When you build AI applications, the knowledge your system needs rarely lives just inside the model itself. It’s also scattered across PDFs, research papers, internal documentation, and databases. If your application cannot reliably organize and retrieve that information, even powerful language models may produce incomplete answers or make confident guesses that are not grounded in your data.
To solve this, many AI systems use retrieval-augmented architectures that connect language models to external knowledge sources. Instead of relying only on what the model learned during training, the system retrieves relevant information from your data at query time. LlamaIndex (originally called “GPT Index”) was founded in 2023 by former Uber AI researchers Jerry Liu and Simon Suo. The framework helps you build the retrieval layer by transforming messy documents into a structured knowledge base. With the right retrieval layer in place, your AI application can perform beyond generic responses and start answering questions from your company’s data.
Key takeaways:
-
LlamaIndex is an open-source retrieval framework that connects LLMs to external data sources by structuring documents, creating searchable indices, and retrieving relevant context before generation.
-
LlamaIndex improves AI application accuracy by grounding responses in real data through context augmentation, flexible indexing strategies, and integrations with orchestration tools like LangChain.
-
LlamaIndex use cases include enterprise knowledge assistants, customer support automation, financial document analysis, legal and compliance search, and research tools that query large document collections.
-
DigitalOcean Gradient™ AI Platform simplifies building LlamaIndex applications by providing managed knowledge bases, embeddings, and hosted LLMs for developers to build production-ready RAG systems without managing complex infrastructure.
What is LlamaIndex?
LlamaIndex is an open-source data framework that connects large language models (LLMs) to external data sources. It uses retrieval-augmented generation (RAG) by structuring, indexing, and retrieving relevant context before sending it to an LLM for response generation. LlamaIndex performs context augmentation, where retrieved information is injected into the model prompt so responses are grounded in real data. It helps you build retrieval pipelines that make LLM outputs more context-aware, bridging the gap between your data and the language model.
LlamaCloud is a hosted, paid platform from LlamaIndex that simplifies document processing and data preparation for LLM applications. Tools like LlamaParse automatically parse complex documents such as PDFs containing tables, charts, images, and handwritten content and convert them into structured data ready for indexing and retrieval.
Build LlamaIndex-powered RAG applications faster with DigitalOcean: DigitalOcean Gradient™ AI platform integrates natively with LlamaIndex. With open-source packages, you can add retrieval and generation capabilities to your application in minutes.
LlamaIndex vs LangChain
LlamaIndex and LangChain are compared because both are used in LLM application development. The confusion arises from the fact that both frameworks interact with external data, prompts, and models, which makes their responsibilities appear similar at first glance. But, they focus on different layers of the AI stack: LlamaIndex specializes in data indexing and retrieval, while LangChain focuses on orchestration, agents, and multi-step workflows. For example, you might use LlamaIndex to parse, index, and retrieve data from documents, and LangChain to orchestrate an agent or workflow that uses that retrieved context with tools, prompts, and model calls.
| Factor | LlamaIndex | LangChain |
|---|---|---|
| Process | Data indexing and retrieval for RAG systems. The main focus is on structuring and retrieving private or external data | Workflow orchestration and agent frameworks. The main focus is on tool usage, agents, and multi-step reasoning chains |
| Architecture style | Data-centric architecture focused on organizing and retrieving context. It works on the retrieval layer in an LLM application stack | Workflow-centric architecture focused on chaining tasks and tools. It works on the orchestration layer, managing workflows and agents |
| Learning curve | Easier for developers building RAG pipelines | Steeper when designing complex chains or agents |
| Use cases | Document querying, enterprise knowledge assistants, internal search systems | Agent-driven applications, automation workflows, and AI assistants |
Confused about the difference between LlamaIndex and LangChain? Choosing the right tool depends on whether your application’s core challenge is retrieving the right data or coordinating complex AI workflows.
Benefits of using LlamaIndex
LlamaIndex is designed specifically as a retrieval framework and indexing framework for grounding LLM applications in external data. Instead of relying only on what a model learned during training, it retrieves relevant information from your data and uses it to generate accurate answers.
-
Retrieval built into the architecture: Unlike tools that treat retrieval as an add-on, LlamaIndex is designed from the ground up as a retrieval framework. The system focuses on finding the right context from your data before the model generates a response. This helps produce answers that remain grounded in real documents rather than relying solely on model memory.
-
Flexible indexing strategies for different data needs: LlamaIndex supports multiple LlamaIndex index formats for developers to structure data in ways that best match how it will be queried. For example, vector indexes work well for semantic search, while tree or list structures can support hierarchical summaries or structured document navigation.
-
Smarter context injection for more accurate responses: Instead of sending entire documents to a model, LlamaIndex selects only the most relevant pieces of information and inserts them into the prompt. The context augmentation approach improves answer quality and keeps prompts smaller and more efficient.
-
Connects data from many sources: Files, APIs, SaaS tools, and databases can all be ingested and organized into a unified indexing framework. This makes it easier for developers to build practical use cases, like internal knowledge assistants or document search systems.
-
Support orchestration tools: LlamaIndex focuses on data retrieval and integrates with orchestration frameworks like LangChain or Semantic Kernel to manage workflows, agents, and tool calls. LlamaIndex exposes retrievers, query engines, and data connectors as modular components that orchestration frameworks can call during a workflow. You can build an agent in LangChain that can invoke a LlamaIndex retriever to fetch relevant documents before generating a response.
Challenges of using LlamaIndex
LlamaIndex is a great retrieval framework, but building reliable RAG systems requires thoughtful engineering. Performance, accuracy, and scalability depend heavily on design decisions for embeddings, indexing strategy, and infrastructure.
-
Retrieval quality depends on embeddings and chunking strategy: The effectiveness of LlamaIndex is closely tied to how documents are split and embedded. If chunks are too large, relevant signals get diluted; if too small, context becomes fragmented. Selecting the right embedding model and tuning similarity thresholds requires lots of experimentation, which might increase development time.
-
Infrastructure complexity at scale: Small prototypes can run locally, but production deployments of LlamaIndex require a vector database, caching layers, and monitoring for latency and cost control. As query volume grows, decisions around storage, concurrency, and response time directly impact user experience and infrastructure spend.
-
Data volume and indexing overhead: Indexing large datasets becomes computationally expensive as the amount of data grows. If a company indexes one million customer support tickets, each ticket must be chunked and converted into embeddings before retrieval works. Creating and storing these vectors takes hours of processing and requires large vector storage, which makes indexing pipelines a bottleneck in the RAG workflow.
-
Re-indexing and data freshness management: Enterprise data changes frequently, and outdated embeddings can lead to stale or misleading responses. Maintaining automated re-indexing pipelines, detecting data changes, and avoiding downtime during index updates adds operational complexity to LLM applications.
-
Security considerations: Retrieval pipelines must respect document-level and user-level permissions when connecting to internal data sources. Without proper filtering and authorization checks, sensitive information might surface unintentionally during query-time context augmentation.
LlamaIndex architecture
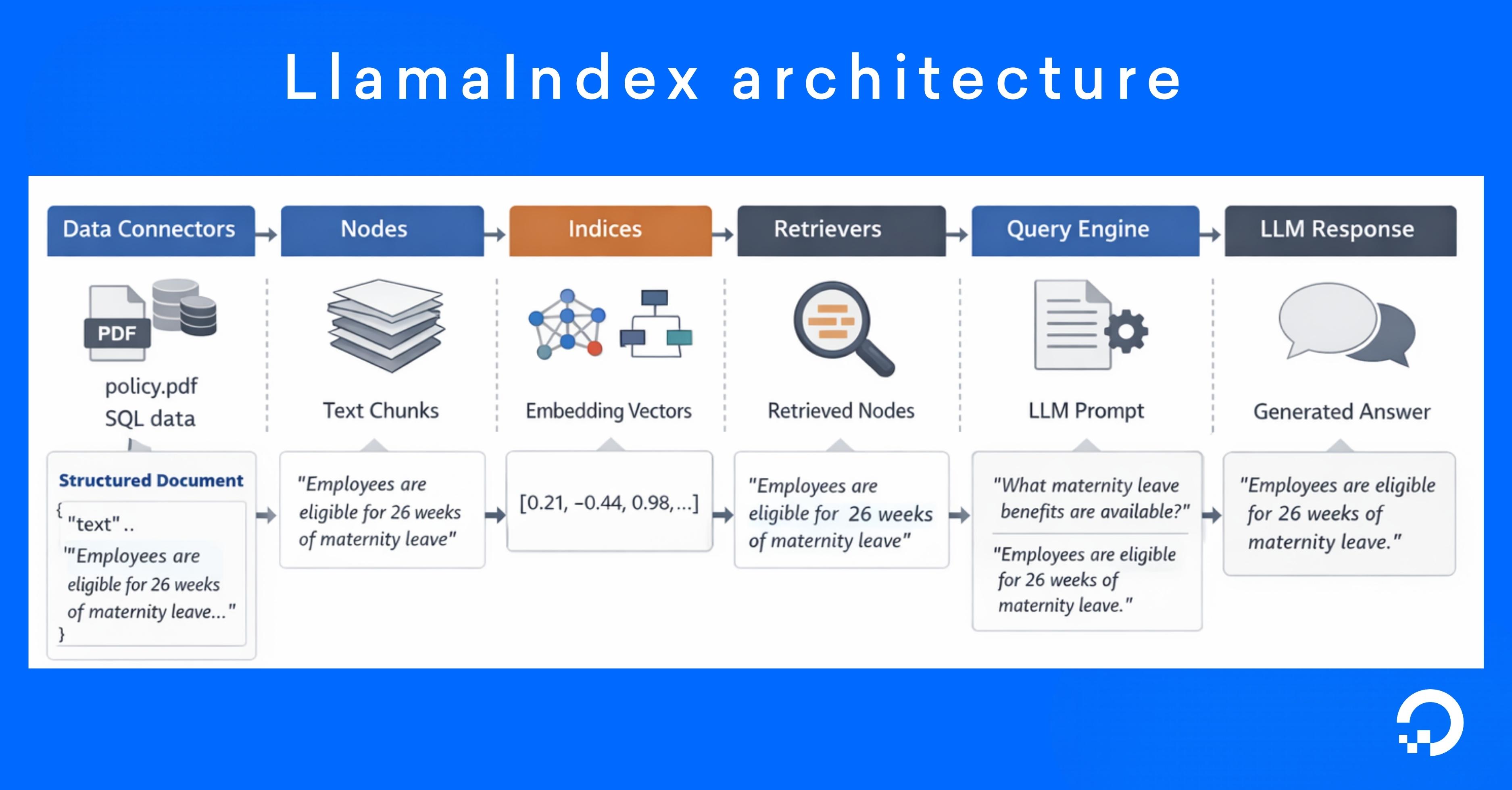
LlamaIndex architecture separates the pipeline into distinct layers: from ingestion to query processing, so developers can control how data is prepared, indexed, retrieved, and used by the model.
-
Data connectors: Raw data is ingested from different sources (PDFs, Word documents, Markdown files, SQL databases, and cloud storage systems) and converted into formats that can be processed by the indexing pipeline. During ingestion, connectors perform preprocessing tasks such as text extraction, metadata tagging, and format normalization.
-
Nodes: LlamaIndex divides the ingested data into smaller, structured units called nodes (chunking). Nodes are the fundamental pieces of information that the system retrieves during a query.
-
Indices: Nodes are organized into searchable data structures to efficiently retrieve relevant information. Instead of scanning every node during a query, the index provides optimized lookup mechanisms. LlamaIndex also supports index formats designed for different retrieval strategies: Vector indices for semantic similarity search, tree indices for hierarchical document summarization, and keyword indices for keyword-based retrieval.
-
Retrievers: It’s determined which nodes from the index should be returned in response to a query. When a user submits a question, the retriever converts the query into an embedding and searches the index for the most relevant nodes. Retrieval strategies may include semantic similarity search, metadata filtering, or hybrid retrieval methods that combine vector search with keyword matching.
-
Query engines: The interaction between the retriever and the language model is orchestrated. When a query is received, the query engine integrates with the RAG workflows in which the LLM produces answers grounded in external knowledge. The query engine might also support advanced capabilities like response synthesis across multiple nodes, reranking retrieved results, or iterative query refinement.
To understand how LlamaIndex processes data, let’s take an example of a product review analysis workflow. When a user asks a question, “How long does the laptop battery last?”, the system retrieves the most relevant review fragments and uses them as context for the language model to generate a grounded answer.
| Component | Example input | Example output |
|---|---|---|
| Data connectors | Product reviews stored in a CSV file or database record: “Customer review: The battery life of this laptop lasts more than 10 hours.” | Structured document object: json<br>{<br> "text": "The battery life of this laptop lasts more than 10 hours.",<br> "metadata": { "source": "reviews.csv", "product": "Laptop X1" }<br>}<br> |
| Nodes (chunking) | Document text: “The battery life of this laptop lasts more than 10 hours, and it charges quickly.” | Chunked nodes: json<br>[<br> {<br> "node_id": "node_1",<br> "text": "The battery life of this laptop lasts more than 10 hours",<br> "metadata": {"product": "Laptop X1"}<br> }<br>]<br> |
| Indices | Node text: “The battery life of this laptop lasts more than 10 hours” | Vector embedding stored in index: [0.42, -0.18, 0.67, ...] |
| Retrievers | User query: “How long does the laptop battery last?” | Top relevant nodes retrieved from the index: json<br>[<br> {<br> "node_id": "node_1",<br> "text": "The battery life of this laptop lasts more than 10 hours"<br> }<br>]<br> |
| Query engines | Query and retrieved context: Query: “How long does the laptop battery last?” Context: “The battery life of this laptop lasts more than 10 hours.” | Final LLM response: “Customer reviews indicate the laptop battery lasts more than 10 hours on a full charge.” |
The input and output formats shown above are simplified examples to illustrate how data flows through each LlamaIndex component. Actual implementations may use different data structures, libraries, or storage systems depending on the application architecture and deployment environment.
How LlamaIndex works
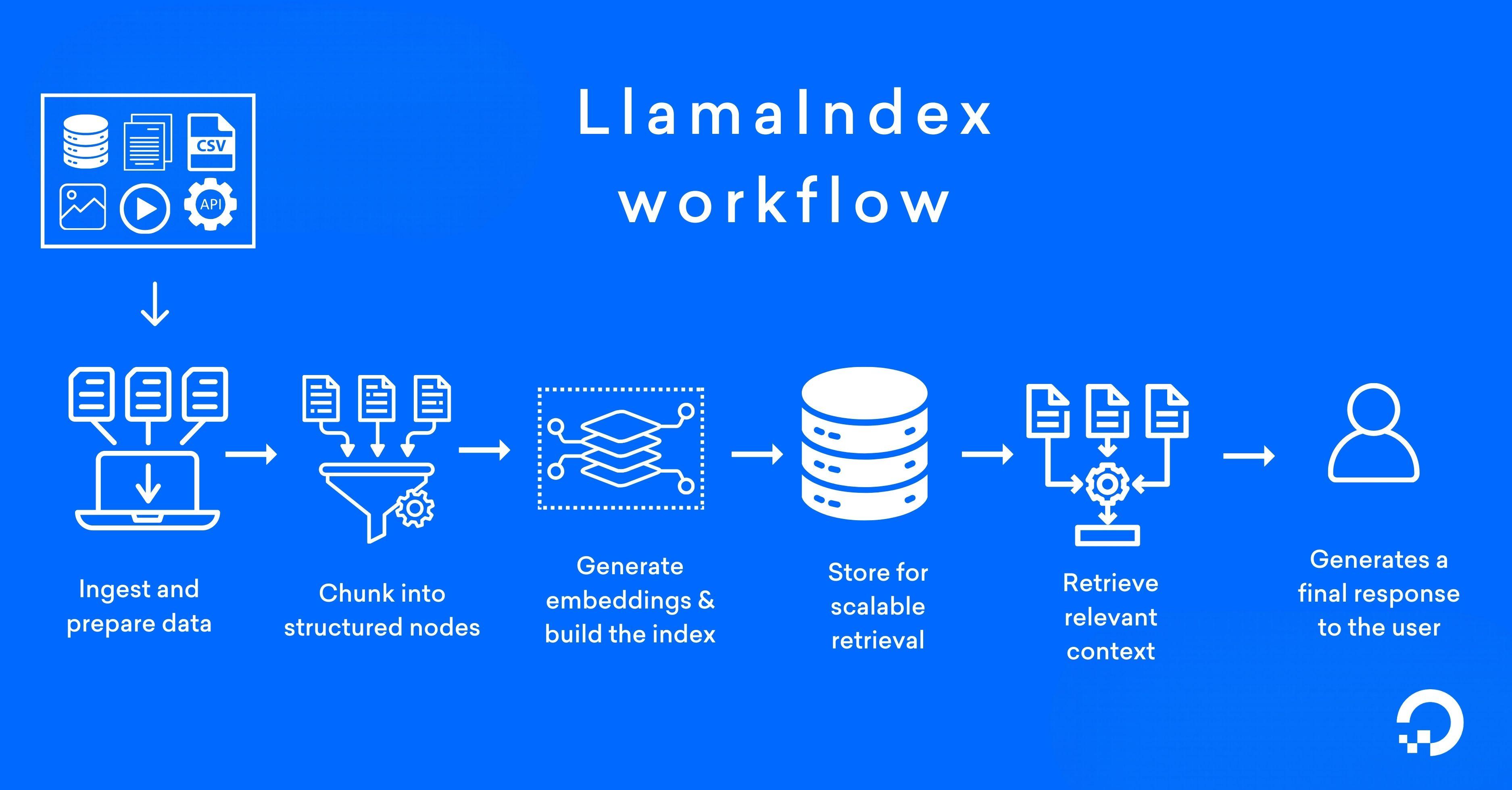
To understand how LlamaIndex works, let’s take an enterprise HR knowledge assistant built for an internal employee portal. Employees want to ask questions like, “What is the parental leave policy for remote employees?” The answer exists inside PDFs, policy documents, and a company wiki, but not inside the LLM’s training data.
1. Ingest and prepare data
Before retrieval begins, LlamaIndex connects to external data sources such as files, APIs, databases, or SaaS tools. In an enterprise workflow, this may include PDFs explaining HR policies, internal documentation systems like JIRA, and structured policy databases. The preparation stage ensures consistency across heterogeneous data sources within the indexing framework:
-
During ingestion, raw content is cleaned and normalized.
-
Text is extracted from PDFs, HTML is stripped from web pages, metadata (document title, department, or access level) is attached, and formats are standardized.
2. Chunk into structured nodes
Large documents are not suitable for direct retrieval. A 50-page HR policy manual contains too much unrelated content to send to a model at once. LlamaIndex splits content into smaller, structured units called nodes. Each node represents a semantically meaningful segment, like a policy section or paragraph, along with associated metadata. Proper chunking improves retrieval precision, enabling search to operate on focused, context-rich fragments rather than entire documents. Overly small chunks fragment context, while overly large chunks dilute relevance.
3. Generate embeddings and build the index
Once nodes are created, each node is converted into an embedding (a dense numerical vector representation) that captures semantic meaning. If an employee asks, “What is the parental leave policy for remote employees?”, the system converts the query into an embedding and compares it with node embeddings stored in the index. Even if the wording differs (e.g., “family leave for remote staff”), semantic similarity helps locate the relevant policy section.
4. Store for scalable retrieval
Embeddings and metadata are stored locally or in a vector database for production-scale querying. At a small scale, in-memory storage may suffice. In a production HR knowledge assistant, embeddings are saved in a vector database or scalable storage system. Separating embeddings from the raw documents improves performance because the retrieval system only searches through compact vector representations instead of full files. At the same time, metadata and document references can be traced for each retrieved node to its original source, like the HR policy PDF or internal wiki page, when generating the final response.
5. Retrieve relevant context
When an employee submits the query, “What is the parental leave policy for remote employees?”, LlamaIndex converts the query into an embedding using the same embedding model applied during indexing. Similarity search is then performed against stored node vectors. The system retrieves the most semantically relevant nodes: perhaps a section titled “Remote Work Benefits” and a subsection detailing “Parental Leave Eligibility.” The result is a small, high-quality set of context fragments ready for injection into the LLM.
6. Generate a response
After relevant nodes are retrieved, the query engine assembles them into a prompt that is sent to the language model. The user does not see this step. Instead, the application automatically inserts the retrieved context into a predefined prompt template. The language model then generates an answer using the retrieved context.
Context:
Remote employees are eligible for 16 weeks of parental leave. The policy applies to full-time employees after 12 months of service.
Question:
What is the parental leave policy for remote employees?
Answer: Remote employees are eligible for 16 weeks of paid parental leave.
The policy applies to full-time employees who have completed at least 12 months of service with the company.
Since the retrieval occurs before generation, the response is grounded with factual data from HR documents, policy manuals, or internal knowledge bases. The application logs operational data like the query text, retrieved node IDs, response latency, and generated output. These logs help monitor system performance, evaluate retrieval quality, and improve prompt design.
LlamaIndex use cases
LlamaIndex is effective when you want to search, analyze, or synthesize insights from large volumes of structured and unstructured data.
-
Enterprise knowledge assistants: KPMG uses LlamaIndex to provide contextual intelligence for professionals working with contracts and vendor data. The system pulls from contracts, invoices, and vendor records to surface details like upcoming renewals, misaligned payment terms, and procurement history—giving teams the context they need for renegotiations, vendor rationalization, and financial reconciliation.
-
Customer support automation: kapa.ai built a chatbot built with LlamaIndex knowledge sources deployed in the LlamaIndex Discord community to answer technical questions from users. The assistant ingested more than 200 documentation files and began responding to hundreds of questions per week, saving the equivalent of two support engineers’ time.
-
Financial document analysis: An OpenAI Developers cookbook shows how LlamaIndex is used to analyze the 10-K documents (annual reports required by the U.S. Securities and Exchange Commission (SEC)) through a RAG pipeline. The implementation involves loading financial filings, indexing the documents, and processing natural-language queries over the indexed data. Once indexed, analysts can ask questions about the documents or compare information across multiple filings using LLM-generated responses.
-
Legal and compliance search: Developer Fahd Mirza walks through LlamaIndex and LlamaCloud contract compliance checks against regulatory frameworks like GDPR. The workflow extracts key clauses from a vendor agreement, retrieves relevant regulatory language using semantic search, and compares both to evaluate compliance. The system then generates a structured compliance report that highlights violations and summarizes whether the contract meets regulatory requirements.
- Research and technical analysis: Arcee AI integrated LlamaParse to process thousands of NLP research papers stored in an S3 bucket, parsing complex content like tables, charts, and equations. The processed documents were then used to build structured datasets capable of answering technical questions about large academic corpora.
💡Adopting AI technologies in your business strategy is key to staying competitive and driving forward with innovation. DigitalOcean provides abundant AI content resources to guide you through the initial steps:
When should you use LlamaIndex?
LlamaIndex is most valuable when your application needs to ingest, parse, and query large volumes of unstructured data—think PDFs, Slack threads, Confluence wikis, or SQL databases—and return grounded answers rather than generic completions. If your bottleneck is retrieval quality (chunking strategy, embedding selection, reranking, query routing) rather than model capability, LlamaIndex gives you the framework to build and iterate on that pipeline without stitching together a dozen libraries yourself.
-
Building a dedicated data retrieval layer: Use LlamaIndex when your system requires a clear retrieval layer that prepares data before it reaches the model. The framework handles document ingestion, chunking, embedding generation, and indexing, ensuring that queries return only the most relevant context rather than entire documents.
-
Structuring data for semantic search: LlamaIndex is valuable if your application depends on semantic retrieval rather than keyword matching. LlamaIndex provides tools to convert documents into embeddings and store them in searchable index formats. The system then locates relevant information based on meaning rather than exact text matches.
-
Integrating with orchestration and agent frameworks: In many LLM architectures, orchestration tools manage workflows, agents, and tool execution. LlamaIndex fits into this architecture as the retrieval layer that supplies contextual data whenever the system needs external knowledge.
-
Supporting scalable document indexing: LlamaIndex becomes valuable when applications must manage large or frequently updated document collections. With the indexing framework, you can experiment with different indexing strategies and retrieval methods without redesigning the overall system.
Choosing between LlamaIndex, RAG, and fine-tuning
-
RAG is an architectural pattern where external data is retrieved and inserted into the prompt before the model generates a response.
-
LlamaIndex is a framework for implementing RAG pipelines, providing tools for data ingestion, indexing, and retrieval.
-
Fine-tuning modifies the model itself by training it on new data so the knowledge becomes part of the model’s weights.
A hybrid approach may also be implemented depending on your use case. For instance, a customer support assistant may use LlamaIndex (RAG) to retrieve relevant troubleshooting information from product manuals and knowledge base articles. The model can be fine-tuned on past support tickets so it learns the company’s tone and response format. In this setup, RAG provides up-to-date knowledge, and fine-tuning improves response style.
RAG and fine-tuning offer different ways to improve LLM responses: one by retrieving external knowledge and the other by adapting the model itself. The RAG vs fine tuning article breaks down their differences and helps you decide an approach for your next project.
LlamaIndex FAQ
What is LlamaIndex used for? LlamaIndex is used to implement RAG in AI systems that connect LLMs to external data. It acts as a retrieval framework and indexing framework that structures documents, creates searchable indices, and injects relevant context into LLM prompts. Applications like enterprise search, document querying, and domain-specific assistants are potential use cases for LlamaIndex.
How does LlamaIndex work with embeddings? LlamaIndex converts structured document nodes into vector embeddings that capture semantic meaning rather than keywords. When a user submits a query, the embedding model transforms the query into a vector and performs a similarity search against indexed vectors. The most relevant nodes are retrieved and passed to the model as grounded context.
Is LlamaIndex better than LangChain? LlamaIndex and LangChain serve different purposes within an AI architecture. LlamaIndex specializes in context augmentation and structured retrieval, while LangChain focuses on orchestration framework capabilities such as agents and multi-step workflows. The better choice depends on whether retrieval precision or workflow orchestration is the primary requirement.
Can LlamaIndex handle large datasets? Yes, LlamaIndex can support large datasets when paired with scalable storage like a vector database. The LlamaIndex architecture separates embeddings and metadata for efficient semantic lookup at scale. Performance depends on indexing strategy, storage layer, and query concurrency requirements.
What index types does LlamaIndex support? LlamaIndex supports multiple LlamaIndex index formats, like vector-based indices for semantic search and structured formats such as tree or list indices. The appropriate choice depends on your document structure and query patterns.
How do you query a LlamaIndex index?
Querying begins by converting a user question into an embedding using the same model applied during indexing. The retrieval framework performs similarity search across stored vectors, optionally applying metadata filters or hybrid retrieval methods. Retrieved nodes are then injected into the LLM prompt to generate a grounded response.
Turn your data into AI applications with DigitalOcean Gradient™ AI Platform
Building AI systems means connecting vector databases, storage layers, and model endpoints. With the DigitalOcean Gradient™ AI Platform, much of that complexity disappears. You can connect your LlamaIndex workflows directly to a managed knowledge base and hosted LLMs. Developers can install packages, plug the retriever and LLM into existing LlamaIndex pipelines, and immediately start building document-grounded applications.
Here’s a starter list of what you can build:
-
Support assistants grounded in product documentation that answer customer questions using manuals, FAQs, and troubleshooting guides.
-
Internal knowledge assistants that query company wikis, runbooks, and operational documentation to help teams find answers faster.
-
Code assistants with a private repository context that understand internal APIs, architecture decisions, and engineering documentation.
-
Research and document analysis tools that perform question answering across large collections of reports, papers, or technical documents.
Explore DigitalOcean Gradient™ AI Platform and launch your RAG application with managed infrastructure.
Any references to third-party companies, trademarks, or logos in this document are for informational purposes only and do not imply any affiliation with, sponsorship by, or endorsement of those third parties.
Pricing and product information are accurate as of March 2026.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
