By Adrien Payong and Shaoni Mukherjee

Introduction
Traditional databases’ limitations are no longer mysterious in a world fueled by high-dimensional data.
Vector databases are database systems designed for storing and managing high-dimensional vectors, representing numerical representations of data that capture semantic information.
This article features some of the most popular vector databases tools, such as Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy, and Qdrant.
We also explore their strengths, limitations, and use cases to guide the reader in the growing vector database space.
Prerequisites
To follow this tutorial, you must understand high-dimensional data, vector embeddings, and similarity searches. It requires some knowledge of Python, Rust, or TypeScript and machine learning techniques with frameworks such as PyTorch. You must know how to create a development environment using Python 3.8+ and machine learning libraries to use Pinecone, FAISS, Milvus, and Qdrant most efficiently.
Why Are Vector Databases Necessary?
Understanding High-Dimensional Data
High-dimensional data (data that contains many variables) is very common in applications where complex features have to be computed and compared. For example, each word can be encoded as a vector in NLP, and similar words are located nearby. Such representations capture nuance, which makes it possible to analyze complex relationships. Vector databases are built to handle this type of data, which traditional databases struggle with because they depend on tabularized data structures.
The Need for Efficient Similarity Search
Vector databases have one thing in common — they support similarity searches. Similarity searches identify the “closest” record in the database to a vector. This is important for operations such as recommendation engines and personalization tools. Unlike keywords and SQL searches, similarity search depends on the indexing mechanism, such as Approximate Nearest Neighbors (ANN), that vector databases are built to support.
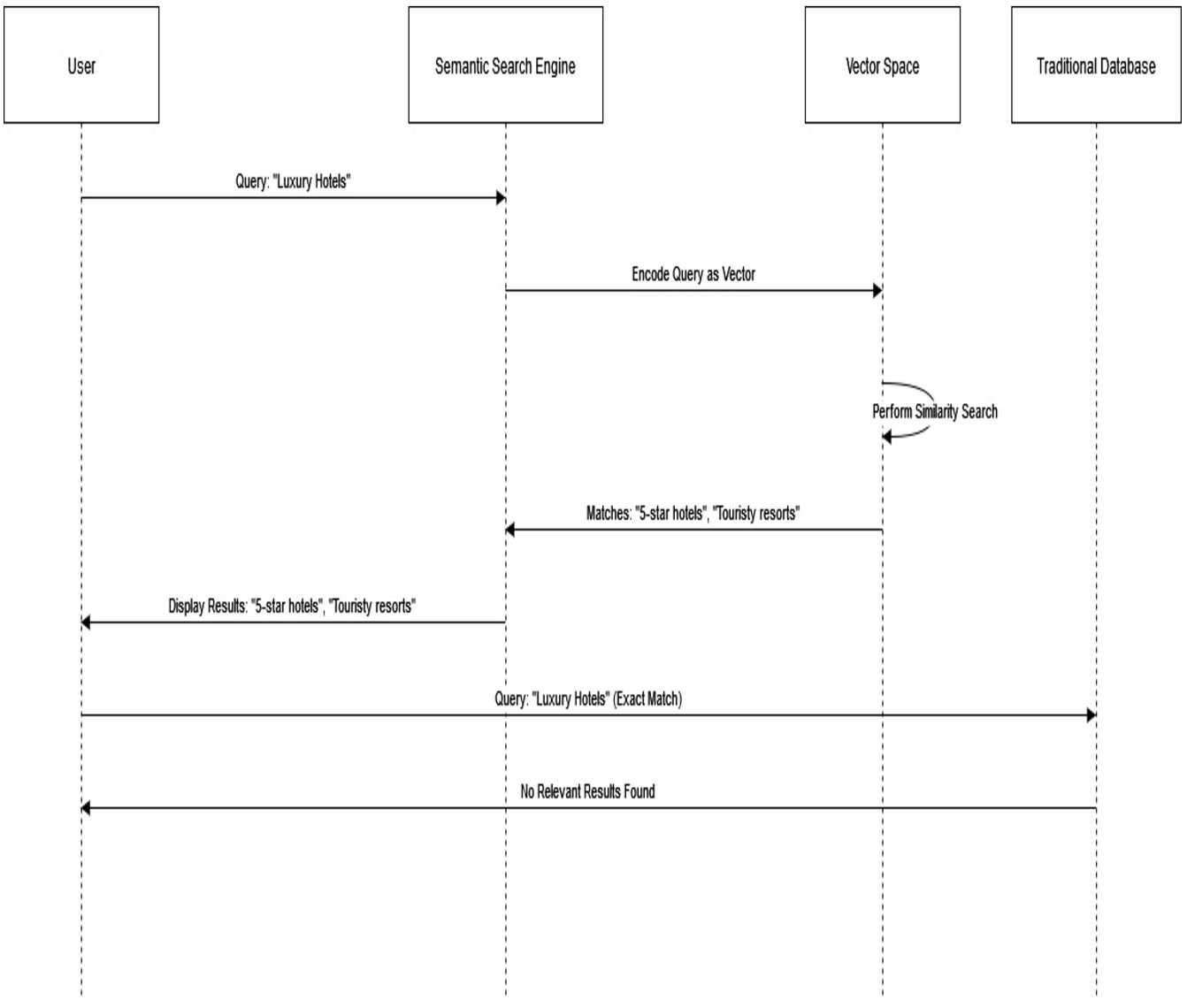
To make this more concrete, we will consider a semantic search engine. A user searching for “luxury hotels” might use natural language input. The vector-encoded engine searches for phrases semantically related to each other, such as “5-star hotels” or “touristy resorts,” and finds matching entries.
Traditional databases would struggle with these queries as they mainly deal with exact matching or rigid models such as SQL queries instead of the finer, more complex relationships inherent in vector spaces.
The diagram below shows that a semantic search engine encodes a user query into a vector, performs a similarity search across vectors, and returns semantic results such as ‘5-star hotels’ and ‘Touristy resorts.’ The traditional database handles the same query using exact matching and fails to return any relevant results, demonstrating traditional databases’ limitations in handling semantic relationships.
AI and Machine Learning Integration
Vector databases are a natural fit for AI and machine learning applications. AI models also often generate vectors to represent the data being processed. A database must efficiently store, retrieve, and index these vectors for seamless integration with real-time applications.
Let’s consider an image recognition system. When a user uploads an image of a landmark, the AI model processes the image and creates a vector embedding that describes its contours, colors, and textures. These vectors are then stored in a vector database.
Whenever a user uploads a similar image, the system searches the database for the most similar vector embeddings and identifies the matching landmarks. This can be done efficiently if the database stores, accesses, and indexes vectors. These capabilities are necessary for real-time recognition and similarity matching to be possible.
Current Options in the Vector Database Landscape
As vector databases rise in popularity, several solutions have emerged, each with unique strengths and limitations. We will examine some of the top vector databases available today.
Introduction to Pinecone
Pinecone is a powerful vector database built to support the needs of modern AI and machine learning projects. As a fully managed service, it reduces the time it takes to store, index, and query large amounts of vector data. Consequently, Pinecone is ideal for real-time similarity searches and large-scale applications. Its simplicity and performance have made Pinecone one of the pioneers in the growing vector database space.
How Pinecone Works
Pinecone allows developers to store, index, and query high-dimensional data as vectors. This is helpful in recommendation systems or semantic search engines, where it is important to understand the similarity between products.
Step 1: Install and Import Pinecone
To start, we must install the Pinecone Python client library. This allows us to access Pinecone’s services from the code.
pip install pinecone-client
We must also Import the necessary modules into the Python code:
from pinecone import Pinecone, ServerlessSpec
Step 2: Initialize Pinecone
Consider this step as “logging in” to Pinecone’s service.
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key="API_KEY")
We can replace the API key with the one that was issued by our Pinecone account.
Step 3: Create an Index
An index is a container where we store data (vectors). To create one:-
index_name = “index_use_case”
pc.create_index(name=index_name,
dimension=6,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
Here:
- “index_use_case” is the name of our index.
- dimension=6 is the number of features in our vectors (e.g., 6-dimensional vectors).
- metric=“cosine”: Define the similarity metric for searching (e.g., cosine similarity).
- The cloud=”aws” specifies that the index will be hosted on Amazon Web Services (AWS).
- The region=“us-east-1” specifies that the index will be in the US East (N. Virginia) region.
Step 4: Connect to the Index
Once we have created an index, we can connect to it.
index = pc.Index("index_use_case")
Now, we can use the variable index to make operations on our new index.
Step 5: Insert data into the Index
Here, we can add data (vectors) to our index. Each vector has:
- An ID (a unique name for the vector).
- Values (the actual vector representation).
Example:-
data = [
{"id": "items1", "values": [1, 2, 3, 4, 5, 6]},
{"id": "items2", "values": [8, 7, 6, 5, 4, 3]},
]
index.upsert(items=data)
The code above uploads two vectors into the index.
Step 6: Query the Index
The query() method allows a search for vectors similar to a given query vector. For example:-
query_v = [2, 1, 4, 3, 6, 5]
res = index.query(vector=query_v, top_k=3)
Here:
- vector=query_v is the vector we’re searching for.
- top_k=3 is the number of similar items returned.
The output will return the IDs and similarity scores of the top 3 matching vectors.
Step 7: Manage Your Index
Once done, we can access or clear the index as needed:
- List all indexes:
print(pc.list_indexes())
- Delete an index:
pc.delete_index(“index_use_case”)
We have shown how to configure and interact with Pinecone. Please replace the placeholders with your data and settings.
Strengths of Pinecone
Let’s consider some of the strengths of Pinecone:
- Ease of Use: Pinecone’s fully managed approach allows developers to implement it into their applications with minimum effort. The API-first structure makes it accessible even for those unfamiliar with vector databases.
- High Performance: Pinecone’s emphasis on speed allows even the most complex similarity searches with large data sets to be executed in milliseconds.
- Reliable Scalability: Pinecone scales up without compromising performance as data grows, making it ideal for start-ups and enterprise-level deployments.
- Cross-Platform Integration: It supports an efficient model-to-production process and is compatible with multiple AI frameworks.
Weaknesses of Pinecone
While Pinecone is an excellent solution for many use cases, it does have some limitations:
- Limited Flexibility: Pinecone’s managed architecture can feel too locked down for some developers, as it does not allow for the same customization and control as self-hosted solutions.
- Dependency on Cloud: Pinecone is a cloud service that may not be suitable for an enterprise with a high on-premise data use case.
FAISS Explained: Optimizing Similarity Search and Clustering for Large-Scale Data
FAISS stands for Facebook AI Similarity Search, an open-source library that can perform similarity search and clustering of dense vectors. Dense vectors are numerical representations of data (e.g., text embeddings, images, audio tracks) in machine learning models.
FAISS is optimized to:
- Get the nearest neighbors of a query vector among millions, even billions of other vectors.
- Provide fast and memory-efficient performance using product quantization and inverted file indexing methods.
- Scale on CPUs and GPUs, enabling real-time and large-scale offline deployment.
How FAISS Works
Amongst FAISS’s core competencies lies the fact that it can be used to convert high-dimensional vector similarity searches into efficient operations. Here’s how it works:
Indexing
FAISS creates an index of vectors using one of its indexing techniques before it performs similarity searches:
- Flat Index organizes vectors for exhaustive search. While highly accurate, it is computationally intensive for large datasets.
- IVF(Inverted File) partitions vectors into clusters and restricts the search space to clusters relevant to queries.
- Product Quantization (PQ) reduces vectors into more miniature representations at the expense of some accuracy in exchange for faster searches and lower memory usage.
- HNSW (Hierarchical Navigable Small World) builds a graph where nodes represent vectors, enabling rapid traversal to find the nearest neighbors.
Search Query
FAISS searches the indexed vectors when a query vector is provided using an exact or approximate method:
- For exact searches, the query vector is compared to all vectors in the index, ensuring maximum accuracy.
- For approximate searches, FAISS uses techniques like compressed representations or clustering to accelerate search while maintaining reasonable accuracy.
Distance Metrics
FAISS provides different similarity metrics for use cases, such as Euclidean distance or cosine similarity.
Strengths of FAISS
Let’s consider some strengths of FAISS:
- Speed: FAISS allows quick similarity searches, even for datasets with billions of vectors. GPU support enhances its performance.
- Scalability: The library’s scalability on massive datasets ensures it is still relevant to large-scale applications.
- Flexibility: FAISS supports a range of indexing settings so that its behavior can be personalized to meet user requirements.
- Open Source: FAISS, being open-source, has the benefit of wide participation and adoption from the community.
Challenges and Limitations of Using FAISS
Despite its strengths, FAISS has some limitations. Let’s consider some of them:
- Complexity of Implementation: A good understanding of its indexing methods and trade-offs is required. Novice users may find it challenging to configure and optimize.
- Accuracy vs. Speed Trade-Off: Approximate approaches in FAISS sacrifice some accuracy for speed, which isn’t necessarily good in some use cases that require accuracy.
- Memory Usage: It allows memory-optimized operations such as product quantization, but an exact search using large datasets can still require high memory resources.
- Learning Curve: Implementing FAISS properly for specific datasets and uses can be time-consuming and require expertise.
Getting Started with FAISS
To get started with FAISS in our projects, we must first install the following:
pip install faiss-cpu
For GPU support:-
pip install faiss-gpu
Basic Usage Example
Here’s a quick demo on how to implement FAISS for nearest neighbor search:-
import numpy as np
import faiss
dim = 64
b = 10000
q = 1000np.random.seed(234)
x_b = np.random.random((b, dim))
x_q = np.random.random((q, dim))
index = faiss.IndexFlatL2(dim)
index.add(x_b)
k = 3
S, J = index.search(x_q, k)
# search
print(J[:3])
A FAISS index (IndexFlatL2) is created in the code above based on the Euclidean distance (L2) as a similarity measure. The database vectors (x_b) are stored in the index for faster search. The index.search method returns the top 3 closest neighbors (k=3) for each query vector in x_q: The resulting indices of the nearest neighbors (J) are printed for the first 3 queries.
Weaviate: An Open-Source Vector Database
Weaviate is a cutting-edge tool for storing raw data and its semantic representations. Unlike traditional databases, which work using an organized SQL-like pattern, Weaviate uses AI-driven vector embeddings for similarity-based queries.
This feature is necessary for context-driven applications like conversational AI, recommendation engines, content categorization, etc.
Fundamentally, Weaviate works with machine learning models to transform unstructured data into high-dimensional vectors. These vectors can be stored with data objects for similarity search, which is more relevant contextually than traditional keyword search.
How Weaviate Enables Semantic Understanding
In the image below, Weaviate transforms the search query “biology” into the semantic vector representation and compares it to stored vectors for contextual matches.
It pulls out and sorts the results by similarity score, providing the most similar documents, even if they do not have the exact keyword “biology”:
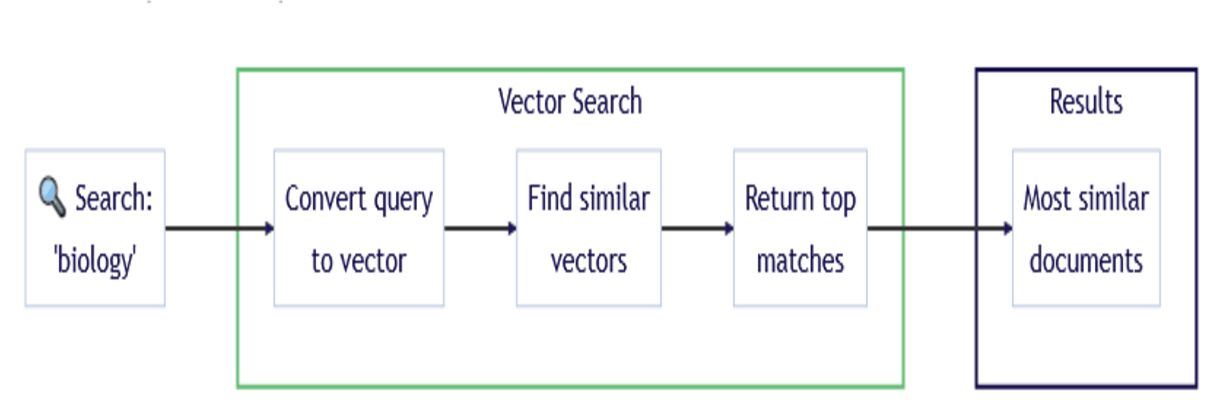
- Search: ‘biology’: A user enters a search query and say the term “biology.” In traditional databases, this can trigger a keyword search. However, in Weaviate, the query is transformed into a vector for semantic understanding.
- Convert Query to Vector: Weaviate vectorizes the text query using a vectorization module (OpenAI, Sentence Transformers). This vector encodes the query’s semantic meaning, enabling the system to search based on context instead of purely exact keyword matches.
- Find Similar Vectors: The vector representation of the query is compared with the vectors of stored data objects in the Weaviate database. The database looks up the vectors most similar to the query vector using distance metrics (such as cosine similarity). These vectors correspond to data objects that are semantically related to the user search query.
- Return Top Matches: Weaviate picks out the top matches based on similarity scores upon spotting similar vectors. These matches represent the most relevant documents, images, or other stored objects that align with the query.
- Results: Most Similar Documents: These results are presented to the user in order of relevance. In this case, documents or objects with the highest correlation to ‘biology’ would be returned, even if they didn’t include the specific keyword ‘biology.’
Some Keys Strengths of Weaviate
Let’s consider the strengths of Weaviate:
- Search engines rely on exact matches or keyword ranking, but Weaviate’s semantic search understands the meaning of the queries and returns more relevant results.
- Featuring multiple vectorization modules, Weaviate is adaptable to any type of data.
- HNSW indexing ensures fast query execution, even for datasets with millions of vector embeddings.
- GraphQL and RESTful APIs enable the developer to easily interact with the database, making it accessible to technical and non-technical users.
Challenges and Limitations of Using Weaviate
Below are some challenges associated with Weaviate:
- Weaviate is reliant on the vectorization model’s performance. In cases where the embeddings don’t accurately represent semantic relationships, the search results are sub-optimal.
- The vectorization and storage require very high computations and can be challenging in limited resource environments.
- The configuration of Weaviate can be a challenge for a novice unfamiliar with vector databases.
- As powerful as it is with unstructured data, Weaviate does not perform some powerful SQL-like operations, which leaves it unfit for traditional relational database scenarios.
- Although scalable, the cost of maintaining large-scale deployments can escalate, especially when combined with cloud infrastructure costs.
Milvus: Setting Up Milvus Lite for Local Vector Database Management
Milvus is an open-source vector database that efficiently organizes and searches vector data at a large scale. It is especially useful in knowledge bases, semantic search, and RAG applications. We’ll walk through how to install Milvus locally using Milvus Lite, a lightweight version of Milvus that can be integrated into client applications.
To start using Milvus, we must ensure that Python 3.8 or higher is installed in our local environment.
We will install the pymilvus package, which provides the Python client library and Milvus Lite, for local deployments. We can easily install it via pip:
pip install -U pymilvus
Next, we create a local Milvus vector database by specifying a MilvusClient and assigning a file name to store the data.
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
Here, we create a collection in Milvus (similar to a table in SQL databases) named “demo_collection” with a vector size 768.
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768,
)
The code above first checks if there is already a collection named “demo_collection” and deletes it if there is one, ensuring a fresh start. It then creates a new collection, demo_collection, with vector dimensions set to 768.
To perform a semantic text search, we will create vector embeddings with utility functions from the pymilvus[model] library. We must install the library—this includes Machine learning libraries such as PyTorch—for embedding generation.
pip install "pymilvus[model]"
Generate vector embeddings using the default model
from pymilvus import model
embedding_fn = model.DefaultEmbeddingFunction()
documents = [
"Artificial intelligence is a field in computer science.",
"There are many computer scientist today.",
"Deep learning is a subset of artificial intelligence.",
]
vectors = embedding_fn.encode_documents(documents)
dataset = [
{"id": i, "vector": vectors[i], "text": documents[i], "subject": "history"}
for i in range(len(vectors))]
The code above uses the DefaultEmbeddingFunction from pymilvus.model for encoding a list of text documents into high-dimensional vector embeddings. The documents revolve around artificial intelligence, computer science, and deep learning.
Each document is encoded as a vector via encode_documents. The result is presented as a list of dictionaries, including a unique ID, the corresponding vector, the original text, and a subject field labeled “history.”
Now, we will insert the generated embedding into the “demo_collection” collection:-
res = client.insert(collection_name="demo_collection", data=dataset)
print(res)
The code below will perform a search for vectors similar to query vectors
query_vectors = embedding_fn.encode_queries(["What is Deep learning?"])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,output_fields=["text", "subject"],
)
print(res)
The code above runs a similarity search on Milvus’s “demo_collection.” It starts by encoding the query “What is Deep Learning?” into a vector through the encode_queries method of the embedding_fn. The resulting vector is then passed to the client.search function that searches the collection for the two most similar vectors.
Strengths and Limitations of Milvus
This vector database is performant, optimized for fast querying, and can process billions of vectors efficiently. It has a strong community and good documentation, making it available to developers. It also provides multiple indexing options (IVF, HNSW, etc) for search performance to suit different use cases.
However, it comes with operational complexity and a huge overhead for deployment and scaling. It presents a steep learning curve for someone without experience setting up vector databases.
Chroma Vector Database
Chroma is a lightweight, intuitive vector database that’s easy and fast to use, perfect for small apps and prototyping projects.
Perhaps Chroma’s best quality is that it is easy to configure. Developers can install and begin working on it without any extensive training or technical know-how. It is, therefore, very easy to understand, even for novices in vector databases. Its lightweight nature makes it ideal for applications with minimal computation resources or smaller-scale environments with limited infrastructure.
Additionally, Chroma enables real-time updates and retrieval of dynamic data. This feature is important in applications where embeddings, such as recommendation engines, personal search engines, or chatbots, may have to be updated regularly. Its easy-to-use API also makes it adaptable for integration with any programming language and machine learning framework.
However, Chroma has a few drawbacks, such as reduced scalability when working with very large data sets and a lack of advanced features typically offered by more mature vectors.
Elastic Vector Search: Strengths, Weaknesses, and Applications
Elastic Vector Search allows similarity searches across large sets of vector data. It is a vector database with strengths and weaknesses. Its advantages include excellent scalability with horizontal scaling, distributed design, and near real-time search capabilities for use cases like recommendation engines.
It offers hybrid queries involving vector and traditional keyword searches. It is fully compatible with the Elastic Stack and has tools like Kibana for visualization and Logstash for data ingestion. It also offers customizable schemas and multiple indexing methods, such as HNSW, for performance.
However, it’s a heavy resource-consumption system (it consumes lots of memory and CPU). It’s not always easy to configure and might require expertise in Elasticsearch and vector data management.
Its accuracy-speed trade-offs for approximate nearest neighbor searches, limited specialized features unlike dedicated vector databases, and steep learning curve might make it unfriendly for new users.
Annoy (Approximate Nearest Neighbors Oh Yeah)
Annoy is an open-source project created by Spotify for fast approximate nearest neighbor searches on high dimensional environments. It is ideal for use cases such as recommendation engines.
Annoy partitions vector spaces with a tree indexing structure to find its neighbors very quickly. Additionally, it optimizes its memory through a memory-mapped file system for large datasets. It also has a simple API for easy integration and other distance metrics.
However, it has some drawbacks, such as approximation tradeoffs, a single-threaded indexing process, and a lack of advanced database capabilities.
Qdrant: Open-Source Vector Database for Fast and Accurate Similarity Search
Qdrant is an open-source vector database used for fast similarity search and retrieval of high-dimensional data, especially in machine learning and AI.
Qdrant Architecture
The diagram below illustrates some of the core features of Qdrant.
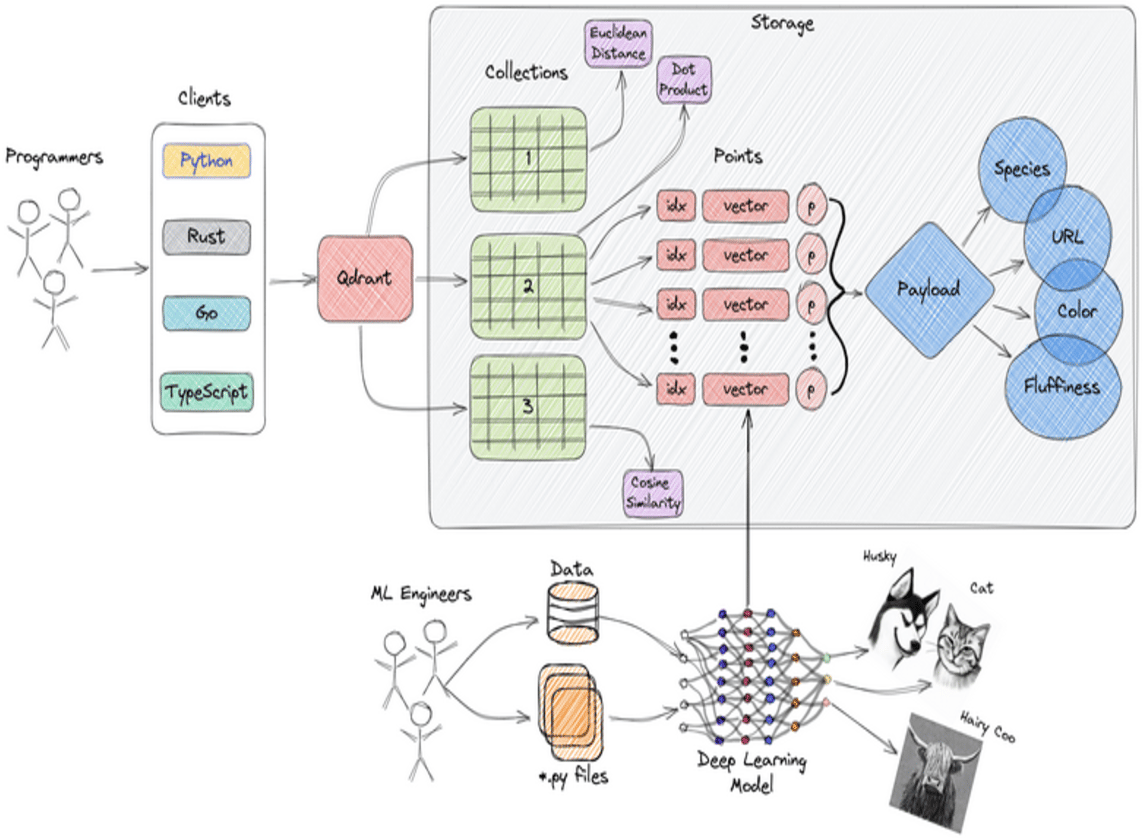
Below are the terms we need to understand:
Clients
Qdrant can be directly integrated with various programming languages and used by developers across multiple platforms. The client libraries for popular languages such as Python, Rust, Go, and TypeScript allow developers to access Qdrant and adapt it to their needs easily.
Input Data
Qdrant’s data generally originates from machine learning models. Machine learning engineers take raw data—text, images, video—and use deep learning algorithms to transform it into vector embeddings. These embeddings encode the underlying features of the data in a high-dimensional space.
Collections
Qdrant groups vector data into collections as bins for logically related data. Each collection holds multiple points, and each point consists of:
- A vector is a high-dimensional representation of the data.
- A payload containing metadata that provides additional context or characteristics about the data (e.g., species, URL, color, fluffiness).
Collections allow data to be organized in a way that is easy to manage and access.
Points and Payloads
Each point in a collection is assigned an idx (identifier) for reference. As a complement to the vector, a payload contains key-value metadata (categorical properties, URLs, or other descriptive information about the data).
Combining vector embeddings and metadata makes Qdrant ideal for use cases requiring similarity search and contextual filtering.
Similarity Search
Quadrant is designed explicitly for similarity searches, and it uses advanced distance metrics to evaluate how “close” a query vector is to stored vectors. Supported similarity measures include:
- Euclidean Distance, which is the straight-line distance between vectors.
- Cosine Similarity determines similarity using the angle between vectors.
- The Dot Product calculates the projection of a vector on another.
Such metrics are required for determining similar data points within text, images, or other large-scale datasets.
Strengths and limitations
Its strengths include accurate, fast nearest neighbor searches thanks to powerful indexing features such as HNSW (Hierarchical Navigable Small World) graphs. It also supports real-time updates and an intuitive API that can be integrated into current workflows. Further, Qdrant provides filtering and metadata management for complex queries.
However, some drawbacks include the complexity of implementation and optimization (especially for users who don’t have experience with vector databases) and the need for sufficient infrastructure for large-scale deployment.
Conclusion
Vector databases are taking the high-dimensional data space one step further by addressing the limitations of traditional databases in handling complex relationships. They enable the development of applications such as recommendation systems, semantic search, and AI-powered solutions.
From Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy, and Qdrant, to name a few, all databases have distinct benefits in terms of scale, real-time updates, or high-level indexing specific to different use cases.
However, those solutions have limitations—like cost, setup, or the trade-offs between speed and accuracy—that need to be considered before deployment. Finally, a vector database choice depends on application needs, infrastructure, and available resources. Consequently, it is important to carefully consider each one for the best integration and performance.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
