AI/ML Technical Content Strategist

Model providers are now advertising 1M+ token context windows. Serving them efficiently is a different problem entirely, and conflating the two will cost you at scale. Long-context support and long-context performance are not the same thing. One is a model capability. The other is an infrastructure challenge that compounds across every layer of your serving stack, quietly at first, and then all at once when you hit production load.
This article breaks down exactly why. We’ll show how KV cache memory pressure, quadratic attention complexity, prefill scheduling contention, and memory bandwidth ceilings interact to create failure modes that only surface at scale, and why no single optimization resolves them. If you’re building on long-context models, or evaluating infrastructure that claims to support them, what follows will change how you ask questions of your provider.
What Is the KV Cache Problem in LLM Inference?

The KV cache memory scaling diagram above shows GPU VRAM usage at 4K, 128K, and 1M token context lengths for a 70B LLM at production scale. The infographic uses full multi-head attention (64 heads) rather than the GQA configuration used in the body calculation below
Every Large Language Model in production today is a Transformer-based autoregressive model. At the heart of how these models process language is a mechanism called attention - the mathematical operation that allows a model to weigh relationships between tokens across the entire input sequence. Attention is what makes LLMs genuinely contextually aware rather than just statistically fluent, and it’s also the root cause of the scaling problems this article is about.
To make attention computationally tractable during inference, Transformers use a KV (Key-Value) Cache. Every time the model processes a token, it computes three vectors for that token: a Query, a Key, and a Value. The Query is used to ask “what should I attend to?” - the Keys and Values from all previous tokens answer that question. Rather than recomputing every Key and Value from scratch on each new token, the model stores them in the KV cache and reuses them. This makes generation incremental and efficient: each new token only needs to compute its own Query, then attend over the cached Keys and Values from everything that came before. At short context lengths, this is a well-understood and manageable overhead.
The problem emerges as context grows. KV cache memory footprint scales as:
2 × layers × KV heads × head dimension × sequence length × bytes per element
To make this concrete, take Llama 3 70B running in BF16 precision - 80 layers, 8 KV heads, head dimension of 128, and a 128K token sequence length:
2 × 80 × 8 × 131,072 × 128 × 2 ≈ 43 GB for a single request
That’s roughly the memory footprint of a heavily quantized version of the 70B model itself, consumed entirely by the cache for one user’s context. And this is a standard long-context case, not an extreme one. At million-token context lengths - which several frontier models now advertise - KV cache size eclipses model weight size entirely. At that point, memory pressure stops being a secondary concern and becomes the primary constraint shaping every decision in your inference stack: how many requests you can batch, whether the cache fits on a single device, and whether attention data has to travel over slow inter-GPU interconnects instead of being read locally. Long context doesn’t just increase cost - it breaks the assumptions that make LLM inference efficient in the first place.
The Quadratic Attention Wall: Why Longer Context Costs Exponentially More
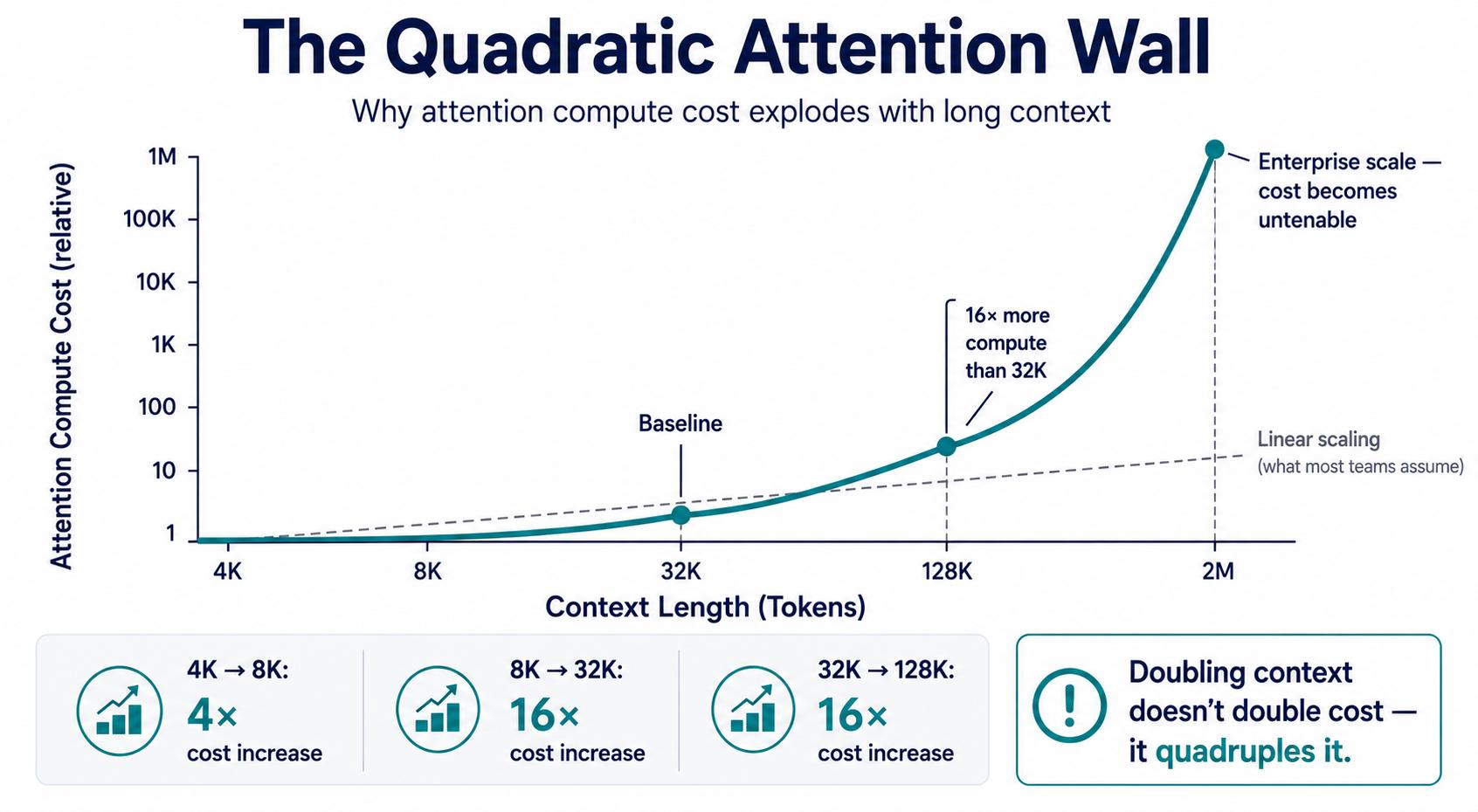
Above is a chart showing quadratic attention compute cost vs context length, with 16x jump from 32K to 128K tokens marked.
The core of the problem is a property of how attention works mathematically. Every token in a sequence must attend to every other token - meaning the compute required doesn’t grow in proportion to context length, it grows with the square of it. Double the context, quadruple the cost. That’s what O(n²) complexity means in practice, and it’s why the jump from 32K to 128K tokens feels so much more punishing than the jump from 4K to 32K.
To manage this, different attention mechanisms have been devised to help with memory, but they cannot affect the underlying compute curve. For example, FlashAttention optimizes the IO complexity - the memory bandwidth bottleneck - by reducing the time spent moving data between slow High Bandwidth Memory (HBM) and fast on-chip SRAM. It optimizes self-attention by tiling (processing data in blocks), fusing kernel operations to reduce memory reads/writes, and recomputing only necessary parts during the backward pass to avoid saving huge intermediate matrices.
The user-facing consequence of all this is felt most acutely in time-to-first-token (TTFT) - the delay between when a request is submitted and when the first output token appears. Because TTFT is dominated by the prefill phase, and prefill carries the full weight of that quadratic attention cost, long contexts can stretch TTFT from milliseconds into multiple seconds. For a chatbot or agent, that delay is the difference between a responsive interaction and a frustrating one. For a streaming application, it’s the dead air before anything starts happening. And critically, TTFT degradation isn’t linear with context length: it accelerates, meaning that the jump from 32K to 128K feels far worse than the jump from 4K to 32K. Optimizations like FlashAttention soften the blow, but they don’t change the shape of the curve. As long as standard self-attention remains O(n²), every additional token in the prompt is paying compound interest on latency.
Prefill vs. Decode: The Inference Imbalance That Breaks Scheduling
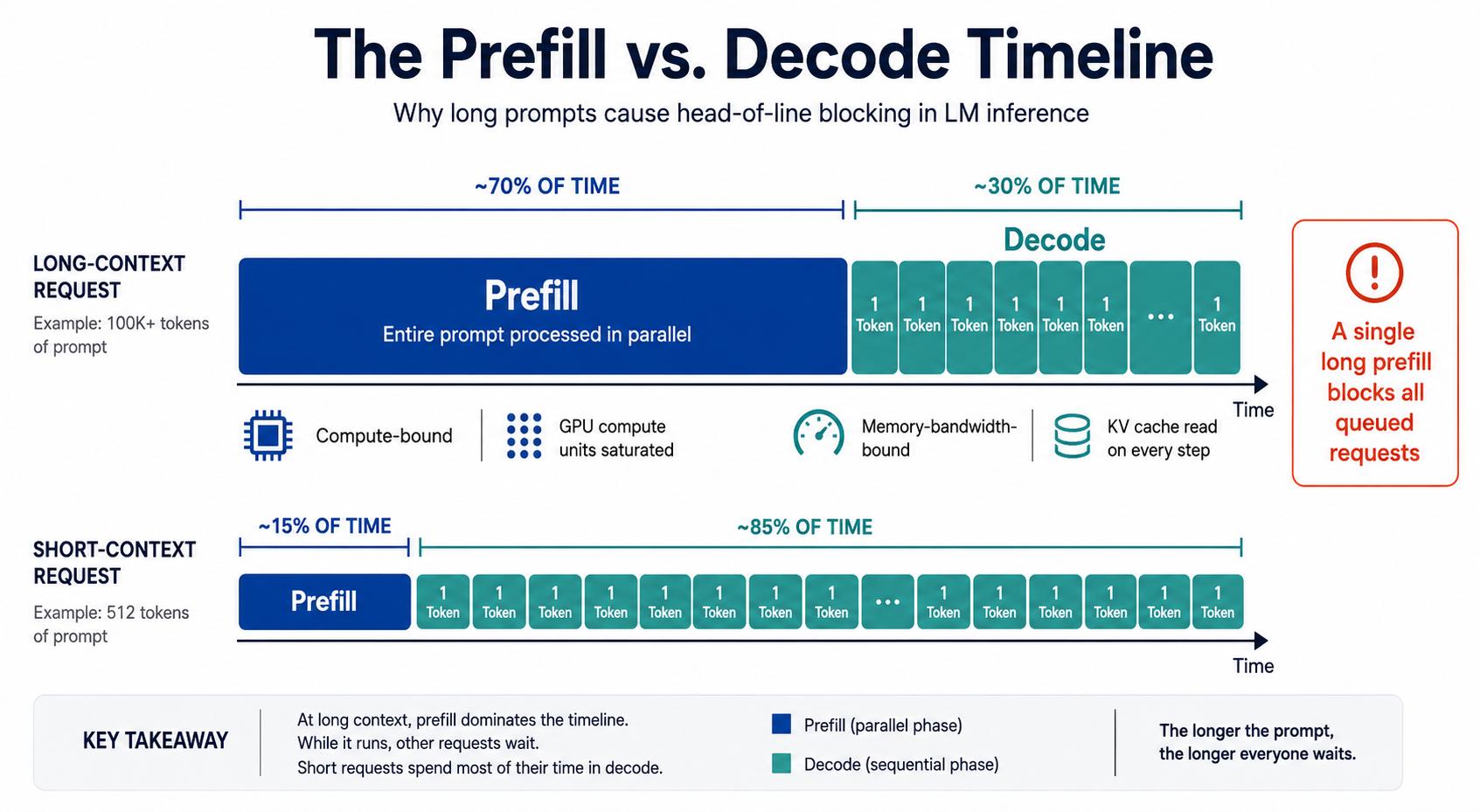
Above is a prefill vs decode inference timeline diagram showing how long-context requests block queued requests in multi-tenant LLM serving.
To understand why long contexts cause such acute scheduling problems, it helps to break inference down into its two distinct phases. The first is prefill, where the model processes the entire input prompt in a single parallel pass to build up the initial KV cache. Because every token in the prompt is processed simultaneously, prefill saturates the GPU’s compute units - it’s compute-bound, meaning performance is limited by how fast the hardware can execute matrix multiplications. The second phase is decode, where the model generates output tokens one at a time, each attending back to the full KV cache built during prefill. Because each new token depends on the previous one, decode can’t be parallelized the same way. Instead of saturating compute, it saturates memory bandwidth - the GPU spends most of its time reading the KV cache from HBM rather than doing math. The two phases stress completely different parts of the GPU: prefill is expensive but finite, happening once per request, while decode is cheaper per step but repeats for every output token.
As prompt length grows, prefill stops being a setup cost and becomes the dominant cost of the entire request. A 128K-token prompt can flip the ratio entirely, with prefill consuming the majority of wall-clock time before a single output token is produced. This matters for latency, but it matters even more for how inference systems schedule work across concurrent requests. When a long-prompt request enters prefill, it holds GPU resources for seconds at a time - during which every other request in the queue is effectively frozen. A single long prefill can delay dozens of unrelated, short-context requests that had the misfortune of arriving at the wrong moment. The downstream consequence is felt most acutely in tail latency. Teams monitoring average latency may see numbers that look acceptable while their p95 and p99 figures quietly degrade. The requests most affected aren’t the long-context ones - those users expect to wait - but the short, time-sensitive queries that land behind them in the queue. For agents, copilots, or any interactive product where responsiveness matters, this kind of unpredictable variance is often more damaging than a uniformly higher baseline. The prefill/decode imbalance doesn’t just create a performance problem; it creates an observability problem, because the costs are distributed unevenly in ways that aggregate metrics tend to hide.
Why Batching Breaks Down at Long Context
Batching is the primary lever inference systems use to stay efficient. By grouping multiple requests together and processing them in parallel, GPUs can amortize fixed costs across many users and maintain high utilization. At short context lengths, this works well - requests are roughly similar in size, KV caches are small, and the scheduler has plenty of flexibility to pack work together. Long context breaks every one of those assumptions.
The core issue is memory fragmentation. Each request carries its own KV cache, and at long context lengths those caches are enormous and variable in size. A serving system handling a mix of 4K and 128K requests can’t pack them efficiently - the long requests consume so much GPU memory that there’s simply no headroom left for additional requests to join the batch. Techniques like PagedAttention help by allocating KV cache memory in discrete pages rather than contiguous blocks, reducing waste at the margins. But they don’t change the underlying reality: a 128K request still needs roughly the memory of a 128K request, and that memory has to come from somewhere.
The result is a shrinking-batch-size cascade. As context length increases across a fleet, average batch sizes fall, GPU utilization drops, and cost per token climbs - even if raw compute capacity hasn’t changed. This is one of the more counterintuitive failure modes of long-context serving: the system isn’t broken, it’s just spending more and more of its capacity on memory overhead rather than useful work. What looks like a model capability on a spec sheet becomes a throughput tax at production scale.
The Memory Bandwidth Ceiling in GPU Inference
Even if you could eliminate every compute bottleneck discussed so far - faster matrix multiplications, perfect scheduling, infinite parallelism - you would still hit a wall during decode, and that wall is memory bandwidth. On every single decode step, the GPU must read the entire KV cache from High Bandwidth Memory to compute attention for the new token. This happens once per generated token, for every token in the output. HBM is fast by memory standards, but it has a fixed bandwidth ceiling - modern flagship GPUs top out around 3-4 TB/s. When KV caches grow to tens of gigabytes per request, the time spent just moving that data on every decode step becomes the binding constraint on throughput, regardless of how much raw compute is sitting idle on the same chip.
The practical consequence is that tokens-per-second drops near-linearly as context grows. Double the context length, double the KV cache, double the data that has to be read on every decode step - and therefore roughly halve your decode throughput. This relationship holds even on the best hardware available, because it’s a function of the memory bandwidth ceiling, not the compute ceiling. You can throw more tensor cores at the problem and see no improvement whatsoever, because the GPU is already waiting on memory transfers, not arithmetic.
This is the counterintuitive lesson that catches many teams off guard: in long-context inference, you can be simultaneously compute-rich and bandwidth-poor. A cluster that looks fully provisioned on paper - plenty of GPUs, high utilization - can still deliver disappointing throughput on long-context workloads because the bottleneck has shifted entirely off the compute units and onto the memory bus. Optimizing for FLOPS, which is how most GPU capacity is purchased and measured, doesn’t help you when the constraint is how fast you can stream data out of HBM. Long context doesn’t just change how much your infrastructure costs - it changes which part of your infrastructure actually matters.
Cascading Effects of Long-Context Requests in Multi-Tenant Systems
The technical issues described so far - KV cache bloat, quadratic attention, prefill blocking, bandwidth saturation - are manageable in isolation. In a multi-tenant production environment, they compound. The most visible symptom is SLA unpredictability. A single long-context request doesn’t just slow itself down; it blocks the queue and degrades latency for every concurrent user on the same serving infrastructure. This makes SLA commitments extremely difficult to honor, because tail latency is no longer a function of your average workload - it’s a function of your worst request at any given moment. One outlier, arriving at peak traffic, can poison the latency profile for an entire fleet. The requests most affected aren’t even the long-context ones - those users expect to wait - but the short, time-sensitive queries that happen to land behind them in the queue.
The cost implications are equally non-linear, and they catch most teams off guard. A reasonable assumption might be that a 128K request costs roughly 128 times more than a 1K request - proportional to token count. In practice, it often costs significantly more. The quadratic attention cost during prefill, the memory pressure that shrinks batch sizes, the bandwidth saturation during decode, and the opportunity cost of blocking other requests all stack on top of each other. The result is that long-context requests punch far above their token-count weight in terms of resource consumption, and most per-token pricing models don’t reflect that reality. Teams optimizing for cost based on token volume alone will consistently underestimate the true expense of long-context workloads - sometimes by a wide margin.
Autoscaling introduces its own failure mode, and it’s one that’s particularly hard to catch before it causes damage. Standard scaling metrics - requests per second, GPU utilization, queue depth - don’t capture context-length variance. A fleet can appear healthy by every conventional dashboard metric while silently drowning in a surge of long-context traffic. Ten 128K requests and a thousand 1K requests can look identical to an autoscaler until latency has already collapsed. By the time the signal is visible, the damage is done. Scaling out in response to a context-length spike is also slower to take effect than scaling out in response to a request-rate spike, because spinning up new capacity doesn’t immediately relieve the memory pressure already present on existing nodes.
Finally, long context undermines many of the throughput optimizations that production inference systems depend on. Speculative decoding - where a smaller draft model proposes tokens that a larger model verifies in parallel - assumes stable, predictable memory layouts that variable-length KV caches disrupt, often making the technique net-negative at long context. The same is true across the board: continuous batching strategies, prefetch optimizations, and memory pooling approaches all degrade in the presence of high context-length variance. Long context doesn’t just make individual requests harder to serve - it makes the entire system harder to optimize, because the unpredictability it introduces erodes the assumptions that production inference tooling is built on.
Why Long-Context Inference Remains an Open Problem

Here is a comparison table of long-context inference mitigation techniques including FlashAttention, PagedAttention, sliding window attention, linear attention, and context compression.
The infrastructure community hasn’t been standing still. FlashAttention, as discussed earlier, dramatically reduces the memory bandwidth cost of the attention operation by tiling computation and fusing kernel operations, making long-context inference meaningfully faster without changing model behavior. PagedAttention improves memory utilization by eliminating KV cache fragmentation, enabling higher batch sizes under memory pressure. Sliding window attention limits how far back each token can attend, capping KV cache growth at the cost of truly long-range context. Linear attention mechanisms attempt to sidestep the quadratic scaling problem entirely by approximating full attention with sub-quadratic alternatives. Context compression techniques - prompt summarization, token pruning, retrieval-augmented approaches that avoid stuffing everything into the context window - reduce the problem by reducing input size. Each of these is a genuine improvement, and in combination they’ve meaningfully raised the ceiling on what’s practical to serve.
The honest framing, however, is that every one of these techniques introduces its own tradeoff. FlashAttention and PagedAttention are largely free wins, but they optimize constants rather than change the underlying scaling curves. Sliding window attention trades coverage for efficiency - it works well for tasks where local context is sufficient, and poorly for tasks that require reasoning across documents. Linear attention approximations often degrade model quality in ways that are subtle but real, particularly on tasks requiring precise long-range recall. Context compression requires either additional model calls, careful prompt engineering, or retrieval infrastructure that introduces its own latency and complexity. There is no technique on this list that delivers full long-context capability at short-context cost. They are mitigations, not solutions.
This is what makes the gap between “supported context length” and “efficiently served context length” so consequential - and so easy to miss. A provider can truthfully advertise a 1M-token context window while serving it at economics and latency that make it unusable for most production applications. The spec sheet number reflects what the model can process; it says nothing about what the infrastructure can serve efficiently, at scale, under real multi-tenant load. That gap exists today at 128K and 1M token contexts, and it is widening. As frontier providers push context windows toward 2M tokens and beyond, the memory, bandwidth, and scheduling pressures described in this article scale with them. The mitigations are improving, but the context lengths are growing faster, and the operational complexity of serving at the frontier is compounding in ways that aggregate benchmarks and marketing specifications were never designed to surface.
What Production AI Teams Should Ask Their Inference Provider
The technical landscape described in this article has a direct practical implication: evaluating an inference provider on context window size alone is like evaluating a database on maximum row count. The number tells you something, but it doesn’t tell you what matters. Teams building on long-context models should be asking harder questions. How is long-context throughput measured and reported - under single-request conditions, or under realistic concurrent load? What happens to other tenants’ latency when a long request enters the queue? How is cost per request calculated as context grows - is pricing linear with tokens, or does it reflect the non-linear resource consumption that long context actually produces? And critically, what observability exists into the prefill versus decode latency split? That last question is a useful proxy for infrastructure maturity: providers who can answer it have instrumented their systems carefully enough to understand where time is actually going. Providers who can’t are likely surfacing only the metrics that look favorable.
These questions matter most before you’ve committed to an infrastructure path, because long-context serving assumptions have a way of becoming load-bearing once they’re embedded in a product. A pipeline built around the assumption that 128K context is cheap and low-latency will need significant rearchitecting if that assumption turns out to be wrong at scale - and the rearchitecting will happen at the worst possible time, when user growth is exposing the limits of the original design. The infrastructure choices made today determine whether long-context capability is something your product can actually use in production, or something that works in a demo and degrades quietly under real load. That distinction is worth pressure-testing early, with real workloads and real concurrency, rather than discovering it after the fact through user complaints and runaway inference costs.
Closing Thoughts
Long context is not a model capability problem - it’s an infrastructure problem. The models can handle the tokens. The question is whether the systems serving them can do so efficiently, predictably, and at a cost that makes sense in production. As this article has shown, the answer depends on a stack of compounding factors: KV cache memory pressure, quadratic attention costs, prefill scheduling contention, memory bandwidth ceilings, and the cascading effects all of these produce in multi-tenant environments. No single optimization resolves the underlying tension, and the gap between what providers advertise and what teams can actually serve efficiently is growing as context windows extend toward 2M tokens and beyond. Understanding that gap - and building infrastructure around it rather than in spite of it - is what separates teams that scale cleanly from those that scramble to catch up.
Purpose-built inference platforms are designed with exactly these tradeoffs in mind, offering the intelligent request routing, built-in observability, and cost transparency that general-purpose deployments tend to lack. If you’re evaluating how your stack will hold up as context demands grow, DigitalOcean’s Inference Engine is worth a close look. You can explore the Inference Engine to see how it handles long-context workloads at scale using products like Model Evaluations and Dedicated Inference. The infrastructure decisions you make now will determine whether long context is a capability your product can rely on - or just one it technically supports.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
