AI Technical Writer

Introduction
Multi-head attention is a fundamental concept behind Transformer-based models such as BERT, GPT, and Vision Transformers. It allows a model to process an input sequence by focusing on multiple aspects of the data at the same time. Instead of reading inputs sequentially, multi-head attention allows parallel understanding of relationships between tokens, making models both faster and more effective at capturing context. This mechanism is a key reason why attention-based architectures dominate modern deep learning.
Key Takeaways
- Multi-head attention allows models to attend to different parts of the input simultaneously.
- It uses multiple attention heads to capture diverse relationships within the same sequence.
- Each attention head operates in a different learned representation subspace.
- Scaling attention scores improves training stability.
- Multi-head attention is central to Transformer architectures across NLP, vision, and multimodal tasks.
Good-to-Know Concepts in Multi-Head Attention
- Embeddings are the foundation of how transformers understand text. Instead of processing words as plain strings, models convert each token into a dense numerical vector called an embedding. These vectors capture semantic and syntactic information, meaning that words with similar meanings tend to have similar embeddings. For example, the embeddings for “cat” and “dog” will be closer in vector space than those for “cat” and “table.” At this stage, embeddings represent tokens, without any awareness of the surrounding context.
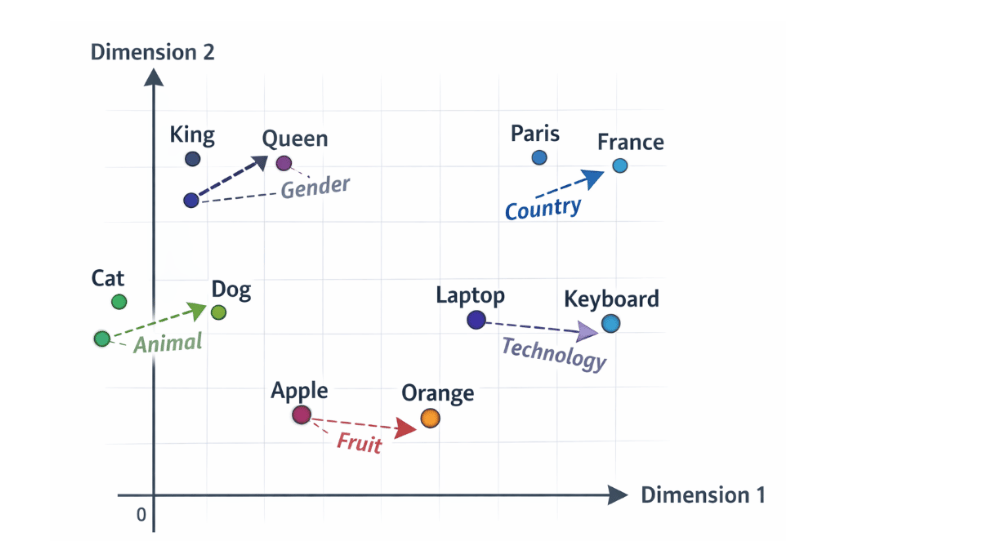
- Attention layers are responsible for adding context to these embeddings. An attention layer allows each token in a sequence to look at every other token and determine which ones are most relevant. Rather than processing text step by step like traditional recurrent models, attention layers analyze the entire sequence in parallel. This helps the model to capture long-range dependencies, such as how the beginning of a sentence relates to its end, and makes transformer models both faster and more effective.
- As embeddings pass through an attention layer, they are transformed into enhanced contextual embeddings. These updated embeddings no longer represent just the token itself, but also include information from the surrounding tokens. This is what allows a model to understand that a word like “bank” has different meanings depending on whether it appears near words like “river” or “account.” Each token’s representation is enriched with contextual information, making it far more expressive and useful for downstream tasks.
- To compute attention, each input embedding is projected into three separate vectors known as the query, key, and value. The query vector represents what a token is looking for, the key vector represents what a token offers, and the value vector contains the information that will be shared if the token is deemed relevant. This separation allows the model to compare tokens efficiently and decide how information should flow between them.
- Query, key, and value vectors are generated using learnable weight matrices. These matrices transform the original embeddings into different representation spaces suitable for attention calculations. Because these weights are learned during training, the model gradually discovers how to best project embeddings so that meaningful relationships emerge. In multi-head attention, each attention head has its own set of query, key, and value weights, enabling different heads to focus on different linguistic patterns such as syntax, semantics, or positional relationships.
- The weight matrices used throughout the attention mechanism are examples of matrix learnable parameters. Transformers rely heavily on large matrix multiplications, and the values inside these matrices are what the model actually learns. These parameters determine how information is transformed, compared, and combined across tokens. Modern transformer models contain millions or even billions of such parameters, which is why they are capable of capturing complex patterns in language.
- Attention scores quantify how strongly one token should attend to another. These scores are calculated by taking the dot product between a query vector and key vectors from all tokens in the sequence. The resulting values indicate similarity and relevance, and they are scaled and passed through a softmax function to produce normalized attention weights. Tokens with higher attention scores contribute more strongly to the final representation, while less relevant tokens contribute very little.
In multi-head attention, this entire attention process is repeated multiple times in parallel using different sets of learnable parameters. Each head learns to focus on different aspects of the input sequence, such as grammatical structure, semantic meaning, or long-distance relationships. The outputs from all heads are then combined to form a final representation that is richer and more informative than what a single attention mechanism could produce. This parallelism is what gives multi-head attention its power and flexibility in modern transformer architectures.
Understanding Attention in Simple Terms
Attention helps a model decide which parts of the input matter most when processing a particular token. When a model reads a sentence, the importance of a word depends on context. For example, the meaning of the word “bank” depends on surrounding words like “river” or “money.” Attention enables the model to dynamically assign importance based on context rather than position alone.
This mechanism is built using three components called queries, keys, and values. A query represents what the current token is looking for. Keys represent what information each token contains. Values carry the actual information to be combined. The model compares the query with all keys to determine relevance and then uses the values to build a context-aware representation.
Let’s take a very small sentence: “Cat sat on mat.”
When this sentence enters a transformer model, the first thing that happens is tokenization and embedding. Each word “Cat, sat, on, and mat” is converted into a numerical vector. These vectors are called embeddings. At this stage, each embedding represents the word by itself, without understanding the full sentence. For example, the embedding for cat knows it refers to an animal, but it does not yet know what the cat is doing or where it is.
| Word | Embedding Vector |
|---|---|
| cat | [0.21, 0.85, 0.14, 0.62] |
| sat | [0.45, 0.33, 0.71, 0.18] |
| on | [0.05, 0.12, 0.88, 0.09] |
| mat | [0.19, 0.79, 0.22, 0.58] |
In real models, embeddings might have hundreds or thousands of dimensions, but for understanding, we’ll use small 4-dimensional vectors.
Next, these embeddings enter an attention layer, where the model tries to understand relationships between words. To do this, each embedding is transformed into three different vectors: a query, a key, and a value. These vectors are created using matrix multiplication with learnable weight matrices. Even though this sounds mathematical, the intuition is simple. The query represents what a word is looking for, the key represents what a word offers, and the value represents the information the word carries.
These embeddings are then stacked together to form an embedding matrix for the sentence:
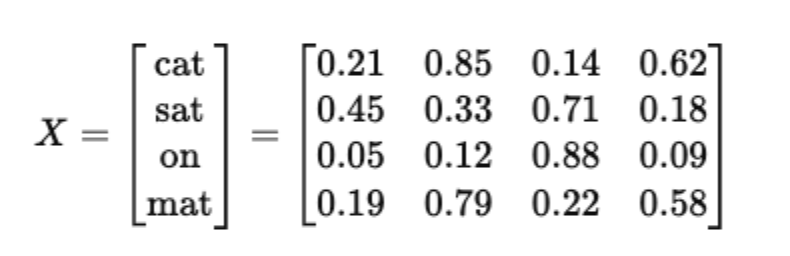
This matrix becomes the input to the attention layer. From here, the model uses matrix multiplications to generate query, key, and value vectors, compare words with each other, and create contextual embeddings where cat knows it sat, and mat knows something sat on it.
Next, these embeddings enter an attention layer, where the model tries to understand relationships between words. To do this, each embedding is transformed into three different vectors: a query, a key, and a value. These vectors are created using matrix multiplication with learnable weight matrices. Even though this sounds mathematical, the intuition is simple. The query represents what a word is looking for, the key represents what a word offers, and the value represents the information the word carries.
These comparisons produce attention scores, which tell the model how much focus to give to each word. After applying a softmax function, the scores become weights that add up to one. The value vectors are then multiplied by these weights and summed together. This creates a new representation for sat that contains information from cat and mat, not just the word sat itself.
After this process, the embedding for sat becomes a contextual embedding. It no longer means “to sit” in a generic sense but now it means the cat is sitting on the mat. The same process happens for cat, on, and mat. Each word looks at the others, decides what matters, and updates its representation accordingly.
This is the core idea of attention: every word decides which other words are important and how much they matter. Vector multiplications and matrices are simply the mathematical tools that make these comparisons efficient and learnable. Even with a tiny four-word sentence, attention allows the model to build meaning by connecting words together, rather than treating them in isolation.
Scaled Dot-Product Attention
The core attention operation is called scaled dot-product attention and is defined as:
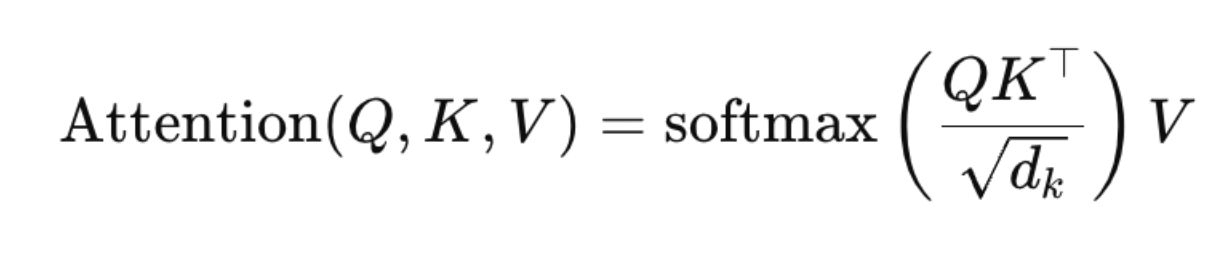
Here, Q, K, and V are matrices of queries, keys, and values, and dk is the dimensionality of the key vectors.
The dot product QKT measures similarity between a query and all keys. A higher value means stronger relevance. Dividing by dk prevents these similarity scores from becoming too large when vector dimensions increase. Without this scaling, the softmax function would produce extremely peaked distributions, leading to very small gradients and unstable training.
After scaling, softmax converts the scores into probabilities that sum to one. These probabilities determine how much each value contributes to the final output. The resulting vector is a weighted summary of relevant information from the entire sequence.
Why Single-Head Attention Is Limited
Single-head attention applies this process once, producing a single perspective of the input. While effective, this approach forces the model to compress all relationships into one representation. This becomes a limitation when the data contains multiple types of dependencies, such as grammar, meaning, and long-distance relationships.
In practice, language often requires understanding multiple relationships at once.
For example, one word may depend syntactically on one token while being semantically related to another. A single attention head struggles to capture all these patterns simultaneously.
Multi-Head Attention in Transformers
In Transformer encoders, multi-head self-attention allows each token to attend to every other token in the input, producing contextualized embeddings. In decoders, masked self-attention ensures that tokens cannot attend to future positions, which is essential for autoregressive generation. In encoder–decoder attention, queries come from the decoder while keys and values come from the encoder, enabling alignment between input and output sequences.
These different uses of multi-head attention allow Transformers to handle tasks such as translation, summarization, and text generation with high accuracy.
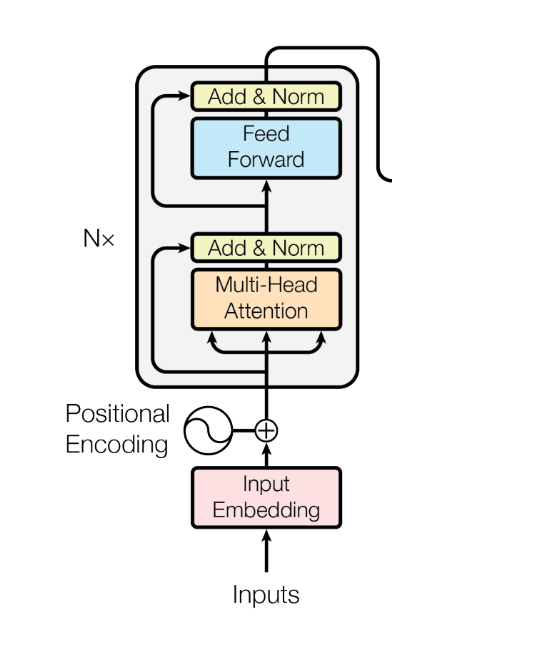
How Multi-Head Attention Works
Multi-head attention addresses this limitation by running several attention mechanisms in parallel. Instead of applying attention directly to the original embeddings, the model first projects them into multiple lower-dimensional spaces using learned matrices.
For each head i, the projections are computed as:
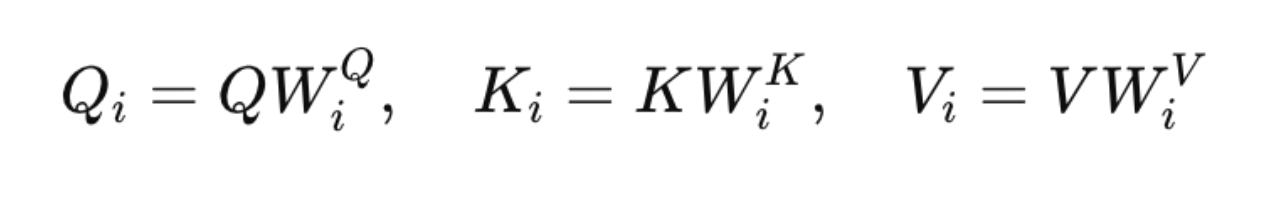
Each head then applies scaled dot-product attention independently:

The outputs of all heads are concatenated and passed through a final linear layer:
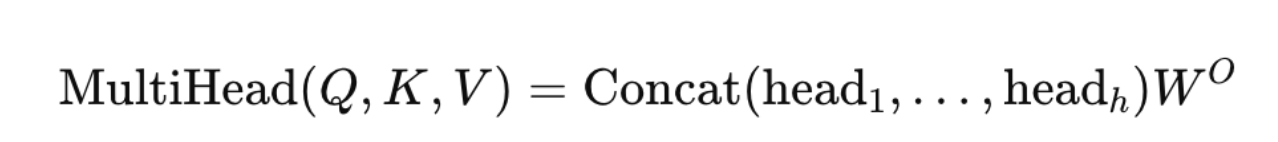
Intuitively, each head learns to focus on a different aspect of the sequence. One head may capture word order, another may focus on semantic similarity, while another may track long-range dependencies. The final projection combines these perspectives into a single rich representation.
Multi-Head Attention in PyTorch (With Tensor Shapes)
The following example shows how multi-head attention works internally using PyTorch. We start with a batch of token embeddings and walk through the key steps, highlighting how tensor shapes change throughout the process.
import torch
import torch.nn as nn
We assume a batch of tokenized sequences, where each token is represented by an embedding vector.
batch_size = 2
sequence_length = 4
embedding_dim = 8
num_heads = 2
head_dim = embedding_dim // num_heads
Here, embedding_dim is split evenly across attention heads. Each head will operate on vectors of size head_dim.
x = torch.randn(batch_size, sequence_length, embedding_dim)
At this stage, the input tensor shape is:
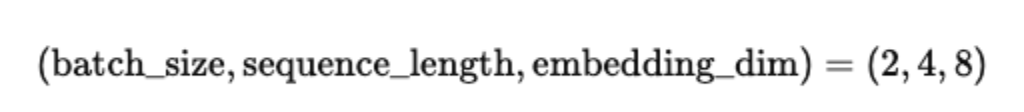
Step 1: Linear Projections for Queries, Keys, and Values
Each token embedding is projected into queries, keys, and values using learned linear layers.
W_q = nn.Linear(embedding_dim, embedding_dim)
W_k = nn.Linear(embedding_dim, embedding_dim)
W_v = nn.Linear(embedding_dim, embedding_dim)
Q = W_q(x)
K = W_k(x)
V = W_v(x)
After projection, all three tensors have the same shape:
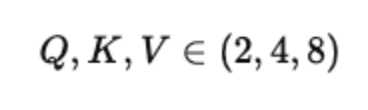
Step 2: Split Embeddings Into Multiple Heads
To create multiple attention heads, we reshape the tensors so each head works on a smaller subspace.
Q = Q.view(batch_size, sequence_length, num_heads, head_dim)
K = K.view(batch_size, sequence_length, num_heads, head_dim)
V = V.view(batch_size, sequence_length, num_heads, head_dim)
The new shape becomes:
(2,4,2,4)
We then transpose the tensors to bring the num_heads dimension forward.
Q = Q.transpose(1, 2)
K = K.transpose(1, 2)
V = V.transpose(1, 2)
Now each tensor has shape:
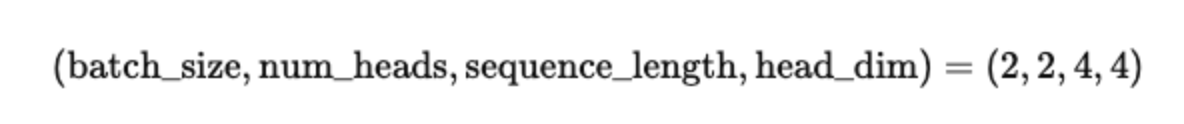
Step 3: Scaled Dot-Product Attention
We compute attention scores by taking the dot product between queries and keys.
scores = torch.matmul(Q, K.transpose(-2, -1))
scores = scores / (head_dim ** 0.5)
The attention score tensor has shape:
(2,2,4,4)
This represents how much each token attends to every other token within each head.
Step 4: Softmax and Weighted Sum
We normalize the attention scores using softmax and apply them to the values.
attention_weights = torch.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, V)
The output per head has the shape:
(2,2,4,4)
Each token now contains a context-aware representation based on attention.
Step 5: Concatenate Heads and Final Projection
We combine all attention heads back into a single embedding.
output = output.transpose(1, 2)
output = output.contiguous().view(batch_size, sequence_length, embedding_dim)
The concatenated output shape is:
(2,4,8)
A final linear layer mixes information across heads.
W_o = nn.Linear(embedding_dim, embedding_dim)
final_output = W_o(output)
The final output tensor has shape:
(2,4,8)
This matches the original embedding dimension and can be passed to the next Transformer layer.
Using PyTorch’s Built-in MultiHeadAttention
PyTorch also provides a built-in implementation that handles these steps internally.
mha = nn.MultiheadAttention(
embed_dim=embedding_dim,
num_heads=num_heads,
batch_first=True
)
output, attention_weights = mha(x, x, x)
Here, output has shape (2, 4, 8), and attention_weights has shape (2, 2, 4, 4) when average_attn_weights=False.
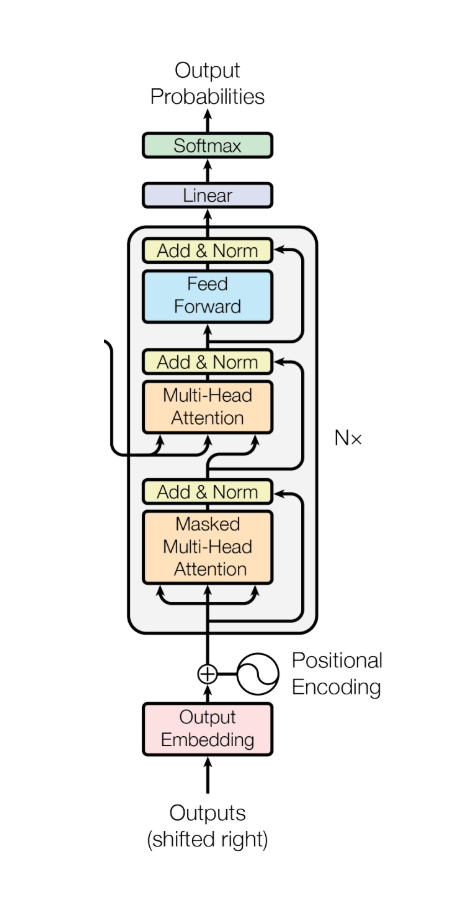
What Is Masked Multi-Head Attention?
Masked Multi-Head Attention is a special form of attention used when a model must not see future words.
In simple words:
Masked Multi-Head Attention prevents a word from looking ahead in the sentence.
This is essential for text generation models like GPT, where the model predicts the next word one step at a time.
When generating text, the model should behave like a human writing a sentence. At any moment, you can only use past words, not future ones. If the model could see future words during training, it would be cheating. Masking ensures the model learns to predict the next word using only what has already appeared.
Multi-head attention means running several attention mechanisms in parallel so the model can capture different types of relationships, such as grammar, meaning, or emphasis. Masking means hiding future words so the model cannot cheat by seeing information it should not have yet.
The mask is a triangular matrix:
[ allowed blocked blocked ]
[ allowed allowed blocked ]
[ allowed allowed allowed ]
This ensures future positions are blocked during attention score computation.
Each attention head first computes attention scores using queries and keys. Before softmax is applied, the mask is added to these scores. The mask assigns extremely large negative values to future positions, making their softmax probability zero.
This process is repeated independently for each head. Afterward, all head outputs are concatenated and passed through a linear layer to produce the final output.
The key idea is that masking happens before softmax and independently in each head.
FAQs
Why does multi-head attention split embeddings into smaller dimensions?
Splitting embeddings allows each attention head to operate in a different subspace. This prevents heads from learning identical patterns and encourages diversity in the relationships each head captures.
Why is softmax used in attention instead of another normalization method?
Softmax converts similarity scores into probabilities that sum to one, making the attention weights interpretable and stable. It ensures that more relevant tokens receive higher weights while less relevant ones contribute minimally.
What happens if the scaling factor is removed from attention?
Without scaling, dot-product values can grow large as dimensionality increases. This pushes softmax into saturated regions where gradients are very small, slowing down learning and harming model performance.
Is multi-head attention interpretable?
To some extent, yes. Attention weights can be visualized to show which tokens influence others. However, interpretation becomes harder as models grow larger and heads interact in complex ways.
Why does multi-head attention scale poorly with long sequences?
Attention computes pairwise interactions between all tokens, resulting in quadratic time and memory complexity. This makes long sequences expensive to process, motivating efficient variants such as sparse attention and FlashAttention.
Conclusion
Multi-head attention extends the basic attention mechanism by allowing models to focus on multiple aspects of the input in parallel. Through separate attention heads, it captures diverse relationships that a single attention mechanism cannot represent effectively. With stable scaling, parallel computation, and rich contextual modeling, multi-head attention has become a cornerstone of modern deep learning architectures. Understanding this mechanism provides deep insight into how today’s most powerful AI models process and reason over complex data.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
