By Gbadebo Bello and Matt Abrams

El autor seleccionó Free and Open Source Fund para recibir una donación como parte del programa Write for DOnations.
Introducción
La extracción de datos de la web (web scraping) es un proceso que automatiza la recopilación de datos de Internet. En general, conlleva la implementación de un rastreador (crawler) que navega por la web de forma automática y extrae datos de páginas seleccionadas. Hay muchos motivos por los cuales se puede querer utilizar este proceso. El principal es que agiliza la recopilación en gran medida al eliminar el proceso manual de obtención de datos. La extracción de datos también es una buena solución cuando se quieren o deben obtener datos de un sitio web, pero este no proporciona una API.
En este tutorial, creará una aplicación de extracción de datos web utilizando Node.js y Puppeteer. La complejidad de su aplicación irá aumentando a medida que avance. Primero, programará su aplicación para que abra Chromium y cargue un sitio web especial diseñado como espacio aislado para la extracción de datos web: books.toscrape.com. En los dos pasos siguientes, extraerá todos los libros de una sola página de books.toscrape y, luego, de varias. En los pasos restantes, filtrará la extracción por categoría de libros y, a continuación, guardará sus datos como archivo JSON.
Advertencia: Los aspectos éticos y legales de la extracción de datos de la web son muy complejos y están en constante evolución. También difieren según la ubicación desde la que se realice, la ubicación de los datos y el sitio web en cuestión. En este tutorial, se extraen datos de un sitio web especial, books.toscrape.com, que está diseñado específicamente para probar aplicaciones de extracción de datos. La extracción de cualquier otro dominio queda fuera del alcance de este tutorial.
Requisitos previos
- Node.js instalado en su equipo de desarrollo. Este tutorial se probó en Node.js versión 12.18.3 y npm versión 6.14.6. Puede seguir esta guía para instalar Node.js en macOS o Ubuntu 18.04 o esta otra para instalar Node.js en Ubuntu 18.04 utilizando un PPA.
Paso 1: Configurar el extractor de datos web
Con Node.js instalado, puede comenzar a configurar su extractor de datos web. Primero, creará un directorio root de un proyecto y, a continuación, instalará las dependencias requeridas. Este tutorial requiere una sola dependencia que instalará utilizando el administrador de paquetes predeterminado de Node.js npm. npm viene previamente instalado con Node.js, por lo tanto, no es necesario instalarlo.
Cree una carpeta para este proyecto y posiciónese en ella:
- mkdir book-scraper
- cd book-scraper
Ejecutará todos los comandos subsiguientes desde este directorio.
Debemos instalar un paquete utilizando npm o el administrador de paquetes de Node. Primero, inicialice npm para crear un archivo packages.json que gestionará las dependencias y los metadatos de su proyecto.
Inicialice npm para su proyecto:
- npm init
npm presentará una secuencia de solicitudes. Puede presionar ENTER en cada una de ellas o añadir descripciones personalizadas. Asegúrese de presionar ENTER y dejar los valores predeterminados en las solicitudes de entrypoint: y test command:. Alternativamente, puede pasar el indicador y a npm, npm init -y, para que complete todos los valores predeterminados de forma automática.
El resultado tendrá un aspecto similar a este:
Output{
"name": "sammy_scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "sammy the shark",
"license": "ISC"
}
Is this OK? (yes) yes
Escriba yes y presione ENTER. npm guardará este resultado como su archivo package.json.
Ahora, utilice npm para instalar Puppeteer:
- npm install --save puppeteer
Este comando instala Puppeteer y una versión de Chromium que el equipo de Puppeteer sabe que funciona con su API.
En equipos basados en Linux, Puppeteer podría requerir algunas dependencias adicionales.
Si está utilizando Ubuntu 18.04, consulte el menú desplegable ‘Debian Dependencies’ (Dependencias de Debian) de la sección ‘Chrome headless doesn’t launch on UNIX’ (Chrome desatendido no se inicia en UNIX) en los documentos de resolución de problemas de Puppeteer. Puede utilizar el siguiente comando como ayuda para encontrar dependencias faltantes:
- ldd chrome | grep not
Ahora que tiene npm, Puppeteer y todas las dependencias adicionales instaladas, su archivo package.json requiere un último ajuste para que pueda comenzar a programar. En este tutorial, iniciará su aplicación desde la línea de comandos con npm run start. Debe añadir cierta información sobre esta secuencia de comandos start en el archivo package.json. Específicamente, debe añadir una línea en la directiva scripts relativa a su comando start.
Abra el archivo en su editor de texto preferido:
- nano package.json
Busque la sección scripts: y añada las siguientes configuraciones. Recuerde colocar una coma al final de la línea test de la secuencia de comandos; de lo contrario, su archivo no se analizará correctamente.
Output{
. . .
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
. . .
"dependencies": {
"puppeteer": "^5.2.1"
}
}
También notará que, ahora, aparece puppeteer debajo de dependencies casi al final del archivo. Su archivo package.json no requerirá más ajustes. Guarde sus cambios y cierre el editor.
Con esto, está listo para comenzar a programar su extractor de datos. En el siguiente paso, configurará una instancia de navegador y probará la funcionalidad básica de su extractor de datos.
Paso 2: Configurar una instancia de navegador
Al abrir un navegador tradicional, entre otras cosas, puede hacer clic en botones, navegar con el mouse, escribir y abrir herramientas de desarrollo. Los navegadores desatendidos como Chromium permiten realizar estas mismas tareas, pero mediante programación y sin interfaz de usuario. En este paso, configurará la instancia de navegador de su extractor de datos. Cuando inicie su aplicación, esta abrirá Chromium y se dirigirá a books.toscrape.com de forma automática. Estas acciones iniciales constituirán la base de su programa.
Su extractor de datos web requerirá cuatro archivos .js: browser.js, index.js, pageController.js y pageScraper.js. En este paso, creará estos cuatro archivos y los actualizará de forma continua a medida que su programa se vuelva más sofisticado. Comience con browser.js; este archivo contendrá la secuencia de comandos que inicia su navegador.
Desde el directorio root de su proyecto, cree y abra browser.js en un editor de texto:
- nano browser.js
Primero, solicitará Puppeteer con require y creará una función async denominada startBrowser(). Esta función iniciará el navegador y devolverá una instancia de él. Añada el siguiente código:
const puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};
Puppeteer cuenta con un método .launch() que inicia una instancia de un navegador. Este método devuelve una promesa que debe asegurarse de que se resuelva utilizando un bloque .then o await.
Utiliza await para asegurarse de que la promesa se resuelva, envuelve esta instancia en un bloque de código try-catch y, luego, devuelve una instancia del navegador.
Tenga en cuenta que el método .launch() toma un parámetro JSON con varios valores:
- headless: con el valor
false, el navegador se ejecuta con una interfaz para que pueda ver la ejecución de su secuencia de comandos y, contrue, se ejecuta en modo desatendido. Tenga en cuenta que si desea implementar su extractor de datos en la nube, debe establecerheadlessentrue. La mayoría de los equipos virtuales se ejecutan en modo desatendido y no incluyen interfaz de usuario, por tanto, solo pueden ejecutar el navegador en ese modo. Puppeteer también incluye un modoheadful, pero debe utilizarse únicamente para fines de prueba. - ignoreHTTPSErrors: con el valor
true, le permite visitar sitios web que no están alojados con un protocolo HTTPS seguro e ignorar cualquier error relacionado con HTTPS.
Guarde y cierre el archivo.
Ahora, cree su segundo archivo .js, index.js:
- nano index.js
Aquí, utilizará require para solicitar browser.js y pageController.js. Luego, invocará la función startBrowser() y pasará la instancia de navegador creada a nuestro controlador de página, que dirigirá sus acciones. Añada el siguiente código:
const browserObject = require('./browser');
const scraperController = require('./pageController');
//Start the browser and create a browser instance
let browserInstance = browserObject.startBrowser();
// Pass the browser instance to the scraper controller
scraperController(browserInstance)
Guarde y cierre el archivo.
Cree su tercer archivo .js, pageController.js:
- nano pageController.js
pageController.js controla el proceso de extracción de datos. Utiliza la instancia de navegador para controlar el archivo pageScraper.js, que es donde se ejecutan todas las secuencias de comandos de extracción de datos. Más adelante, lo utilizará para especificar de qué categoría de libros desea extraer datos. Sin embargo, por ahora, solo desea asegurarse de que puede abrir Chromium y navegar a una página web:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Este código exporta una función que toma la instancia de navegador y la pasa a otra función denominada scrapeAll(). Esta función, a su vez, pasa la instancia como argumento a pageScraper.scraper(), que la utiliza para extraer datos de las páginas.
Guarde y cierre el archivo.
Por último, cree su cuarto archivo .js, pageScraper.js:
- nano pageScraper.js
Aquí, creará un literal de objeto con una propiedad url y un método scraper(). La propiedad url es la URL de la página web de la que desea extraer datos y el método scraper() contiene el código que realizará la extracción en sí, aunque, en este punto, simplemente navega a una URL. Añada el siguiente código:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;
Puppeteer cuenta con un método newPage() que crea una instancia de página nueva en el navegador. Se pueden hacer varias cosas con las instancias de página. En nuestro método scraper(), creó una instancia de página y, luego, utilizó el método page.goto() para navegar a la página de inicio de books.toscrape.com.
Guarde y cierre el archivo.
Con esto, completó la estructura de archivos de su programa. El primer nivel del árbol de directorios de su proyecto tendrá este aspecto:
Output.
├── browser.js
├── index.js
├── node_modules
├── package-lock.json
├── package.json
├── pageController.js
└── pageScraper.js
Ahora, ejecute el comando npm run start y observe la ejecución de su aplicación de extracción de datos:
- npm run start
Abrirá una instancia de Chromium y una página nueva en el navegador, y se dirigirá a books.toscrape.com de forma automática.
En este paso, creó una aplicación de Puppeteer que abre Chromium y carga la página de inicio de una librería en línea ficticia: books.toscrape.com. En el siguiente paso, extraerá datos de todos los libros de esa página de inicio.
Paso 3: Extraer datos de una sola página
Antes de añadir más funcionalidades a su aplicación de extracción de datos, abra su navegador web preferido y diríjase de forma manual a la página de inicio de Books to Scrape. Navegue por el sitio para comprender cómo están estructurados los datos.
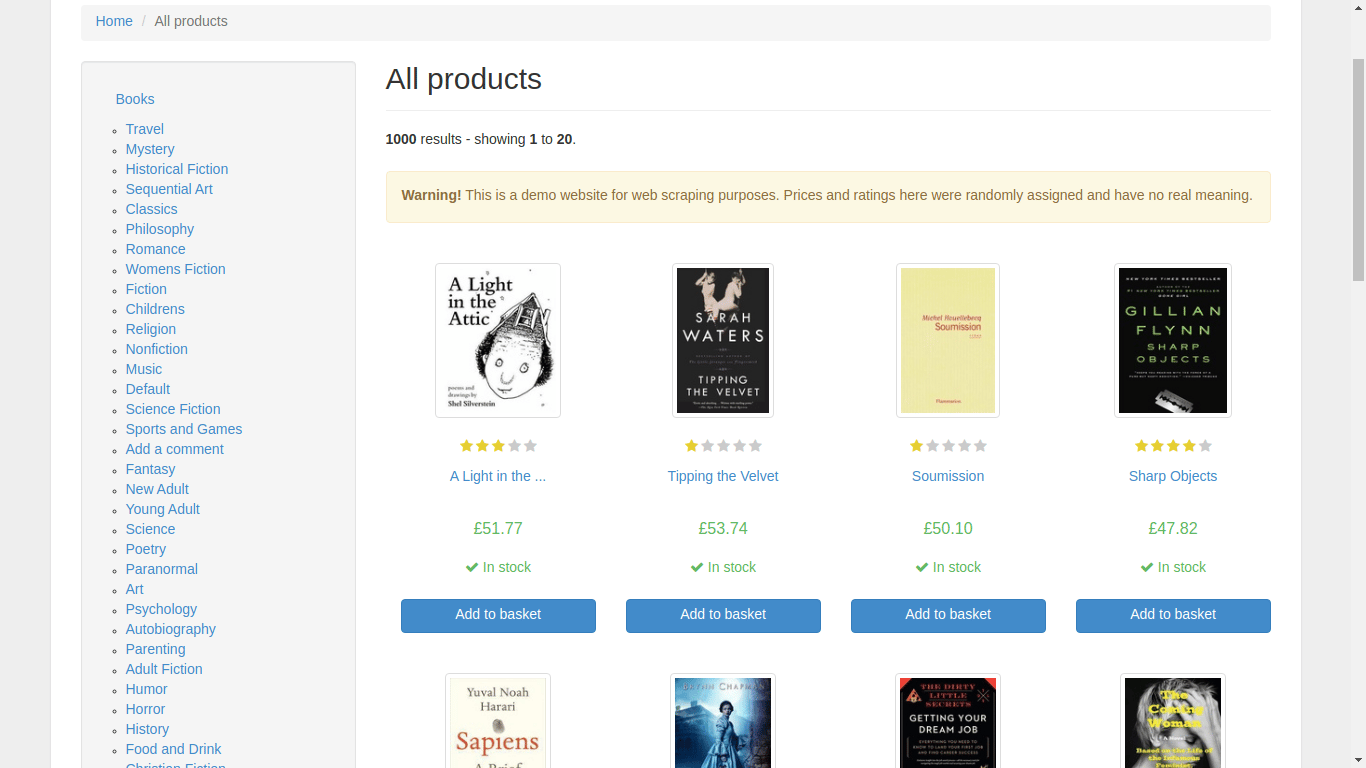
Verá una sección de categorías a la izquierda y los libros exhibidos a la derecha. Al hacer clic en un libro, el navegador se dirige a una nueva URL que muestra información pertinente sobre ese libro en particular.
En este paso, replicará este comportamiento, pero mediante programación: automatizará la tarea de navegar por el sitio web y consumir sus datos.
Primero, si analiza el código fuente de la página de inicio utilizando las herramienta de desarrollo de su navegador, notará que la página enumera los datos de cada libro debajo de una etiqueta section. Dentro de la etiqueta section, cada libro está debajo de una etiqueta list (li), y es aquí donde se encuentra el enlace a la página separada del libro, su precio y su disponibilidad.
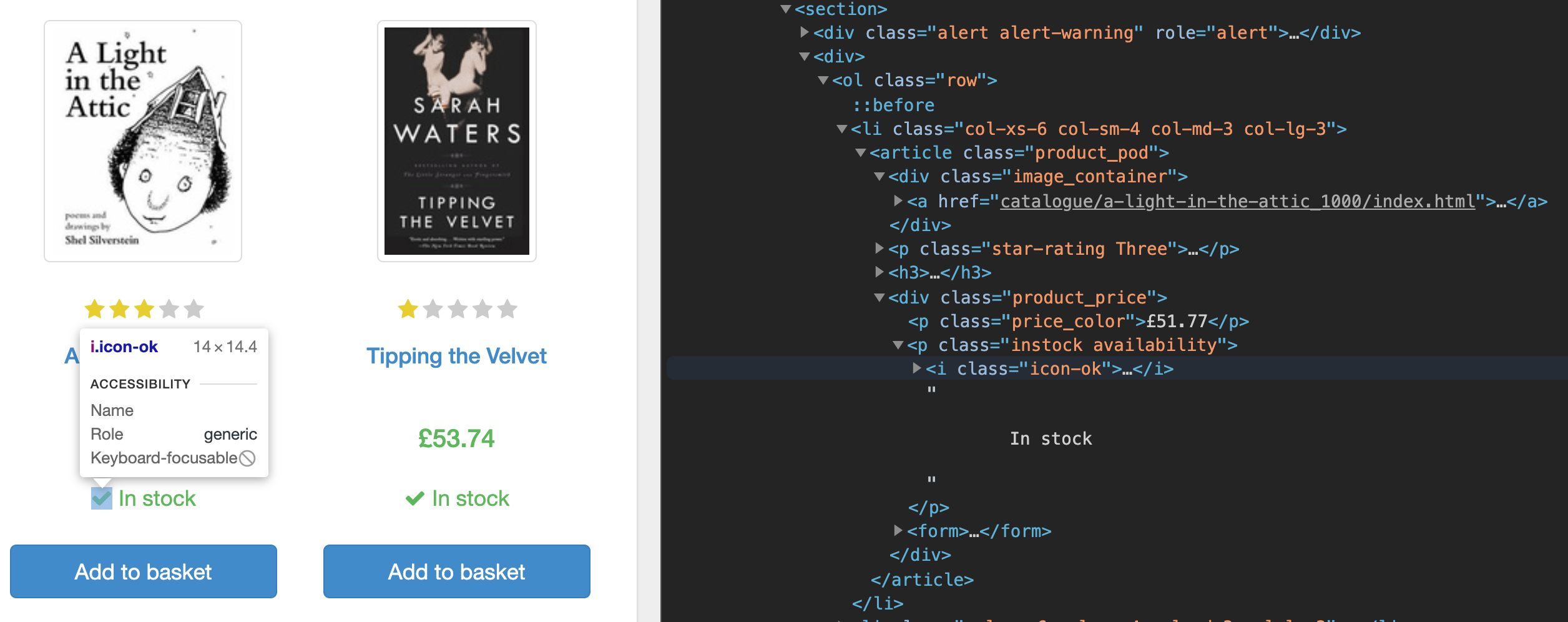
Extraerá datos de estas URL de los libros, filtrará los libros que están disponibles y navegará a la página separada de cada libro para extraer sus datos.
Vuelva a abrir su archivo pageScraper.js:
- nano pageScraper.js
Añada el siguiente contenido resaltado: Anidará otro bloque de await dentro de await page.goto(this.url);:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
En este bloque de código, invocó el método page.waitForSelector(). Con esto, esperó el div que contiene toda la información relacionada con el libro que se debe reproducir en el DOM y, luego, invocó el método page.$$eval(). Este método obtiene el elemento de URL con el selector section ol li (asegúrese de que siempre se devuelva solo una cadena o un número con los métodos page.$eval() y page.$$eval()).
Cada libro puede tener dos estados: disponible, In Stock, o no disponible, Out of stock. Solo desea extraer datos de los libros In Stock. Como page.$$eval() devuelve una matriz de todos los elementos coincidentes, la filtró para asegurarse de estar trabajando únicamente con los libros que están disponibles. Para hacerlo, buscó y evaluó la clase .instock.availability. Luego, identificó la propiedad href de los enlaces del libro y la devolvió del método.
Guarde y cierre el archivo.
Vuelva a ejecutar su aplicación:
- npm run start
El navegador se abrirá, se dirigirá a la página web y se cerrará cuando la tarea se complete. Ahora, observe su consola; contendrá todas las URL extraídas:
Output> book-scraper@1.0.0 start /Users/sammy/book-scraper
> node index.js
Opening the browser......
Navigating to http://books.toscrape.com...
[
'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
'http://books.toscrape.com/catalogue/soumission_998/index.html',
'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
'http://books.toscrape.com/catalogue/olio_984/index.html',
'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
]
Es un gran comienzo, pero desea extraer todos los datos pertinentes de un libro determinado, no solo su URL. Ahora, utilizará estas URL para abrir cada página y extraer el título, el autor, el precio, la disponibilidad, el UPC, la descripción y la URL de la imagen de cada libro.
Vuelva a abrir pageScraper.js:
- nano pageScraper.js
Añada el siguiente código, que recorrerá en bucle cada uno de los enlaces extraídos, abrirá una instancia de página nueva y, luego, obtendrá los datos pertinentes:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
// scrapedData.push(currentPageData);
console.log(currentPageData);
}
}
}
module.exports = scraperObject;
Tiene una matriz de todas las URL. Lo que desea hacer es recorrer en bucle esta matriz, abrir una URL en una página nueva, extraer los datos de esa página, cerrarla y abrir una nueva para la siguiente URL de la matriz. Tenga en cuenta que envolvió este código en una promesa. Esto se debe a que desea esperar a que se complete cada acción de su bucle. Por lo tanto, cada promesa abre una URL nueva y no se resuelve hasta que el programa haya extraído todos sus datos y la instancia de esa página se haya cerrado.
Advertencia: Tenga en cuenta que esperó la promesa utilizando un bucle for-in. Puede utilizar cualquier otro bucle, pero evite recorrer en iteración sus matrices de URL con métodos de iteración de matrices, como forEach, o cualquier otro método que utilice una función de devolución de llamada. Esto se debe a que la función de devolución de llamada debe pasar, primero, por la cola de devolución de llamadas y el bucle de evento, por lo tanto, se abrirán varias instancias de la página a la vez. Esto consumirá mucha más memoria.
Observe con mayor detenimiento su función pagePromise. Primero, su extractor creó una página nueva para cada URL y, luego, utilizó la función page.$eval() para apuntar los selectores a los detalles pertinentes que deseaba extraer de la página nueva. Algunos de los textos contienen espacios en blanco, pestañas, líneas nuevas y otros caracteres no alfanuméricos, que eliminó utilizando una expresión regular. Luego, anexó el valor de cada dato extraído de esta página a un objeto y resolvió ese objeto.
Guarde y cierre el archivo.
Vuelva a ejecutar la secuencia de comandos:
- npm run start
El navegador abre la página de inicio y, luego, abre la página de cada libro y registra los datos extraídos de cada una de ellas. Se imprimirá este resultado en su consola:
OutputOpening the browser......
Navigating to http://books.toscrape.com...
{
bookTitle: 'A Light in the Attic',
bookPrice: '£51.77',
noAvailable: '22',
imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
upc: 'a897fe39b1053632'
}
{
bookTitle: 'Tipping the Velvet',
bookPrice: '£53.74',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
upc: '90fa61229261140a'
}
{
bookTitle: 'Soumission',
bookPrice: '£50.10',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
bookDescription: 'Dans une France assez proche de la nôtre, [...]',
upc: '6957f44c3847a760'
}
...
En este paso, extrajo datos pertinentes de cada libro de la página de inicio de books.toscrape.com, pero podría añadir muchas funcionalidades más. Por ejemplo, todas las páginas de libros están paginadas; ¿cómo puede obtener libros de estas otras páginas? Además, observó que hay categorías de libros en el lado izquierdo del sitio web; ¿y si no desea extraer todos los libros, sino solo los libros de un género en particular? Ahora, añadirá estas funciones.
Paso 4: Extraer datos de varias páginas
Las páginas de books.toscrape.com que están paginadas tienen un botón next debajo de su contenido; las páginas que no lo están, no.
Utilizará la presencia de este botón para determinar si una página está paginada o no. Como los datos de todas las páginas tienen la misma estructura y marcación, no escribirá un extractor para cada página posible. En su lugar, utilizará la técnica de recursión.
Primero, debe realizar algunos cambios en la estructura de su código para admitir la navegación recursiva a varias páginas.
Vuelva a abrir pagescraper.js:
- nano pagescraper.js
Agregará una nueva función denominada scrapeCurrentPage() a su método scraper(). Esta función contendrá todo el código que extrae datos de una página en particular y, luego, hará clic en el botón “siguiente”, si está presente. Añada el siguiente código resaltado:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Primero, configure la variable nextButtonExist en false y, luego, compruebe si el botón aparece. Si el botón next está presente, configure nextButtonExists en true y proceda a hacer clic en él``; luego, se invoca esta función de forma recursiva.
Cuando nextButtonExists tiene un valor false, devuelve la matriz de scrapedData como de costumbre.
Guarde y cierre el archivo.
Vuelva a ejecutar su secuencia de comandos:
- npm run start
Esto puede tomar un tiempo; después de todo, su aplicación está extrayendo datos de más de 800 libros. Puede cerrar el navegador o presionar CTRL + C para cancelar el proceso.
Ha maximizado las capacidades de su extractor de datos, pero, en el proceso, generó un problema. Ahora, el problema no es tener pocos datos, sino demasiados. En el siguiente paso, ajustará su aplicación para filtrar la extracción de datos por categoría de libros.
Paso 5: Extraer datos por categoría
Para extraer datos por categoría, deberá modificar sus archivos pageScraper.js y pageController.js.
Abra pageController.js en un editor de texto:
nano pageController.js
Invoque el extractor de modo que solo extraiga libros de viajes. Añada el siguiente código:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Ahora, está pasando dos parámetros a su método pageScraper.scraper(); el segundo es la categoría de libros de la que desea extraer datos, que, en este ejemplo, es Travel. Pero su archivo pageScraper.js todavía no reconoce este parámetro. También deberá ajustar este archivo.
Guarde y cierre el archivo.
Abra pageScraper.js:
- nano pageScraper.js
Agregue el siguiente código, que añadirá su parámetro de categoría, navegará a esa página de categoría y, luego, comenzará a extraer datos de los resultados paginados:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser, category){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Select the category of book to be displayed
let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
// Search for the element that has the matching text
links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
let link = links.filter(tx => tx !== null)[0];
return link.href;
}, category);
// Navigate to the selected category
await page.goto(selectedCategory);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Este bloque de código utiliza la categoría que pasó para obtener la URL en la que se encuentran los libros de esa categoría.
El método page.$$eval() puede tomar argumentos al pasarlos como tercer parámetro al método $$eval() y definirlos como tales en la devolución de llamada de la siguiente manera:
page.$$eval('selector', function(elem, args){
// .......
}, args)
Esto es lo que hizo en su código: pasó la categoría de libros de la que quería extraer datos, marcó todas las categorías para determinar cuál coincidía y, luego, devolvió la URL de esa categoría.
Luego, utilizó esa URL para navegar a la página que muestra la categoría de libros de la que desea extraer datos utilizando el método page.goto(selectedCategory).
Guarde y cierre el archivo.
Vuelva a ejecutar su aplicación. Observará que navega a la categoría Travel, abre los libros de esa categoría de forma recursiva, página por página, y registra los resultados:
- npm run start
En este paso, extrajo datos de varias páginas y, luego, de varias páginas de una categoría en particular. En el paso final, modificará su secuencia de comandos para extraer datos de varias categorías y, luego, guardará los datos extraídos en un archivo JSON convertido a cadena JSON.
Paso 6: Extraer datos de varias categorías y guardarlos como JSON
En este paso final, modificará su secuencia de comandos para extraer datos de todas las categorías que desee y, luego, cambiará la forma de su resultado. En lugar de registrar los resultados, los guardará en un archivo estructurado denominado data.json.
Puede añadir más categorías para extraer de datos de forma rápida. Para hacerlo, solo se requiere una línea adicional por género.
Abra pageController.js:
- nano pageController.js
Ajuste su código para incluir categorías adicionales. En el ejemplo a continuación, se suman HistoricalFiction y Mystery a nuestra categoría Travel existente:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Guarde y cierre el archivo.
Vuelva a ejecutar la secuencia de comandos y observe cómo extrae datos de las tres categorías:
- npm run start
Ahora que el extractor está totalmente operativo, su paso final es guardar los datos en un formato más útil. Ahora, los almacenará en un archivo JSON utilizando el módulo fs de Node.js.
Primero, vuelva a abrir pageController.js:
- nano pageController.js
Añada el siguiente código resaltado:
const pageScraper = require('./pageScraper');
const fs = require('fs');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
if(err) {
return console.log(err);
}
console.log("The data has been scraped and saved successfully! View it at './data.json'");
});
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Primero, solicita el módulo fs de Node.js en pageController.js. Esto garantiza que pueda guardar sus datos como archivo JSON. Luego, añade código para que, cuando se complete la extracción de datos y se cierre el navegador, el programa cree un archivo nuevo denominado data.json. Tenga en cuenta que el contenido de data.json está convertido a cadena JSON. Por tanto, al leer el contenido de data.json, siempre se lo debe analizar como JSON antes de volver a utilizar los datos.
Guarde y cierre el archivo.
Con esto, ha creado una aplicación de extracción de datos web que extrae libros de varias categorías y, luego, almacena los datos extraídos en un archivo JSON. A medida que su aplicación se vaya volviendo más compleja, puede resultarle conveniente almacenar los datos extraídos en una base de datos o proporcionarlos a través de una API. La manera en la que se consumen estos datos es una decisión personal.
Conclusión
En este tutorial, creó un rastreador web que extrajo datos de varias páginas de forma recursiva y los guardó en un archivo JSON. En resumen, aprendió una nueva manera de automatizar la recopilación de datos de sitios web.
Puppeteer cuenta con muchas características que no se abordaron en este tutorial. Para obtener más información, consulte Cómo usar Puppeteer para controlar Chrome desatendido de forma sencilla. También puede consultar la documentación oficial de Puppeteer.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Gbadebo is a software engineer that is extremely passionate about JavaScript technologies, Open Source Development and community advocacy.
Supporting the open-source community one tutorial at a time. Former Technical Editor at DigitalOcean. Expertise in topics including Ubuntu 22.04, Ubuntu 20.04, CentOS, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
