By Alligator

How about an easy way to programmatically navigate to different pages, take screenshots, scrape website content, produce PDFs and run tests? It’s now quite easy to do using a new library by the Chrome team, Puppeteer, a Node.js library that abstracts the Chrome DevTools protocol.
Getting Started
The fastest way to get started is to use Try Puppeteer, a tool that allows to play with Puppeteer right in your browser.
If you want to explore Puppeteer for anything more serious than just playing around, you’ll want to actually add the library to your Node project using Yarn or npm:
$ yarn add puppeteer
# or, using npm:
$ npm install puppeteer
Then, all you have to do is require puppeteer and you’ll be ready to get down to business:
'use strict';
Usage
Evaluating Elements
Here’s a simple Hello World example using Puppeteer to go to the Wikipedia article about Hello World, extract the first paragraph of the article and output the result to the console:
'use strict';
const puppeteer = require('puppeteer');
async function helloWorld() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://en.wikipedia.org/wiki/%22Hello,_World!%22_program');
const firstPar = await page.$eval('#mw-content-text p', el => el.innerText);
console.log(firstPar); // A "Hello, World!" program is a computer program that outputs ...
await browser.close();
}
helloWorld();
Given that Puppeteer exposes a promise-based API, it’s easy to use async functions to define series of steps to follow.
In the above we used $eval on the page instance to get the first element that matches our selector and then extract its inner text. Pages also have the $$eval method to select all the elements that match the selector.
There’s also the $ and $$ methods, which are analogous, but return an elementHandle instead. Element handles can be clicked or tapped.
Taking Screenshots
Using Puppeteer to take a screenshot of a page or an element is just as easy. Here’s a simple example that takes a screenshot of Alligator.io’s home page and saves it to disk:
async function takeScreenshot() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://alligator.io/');
await page.screenshot({ path: 'hello-alligator.png' });
await browser.close();
}
takeScreenshot();
🎩 Pretty magical if you ask me! Now say that you’re not happy with that screenshot. You want a lower quality Jpeg image instead and you want to also control the exact sizing of the viewport. That’s easily done with just a few more options:
async function takeScreenshot() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://alligator.io/');
await page.setViewport({
width: 1440,
height: 900
});
await page.screenshot({
path: 'hello-alligator.jpg',
type: 'jpeg',
quality: 20
});
await browser.close();
}
takeScreenshot();
Generating PDFs is also just as easy:
async function pdf() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://alligator.io/');
await page.pdf({
path: 'hello-alligator.pdf'
});
await browser.close();
}
pdf();
Interacting With the Page
Given that we’re effectively controlling a real Chrome browser instance under the hood, we can also interact with a page by, for example, filling form fields and clicking on elements.
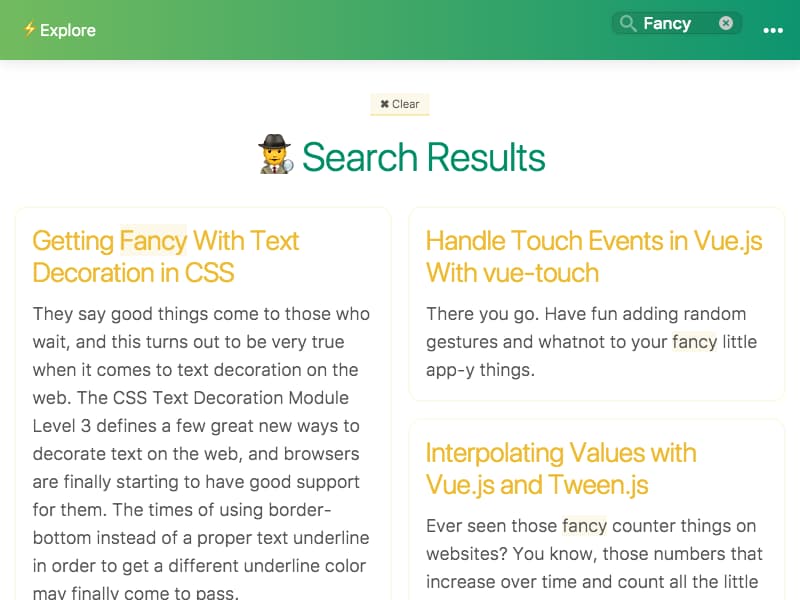
Here’s an example that performs the following steps:
- Go the Alligator.io’s homepage
- Place the focus into the search input
- Wait for 1 second
- Type-in the word Fancy width a delay of 150ms between keystrokes
- Wait for the page to have an element with a class of algolia__results
- Take a screenshot
'use strict';
const puppeteer = require('puppeteer');
async function performSearch() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://alligator.io/');
await page.focus('.algolia__input');
await page.waitFor(1000);
await page.type('.algolia__input', 'Fancy', { delay: 150 });
await page.waitForSelector('.algolia__results');
await page.screenshot({ path: 'search.png' });
await browser.close();
}
performSearch();
Here’s the resulting screenshot…
🤖 This post barely scratched the surface with what’s possible with headless Chrome and Puppeteer. Refer to the extensive API docs to dig deeper.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Alligator.io is a developer-focused resource that offers tutorials and insights on a wide range of modern front-end technologies, including Angular 2+, Vue.js, React, TypeScript, Ionic, and JavaScript.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
I am trying to scrape massart.edu, it’s not working. Do you have any advice.
const scraperObject = {
//url: 'http://books.toscrape.com',
url: 'https://massart.edu/news-category/massart-news',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url, {waitUntil: 'domcontentloaded'});
// Wait for the required DOM to be rendered
//await page.waitForSelector('.l_main'); //need to figure .page_inner
await page.waitForSelector('.layout-region.content-main');
// Get the link to all the required books
//let urls = await page.$$eval('section ol > li', links => {
//let urls = await page.$$eval('section main > article >div', links => {
let urls = await page.$$eval('article div > h2', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.field__items > i'))
// Extract the links from the data
links = links.map(el => el.querySelector('h2 > a'))
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
How can this be used in a Digital Ocean App. I tried creating and express app, where for one route, I’m using puppeteer to take screenshots. It is working in local, but when it is moved to the DigitalOcean, it does not work.
Are there any additional steps needed to make Puppeteer work in a Digital Ocean App?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
