By Adrien Payong and Shaoni Mukherjee

Retrieval‑augmented generation is supposed to augment large language models with external knowledge. It can work beautifully in demos: a small curated dataset, clean queries, and an unconstrained latency budget lead to knowledgeable, grounded answers that users believe are correct. However, many teams find that once they deploy their RAG application to users, performance collapses. Queries become ambiguous, the corpus expands, retrieval quality drops, latency balloons, and the system silently begins to fade in accuracy. Even worse, poor evaluation techniques hide where the system actually begins to fail until users complain. This article explores reasons why many RAG systems fail in production. We draw from recent research and industry guidelines. We frame issues around retrieval quality, latency trade‑offs, embedding drift, and evaluation gaps as links in a chain of failure modes. Each link in this chain must be accounted for to build a robust production RAG system.
Key Takeaways
- Most RAG failures start in retrieval, not generation. When the system retrieves incomplete, irrelevant, or poorly ranked evidence, even a strong LLM will produce weak answers.
- Better retrieval requires better engineering choices. Domain-aware chunking, hybrid retrieval, and reranking are presented as core techniques to improve relevance and reduce silent retrieval failures.
- Latency quickly becomes a production bottleneck. Adding larger top_k, rerankers, long contexts, and extra retrieval steps may improve recall, but it can also make the system too slow for real users.
- Embedding drift quietly degrades performance over time. Changes in embedding models, document collections, and user vocabulary can all shift retrieval behavior, so versioning and observability are necessary.
- Final-answer quality alone is not enough for evaluation. Teams need separate retrieval and generation metrics, realistic test sets, ongoing monitoring, and the ability for the system to abstain when evidence is weak or missing.
Failure Due to Poor Retrieval Quality
Low retrieval quality is one of the most frequent causes of failure of RAG systems when deployed to production. Developers often blame the LLM for wrong/bad answers; however, the fault typically lies earlier in the pipeline. If the system cannot retrieve complete or relevant evidence, or ranks evidence poorly, even the best model is unlikely to generate a trustworthy response. Retrieval quality should be treated as a first-class engineering concern rather than a background step.
Most failures happen before the LLM sees a query
The standard pipeline embeds the user query, retrieves the top‑k documents from a vector store, and sends them off to an LLM. Every arrow in that pipeline is a potential point of failure.
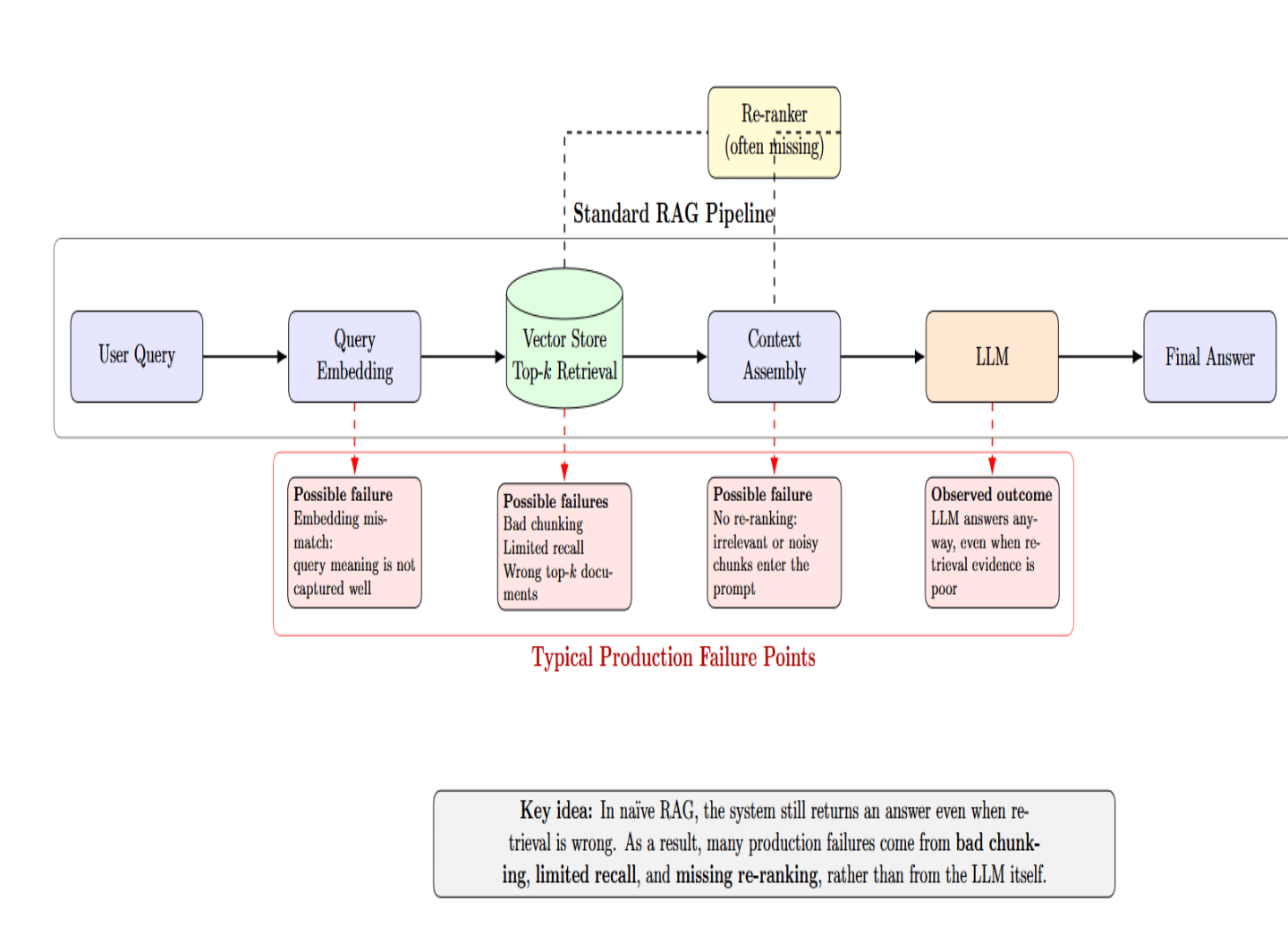
Naïve RAG obscures these failures since the system provides an answer regardless of whether the retrieval was wrong. Many production issues arise from bad chunking strategies, limited recall, and missing re‑ranking, rather than shortcomings of the LLM.
Chunking mistakes creates silent failures
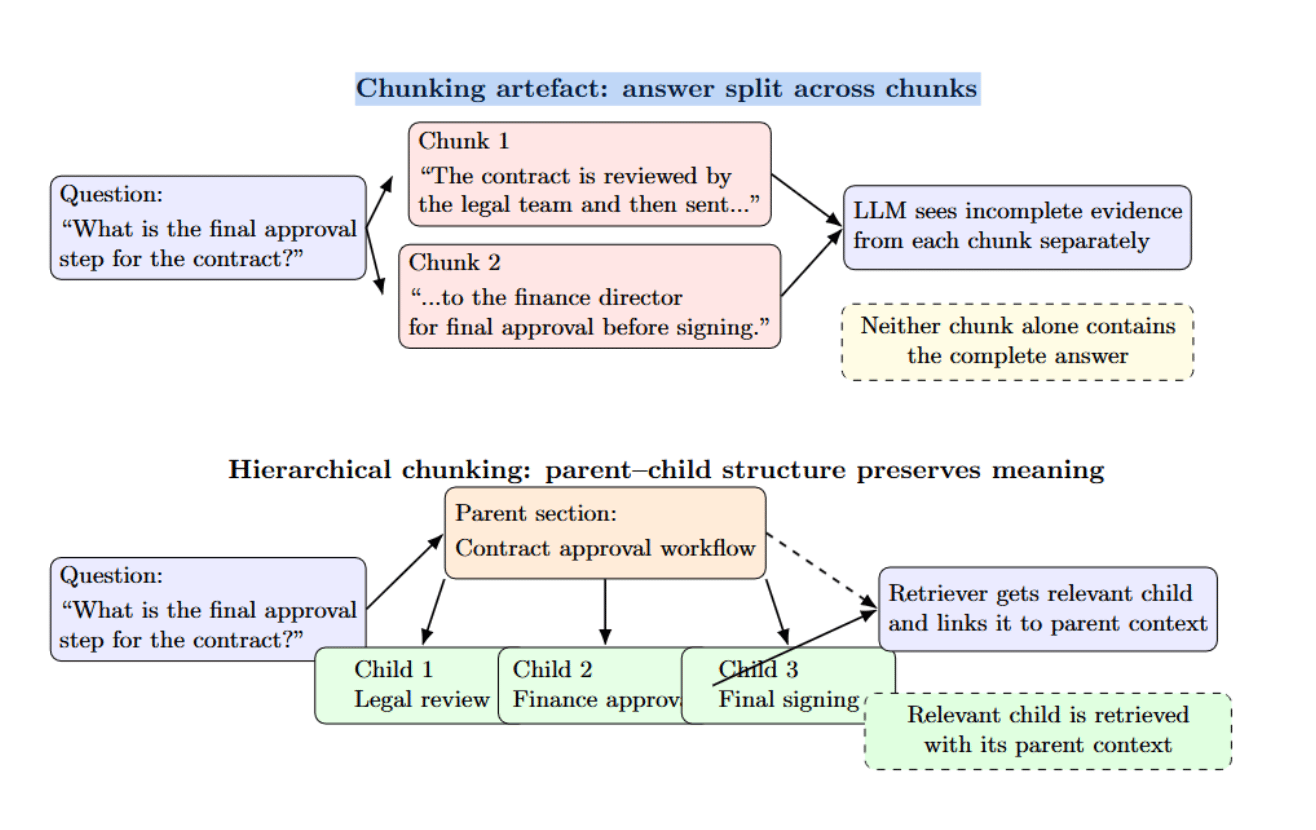
Chunk size impacts precision/recall — larger chunks provide more context with less relevance, while smaller chunks provide higher precision but lose surrounding information. Hierarchical (parent–child) chunking solves this trade‑off by storing entire sections as the parent chunk and retrieving only the smaller relevant child chunk.
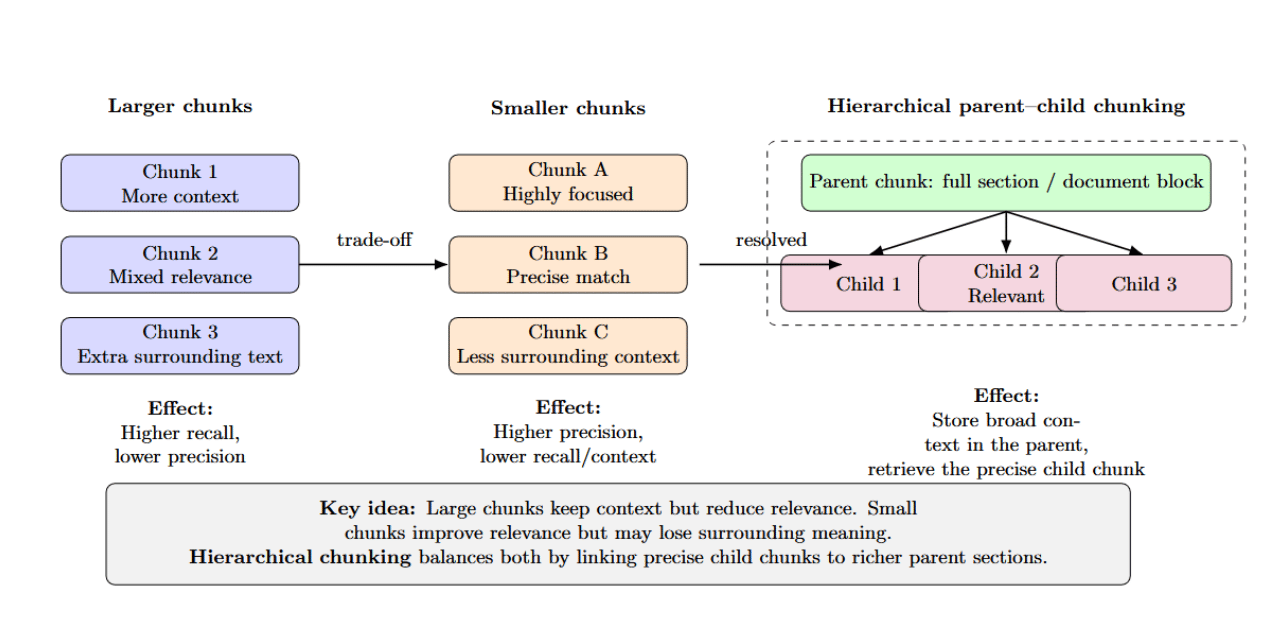
NVIDIA’s internal testing on university presentation decks found that hierarchical chunking improves answer accuracy from 61% with fixed‑size chunks to 89%. It’s important to choose an appropriate chunk size while still respecting structural boundaries and applying domain‑aware splitting where possible.
Hybrid retrieval and re‑ranking
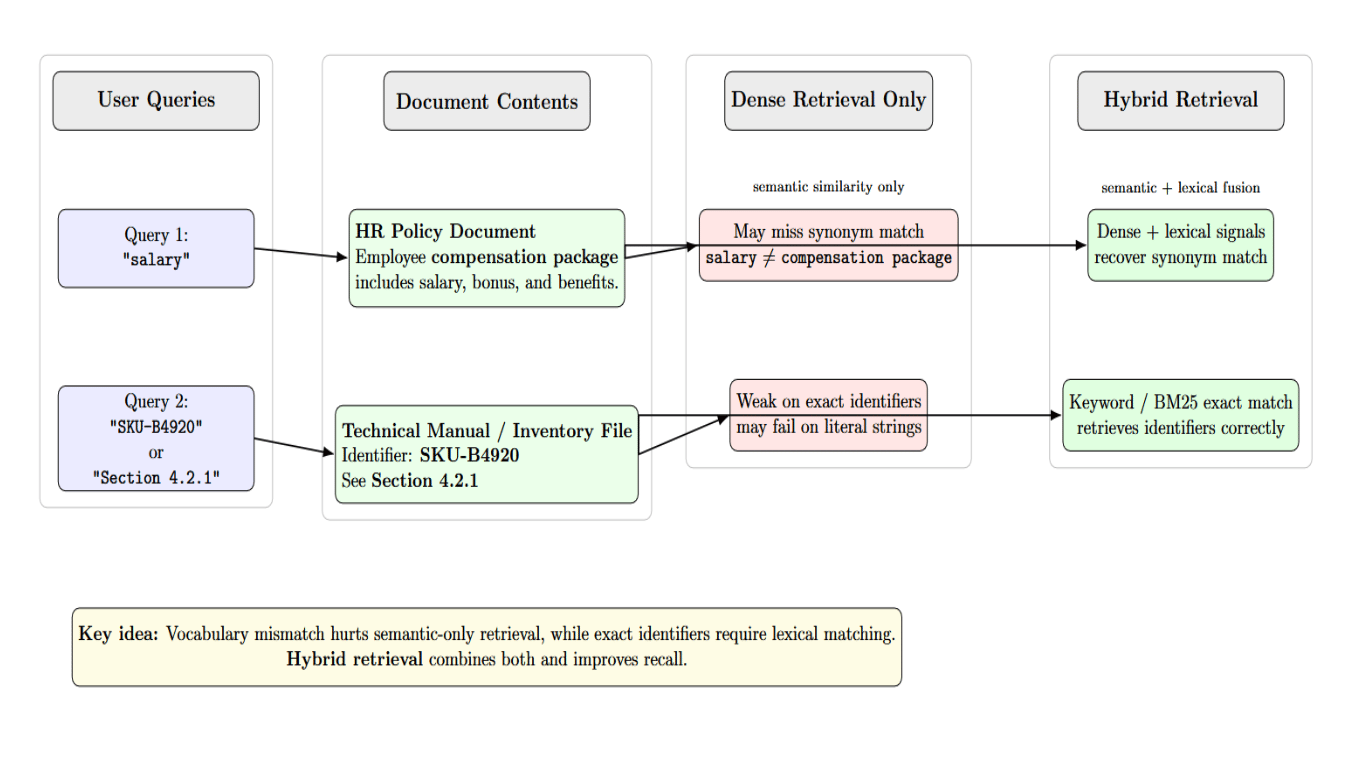
Pure dense retrieval is good at semantic similarity but misses exact identifiers. Pure keyword search is sensitive to exact terms, but fails at semantic paraphrases. Hybrid retrieval systems run dense (vector) retrieval and sparse (BM25/keyword) retrieval simultaneously, then fuse their results with reciprocal rank fusion.
Hybrid retrieval systems solve vocabulary mismatch by combining semantic similarity signals with lexical matching signals. Rescoring the candidate pairs with a re‑ranker (cross‑encoder) after fusion improves recall. Essentially, rerankers reorder retrieved documents so that only the most relevant documents make it into the context that the LLM reviews. This saves token limits and avoids context stuffing while improving LLM recall.
Retrieval metrics must be monitored separately
Teams tend to only measure end‑to‑end answer quality. Retrieval itself has metrics you can use: precision@k (what fraction of retrieved chunks are relevant? ), recall@k (what fraction of relevant chunks did you retrieve? ), mean reciprocal rank (how high was the first relevant chunk? ), and normalized discounted cumulative gain (how good is your overall ranking?).
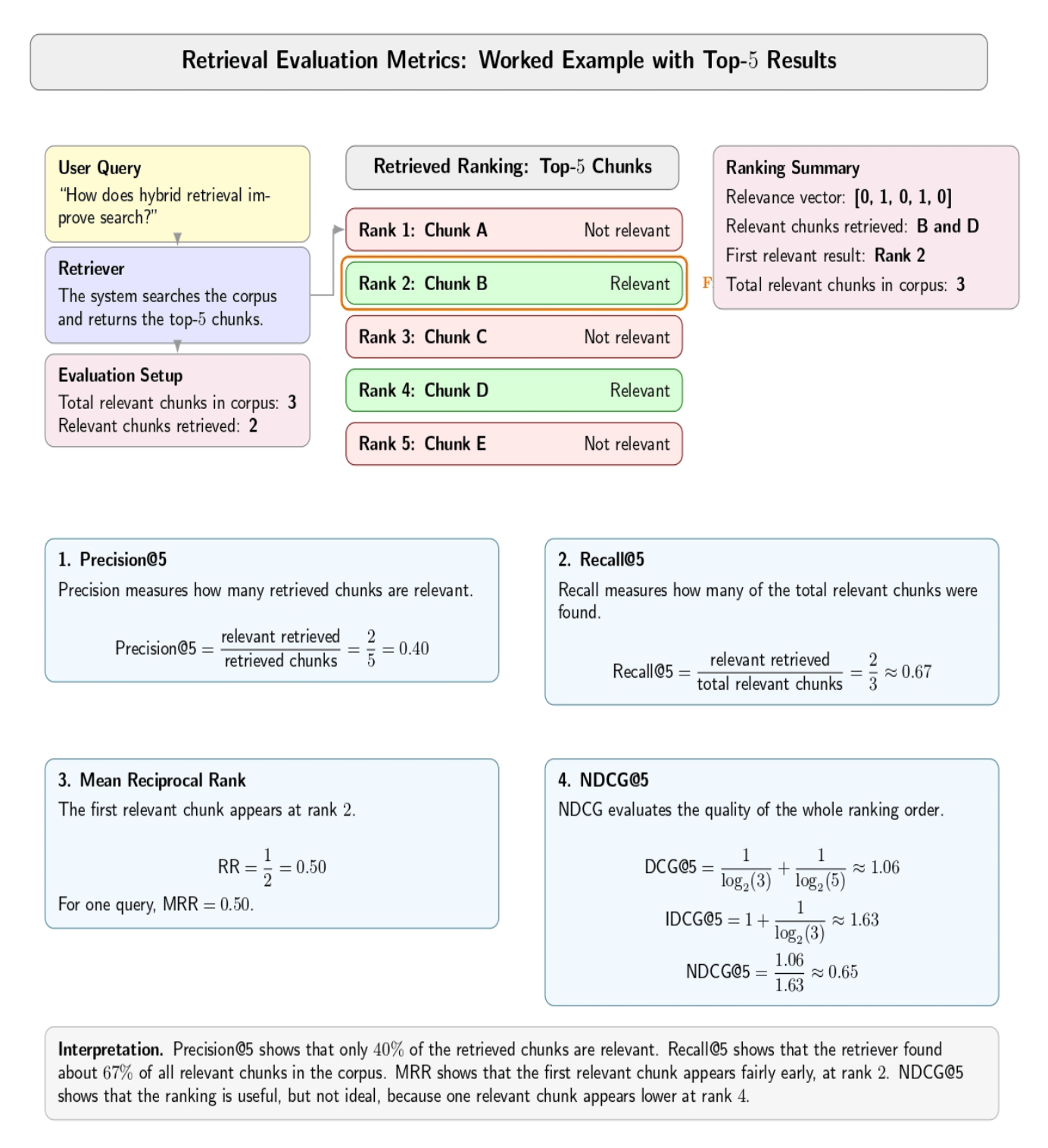
If you don’t measure these, you won’t know if the failures are from a bad retrieval or a bad generator. Test queries and golden datasets will let you evaluate offline. If you track these metrics on real queries, you can surface production regressions.
Diagnosing retrieval failure with examples
Ambiguous queries and vocabulary mismatch often cause incorrect retrieval. A user may search for “salary” while the document refers to “compensation package”. Dense embeddings may fail to recognize the synonym, while hybrid retrieval corrects this. Another case is for exact matches, such as identifiers. A query for “SKU‑B4920” or “Section 4.2.1” needs exact lexical matching.
“Lost in the middle” happens when relevant information is buried deep in a lengthy document. The LLM will underweight tokens in the middle chunks.
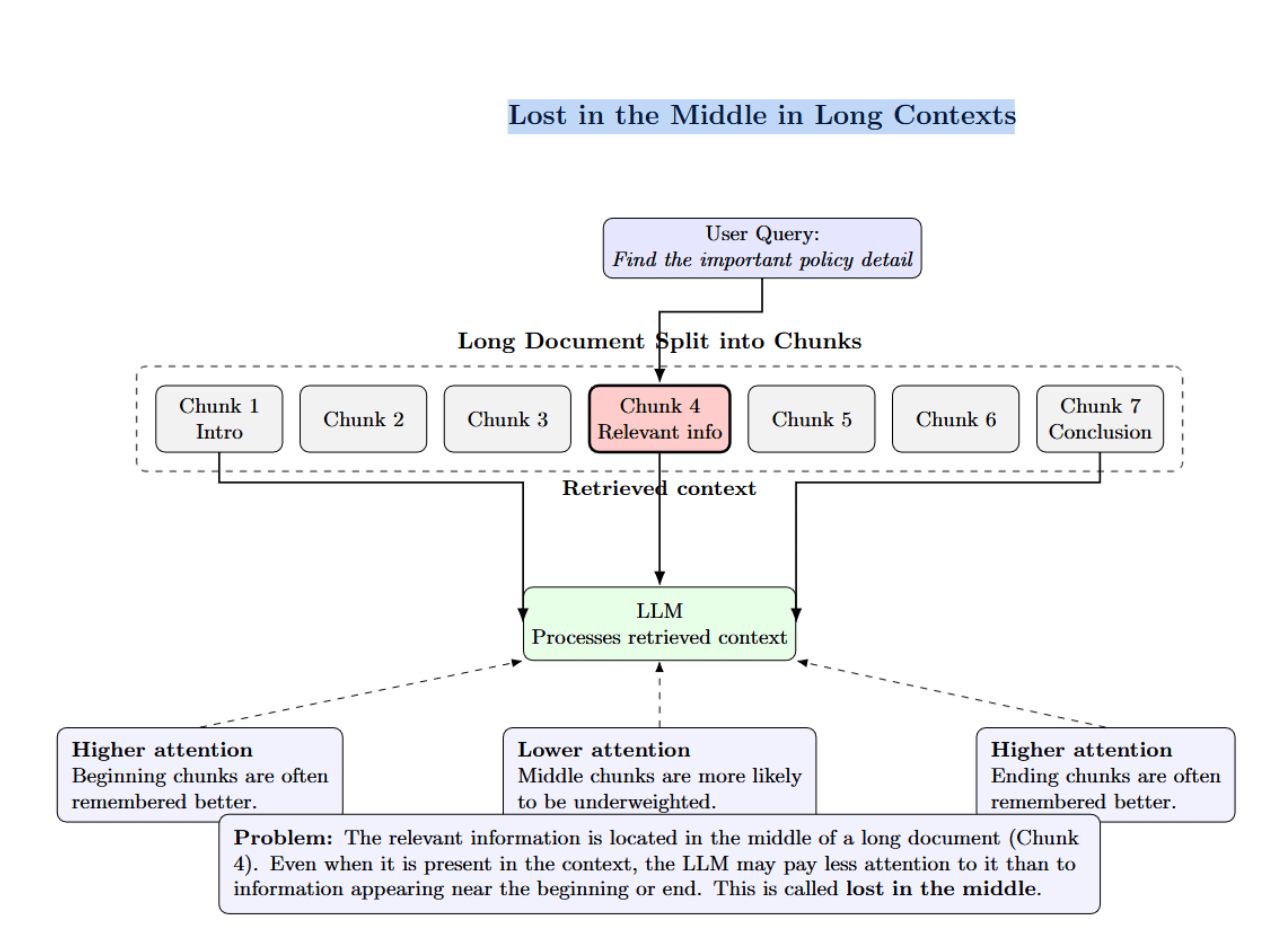
Chunking artefacts arise when an answer is split across two chunks, so neither chunk contains the complete answer. Hierarchical chunking helps mitigate this by connecting parent and child nodes.
Failure Due to Latency Explodes in Real Systems
Latency is one of the main reasons a RAG system that works in a demo struggles in production. As retrieval pipelines become more sophisticated, response times can rise quickly and force teams to trade answer quality against usability.
The retrieval–latency trade‑off
Production teams often must balance retrieval quality and their latency budgets. Everything that increases response time (going bigger with top_k, adding hybrid retrieval, doing reranking, or running long‑context models) cuts into those budgets. The trade‑off is especially difficult because users expect responsive answers, and enterprise integrations come with rigid latency budgets. However, as recent work by Cornell and NVIDIA demonstrates, RAG incurs significant latency overhead. Running retrievals too frequently can boost accuracy, but increase end‑to‑end latency to nearly 30 seconds—too high for production use.
Generation usually dominates, but retrieval matters
Benchmarking with RAGPerf shows that generation is often the dominant part of text‑only RAG pipelines. Choosing a smaller LLM can drastically reduce latency without sacrificing answer quality if retrieval quality is maintained. Multimodal pipelines (PDF and image retrieval) have large compute demands in part due to reranking and the associated cross‑modal models. Retrieval latency can increase when vector databases are slow or don’t allow concurrent lookups. However, even with fast lookups, reranking can dominate total latency for many RAG workloads.
Latency, cost, and context windows
Some teams try to solve recall by increasing top_k or cramming more documents into the LLM’s context. Studies show this has the opposite effect. The more documents you add to the prompt, the less able the LLM is to recall the correct information. Retrieval reranking solves this by retrieving many documents, then selecting only the best ones for the LLM. Long context windows cause “lost in the middle” and astronomical computational costs.
Optimizing latency
Addressing latency in RAG systems requires deliberate orchestration across the entire pipeline:
| Focus Area | What to Do | Why It Matters |
|---|---|---|
| Retrieval quality | Use domain-aware chunking instead of default fixed windows. Preserve document structure where it matters. Combine dense and lexical retrieval. Add reranking. Use metadata intelligently. | Improves coverage and relevance, and helps the system retrieve context that is more useful for grounded answers. |
| Latency control | Measure every stage. Remove steps that do not produce meaningful gains. Keep the pipeline as simple as the use case allows. Build for the real interaction pattern. | Reduces unnecessary overhead and keeps the system responsive in real production settings. |
| Drift management | Version embeddings, indexes, chunking strategies, and ingestion policies. Re-evaluate when documents change or models are swapped. Engineer freshness explicitly. | Prevents silent quality decay as content, models, and query patterns evolve over time. |
| Evaluation | Maintain golden datasets based on real queries. Separate retrieval metrics from generation metrics. Measure context precision, recall, groundedness, and faithfulness. | Helps identify the true failure point instead of relying only on final answer quality. |
| Monitoring and tracing | Run evaluations before deployment and monitor after launch. Add tracing across the retrieval and generation layers. | Makes regressions visible and helps teams diagnose failures more precisely in production. |
| Abstention behavior | Let the system say when evidence is missing, stale, or contradictory. | Improves trust by favoring disciplined grounding over confident but weak answers. |
Failure Due to Embedding Drift and Knowledge Change
Embeddings represent text as high‑dimensional vectors with similar meanings close to each other. Teams frequently re-embed their documents with a different embedding model or swap out query encoders without versioning their index properly or benchmarking relevance changes. The new model might be objectively stronger, but it could change neighborhood structure in unexpected ways that impact ranking, recall, or even domain-specific language. A model that excels at generalized benchmarks might perform terribly with your real-world enterprise lingo.
The three causes of drift
- Model drift. Embedding models are constantly updated. When you index documents using a version of an embedding model, you can’t search them with embeddings from another model. Switching the embedding model without reindexing the corpus will affect your retrieval.
- Corpus drift. When you add new documents to the index, especially documents of new types, the vector space changes. New clusters of dense vectors appear. Those dense clusters begin pulling in queries that should be matching against other documents. Adding user-generated or noisy content will degrade retrieval quality over time, even if you don’t change the embedding model.
- Query drift. Users’ vocabulary expands and shifts over time. New terms come into usage (“remote work,” “stablecoin,” “prompt engineering”) and old terminology fades away. Pre-existing embeddings cannot match against words that didn’t exist when they were trained. If a company changes the name of one of its products, searches for the new name fail because embeddings still reflect the old name.
Detecting Embedding Drift with Mean Reciprocal Rank
Below is an example diagram illustrating how embedding drift is detected by monitoring changes in retrieval performance before and after a system change, or over time. The diagram first calculates a baseline MRR score where relevant documents appear near the top of the ranking. Then it calculates a current MRR score where relevant documents are ranked further down the ranking. The system then computes the percentage drop between baseline MRR and current MRR. If the MRR drop is above a preselected threshold, the system raises an alert for embedding drift and suggests reviewing the embedding model, data distribution, and index. Otherwise, if the drop is below the threshold, then the system determines the retrieval system is stable and continues monitoring.
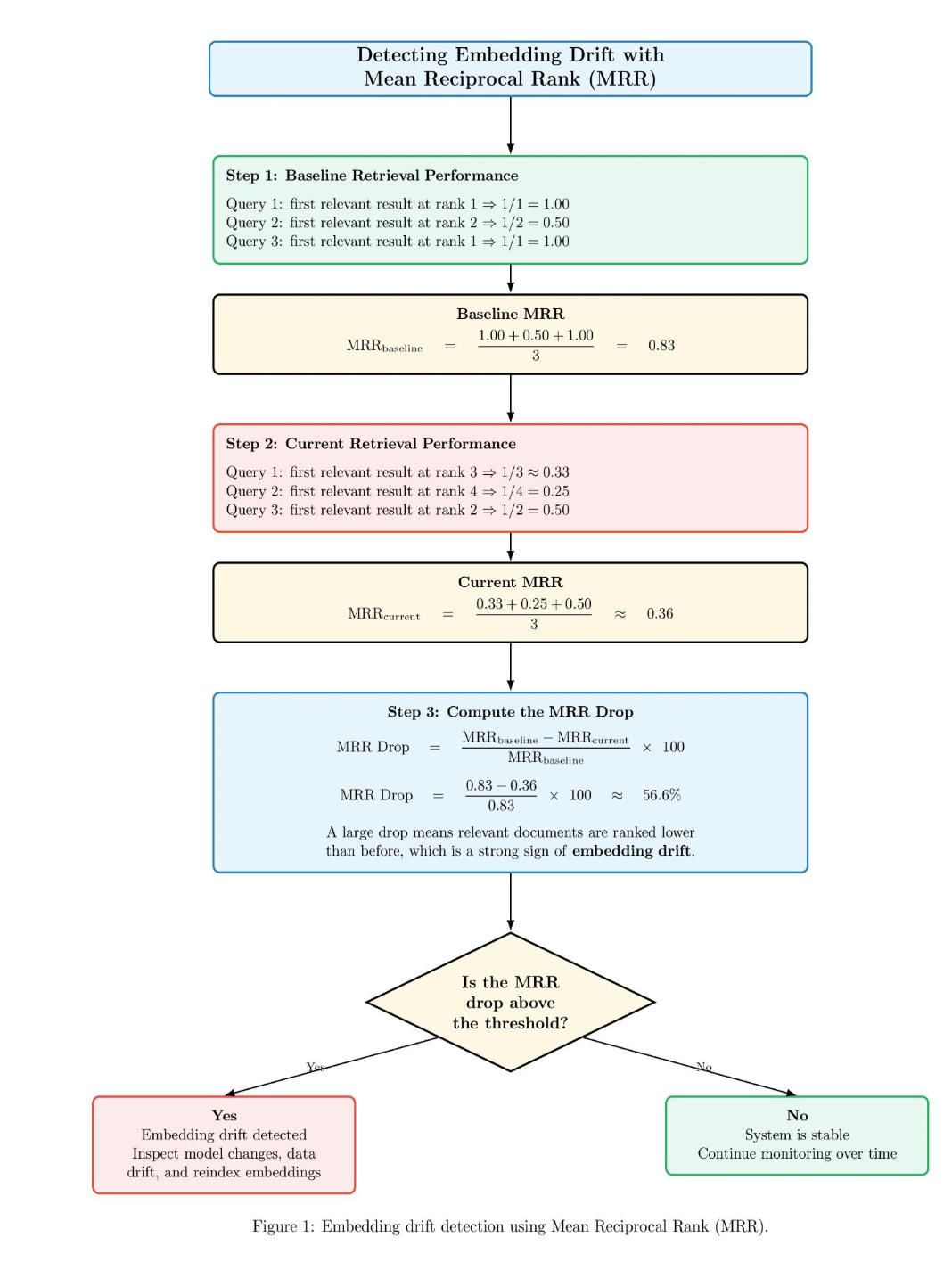
For this reason, production RAG systems need to be explicitly versioned and observable. The embeddings should be versioned. Index builds should be traceable. The chunking policy should be documented and reproducible. If quality starts to degrade, you must be able to answer questions such as: Which embedding model produced this index? What chunking rules created this chunk of content? When was this document last re-ingested into the system? What retriever and reranker served this request?
If you don’t have visibility into the pipeline, drift will seem random. With it, it becomes diagnosable.
Failure Due to Evaluation Gaps: Hides the Real Bottleneck
Weak evaluation is the fourth most common reason teams fail to deploy RAG systems into production. We tend to only evaluate the final answer. That is not enough.
Production-grade RAG is a pipeline. At any number of layers, poor inputs can cause bad final outputs. The retriever may have failed to retrieve the right document. The ranker may have ranked the best evidence too low. The context assembler may have included too much noise. The generator may have glossed over the strongest passage. The answer could be correct on a broad level while still being totally unfaithful to the retrieved evidence. You cannot identify weak stages if you only score the final output text.
Retrieval Metrics Should Be Evaluated Separately
For this reason, RAG evaluation should include separate retrieval metrics from generation metrics. Retrieval metrics should include context precision and context recall.
- Context Recall: Context recall checks whether the passages retrieved contain the information necessary to answer the question.
- Context Precision: Context precision measures whether the retrieved set is mostly relevant or is polluted with noise.
- Ranking quality: Ranking quality matters too, since a relevant passage at rank 1 is more useful than the same relevant passage at rank 10.
Generation Metrics Matter Just As Much
Once retrieval is measured, the generation layer must be evaluated on its own terms. Two key metrics are groundedness and faithfulness.
- Groundedness: Groundedness asks whether the answer reflects information provided in the retrieved context.
- Faithfulness: Faithfulness asks whether the model accurately represents that context. This metric matters because a system can sound plausible while still misrepresenting the source material.
Unrealistic Test Data Hides Real Failures
Unrealistic test data is another major issue. Many teams evaluate on clean, synthetic questions or prompts carefully curated by internal teams. That fundamentally hides the real failure surface. Evaluation conditions in production should include ambiguous questions, contradictory documents, partial user input, stale content, and situations where the right answer is to not answer at all. If the dataset does not reflect real user behavior, evaluation becomes a comfort mechanism rather than a diagnostic tool.
Evaluation Must Continue After Deployment
Evaluation shouldn’t stop after you’ve completed the initial run. Production RAGs change. Documents change. Embeddings get swapped out. Ranking logic evolves. Prompt templates shift. Without evaluation as part of your CI/CD and production tracing post-deployment, you’ll learn about regressions from unhappy users rather than from their own monitoring.
Why Production RAG Fails Even When Benchmarks Look Good
This is where many teams become confused. Benchmarks improve, yet the live system still disappoints.
Production Failures are usually caused by incentive misalignment. Teams try to optimize for retrieval recall without factoring in latency budgets or optimize for higher LLM scores without tracking retrieval precision. Retrieval may be over‑tuned at the expense of generation quality, introducing noise. Generation may be over‑tuned without regard to retrieval improvements. The appropriate ratio between retrieval and generation accuracy depends on the application. Compliance, legal, and other high-stakes use cases require as much faithfulness and context precision as possible. Creative use cases can allow for noise in exchange for speed.
Production isn’t optimized on a single metric. There are tradeoffs between retrieval quality, latency, freshness, groundedness, and operational simplicity. That’s why demo success can be so misleading. Demos reward systems that “sound right”. Production rewards reliability.
How to Fix Production RAG Systems
The path forward is not to abandon RAG. It is to treat it as a disciplined retrieval system.
| Focus Area | What to Do | Why It Matters |
|---|---|---|
| Retrieval quality | Use domain-aware chunking instead of default fixed windows. Preserve document structure where it matters. Combine dense and lexical retrieval. Add reranking. Use metadata intelligently. | Improves coverage and relevance, and helps the system retrieve context that is more useful for grounded answers. |
| Latency control | Measure every stage. Remove steps that do not produce meaningful gains. Keep the pipeline as simple as the use case allows. Build for the real interaction pattern. | Reduces unnecessary overhead and keeps the system responsive in real production settings. |
| Drift management | Version embeddings, indexes, chunking strategies, and ingestion policies. Re-evaluate when documents change or models are swapped. Engineer freshness explicitly. | Prevents silent quality decay as content, models, and query patterns evolve over time. |
| Evaluation | Maintain golden datasets based on real queries. Separate retrieval metrics from generation metrics. Measure context precision, recall, groundedness, and faithfulness. | Helps identify the true failure point instead of relying only on final answer quality. |
| Monitoring and tracing | Run evaluations before deployment and monitor after launch. Add tracing across the retrieval and generation layers. | Makes regressions visible and helps teams diagnose failures more precisely in production. |
| Abstention behavior | Let the system say when evidence is missing, stale, or contradictory. | Improves trust by favoring disciplined grounding over confident but weak answers. |
FAQ SECTION
How do you measure retrieval quality in RAG?
We use retrieval metrics such as context precision, context recall, and ranking quality, and also check whether the retrieved evidence actually supports answer generation.
What causes RAG systems to fail in production?
Production failures are most commonly caused by a degradation in retrieval quality, latency creep, embedding/corpus drift, and bad evaluation practices that hide where problems start.
What is embedding drift in an RAG pipeline?
Embedding drift occurs when updates to embedding models, corpora, or live query behavior slowly change retrieval behavior (degrading relevance), without causing any obviously broken system behavior.
Why does RAG latency increase at scale?
Latency rises because production systems often add query rewriting, multiple retrieval passes, reranking, extra model calls, and larger corpora, all of which increase processing time and operational complexity.
How do you evaluate groundedness and faithfulness in RAG?
You compare the generated answer against the retrieved evidence, checking whether claims are supported by the sources and whether the wording accurately reflects those sources without invention or distortion.
Conclusion
Production failure in most RAG systems isn’t the result of a single point of failure. Instead, responsible engineers will notice most breakdowns begin with a weak link in a connected chain. Retrieval quality is nearly always the first to fail. Engineers “solve” this problem by leveraging more retrieval, more context, and more orchestration layers. Doing so serves to increase latency. As embeddings, corpora, and user behavior all drift over time, weak evaluation metrics hide where the system is truly failing. Users start to notice and lose trust before managers realize there is a problem. By then, the breakdown of the pattern feels mysterious. However, the problems were clear from the start.
RAG fails at scale not because the pattern is wrong, but because building production RAG systems requires strong retrieval engineering, latency management, drift mitigation, and continuous evaluation. They demand improved ranking, improved chunking, better observability, and measurement of groundedness and faithfulness. Most importantly, teams need to approach RAG as a living system rather than a set-it-and-forget-it demo architecture.
Reference
- RAG System in Production: Why It Fails and How to Fix It
- Best Chunking Strategies for RAG (and LLMs) in 2026
- What is RAG evaluation? Measuring retrieval quality and answer groundedness
- Towards Understanding Systems Trade-offs in Retrieval-Augmented Generation Model Inference
- RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
- Rerankers and Two-Stage Retrieval
- From RAG to Context - A 2025 year-end review of RAG
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
