By Adrien Payong and Shaoni Mukherjee

Introduction
Retrieval-Augmented Generation is the de facto method for providing grounding information to large language models. The standard RAG pipeline is based on embeddings (numeric vector representations of text) and a vector database for semantic search.
Documents are split into chunks, embedded as high-dimensional vectors, stored in a vector database, and queried via nearest-neighbor search to retrieve relevant context for the LLM. Models then search for information by semantic meaning.
However, the ‘vector DB + embeddings’ method is associated with significant overhead in cost, complexity, and performance. With these challenges in mind, there has been increasing interest in exploring alternatives to embedding-based RAG. Researchers have begun to develop RAG without embedding methods and systems, avoiding vector search. In this article, we define what embedding-free RAG means, explore the reasons for its current emergence, and compare it to traditional vector database approaches.
Key Takeaways:
- Traditional RAG systems rely on embeddings and vector databases. The documents are chunked, embedded into high-dimensional vectors, and indexed in a vector database for nearest-neighbor search to provide semantic context for LLMs.
- Vector search has limitations such as semantic gaps, reduced retrieval accuracy, and a lack of interpretability. There are also challenges in precision-sensitive domains where embeddings might retrieve topically similar but non-answer-bearing passages.
- Embedding-based RAG faces infrastructure complexity and high costs. Generating embeddings, maintaining a vector database, and re-indexing updated data demand significant compute and storage resources.
- RAG without embeddings can use alternatives to embedding and vector search. This includes keyword-based search (BM25), LLM-driven iterative retrieval (ELITE), knowledge-graph-based approaches (GraphRAG), and prompt-based retrieval (Prompt-RAG) to address semantic and operational limitations.
- Embedding-free RAG offers interpretability, lower latency, reduced storage, and domain adaptability. This makes it valuable in specialized domains (healthcare, law, finance) and use cases requiring transparency or reasoning across documents.
Traditional RAG and Vector Databases
In the traditional RAG architecture, the embeddings + vector search system constitutes the core of the “retrieval” process.
In the offline indexing phase, source documents are split into chunks, and each chunk is embedded (using an embedding model) to produce a vector representation of the index. Each of these vectors is then stored in a vector database optimized for fast nearest-neighbor search.
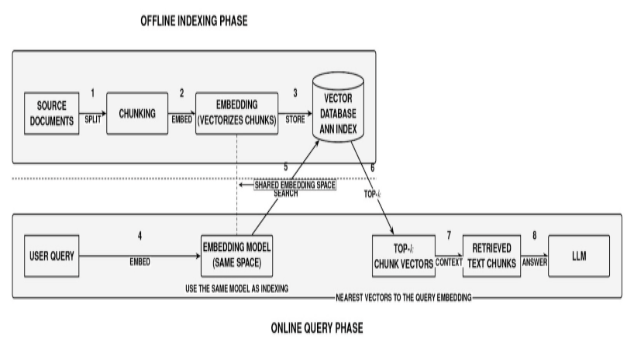
During the online query phase, an incoming query is embedded into the same vector space, and the system queries the vector store to fetch the top-k nearest chunk vectors. The retrieved text chunks (embeddings most “similar” to the query embedding) are then provided as context into the LLM along with the query to assist in generating an answer.
The key advantage of this pipeline is that vector embeddings capture semantic similarity. It can pair a question to passages using different wording but with similar meaning. Vector databases can serve high-dimensional similarity search, making retrieval latency manageable as the corpus scales to millions of chunks.
Limitations of Embeddings & Vector Search
Despite its popularity, the vector-based RAG approach has notable shortcomings. Let’s consider some of them:
Semantic Gaps
Semantic gaps with embeddings/vector search are common. This is because dense vector similarity may capture topical relatedness but not necessarily answer relevance. They can return semantically similar but unrelated passages as well, especially when the answer’s precision (exact numbers/dates/negation) matters. Embeddings can also struggle with domain-specific terms, rare entities, or multi-hop questions linking several documents.
Retrieval Accuracy
The above issue can lead to poor retrieval accuracy in real-world RAG deployments. When the embedding model fails to capture the relationship between a question and its answer, top vector hits may not contain the answer. Some reports indicate that RAG pipelines often struggle to retrieve the correct supporting text. One practitioner noted that even after optimizing the ‘Chunking + Embedding + Vector Store’ pipeline, the accuracy for retrieving the correct chunks is ‘usually below 60%.’ RAG systems may provide incorrect or incomplete answers due to irrelevant context.
Lack of Interpretability and Control
With vector embeddings, it becomes hard to know why you missed an answer or retrieved a wrong passage, because we can’t easily say what the vectors “thought.” The retrieval is a black-box process. Adjusting the retrieval behavior (for example, to emphasize certain keywords or data fields) is challenging when using a purely learned embedding.
Infrastructure Complexity and Cost
There are offline costs (the time and compute required to generate embeddings for thousands of documents - GPUs are often used for this) and online costs (running a vector DB service, which can be memory-intensive). It may be really expensive for teams without specialized infrastructure. There’s also the maintenance cost of the index itself (recomputing new embeddings when your data updates).
Traditional vector database RAG carried us a long way, empowering semantic search for LLMs. However, its limitations have also inspired researchers to look beyond vector databases for retrieval augmentation.
What Is RAG Without Embeddings?
RAG without embeddings refers to any RAG architecture that doesn’t use vector embeddings as the main approach for retrieving relevant context for generation. It omits the usual “embed query and documents, then do vector nearest-neighbor search” step.
How can we retrieve relevant information without embeddings? There are a few emerging approaches:
Lexical or Keyword-Based Retrieval
One of the most “embedding-free” implementations of RAG would be to fall back to lexical keyword search (or sparse retrieval).
Instead of comparing continuous vectors, the system searches for overlapping keywords/tokens shared between the query and documents (using algorithms like BM25). In fact, this “old school” sparse keyword method often exhibits competitive performance, performing on par with (fancy) vectors in many cases.
This classic keyword method is still competitive with other approaches. For example, one XetHub benchmark showed BM25 to be “not much worse” than state-of-the-art OpenAI embeddings. According to that researcher, achieving an 85% recall of relevant documents might require 7 results returned from an embedding and vector search, compared to 8 results from the classical keyword approach. This small difference in accuracy “is insignificant, considering the cost of maintaining a vector database as well as an embedding service.”
In other words, a well-tuned keyword search might be able to get you part of the way there, without all the overhead of running a vector DB.
You can implement this by generating an optimized search query from the user prompt (possibly with the help of an LLM to extract important terms) and performing a query against a full-text engine (Elasticsearch or an SQL full-text index, etc.).
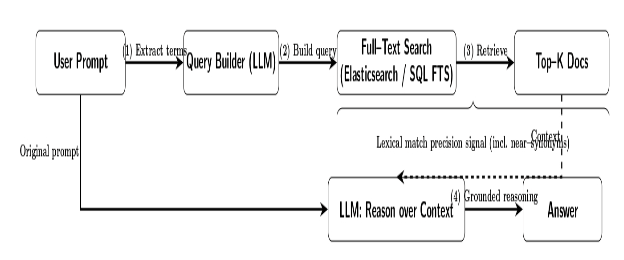
The LLM can then operate on those retrieved texts as context. This can use the strong precision signal of lexical matches (high confidence that the retrieved docs contain the query terms or near-synonyms), which can sometimes be more relevant than a dense embedding’s retrieval.
LLM-based Iterative Search (Reasoning as Retrieval)
Another approach to embedding-free RAG is to leverage the LLM itself to do retrieval via reasoning and inference. Rather than ranking vector similarity scores, this type of system instead “asks the LLM” to figure out where the answer is located. For example, an LLM agent could be provided with a list of document titles or summaries, and asked to reason about which document is most likely to contain the answer (and then fetch it).
That’s the concept behind Agent-based RAG – an LLM agent “uses” tools to search a document catalog by title/metadata before detailed analysis.
Similarly, there is a research framework, ELITE (Embedding-Less Retrieval with Iterative Text Exploration), that provides the LLM the capability to iteratively narrow down on relevant text. It uses a custom importance measure to guide the search.
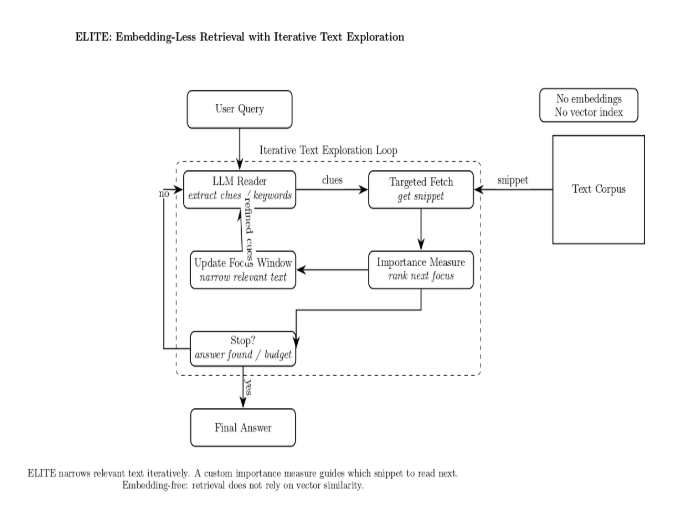
The above diagram represents an embedding-free RAG loop. The user query is sent to an LLM, which produces clues for retrieving a snippet from the corpus. That snippet is then scored by an importance measure to decide which window to focus on next. That new, more targeted focus is then fed back to the LLM in a loop that iterates until the stop check condition is met, and the system returns the final answer.
This approach “asks” the model to perform the retrieval via its native language understanding and logical reasoning. It does not “delegate” retrieval to an embedding index.
Structured Knowledge and Graph-Based Retrieval
Instead of adding the knowledge base as unstructured chunks of text to a vector index, this approach structures the data in a knowledge graph or other symbolic data structure.
In a graph-based RAG, entities (such as people, places, or concepts) are represented as nodes and relationships are represented as edges, extracted from the source text or database. In response to the user’s query, the system retrieves relevant nodes and follows edges to gather a set of facts or related pieces of information, which is then passed to the LLM.
Microsoft recently released GraphRAG, which “keeps the good bits of RAG but slips a knowledge graph between the indexer and the retriever”.
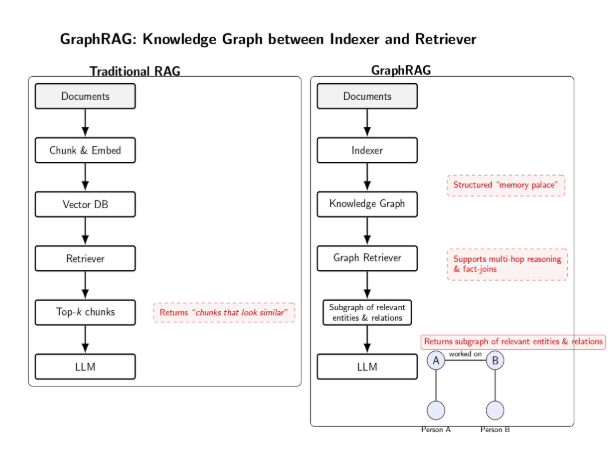
In GraphRAG, instead of simply returning “chunks that look similar” to the query, the system returns a subgraph of relevant entities and relationships. It provides the LLM with a structured memory palace of how facts connect.
This is especially valuable for complex queries that require multi-hop reasoning or fact joins (e.g., recognizing that Person A who did X is related to Person B mentioned elsewhere).
Some implementations of GraphRAG still involve embeddings at certain points in the pipeline (e.g., embedding the text of each node’s context for similarity search within the neighborhood). However, the point is that a graph imposes a symbolic relational structure that is lacking in pure vector search.
Prompt-Based Retrieval (Embedding-Free Prompt RAG)
Another recent thread of research has explored whether we can use the LLM’s prompting ability to perform text retrieval without explicit vectors. One such approach is Prompt-RAG, proposed in a 2024 paper in the specific domain of Korean medicine.
Instead of vector indexes, Prompt-RAG constructs a structured Table-of-Contents(ToC) from the documents. It then prompts the LLM to choose the sections (headings) that are relevant to the query.
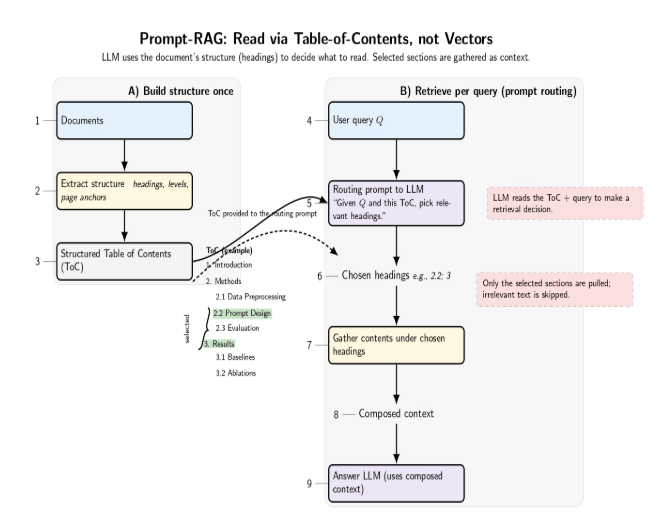
The contents under those headings are then combined as context. The LLM is directly used to parse the query and the document structure and perform a retrieval decision. There are no embedding vectors required. It was shown to outperform a traditional embedding-based RAG in that particular domain. This suggests that prompt-guided retrieval can be a good alternative when embeddings don’t capture the domain’s semantics. RAG without embeddings replaces the vector search step with either classic information retrieval techniques or LLM-powered logic. It’s a sort of inversion of the trend from the past few years. We are going “back” to using symbols and text for retrieval, but with the enhanced reasoning abilities of large LLMs.
Benefits of Embedding-Free RAG
Why even consider these alternatives? There are some real potential benefits of RAG without embeddings. Remember our review of limitations earlier. Many of these can be tackled with these alternate approaches:
| Benefit | What it means |
|---|---|
| Improved Retrieval Precision | Because they don’t depend only on vector similarity, embedding-free methods can also surface information that would be missed by vectors. This can be done with exact keyword matching or LLM reasoning to help find an answer that is phrased differently from the query. |
| Lower Latency & Indexing Overhead | Eliminates the need to compute/store large embedding indexes and to perform high-dimensional similarity searches, enabling learner retrieval. |
| Reduced Storage & Cost | Eliminates or minimizes vector stores, reducing memory footprint and ongoing infrastructure costs; can move to pay-per-use models. |
| Better Interpretability & Adaptability | keyword matches, knowledge-graph traversals, or agent choices are more interpretable and fine-tunable than opaque vector similarities. |
| Domain Specialization | Can outperform embeddings in low-data regimes or specialized domains by utilizing structure (TOCs, ontologies, knowledge graphs) and domain cues. |
It is worth noting that these benefits don’t come “for free”. The alternative approaches often trade one set of challenges (such as the compute cost of multiple LLM calls, or the engineering complexity of a knowledge graph). However, shedding the vector DB dependency can eliminate many pain points of current RAG systems.
Use Cases and Comparisons
When can we consider using an embedding-free RAG architecture over the classic vector database approach? It depends on your task, data, your constraints, and many other factors. Here are some use cases and how each approach compares:
| Scenario | Vector-Only RAG Challenge | Why Embedding-Free / Graph / Agent Helps | Recommended Strategy |
|---|---|---|---|
| Complex, multi-hop questions (e.g., “What connects X and Y?”) | Retrieves chunks about X and Y separately, but doesn’t know they must be linked; the generation step may hallucinate the connection. | Graphs can surface the explicit path (X → … → Y). Reasoning-centric retrieval gives the LLM a factual chain to follow. | GraphRAG (entity/relationship traversal) or an agentic retriever that plans multi-hop lookups. |
| Strict factual / compliance needs (law, finance, healthcare) | Semantic near-misses are unacceptable; authoritative clause/case might be missed if phrasing differs. | Keyword/lexical signals and legal/clinical graphs allow exact hits and auditable trails; easy to show why a snippet was retrieved. | Keyword/BM25 filters → optional LLM re-rank; or domain graph (citations, statutes). Hybrid before vectors if used at all. |
| Specialized domains / low-data (biomed, legal, niche technical docs) | Generic embeddings struggle with jargon/notation; they can misrank or miss key passages. | Leverages document structure (headings/TOCs), ontologies, and domain graphs; prompt-guided section selection can outperform vectors. | Prompt-guided retrieval (TOC/heading aware), ontology/graph queries, or lexical → LLM re-rank. |
| Low query volume, huge corpus (archives, research vaults) | Maintaining a large vector index is costly when queries are rare; re-embedding on updates adds operational overhead. | On-demand, agentic retrieval avoids idle infra; cost is incurred only when a query arrives. | Agent-based retrieval over catalogs/metadata + targeted reading; optional small lexical index instead of a vector DB. |
Tip: Many teams are going hybrid—perform quick lexical filters, then vector search, then LLM re-rank; for complex/multi-hop or regulated queries, fall back to graph/agent retrieval
Future of RAG Architectures
Will these embedding-free methods outpace or replace vector databases in RAG? The more likely scenario, we think, is coexistence and complementarity. Here are some trends and predictions for what the future may bring:
| Trend | Key Insights | Where It Shines vs Where Vectors Shine |
|---|---|---|
| Hybrid & Adaptive Pipelines | Future systems won’t pick just one method. They’ll mix and match: Fast vector search first for common queries. Fallback to graph/agent retrieval if reasoning is required. Projects like Microsoft’s AutoGen orchestrate multiple retrievers. | Embedding-free is ideal when reasoning or multi-hop queries are needed. Vectors shine for quick semantic similarity at scale. |
| Knowledge Graph RAG | GraphRAG and Neo4j-led work show promise: Convert unstructured text into graphs. Graphs may feed into embeddings, or stand alone. Hybrid graph + vector stores are emerging. | Embedding-free excels in structured, relational domains (biomed, intelligence, finance). Vectors are suitable for broad coverage when no explicit structure exists. |
| Larger Context Windows | Bigger context models (100k+ tokens) reshape retrieval: Can load whole documents without chunking. Iterative reading strategies (like ELITE) become more powerful. Speculation: LLMs may perform in-context retrieval internally. | Embedding-free performs well when models can directly “read and reason” inside long contexts. Vectors still shine for cutting down context cost and narrowing focus efficiently. |
| Evaluations & Benchmarks | More side-by-side benchmarks are emerging: ELITE, Prompt-RAG, RAPTOR show efficiency gains. Evaluation tasks: long-doc QA, multi-hop, domain-specific QA. Explainability (graph paths, citations) may boost user trust. | Embedding-free is effective when interpretability and efficiency are valued. Vectors are best when benchmarks demand speed and coverage across huge corpora. |
Vector DBs are strong for massive-scale semantic similarity. Embedding-free is better at reasoning, structure, and interpretability. The future lies in hybrid, adaptive systems that use each where appropriate.
FAQ SECTION
Why does traditional RAG rely on embeddings and vector databases?
Traditional RAG works by first embedding the text chunks into a vector space and then storing these embeddings in a vector database. When answering a query, the model embeds the user query into the same vector space and performs a nearest-neighbor search. It then uses the embeddings from the retrieved passages as context for answering the query. RAG can thus retrieve passages whose meaning aligns with the query, even if the exact wording differs.
What are the main limitations of embeddings and vector search in RAG?
While extremely useful, embeddings and vector search still have several limitations. They suffer from semantic gaps. Of the retrieved passages, it is possible to have only a fraction of these that are answer-bearing, while many are topically similar. This degrades retrieval accuracy, especially in precision-sensitive domains (law, healthcare, etc.). Vector search is also a black box from which it is difficult to infer why a passage was retrieved. The storage and maintenance of embeddings and vector databases add significant infrastructure cost and complexity (e.g., need to re-index on every change to any document).
How does RAG without embeddings work, and what benefits does it offer?
The RAG without embedding approaches use some method other than vector search for retrieval. This includes keyword-based retrieval, iterative LLM-guided search, and graph-based or prompt-based retrieval. They can improve retrieval precision, reduce indexing overhead. They can also reduce compute costs and enhance interpretability. RAG without embeddings is especially promising in specialized or low-data domains (healthcare, finance, legal) where embeddings often fail to capture domain-specific semantics.
Conclusion
Embedding-free RAG is emerging as a significant alternative to classic vector database methods. In many cases, embeddings and vector search are the optimal choice for massive-scale semantic retrieval. However, they bring complexity, cost, and accuracy challenges.
On the other hand, keyword search, knowledge graphs, and LLM-based reasoning and interpretation are popular embedding-free RAG techniques. They are simpler, faster, and more interpretable.
Vector databases perform fast semantic similarity search but struggle with reasoning-heavy and domain-specific problems, where embedding-free RAG performs better. Hybrid systems can combine the strengths of both approaches to create adaptive pipelines that provide higher accuracy, lower latency, and greater trust.
Many of the concepts we’ve described (such as ELITE’s iterative retrieval or GraphRAG) provide open-source implementations or are available as a service. It is possible to run these systems on your own data to evaluate how they compare to a vector search baseline.
You must ensure that you have computing resources available. For example, to run 70B parameter models for reasoning-heavy retrieval, you’ll need large-memory GPU instances. Fortunately, services like DigitalOcean’s Gradient™ AI GPU Droplets allow you to quickly spin up GPU-based Droplets to provide such compute environments.
References and Resources
- ELITE: Embedding-Less retrieval with Iterative Text Exploration
- Agent-based RAG (A-RAG) without Vector Store
- GraphRag: When your Rag needs a Memory Palace
- MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation
- Prompt-RAG: Pioneering Vector Embedding-Free Retrieval-Augmented Generation in Niche Domains, Exemplified by Korean Medicine
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
