AI Technical Writer

From Simple Predictions to Complex Intelligence
From simple regression model to complex models like GPT, BERT and diffusion model Machine learning models have transformed from simple model to deep learning model to transformer model. Earlier these simple regression models used to predict outcomes now the advanced transformer architecture model is the backbone of today’s AI systems.
Regression models are one of the earliest forms of supervised learning, where the model learns from labeled data to predict continuous outcomes. They help data scientists understand why certain results occur by identifying clear relationships between variables. These models helped to understand why certain outcomes happened in the dataset by identifying clear relationships between variables.
On the other hand, transformer models are focused on predicting what comes next by learning complex patterns from massive datasets. Transformers are semi-supervised learning models that can learn massive amounts of unlabeled or partially labeled data.
In this article, we’ll explore how regression and transformer models compare in terms of architecture, data handling, interpretability, and performance, helping you choose the right approach for your machine learning tasks.
Key Takeaways
- Regression models are simple, fast, and interpretable, making them ideal for structured data and straightforward prediction tasks.
- Transformers excel at handling complex, sequential, or multimodal data, capturing patterns and relationships that traditional models cannot.
- Efficiency trends such as parameter-efficient fine-tuning (PEFT) and lightweight transformer variants make transformers more accessible for real-world applications.
- Choosing the right model depends on data type, problem complexity, and resources: use regression for clarity and speed, and transformers for scale and complexity.
Understanding Regression in Machine Learning
Regression is one of the foundational techniques in supervised learning, where the goal is to predict a continuous output variable based on one or more input features. Regression models aim to model the relationship between dependent (target) and independent (predictor) variables by fitting a function that best describes their correlation.
In simpler terms, regression helps to understand how one variable changes with respect to the other variable. For example, predicting house prices or estimating the temperature.
The essence of regression lies in finding patterns in numerical data. The model assumes that there’s an underlying mathematical relationship between inputs and outputs, and it learns the best-fit function typically by minimizing an error metric, also known as the loss, such as Mean Squared Error (MSE) or Mean Absolute Error (MAE).
A simple linear regression can be represented as:
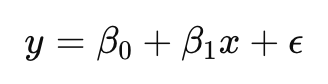
where:
- y = predicted output
- x= input feature
- β0 = intercept
- β1 = slope or coefficient representing the relationship strength
- ϵ = error term (difference between predicted and actual values)
Types of Regression Models
While Linear Regression is one of the most common and straightforward regression models, there are several extensions of this method that are capable of capturing complex relationships between the target and predictor variables. Let’s explore the most common ones in detail.
Multiple Linear Regression: Multiple Linear Regression (MLR) is an extension of simple linear regression that models the relationship between a dependent variable and two or more independent variables. Instead of fitting a single line, MLR fits a hyperplane in multidimensional space that best represents the data.
The equation for multiple linear regression is expressed as:
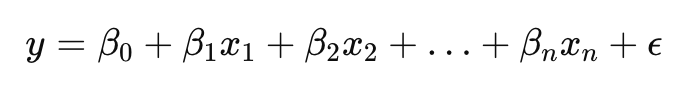
Here, y represents the target variable, x1,x2,…,xn are the predictor variables, β0 is the intercept, β1,β2,…,βn are the coefficients representing the influence of each predictor, and ϵ denotes the error term.
Multiple Linear Regression assumes a linear relationship between each independent variable and the dependent variable. It is one of the most used regression models in economics, healthcare, and marketing fields for tasks like predicting sales, assessing risk, or estimating demand. However, it requires that the predictors are not highly correlated (a condition known as multicollinearity), and it can struggle when data relationships are non-linear.
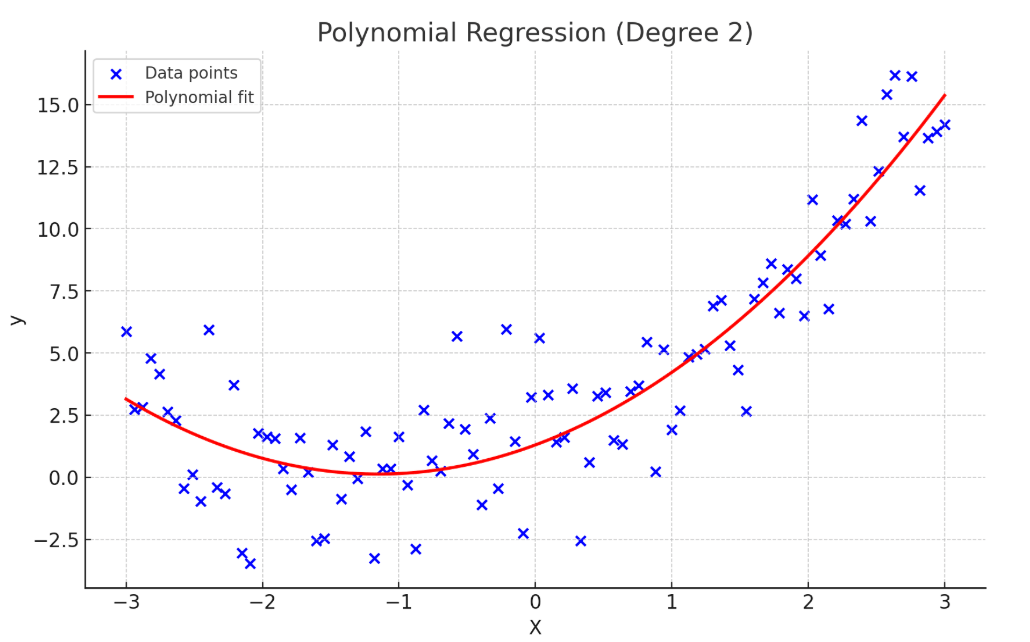
Polynomial Regression: Polynomial Regression extends linear regression by allowing the model to fit non-linear relationships between the independent and dependent variables. Instead of using only the original features, it introduces higher-order terms (squares, cubes, etc.) of the features to capture curvature in the data. The general form of a polynomial regression model is:
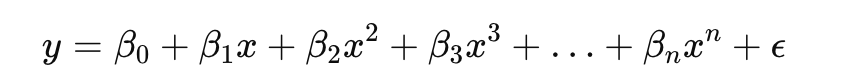
By adding these polynomial terms, the model can bend the regression line to follow complex data patterns, making it suitable for problems where the relationship between input and output is not strictly linear, such as modeling population growth or predicting temperature variations. However, polynomial regression is prone to overfitting, especially when higher-degree terms are used without sufficient regularization or data points to support them.
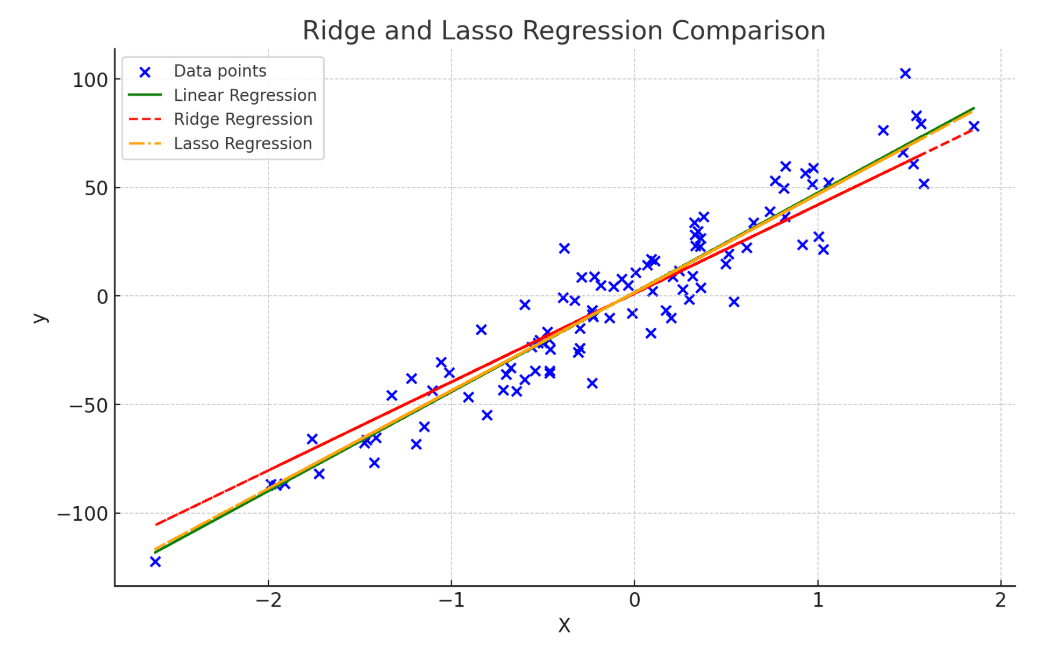
Ridge and Lasso Regression: While linear and polynomial regression models aim to minimize the residual sum of squares, they often suffer from overfitting when dealing with a large number of correlated features. Ridge and Lasso Regression introduce regularization, which penalizes large coefficients to enhance generalization.
Ridge Regression (also known as L2 regularization) adds a penalty equal to the sum of the squared magnitudes of the coefficients to the loss function:
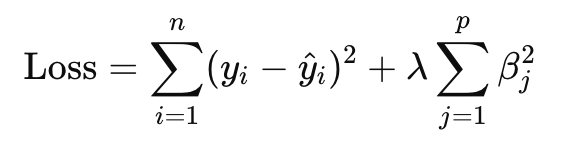
Here, λ is the regularization parameter that controls the strength of the penalty. A higher λ value shrinks the coefficients more aggressively, reducing model variance but increasing bias slightly.
Lasso Regression (L1 regularization) uses the absolute value of the coefficients for the penalty:
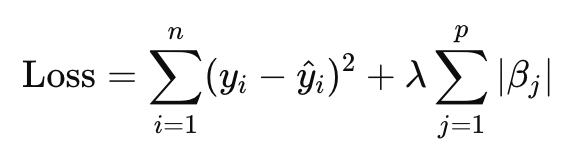
The key distinction is that Lasso can shrink some coefficients to zero entirely, effectively performing feature selection, which makes it especially useful when working with high-dimensional data. Both Ridge and Lasso aim to improve prediction accuracy and model stability, with Elastic Net combining both penalties for balanced performance.
Logistic Regression: Despite its name, Logistic Regression is primarily used for classification tasks, not regression. It predicts the probability of a binary outcome (such as “yes/no” or “spam/not spam”) by modeling the relationship between the input variables and the log-odds of the target event.
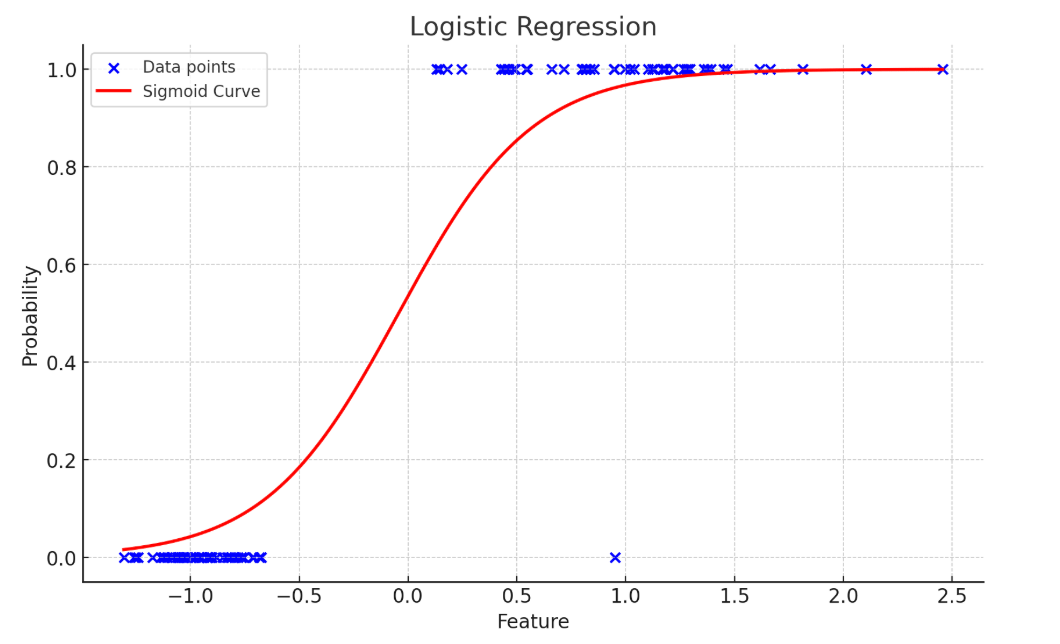
The logistic regression model is expressed as:
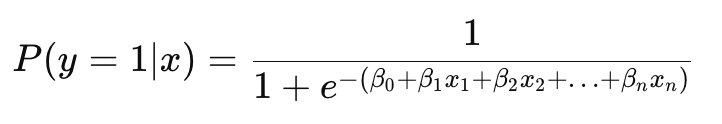
Here, the function 1/(1+e-z )is known as the sigmoid function, which maps any real-valued input into a range between 0 and 1, representing the probability that the dependent variable equals 1.
Logistic regression is widely used in applications such as fraud detection, medical diagnosis, and marketing segmentation because of its simplicity, interpretability, and solid probabilistic foundation. Although it does not handle non-linear relationships directly, techniques such as feature transformation and interaction terms can enhance its flexibility.
Understanding Transformer Models
Transformers are deep learning architectures that are specifically designed to handle sequential data like text, speech, or time series data. Unlike older models such as RNNs (Recurrent Neural Networks) or CNNs (Convolutional Neural Networks), transformers can process entire sequences at once instead of step by step. This process is conducted by the encoder and decoder of the transformer. The transformer model was introduced in the 2017 paper “Attention is All You Need” by Vaswani et al., which marked a turning point in the evolution of modern AI, especially in natural language processing (NLP).
At a high level, a transformer consists of two main parts:
- Encoder: Processes the input data (for example, a sentence) and converts it into meaningful representations.
- Decoder: Uses those representations to generate the output (for example, translating a sentence into another language).
Each of these parts is made up of multiple identical layers that include components like attention mechanisms and feed-forward networks.
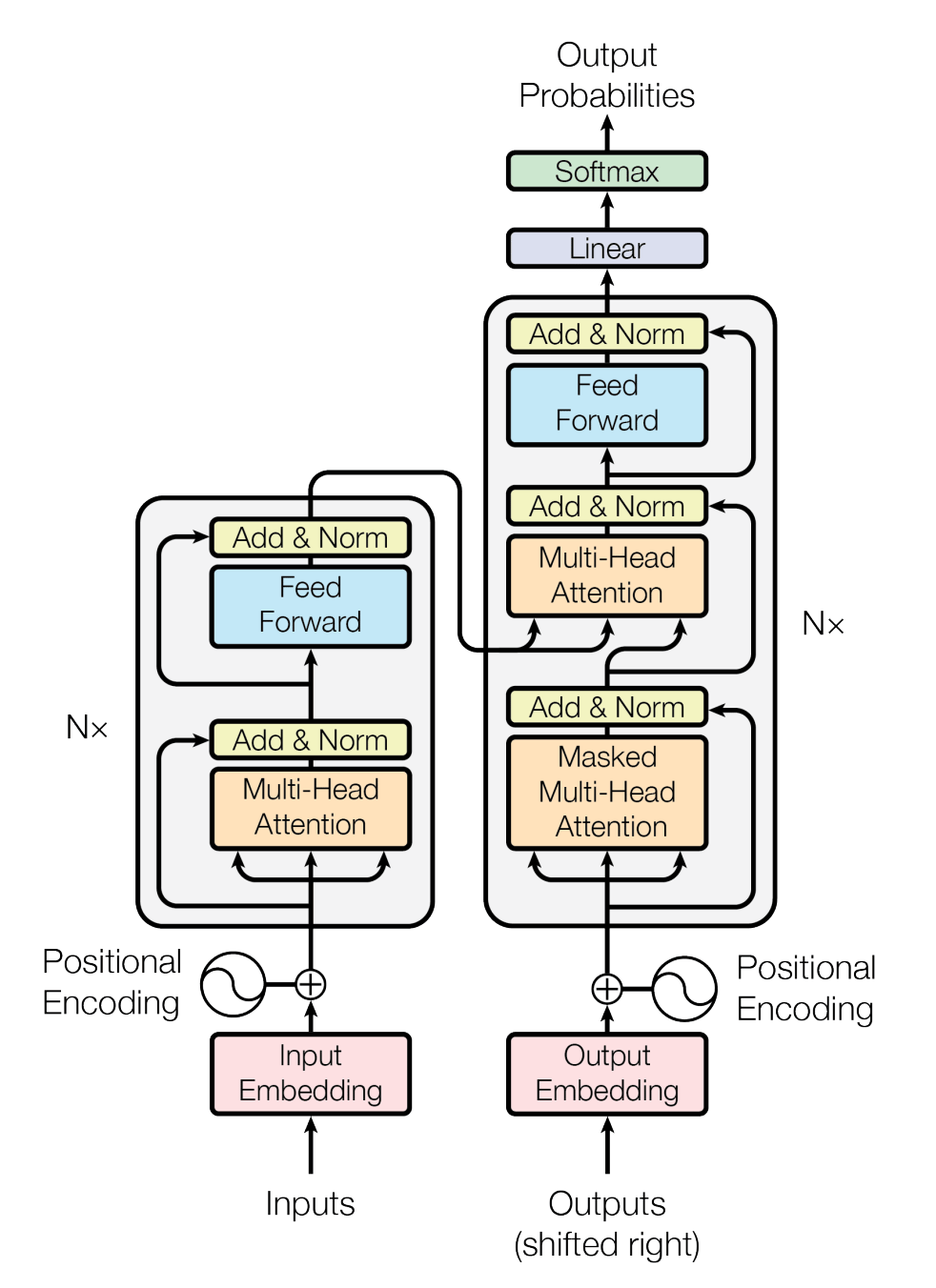
To understand the concept in detail, feel free to check out the detailed blog on transformers linked in the resources section.
The main idea behind transformers is the attention mechanism, which allows the model to focus on the most relevant parts of the input data when making predictions.
1. Input Embedding and Positional Encoding
When you feed text into a transformer, the words are first converted into vectors (numerical representations) called embeddings. However, since transformers process all words in a sequence simultaneously, they don’t know the order of words by default.
To fix this, transformers use positional encoding, which adds unique information about each word’s position in the sentence. This helps the model understand that “the cat sat on the mat” is different from “on the mat sat the cat.”
2. Self-Attention Mechanism
The self-attention mechanism is the heart of the transformer. It allows each word in a sentence to look at (or “attend to”) other words and figure out which ones are most relevant.
For example, in the sentence:
“The animal didn’t cross the street because it was too tired,”
The model needs to understand that “it” refers to “the animal,” not “the street.” Self-attention makes this possible by computing how much attention each word should pay to every other word.
It does this using three components for every word:
- Query (Q) – represents the current word we’re focusing on.
- Key (K) – represents the words we can attend to.
- Value (V) – holds the actual information of those words.
The model calculates attention scores using the formula:
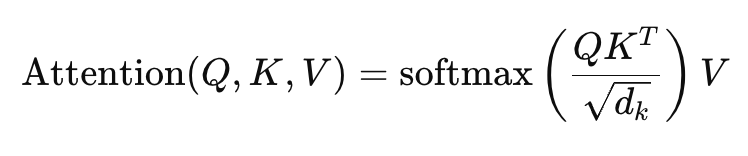
This formula decides how much focus (or weight) each word should receive from others.
3. Multi-Head Attention
Instead of doing self-attention once, transformers perform it multiple times in parallel. This is called multi-head attention.
Each “head” learns different types of relationships.
For example:
- One head might focus on grammatical relationships (like subject–verb).
- Another might focus on semantic meaning (like synonyms or related concepts).
This multi-head setup helps the model better understand complex patterns in language.
4. Feed-Forward Neural Network (FFN)
After attention, the output goes through a feed-forward network, which is simply a small neural network applied to each word’s representation. This step helps the model learn deeper, non-linear patterns and refine its understanding before passing it to the next layer.
5. Layer Normalization and Residual Connections
Transformers also include residual connections (shortcuts that add the input of a layer to its output) and layer normalization (a technique to stabilize learning). Together, they help the model train faster and avoid issues like vanishing gradients.
6. Decoder Mechanism (for Tasks like Translation)
The decoder works similarly to the encoder, but with an additional twist: it uses masked self-attention, so it can only see previous words, not future ones (to prevent “cheating” during text generation).
It also has encoder-decoder attention, allowing the decoder to focus on relevant parts of the encoder’s output when generating each word.
Regression vs Transformers: A Comparative Breakdown
| Feature | Regression Models | Transformers |
|---|---|---|
| Purpose | Predict outcomes and are used to understand relationships between variables. Simple and effective for structured data. | Handle sequential or multimodal data. Excellent for text, images, audio, and complex patterns. |
| Learning Type | Mostly supervised learning uses labeled data. Easy to train and understand. | Supervised or semi-supervised; can also leverage large unlabeled datasets for pretraining. Supports large-scale knowledge acquisition. |
| Architecture | Simple formulas with coefficients. Interpretable and low-complexity. | Deep layers with self-attention, feed-forward networks, and multi-head attention. Captures complex relationships and long-range dependencies. |
| Data Handling | Structured, tabular datasets. Limited to sequences or unstructured data. | Sequential and multimodal datasets, large-scale processing. Highly scalable with parallel processing. |
| Modeling Capacity | Captures linear or simple non-linear relationships. Struggles with long-range dependencies. | Excels at complex patterns and long-range dependencies. Ideal for NLP, vision, and multimodal tasks. |
| Interpretability | Highly interpretable. Coefficients clearly explain predictions. | Harder to interpret. “Black-box” behavior due to billions of parameters. |
| Scalability | Limited. Not ideal for huge datasets. | Highly scalable. Can train on massive datasets with multiple GPUs. |
| Compute Requirements | Low to moderate; works on CPUs or small GPUs. Cost-effective. | High; requires GPUs like NVIDIA H100/A100. Resource-intensive, expensive to train. |
| Applications | Sales prediction, housing prices, medical outcomes, and trend analysis. Simple predictive tasks. | Language modeling, translation, summarization, and vision-language tasks. Drives LLMs and VLMs like GPT, Llama, Claude, and CLIP. |
| Strengths | Fast, interpretable, low-cost. Great for straightforward predictive problems. | Handles complex sequences, long-range dependencies, and scalable, multimodal learning. Powers state-of-the-art AI models. |
| Limitations | Cannot handle complex sequences; limited predictive power. Not suitable for modern deep learning tasks. | Expensive, energy-intensive, hard to interpret, requires large datasets and GPUs. High resource demand. |
When to Use Regression vs Transformers
Choosing the right model depends on the type of data, the complexity of the problem, and the resources available to build the model. Regression models are simple models; they do not require much computing and are also easy to interpret. However, transformers deal with complex problems and sequential data and require larger computing resources. The table below helps you understand when to pick regression and when to go for transformers based on your specific needs.
| Situation / Need | Use Regression Models | Use Transformers |
|---|---|---|
| Data Type | Works best with structured, tabular data, mainly used when the predictor is a continuous variable or categorical. | Best for sequential or unstructured data, text, images, audio, or combinations. |
| Problem Complexity | Suitable for simple relationships or predicting outcomes with a few variables. | Ideal for complex relationships and long-range dependencies in data. |
| Data Size | Small to medium datasets. Easy to train quickly. | Large datasets. Can scale to millions or billions of examples. |
| Interpretability Needed | Yes, when you need clear insights about how input affects output. | Not ideal, models are “black boxes” and hard to explain. |
| Speed of Training | Fast, trains in seconds to minutes. | Slower, may take hours or days, depending on dataset size and model scale. |
| Task Examples | Predicting house prices, sales forecasting, medical outcomes, and trend analysis. | Language translation, text generation, summarization, chatbots, and vision-language tasks. |
| Budget & Energy Concerns | Low cost and low energy use. | Expensive and energy-intensive; may require cloud GPUs to manage costs. |
| When to Choose | Use regression when you need quick, interpretable results with structured data. | Use transformers when tackling modern AI problems that involve sequences, context, or multimodal inputs. |
Future of Predictive Modeling
The future of predictive modeling is all about combining the strengths of different approaches. One exciting trend is combining the clarity of regression models with the power of transformers. For example, transformers can take complex data like text, images, or sequences and turn them into smart feature representations. These features can then be fed into a regression model, giving you the best of both worlds: the transformer’s ability to understand complex patterns, and the regression model’s simplicity and interpretability.
Another big trend is making transformers more efficient and easier to use. Techniques like Parameter-Efficient Fine-Tuning (PEFT) let you tweak a large transformer for a specific task without retraining the whole model, which saves time, energy, and money. We’re also seeing lightweight transformer versions designed to run on edge devices or smaller systems, bringing advanced AI to places where huge GPUs aren’t available.
FAQs
Q1: What is the main difference between regression models and transformers? Regression models are simple, interpretable models used for structured data and straightforward predictions. Transformers are deep learning architectures designed to handle complex, sequential, and multimodal data, capturing long-range dependencies that regression cannot.
Q2: When should I use a regression model instead of a transformer? Use regression when your data is small or structured, interpretability is important, and the relationships are relatively simple. Regression is fast, cost-effective, and easy to implement.
Q3: When are transformers a better choice? Transformers are ideal for large datasets, sequential data (like text or time series), or multimodal tasks. They excel at understanding complex patterns, context, and long-range dependencies that simpler models can’t capture.
Q4: Can regression and transformers be used together? Yes. A hybrid approach can use transformer-generated embeddings as input to a regression model, combining the transformer’s ability to capture complex features with the regression model’s interpretability and simplicity.
Q5: What are the limitations of transformers compared to regression? Transformers require large datasets, high computational power, and GPUs to train. They are harder to interpret and more energy-intensive, while regression models are lightweight, easy to understand, and cheaper to run.
Conclusion
When it comes to choosing between regression models and transformers, it’s all about the right tool for the right task. Regression models are the best choice when your data is structured, your problem is straightforward, and interpretability matters. The best part about these models is that they are simple, fast, and easy to understand. Transformers, on the other hand, are designed for handling complex, sequential, or multimodal data, capturing patterns and relationships that simpler models simply can’t. Ultimately, understanding the strengths and limitations of each approach allows us to make smarter choices, using regression for clarity and speed and transformers for complexity and scale.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
