 in Python")
K-nearest neighbors (kNN) is a supervised machine learning technique that may be used to handle both classification and regression tasks. I regard KNN as an algorithm that originates from actual life. People tend to be impacted by the people around them.
The Idea Behind K-Nearest Neighbours Algorithm
Our behavior is shaped by the companions we grew up with. Our parents also shape our personalities in various ways. If you grow up among folks who enjoy sports, it is highly likely that you will end up loving sports. There are of course exceptions. KNN works similarly.
- If you have a close buddy and spend most of your time with him/her, you will end up having similar interests and loving same things. That is kNN with k=1.
- If you constantly hang out with a group of 5, each one in the group has an impact on your behavior and you will end up becoming the average of 5. That is kNN with k=5.
kNN classifier identifies the class of a data point using the majority voting principle. If k is set to 5, the classes of 5 nearest points are examined. Prediction is done according to the predominant class. Similarly, kNN regression takes the mean value of 5 nearest locations.
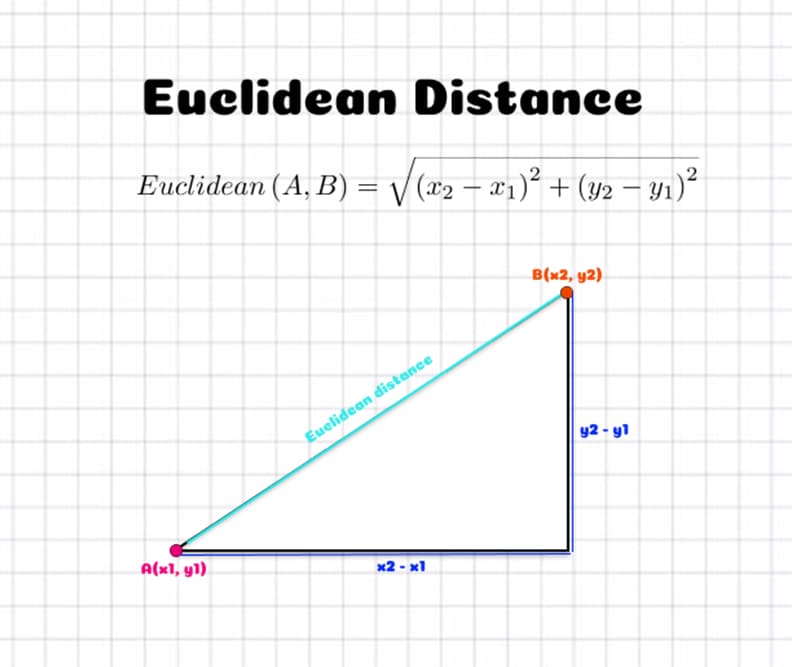
Do we witness folks who are close but how data points are considered to be close? The distance between data points is measured. There are various techniques to estimate the distance. Euclidean distance (Minkowski distance with p=2) is one of the most regularly used distance measurements. The graphic below explains how to compute the euclidean distance between two points in a 2-dimensional space. It is determined using the square of the difference between x and y coordinates of the locations.
Implementation of KNN Algorithm in Python
Let’s now get into the implementation of KNN in Python. We’ll go over the steps to help you break the code down and make better sense of it.
1. Importing the modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
2. Creating Dataset
Scikit-learn has a lot of tools for creating synthetic datasets, which are great for testing machine learning algorithms. I’m going to utilize the make blobs method.
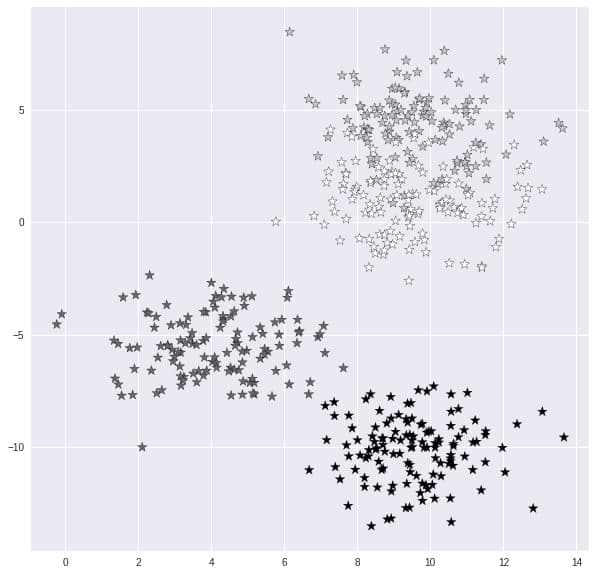
X, y = make_blobs(n_samples = 500, n_features = 2, centers = 4,cluster_std = 1.5, random_state = 4)
This code generates a dataset of 500 samples separated into four classes with a total of two characteristics. Using associated parameters, you may quickly change the number of samples, characteristics, and classes. We may also change the distribution of each cluster (or class).
3. Visualize the Dataset
plt.style.use('seaborn')
plt.figure(figsize = (10,10))
plt.scatter(X[:,0], X[:,1], c=y, marker= '*',s=100,edgecolors='black')
plt.show()
4. Splitting Data into Training and Testing Datasets
It is critical to partition a dataset into train and test sets for every supervised machine learning method. We first train the model and then put it to the test on various portions of the dataset. If we don’t separate the data, we’re simply testing the model with data it already knows. Using the train_test_split method, we can simply separate the tests.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
With the train size and test size options, we may determine how much of the original data is utilized for train and test sets, respectively. The default separation is 75% for the train set and 25% for the test set.
5. KNN Classifier Implementation
After that, we’ll build a kNN classifier object. I develop two classifiers with k values of 1 and 5 to demonstrate the relevance of the k value. The models are then trained using a train set. The k value is chosen using the n_neighbors argument. It does not need to be explicitly specified because the default value is 5.
knn5 = KNeighborsClassifier(n_neighbors = 5)
knn1 = KNeighborsClassifier(n_neighbors=1)
6. Predictions for the KNN Classifiers
Then, in the test set, we forecast the target values and compare them to the actual values.
knn5.fit(X_train, y_train)
knn1.fit(X_train, y_train)
y_pred_5 = knn5.predict(X_test)
y_pred_1 = knn1.predict(X_test)
7. Predict Accuracy for both k values
from sklearn.metrics import accuracy_score
print("Accuracy with k=5", accuracy_score(y_test, y_pred_5)*100)
print("Accuracy with k=1", accuracy_score(y_test, y_pred_1)*100)
The accuracy for the values of k comes out as follows:
Accuracy with k=5 93.60000000000001
Accuracy with k=1 90.4
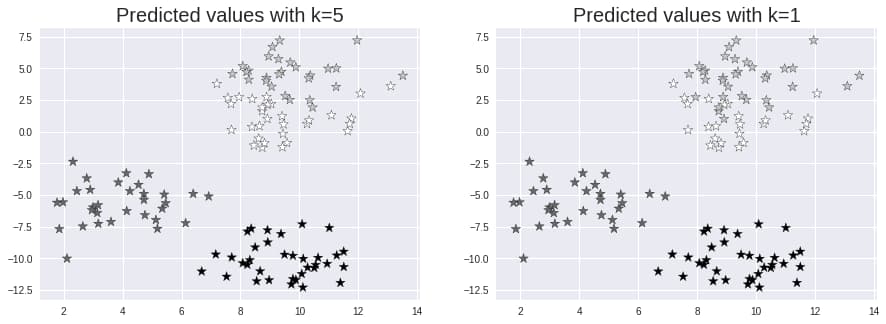
8. Visualize Predictions
Let’s view the test set and predicted values with k=5 and k=1 to see the influence of k values.
plt.figure(figsize = (15,5))
plt.subplot(1,2,1)
plt.scatter(X_test[:,0], X_test[:,1], c=y_pred_5, marker= '*', s=100,edgecolors='black')
plt.title("Predicted values with k=5", fontsize=20)
plt.subplot(1,2,2)
plt.scatter(X_test[:,0], X_test[:,1], c=y_pred_1, marker= '*', s=100,edgecolors='black')
plt.title("Predicted values with k=1", fontsize=20)
plt.show()
How to find the best k value to implement KNN
- k=1: The model is too narrow and not properly generalized. It also has a high sensitivity to noise. The model predicts new, previously unknown data points with a high degree of accuracy on a train set, but it is a poor predictor on fresh, previously unseen data points. As a result, we’re likely to have an overfit model.
- k=100: The model is overly broad and unreliable on both the train and test sets. Underfitting is the term for this circumstance.
Limitations of KNN Algorithm
KNN is a straightforward algorithm to grasp. It does not rely on any internal machine learning model to generate predictions. KNN is a classification method that simply needs to know how many categories there are to work (one or more). This means it can quickly assess whether or not a new category should be added without having to know how many others there are.
The drawback of this simplicity is that it can’t anticipate unusual things (like new diseases), which KNN can’t accomplish since it doesn’t know what the prevalence of a rare item would be in a healthy population.
Although KNN achieves high accuracy on the testing set, it is slower and more expensive in terms of time and memory. It needs a considerable amount of memory in order to store the whole training dataset for prediction. Furthermore, because Euclidean distance is very sensitive to magnitudes, characteristics in the dataset with large magnitudes will always outweigh those with small magnitudes.
Finally, considering all we’ve discussed so far, we should keep in mind that KNN isn’t ideal for large-dimensional datasets.
Conclusion
Hopefully, you now have a better understanding of the KNN algorithm. We’ve looked at a variety of ideas for how KNN saves the complete dataset in order to generate predictions.
KNN is one of several lazy learning algorithms that don’t use a learning model to make predictions. By averaging the similarity between an incoming observation and the data already available, KNN creates predictions on the fly (just in time).
Thank you for reading!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
