By Jayant Verma

Introduction
Loss functions in Python are an integral part of any machine learning model. These functions tell us how much the predicted output of the model differs from the actual output.
There are multiple ways of calculating this difference. In this tutorial, we are going to look at some of the more popular loss functions.
We are going to discuss the following four loss functions in this tutorial
- Mean Square Error
- Root Mean Square Error
- Mean Absolute Error
- Cross-Entropy Loss
Out of these 4 loss functions, the first three are applicable to regressions and the last one is applicable in the case of classification models.
Implementing Loss Functions in Python
Let’s look at how to implement these loss functions in Python.
1. Mean Square Error (MSE)
Mean square error (MSE) is calculated as the average of the square of the difference between predictions and actual observations. Mathematically we can represent it as follows :
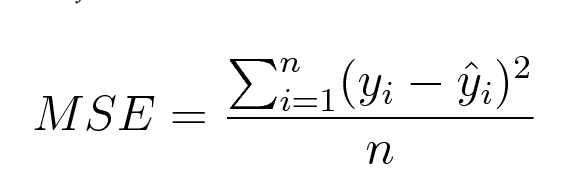
Python implementation for MSE is as follows
import numpy as np
def mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(mean_squared_error(act,pred))
Output :
0.04666666666666667
You can also use mean_squared_error from sklearn to calculate MSE. Here’s how the function works:
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred)
Output :
0.04666666666666667
2. Root Mean Square Error (RMSE)
Root Mean square error (RMSE) is calculated as the square root of Mean Square error. Mathematically we can represent it as follows :
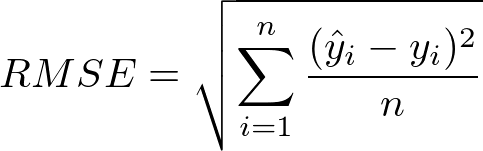
Python implementation for RMSE is as follows
import numpy as np
def root_mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
rmse_val = np.sqrt(mean_diff)
return rmse_val
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(root_mean_squared_error(act,pred))
Output :
0.21602468994692867
You can use mean_squared_error from sklearn to calculate RMSE as well. Let’s see how to implement the RMSE using the same function:
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred, squared = False)
Output :
0.21602468994692867
If the parameter ‘squared’ is set to True then the function returns MSE value. If set to False, the function returns RMSE value.
3. Mean Absolute Error (MAE)
Mean Absolute Error (MAE) is calculated as the average of the absolute difference between predictions and actual observations. Mathematically we can represent it as follows :
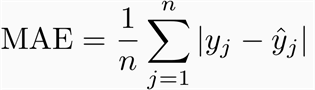
Python implementation for MAE is as follows
import numpy as np
def mean_absolute_error(act, pred):
diff = pred - act
abs_diff = np.absolute(diff)
mean_diff = abs_diff.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act,pred)
Output :
0.20000000000000004
You can also use mean_absolute_error from sklearn to calculate MAE.
from sklearn.metrics import mean_absolute_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act, pred)
Output :
0.20000000000000004
4. Cross-Entropy Loss Function in Python
Cross-Entropy Loss is also known as the Negative Log Likelihood. This is most commonly used for classification problems. A classification problem is one where you classify an example as belonging to one of more than two classes.
Let’s see how to calculate the error in case of a binary classification problem.
Let’s consider a classification problem where the model is trying to classify between a dog and a cat.
The python code for finding the error is given below
from sklearn.metrics import log_loss
log_loss(["Dog", "Cat", "Cat", "Dog"],[[.1, .9], [.9, .1], [.8, .2], [.35, .65]])
Output :
0.21616187468057912
We are using the log_loss method from sklearn.
The first argument in the function call is the list of correct class labels for each input. The second argument is a list of probabilities as predicted by the model.
The probabilities are in the following format :
[P(dog), P(cat)]
Conclusion
This tutorial was about Loss functions in Python. We covered different loss functions for both regression and classification problems. Hope you had fun learning wiht us!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
