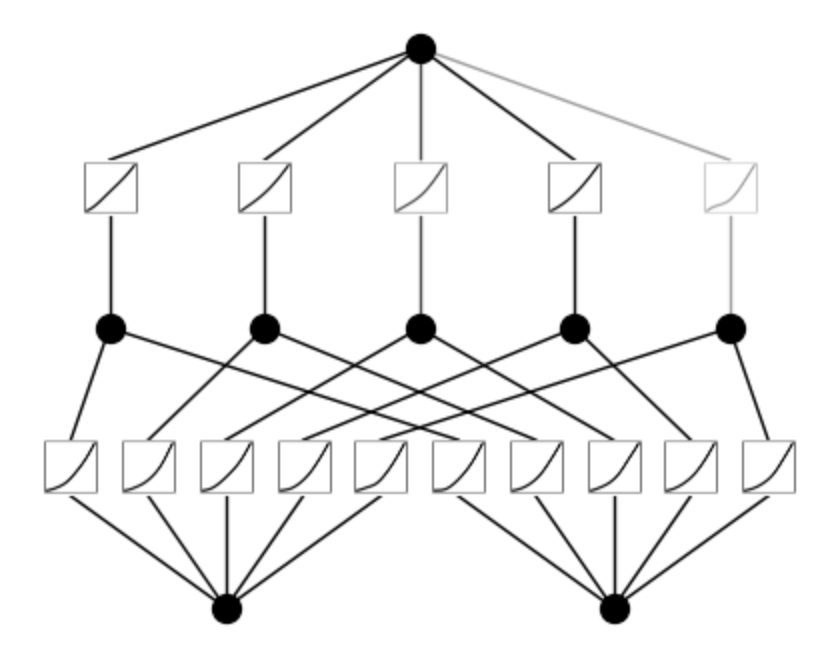
Visual Representation of KAN
Here is a visual representation of training a 3-layer KAN,
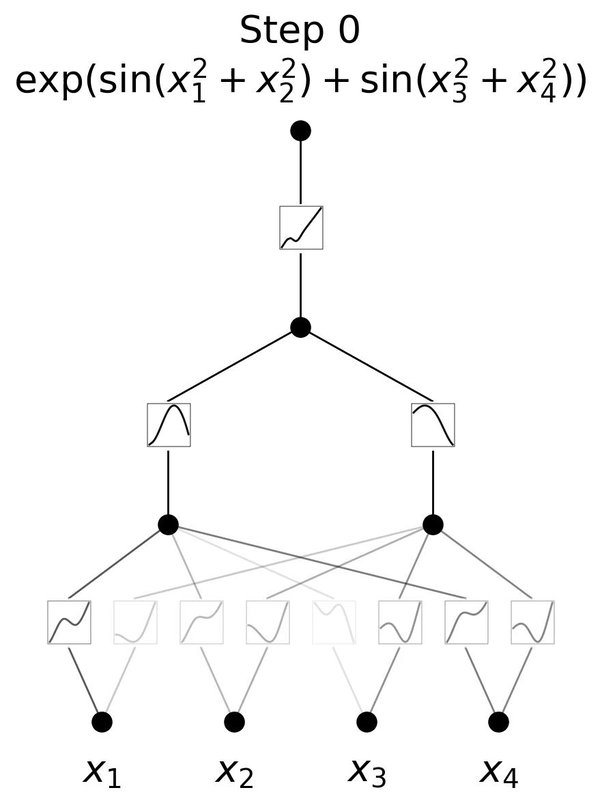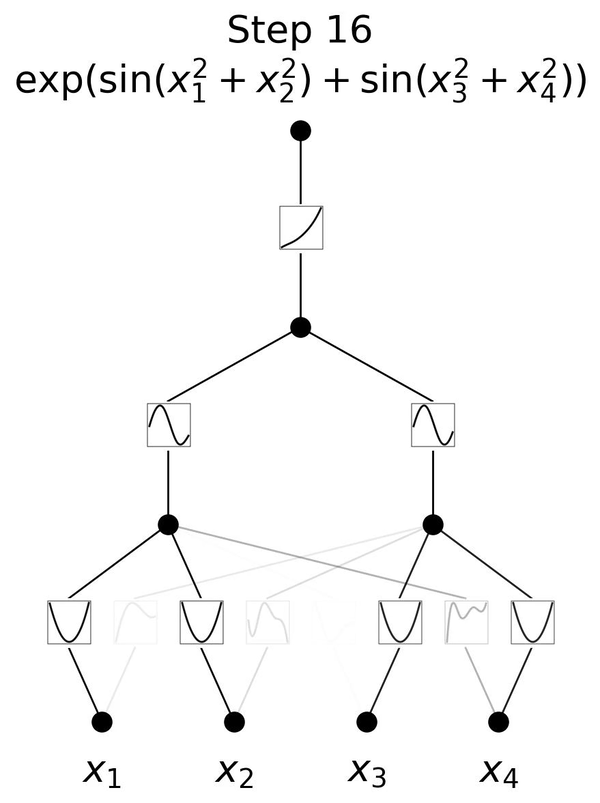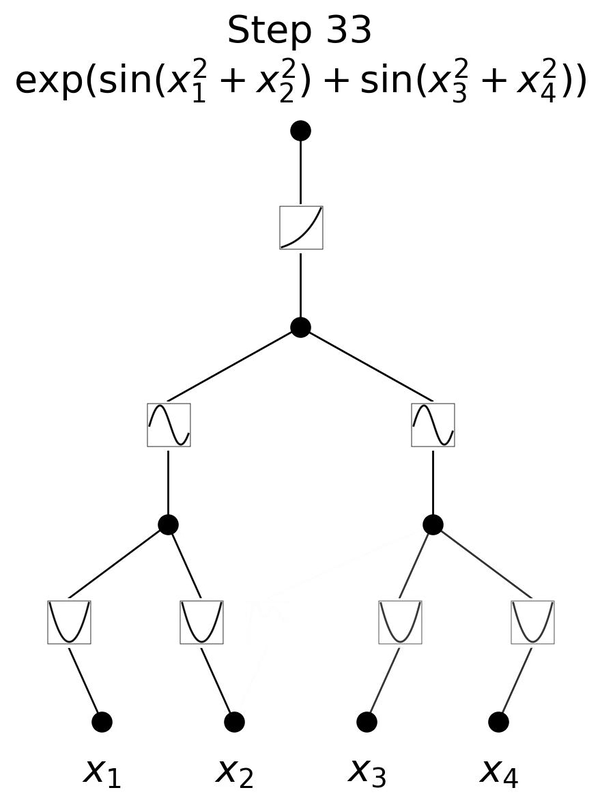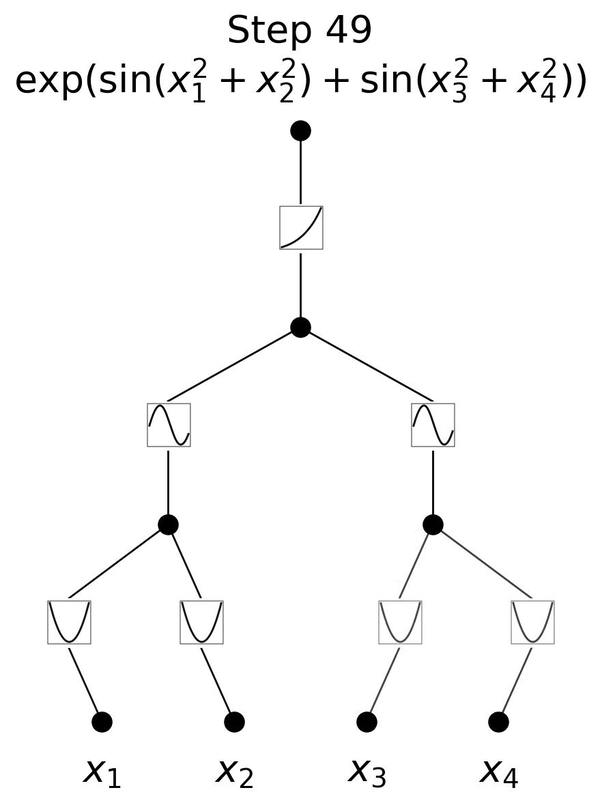
Visual representation of KAN- Notice how the value of x changes the curve, and that in turn, changes the activation values
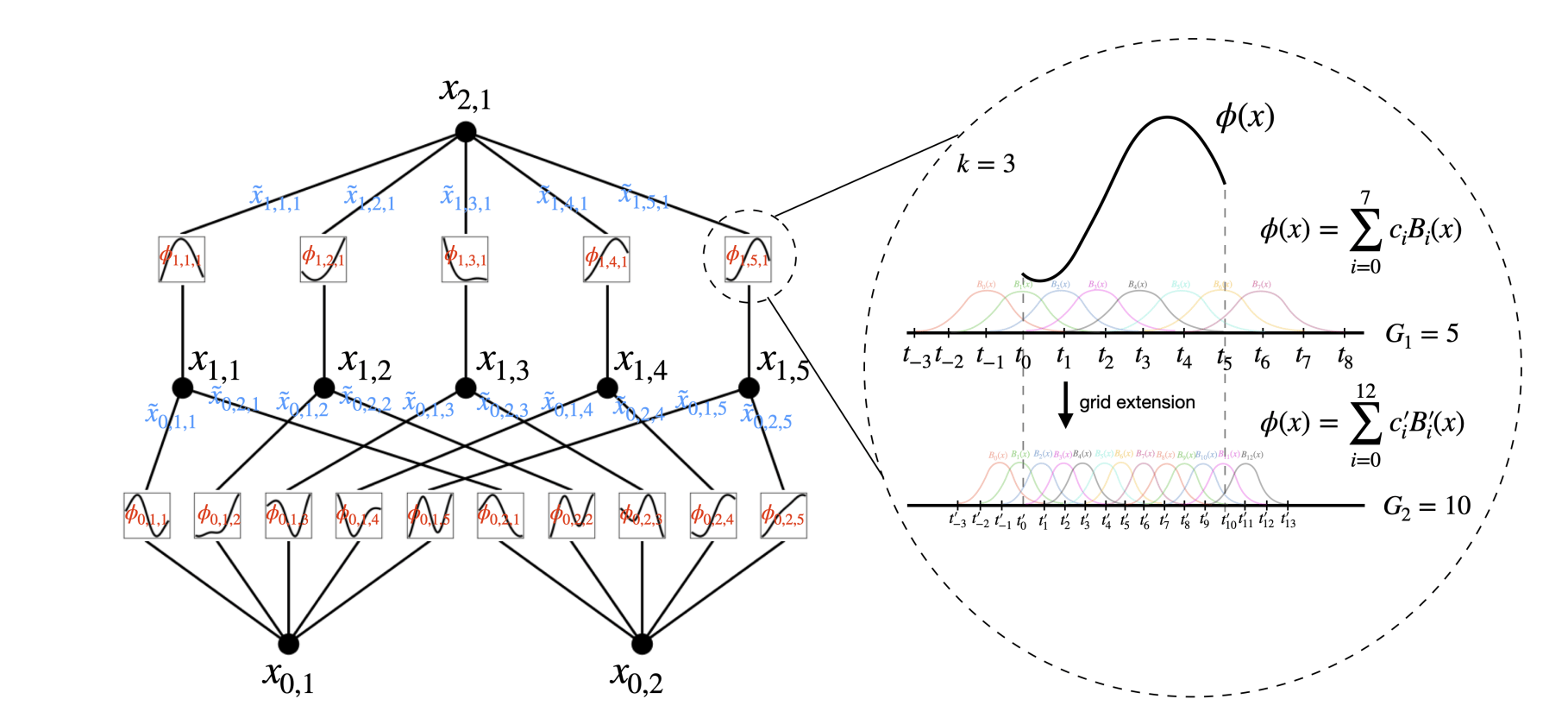
Left: Notations of activations that flow through the network. Right: An activation function is parameterized as a B-spline, which allows switching between coarse-grained and fine-grained grids.
In the given illustration, there are two input features and a first output layer consisting of five nodes. Each output from these nodes undergoes five distinct parameterized univariate activation functions. The resulting activations are then summed to yield the features for each output node. This entire process constitutes a single KAN layer with an input dimension of 2 and an output dimension of 5. Like a multi-layer perceptron (MLP), multiple KAN layers can be stacked on top of each other to generate a long, deeper neural network. The output of one layer is the input to the next.
Further, like MLPs, the computation graph is fully differentiable, as it relies on differentiable activation functions and summation at the node level, enabling training via backpropagation and gradient descent.
Difference between MLPs and KANs
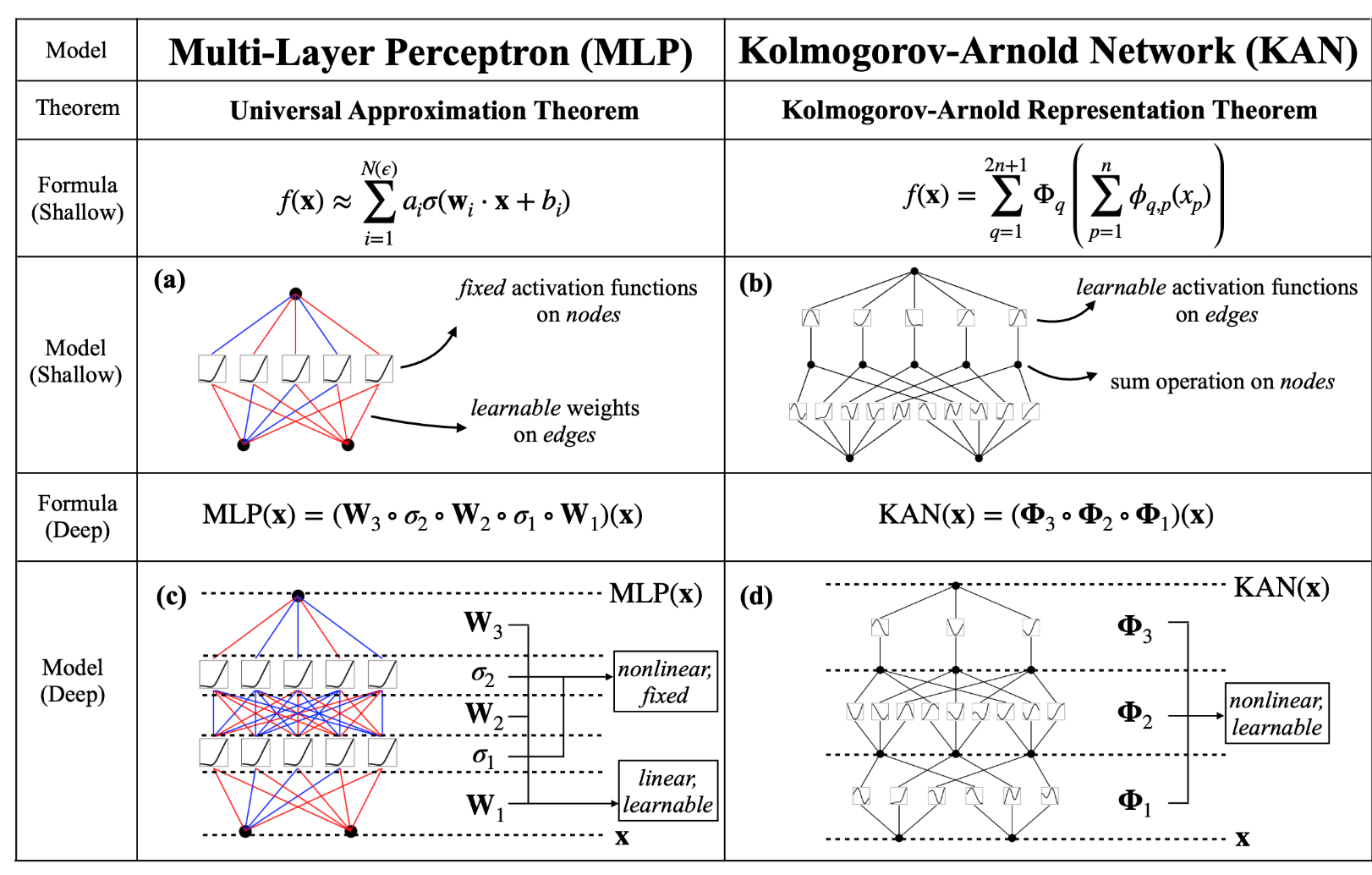
One key differentiator between the two networks is that MLPs place fixed activation functions on the nodes. In contrast, KANs place learnable activation functions along the edges, and the nodes sum them up.
In MLPs, activation functions are parameter-free and perform fixed operations on inputs, while learnable parameters are just linear weights and biases. In contrast, KANs lack linear weight matrices entirely; instead, each weight parameter is substituted with a learnable non-linear activation function.
Also, considering the instability issue with traditional activation functions in neural networks makes training quite challenging. To address this, the authors of KANs employ B-splines, which offer greater stability and bounded behavior.
B-Splines
Now, let’s understand B-splines briefly. B-splines are essentially curves made up of polynomial segments, each with a specified level of smoothness. Picture each segment as a small curve, where multiple control points influence the shape. Unlike simpler spline curves, which rely on only two control points per segment, B-splines use more, leading to smoother and more adaptable curves.
The magic of B-splines lies in their local impact. Adjusting one control point affects only the nearby section of the curve, leaving the rest undisturbed. This property offers remarkable advantages, especially in maintaining smoothness and facilitating differentiability, which is crucial for effective backpropagation during training.
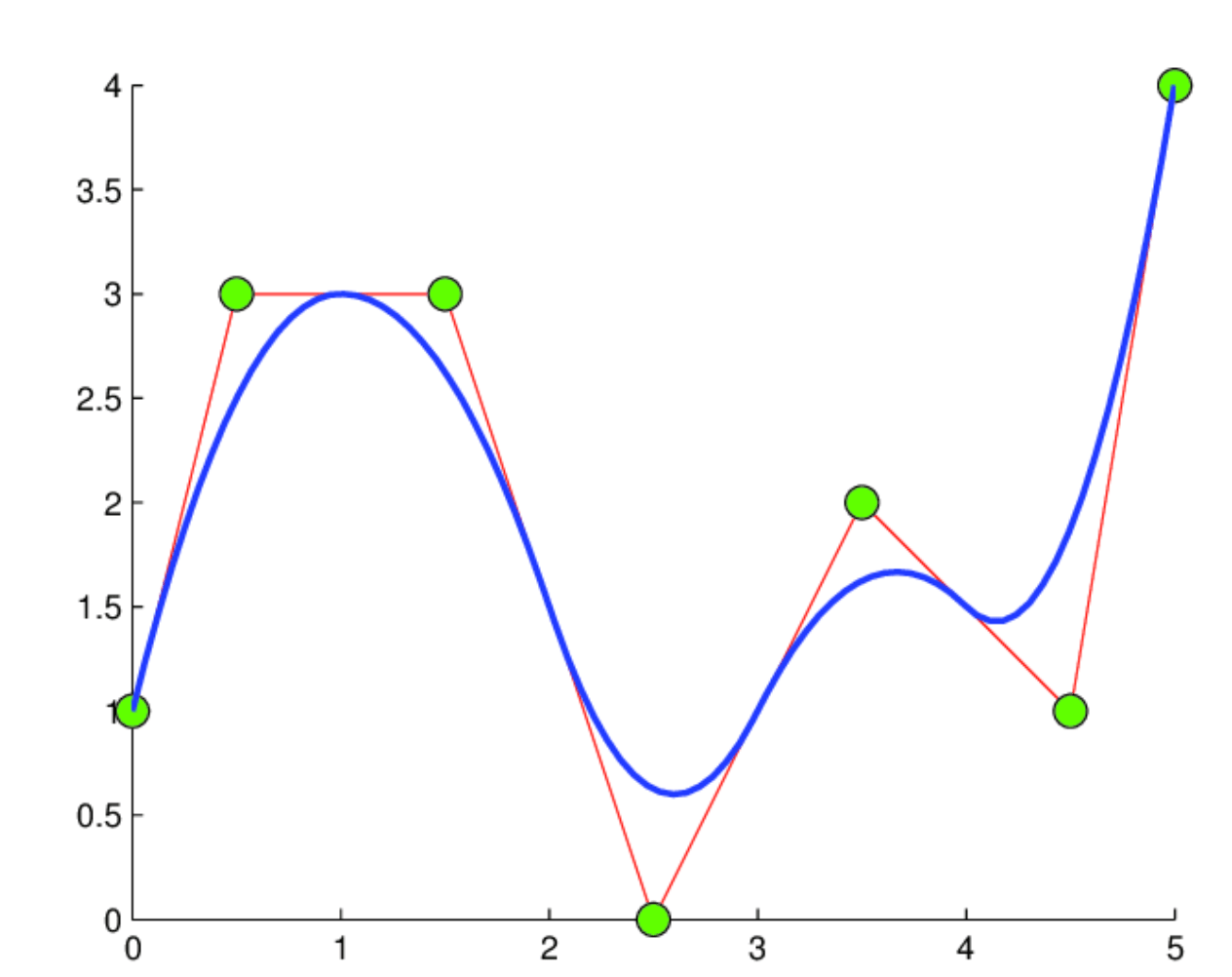
A quadratic (p = 2) B-spline curve (Source)
Training KANs
Backpropagation is a crucial technique for lowering the loss in machine learning. It is crucial for training neural networks by iteratively adjusting their parameters based on observed errors. In KANs, backpropagation is essential for fine-tuning network parameters, including edge weights and coefficients of learnable activation functions.
Training KANs begins with the random initialization of network parameters. The network then undergoes forward and backward passes: input data is fed through the network to generate predictions, which are compared to actual labels to calculate loss. Backpropagation computes gradients of the loss with respect to each parameter using the chain rule of calculus. These gradients guide the parameter updates through methods like gradient descent, stochastic gradient descent, or Adam optimization.
A key challenge in training KANs is ensuring stability and convergence during optimization. Researchers use techniques such as dropout and weight decay for regularization and carefully select optimization algorithms and learning rates to address this. Additionally, batch normalization and layer normalization techniques help stabilize training and accelerate convergence.
KANs or MLPs?
The main drawback of KANs is their slow training speed, which is about 10 times slower than MLPs with the same number of parameters. However, the research has not yet focused much on optimizing KANs’ efficiency, so there is still scope for improvement. If you need fast training, go for MLPs. But if you prioritize interpretability and accuracy, and don’t mind slower training, KANs are worth a try.
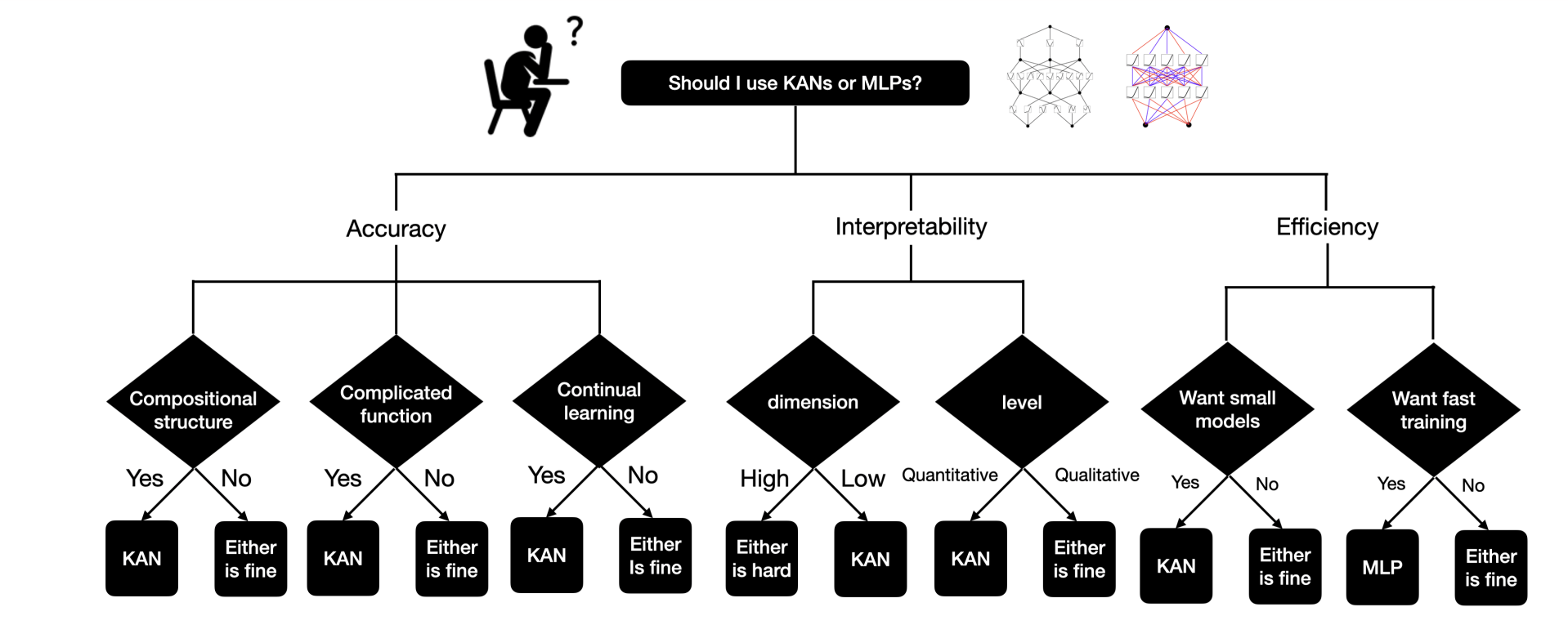
KANs or MLPs(Source)
The key differentiators between MLPs and KANs are:
(i) Activation functions are on edges instead of on nodes,
(ii) Activation functions are learnable instead of fixed.
Advantages of KAN’s
- KAN’s can learn their activation functions, thus making them more expressive than standard MLPs, and able to learn functions with fewer parameters.
- Further, the paper shows that KANs outperform MLPs using significantly fewer parameters.
- A technique called grid extension allows for fine-tuning KANs by making the spline control grids finer, increasing accuracy without retraining from scratch. This adds more parameters to the model for higher variance and expressiveness.
- KANs are less prone to catastrophic forgetting due to B-splines’ local control.
- Catastrophic forgetting occurs when a trained neural network forgets previous training upon fine-tuning with new data.
- In MLPs, weights change globally, causing the network to forget old data when learning new data.
- In KANs, adjusting control points of splines affects only local regions, preserving previous training.
- The paper contains many other interesting insights and techniques related to KANs; hence, we highly recommend that our readers read it.
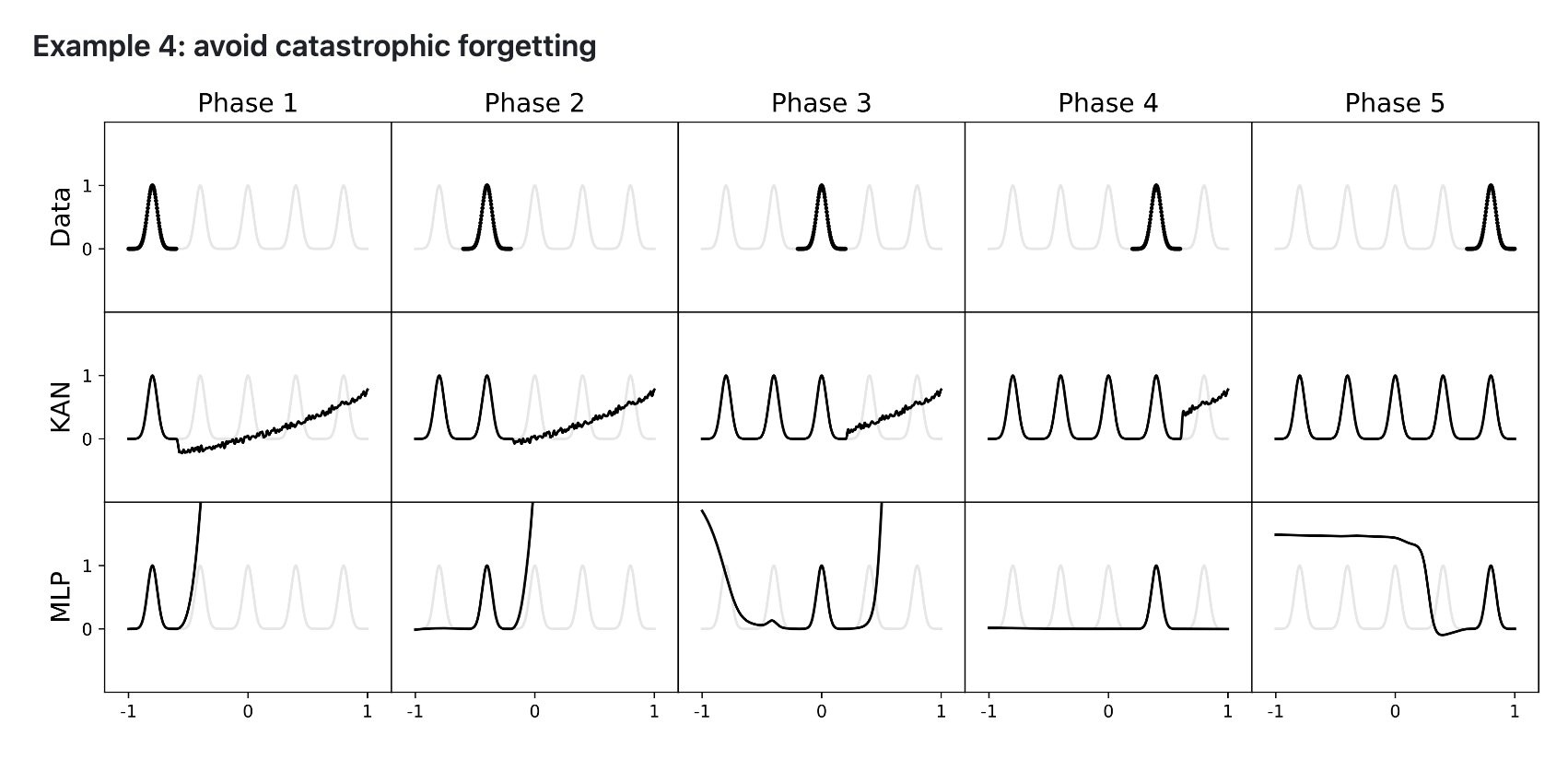
An example of catastrophic forgetting in MLPs and KANs
Get KANs working
Install via GitHub
!pip install git+https://github.com/KindXiaoming/pykan.git
Install via PyPI:
!pip install pykan
Requirements
# python==3.9.7
matplotlib==3.6.2
numpy==1.24.4
scikit_learn==1.1.3
setuptools==65.5.0
sympy==1.11.1
torch==2.2.2
tqdm==4.66.2
Initialize KAN and create a KAN.
from kan import *
# create a KAN: 2D inputs, 1D output, and 5 hidden neurons. cubic spline (k=3), 5 grid intervals (grid=5).
model = KAN(width=[2,5,1], grid=5, k=3, seed=0)
# create dataset f(x,y) = exp(sin(pi*x)+y^2)
f = lambda x: torch.exp(torch.sin(torch.pi*x[:,[0]]) + x[:,[1]]**2)
dataset = create_dataset(f, n_var=2)
dataset['train_input'].shape, dataset['train_label'].shape
# plot KAN at initialization
model(dataset['train_input']);
model.plot(beta=100)
# train the model
model.train(dataset, opt="LBFGS", steps=20, lamb=0.01, lamb_entropy=10.);
model.plot()
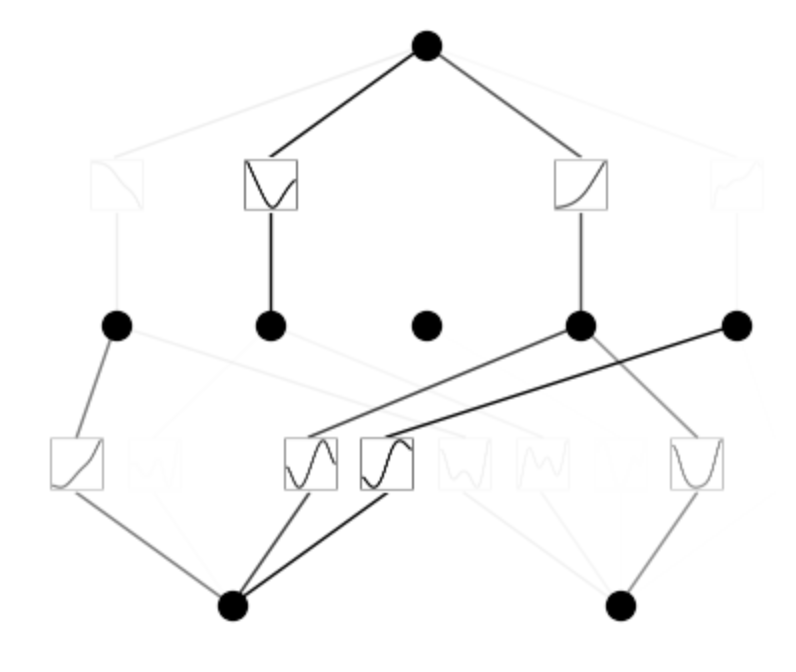
model.prune()
model.plot(mask=True)
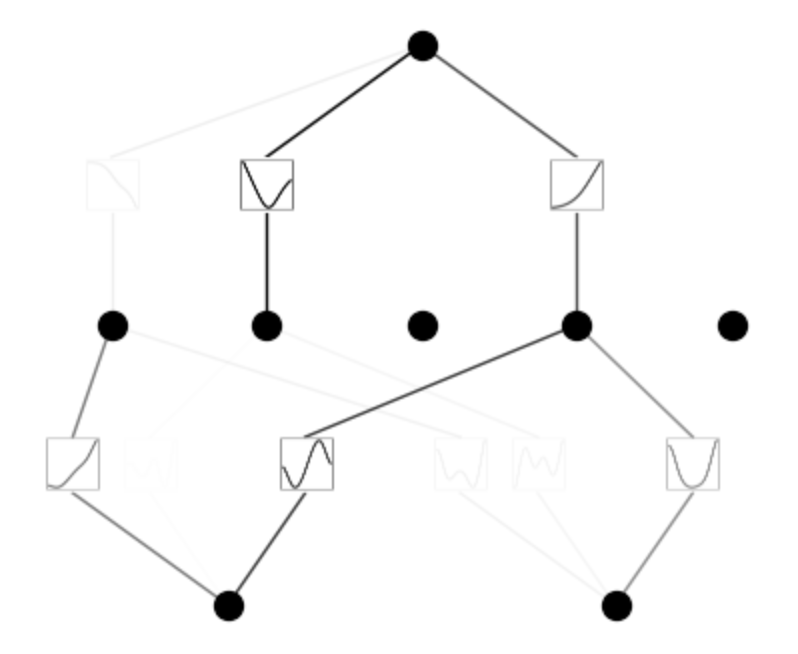
model = model.prune()
model(dataset['train_input'])
model.plot()
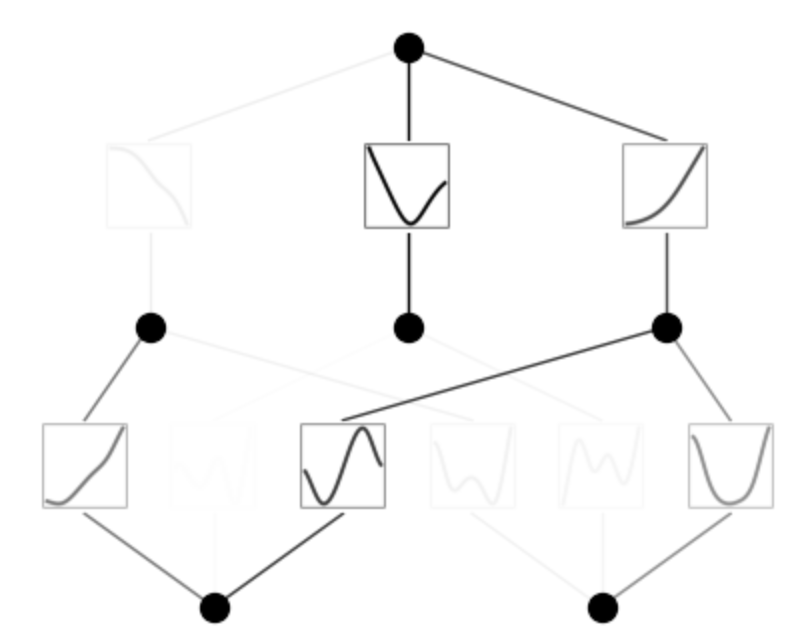
model.train(dataset, opt="LBFGS", steps=50);
train loss: 2.09e-03 | test loss: 2.17e-03 | reg: 1.64e+01 : 100%|██| 50/50 [00:20<00:00, 2.41it/s]
model.plot()
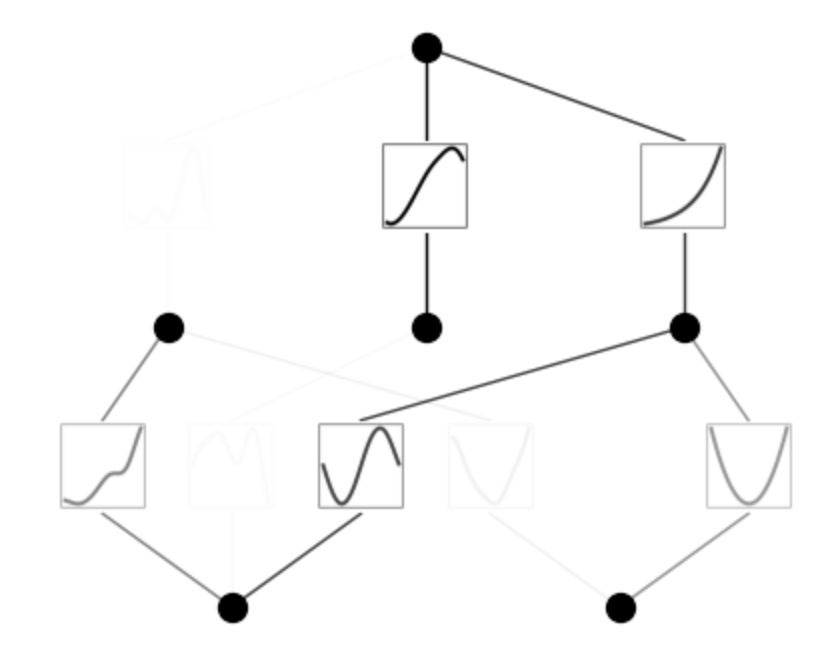
mode = "auto" # "manual"
if mode == "manual":
# manual mode
model.fix_symbolic(0,0,0,'sin');
model.fix_symbolic(0,1,0,'x^2');
model.fix_symbolic(1,0,0,'exp');
elif mode == "auto":
# automatic mode
lib = ['x','x^2','x^3','x^4','exp','log','sqrt','tanh','sin','abs']
model.auto_symbolic(lib=lib)
fixing (0,0,0) with log, r2=0.9692028164863586
fixing (0,0,1) with tanh, r2=0.6073551774024963
fixing (0,0,2) with sin, r2=0.9998868107795715
fixing (0,1,0) with sin, r2=0.9929550886154175
fixing (0,1,1) with sin, r2=0.8769869804382324
fixing (0,1,2) with x^2, r2=0.9999980926513672
fixing (1,0,0) with tanh, r2=0.902226448059082
fixing (1,1,0) with abs, r2=0.9792929291725159
fixing (1,2,0) with exp, r2=0.9999933242797852
model.train(dataset, opt="LBFGS", steps=50);
train loss: 1.02e-05 | test loss: 1.03e-05 | reg: 1.10e+03 : 100%|██| 50/50 [00:09<00:00, 5.22it/s]
Summary of KANs’ Limitations and Future Directions
As per the research, we’ve found that KANs outperform MLPs in scientific tasks like fitting physical equations and solving PDEs. They show promise for complex problems such as the Navier-Stokes equations and density functional theory. KANs could also enhance machine learning models, like transformers, potentially creating “kansformers.”
KANs excel because they communicate in the “language” of science functions. This makes them ideal for AI-scientist collaboration, enabling easier and more effective interaction between AI and researchers. Instead of aiming for fully automated AI scientists, developing AI that assists scientists by understanding their specific needs and preferences is more practical.
Further, significant concerns need to be addressed before KANs can potentially replace MLPs in machine learning. The main issue is that KANs can’t utilize GPU parallel processing, preventing them from taking advantage of the fast-batched matrix multiplications that GPUs offer. This limitation means KANs train very slowly since their different activation functions can’t efficiently leverage batch computation or process multiple data points in parallel. Hence, if speed is crucial, MLPs are better. However, if you prioritize interpretability and accuracy and can tolerate slower training, KANs are a good choice.
Additionally, the authors haven’t tested KANs on large machine-learning datasets, so it’s unclear if they offer any advantage over MLPs in real-world scenarios.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
