AI Technical Writer

Introduction
Creating high-quality, SEO-optimized content at scale can now be done efficiently with modern AI capabilities. Instead of treating content generation as a manual, one-off task, you can build a structured pipeline that transforms a list of topics into well-formatted, consistent outputs.
By utilising DigitalOcean Serverless Inference, we have created a pipeline that allows you to process multiple inputs simultaneously, significantly improving efficiency while maintaining control over structure and quality. In this guide, generating SEO briefs and articles is used as a practical example to demonstrate how such a system can automate workflows and handle high-throughput content generation.
This pipeline-driven method is also highly flexible. With small adjustments, it can be extended beyond blog articles to support a wide range of use cases, such as:
- Product descriptions for e-commerce platforms.
- Structured content outlines.
- Social media captions and marketing copy.
- Technical documentation or knowledge base articles.
With this approach, we will:
- Generate SEO briefs automatically from a list of topics.
- Expand those briefs into full-length, structured articles.
- Save each output as clean, reusable Markdown files.
- Package all generated content into a downloadable ZIP.
All of this is implemented using a lightweight Python pipeline and an interactive Gradio interface, making it easy to run bulk content generation workflows with minimal setup.
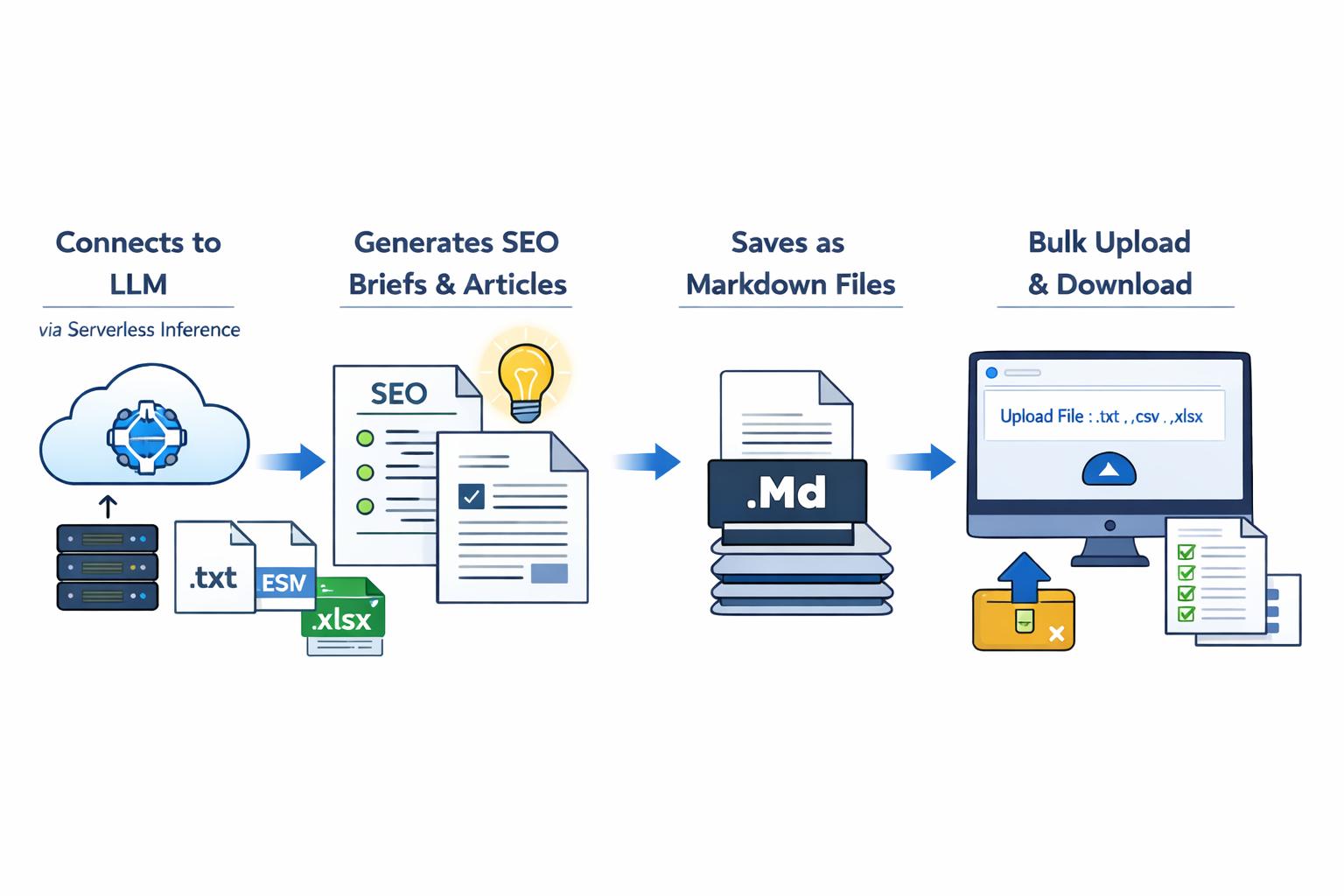
Key Takeaways
- This pipeline helps you generate multiple SEO briefs and articles in one go, saving a significant amount of time and effort.
- Using structured prompts ensures that all generated content stays consistent, organized, and SEO-friendly.
- Automating the entire pipeline removes repetitive manual work and improves overall productivity.
- Saving outputs in Markdown format makes it easy to edit, manage, and publish content across different platforms.
- Running the pipeline on a GPU-enabled Droplet speeds up content generation, especially for large batches.
Prerequisites
- A DigitalOcean account for setting up and using the LLMs.
- GPU Droplet (recommended but not mandatory).
- Basic Python knowledge.
- Familiarity with APIs and environment variables (for managing API keys securely).
- Optional: Experience with tools like Jupyter Notebook or Gradio for experimentation and UI building.
What is Serverless Inference?
Serverless inference is a way to use AI models without setting up or managing any servers. Instead of downloading models, configuring GPUs, and maintaining infrastructure, you simply send a request (API call) to a cloud service, and it returns the result. Everything else, like scaling, performance, and availability, is handled automatically in the background and with token-based billing.
In this tutorial, we are using a GPU-powered setup to speed up inference and handle bulk content generation efficiently, but feel free to use any environment that fits your needs, such as a CPU-based machine, a local setup, or even a fully managed serverless inference endpoint if you want to avoid infrastructure management altogether.
Step-by-Step Implementation
Before we start, just in case if we are working with a GPU Droplet we will then first create the GPU Droplet for our use case. In our previous tutorials, we provided step-by-step instructions for creating a GPU Droplet; please feel free to refer to the documentation for more information.
- First, create a GPU Droplet on DigitalOcean,
- We will choose a GPU-enabled instance,
- Select Ubuntu as the OS,
- Connect using SSH.
ssh root@your-server-ip
This can also be done using VS Code; working entirely with the terminal can sometimes be tricky, so that’s why using a familiar IDE like Visual Studio Code can make the process much easier.
Please note:- You can run this setup on any infrastructure you prefer, but for this tutorial, we’ll use a GPU-enabled Droplet to speed up performance.
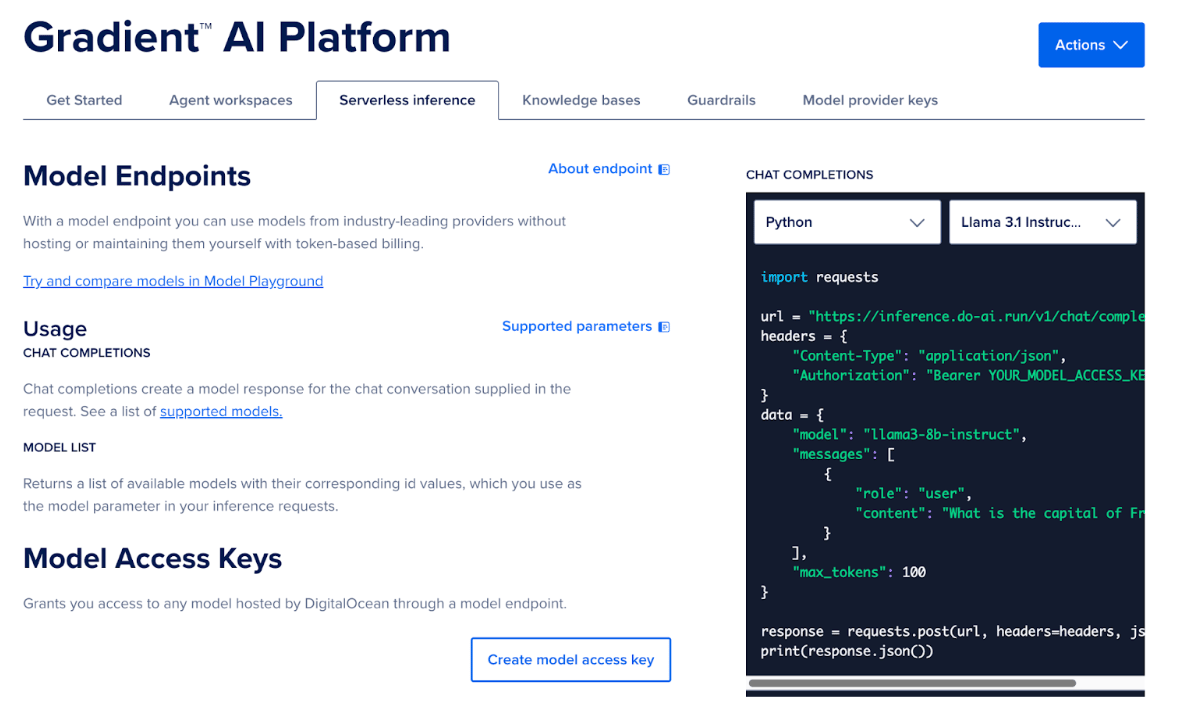
How to use AI Platform serverless inference
To start using serverless inference on DigitalOcean AI Platform, you need to create and use a model endpoint with an access key. Follow these steps:
- Go to the DigitalOcean Platform.
- Navigate to the Agent platform and select the Serverless Inference option.
- Here you will find the details regarding the Model Endpoints.
- Click on “Create Model Access Key”.
- Give it a name. Here, you will also find all the models that can be accessed, along with the pricing.
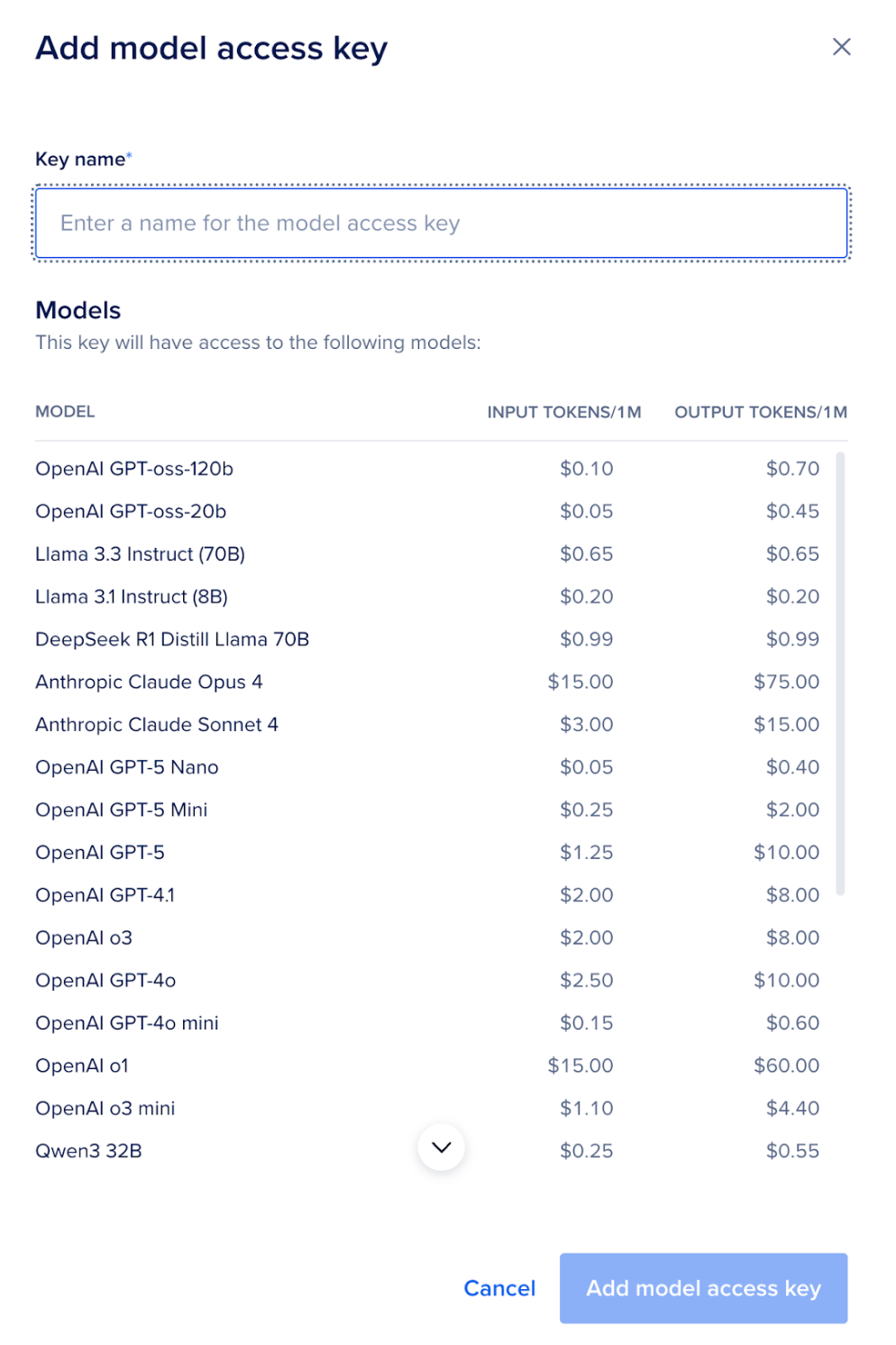
- Copy the generated API key.
This key will be used to authenticate all your inference requests.
Understanding the Code Logic
In this section, we’ll break down how the entire pipeline works from reading topics to generating SEO briefs and full articles and displaying everything through a simple UI built with Gradio.
How the Pipeline Works
- Connects to an LLM (via serverless inference).
- Generates SEO briefs and articles.
- Saves outputs as Markdown files.
- Provides a UI to run everything in bulk (One can upload a .txt, .csv, or .xlsx file which contains the article titles, and the code will generate the zip file containing all the markdown files).
Complete Implementation: Code Logic Explained
Below is the full implementation of the pipeline:
import gradio as gr
import os
import zipfile
import pandas as pd
from datetime import datetime
from openai import OpenAI
from dotenv import load_dotenv
# -----------------------------
# Load API Key
# -----------------------------
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/",
api_key=os.getenv("DO_API_KEY"),
)
MODEL_NAME = "llama3-8b-instruct"
# -----------------------------
# LLM Calls (Serverless)
# -----------------------------
def generate_seo_brief(topic: str) -> str:
prompt = f"""
You are an SEO expert.
Topic: {topic}
Generate:
- SEO Title
- Meta Description
- Target Keywords
- Article Outline
- URL Slug
"""
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": "You are an expert SEO strategist."},
{"role": "user", "content": prompt}
],
temperature=0.7,
)
return response.choices[0].message.content
def generate_article(topic: str, seo_brief: str) -> str:
prompt = f"""
You are a professional technical content writer.
Write a detailed SEO-optimized article.
Topic: {topic}
SEO Brief:
{seo_brief}
- Use headings
- Add examples
- Make it engaging
"""
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": "You are a technical content writer."},
{"role": "user", "content": prompt}
],
temperature=0.7,
)
return response.choices[0].message.content
# -----------------------------
# File Helpers
# -----------------------------
def read_topics(file):
if file.name.endswith(".csv"):
df = pd.read_csv(file.name)
return df.iloc[:, 0].dropna().tolist()
elif file.name.endswith(".txt"):
with open(file.name, "r") as f:
return [line.strip() for line in f.readlines() if line.strip()]
else:
return []
def save_markdown(topic, seo, article, folder):
filename = topic.replace(" ", "_").replace("/", "_")
filepath = os.path.join(folder, f"{filename}.md")
with open(filepath, "w", encoding="utf-8") as f:
f.write(f"# {topic}\n\n")
f.write("## SEO Brief\n\n")
f.write(seo + "\n\n")
f.write("## Article\n\n")
f.write(article)
return filepath
def create_zip(folder):
zip_path = f"{folder}.zip"
with zipfile.ZipFile(zip_path, "w") as zipf:
for file in os.listdir(folder):
zipf.write(os.path.join(folder, file), file)
return zip_path
# -----------------------------
# Main Pipeline
# -----------------------------
def process_file(file):
topics = read_topics(file)
if not topics:
return "❌ No valid topics found.", None
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_folder = f"outputs_{timestamp}"
os.makedirs(output_folder, exist_ok=True)
logs = []
for topic in topics:
logs.append(f"Processing: {topic}")
seo = generate_seo_brief(topic)
article = generate_article(topic, seo)
save_markdown(topic, seo, article, output_folder)
logs.append(f"✅ Done: {topic}")
zip_file = create_zip(output_folder)
return "\n".join(logs), zip_file
# -----------------------------
# Gradio UI
# -----------------------------
with gr.Blocks() as app:
gr.Markdown("# 🚀 Bulk SEO + Article Generator (Serverless Inference)")
file_input = gr.File(label="Upload .txt or .csv with topics")
output_logs = gr.Textbox(label="Processing Logs", lines=15)
download_file = gr.File(label="Download Markdown ZIP")
run_btn = gr.Button("Generate in Bulk")
run_btn.click(
fn=process_file,
inputs=file_input,
outputs=[output_logs, download_file]
)
if __name__ == "__main__":
app.launch(server_name="0.0.0.0")
Understanding the Implementation
Let’s break down how each part of the pipeline works.
Setting Up the LLM Client
client = OpenAI(
base_url="https://inference.do-ai.run/v1/",
api_key=os.getenv("DO_API_KEY"),
)
MODEL_NAME = "llama3-8b-instruct"
Here, the code will initialize a client to interact with serverless inference endpoints. The model used is Llama 3 8B Instruct, which is lightweight and efficient for content generation; however, you can choose any other model. The best model for any specific use case can be determined by comparing different models. This comparison is accessible within the Model Playground of the Agent Platform.
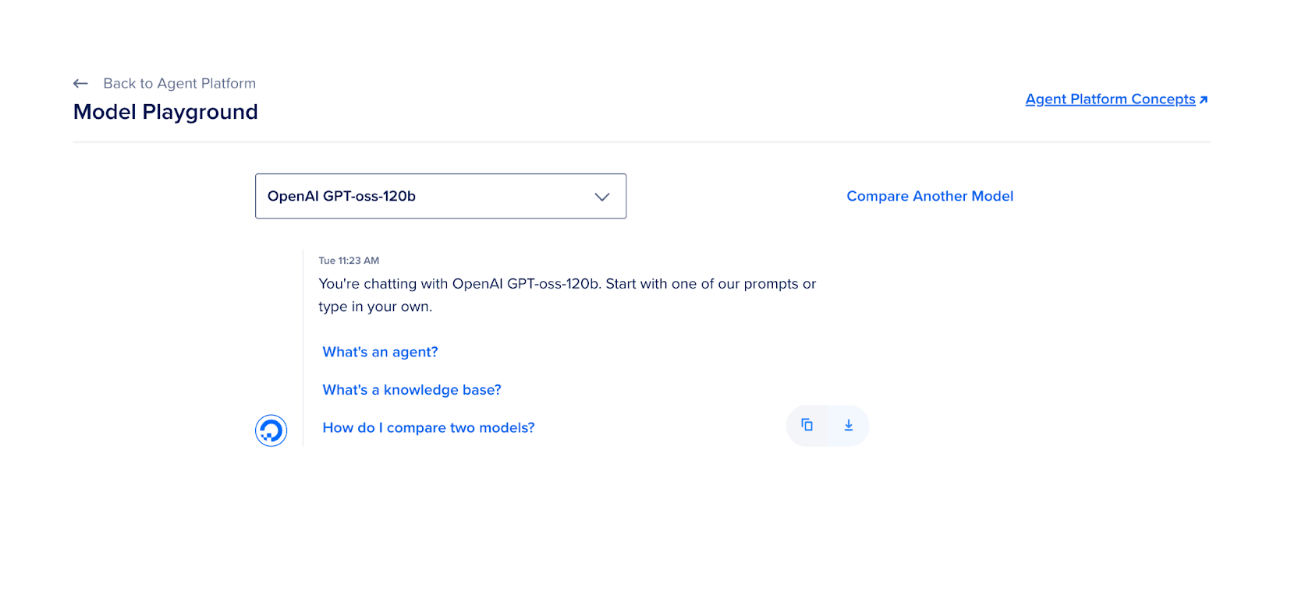
The API key is securely loaded using environment variables. This setup allows you to run inference without managing your own model hosting.
Using the gradient Python SDK for serverless inference
In addition to using the OpenAI-compatible API, you can also interact with serverless inference models through the gradient Python SDK. This method also provides a straightforward way to send prompts to supported models while managing authentication through environment variables.
from gradient import Gradient
from dotenv import load_dotenv
import os
load_dotenv()
client = Gradient(model_access_key=os.getenv("MODEL_ACCESS_KEY"))
models = client.models.list()
print("Available models:")
for model in models.data:
print(f" - {model.id}")
from gradient import Gradient
from dotenv import load_dotenv
import os
load_dotenv()
client = Gradient(model_access_key=os.getenv("MODEL_ACCESS_KEY"))
resp = client.chat.completions.create(
model="llama3-8b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
],
)
print(resp.choices[0].message.content)
This makes it convenient for building applications, automation pipelines, or experimentation workflows that rely on serverless inference.
Important Functions
The functions generate_seo_brief and generate_article are responsible for interacting with the LLM.
- generate_seo_brief: Sends a topic to the model and generates structured SEO data, including title, keywords, and outline.
- generate_article: Uses both the topic and SEO brief to generate a complete, structured article.
- read_topics: Supports both
.csvand.txtfiles to extract topics.
These functions demonstrate how you can perform programmatic LLM inference locally, without any API keys.
File Handling
The helper functions manage input and output:
- read_topics: Reads topics from a
.csvor.txtfile. - save_markdown: Saves each generated article as a Markdown file.
- create_zip: Compresses all generated files into a single ZIP archive.
This ensures that the pipeline produces clean, portable outputs that can be reused or published.
Bulk Processing Logic
The process_file function orchestrates the entire workflow:
This is the core orchestrator:
-
Reads topics
-
Creates a timestamped output folder
-
Loops through each topic:
- Generates SEO brief
- Generates article
- Saves markdown
-
Logs progress for UI display
-
Returns:
- Processing logs
- Downloadable ZIP file
Building the User Interface with Gradio
To make the pipeline accessible, we use Gradio to create a simple web interface.
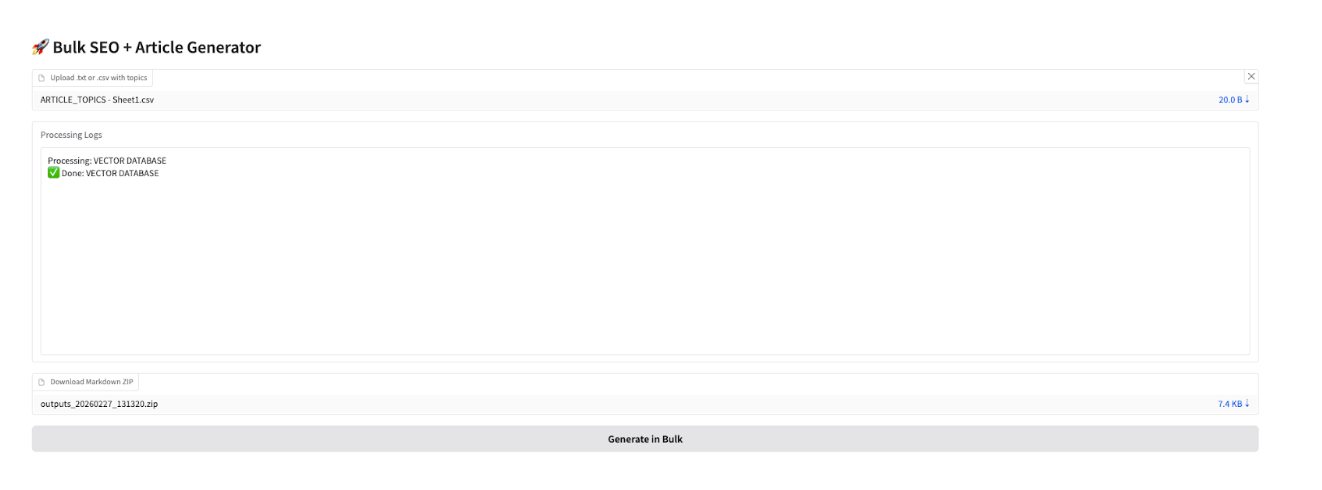
The interface includes:
- File upload for topics
- A button to trigger generation
- A download option for the final ZIP file
This allows even non-developers to use the pipeline with ease.
Running Inference on GPU Droplet
Start the application with:
python app.py
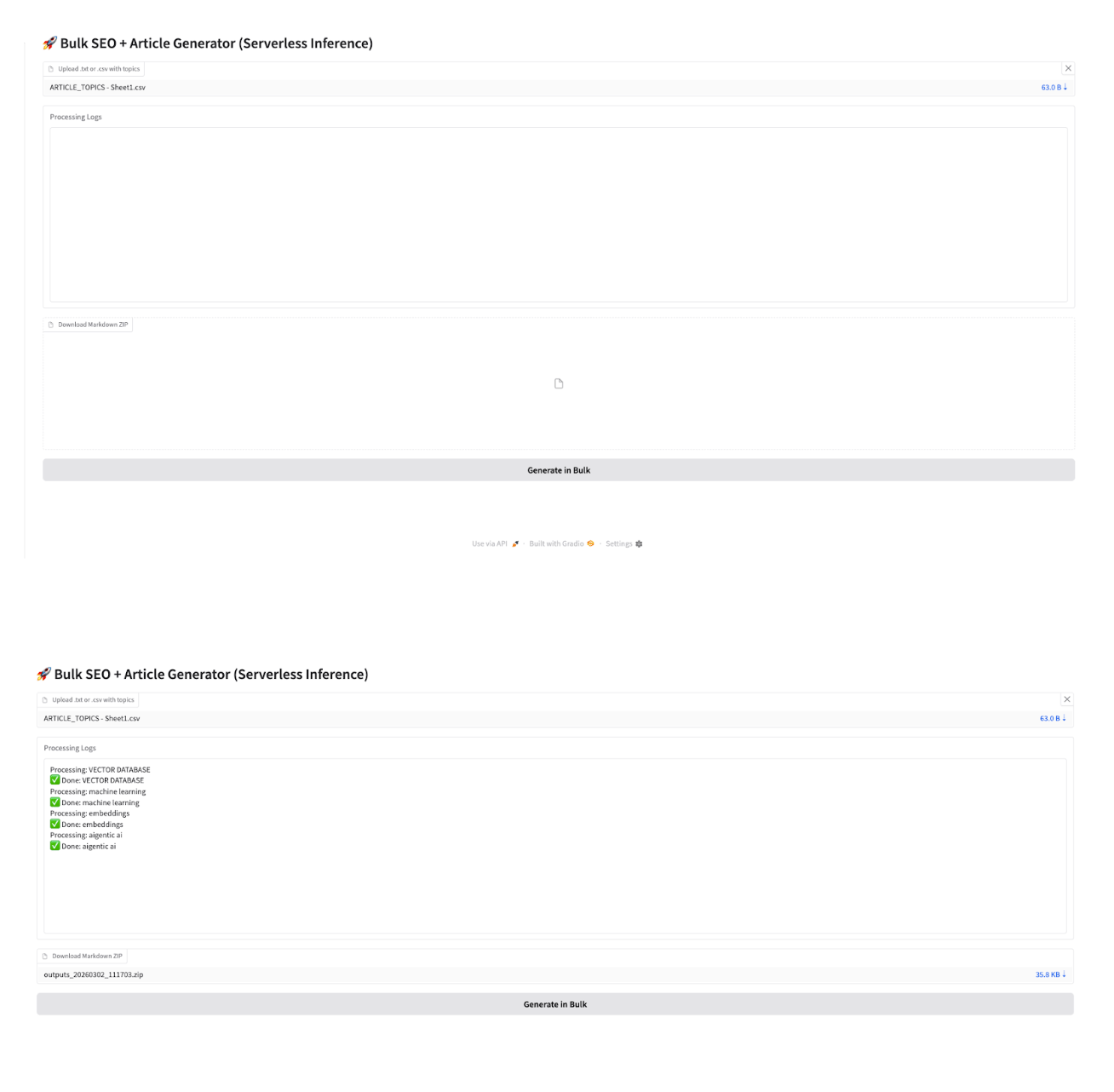
- Upload a
.csvor.txtfile containing all the topics. - Click Generate in Bulk.
- Monitor progress in the logs.
- Download the generated ZIP file. This zip file contains all the markdown files for the article topics.
Running the Pipeline Locally with Ollama
While this article demonstrates the pipeline using DigitalOcean Serverless Inference, the same workflow can also be implemented locally using Ollama. This approach allows you to run open-source large language models directly on your machine without relying on a remote a GPU Droplet.
Step 1: Install Ollama
First, install Ollama on your system. Ollama allows you to run several open-source models locally.
curl -fsSL https://ollama.ai/install.sh | sh
After installation, start the Ollama service and pull a model you want to use for content generation.
ollama pull mistral
You can also choose other models such as llama3, phi, or gemma depending on your requirements.
Step 2: Run the Model Locally
Once the model is downloaded, Ollama automatically exposes a local API endpoint that your Python script can interact with. This endpoint accepts prompts and returns generated text from the selected model.
Step 3: Modify the Pipeline to Use Ollama
Instead of calling a serverless inference API, you can send requests directly to the local Ollama endpoint. Here is a code snippet which can be modified as per the requirement.
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "mistral",
"prompt": "Write a SEO Brief for article title about AI automation",
"stream": False
}
)
print(response.json()["response"])
Project Structure
Here is how the project is organized to keep the code clean, reusable, and easy to maintain. Each folder is responsible for a specific part of the pipeline, making it easier to extend or modify in the future.
bulk-content-generator/
│
├── app.py
├── main.py
│
├── config/
│ └── settings.py
│
├── services/
│ ├── llm.py
│ └── pipeline.py
│
├── utils/
│ ├── file_handler.py
│ └── zip_utils.py
│
├── data/
│ └── sample_topics.csv
│
├── outputs/
│
├── .env
├── .gitignore
├── requirements.txt
└── README.md
Use Cases
This pipeline is highly flexible and can be applied across a variety of real-world scenarios. For SEO content generation at scale, it enables teams to generate hundreds of blog posts from a simple list of topics, automatically creating both SEO briefs and full-length articles, thus making it ideal for content teams, bloggers, and marketing agencies looking to build niche websites quickly.
Additionally, in the e-commerce space, this pipeline can be used to generate product descriptions in bulk, create category pages, and maintain a consistent tone and structure across large product catalogs, significantly reducing manual effort while improving content consistency.
Future Enhancements
This pipeline provides a solid foundation for bulk content generation, but it can be further improved to make it more scalable and production-ready.
- Implement parallel processing to speed up bulk generation for large topic lists.
- Integrate a database (e.g., PostgreSQL) to store generated briefs and articles.
- Enable custom prompt templates for different content types (blogs, product pages, social posts).
- Build a content quality scoring system (readability, SEO score, keyword density).
- Integrate plagiarism detection and AI content detection tools.
- Add direct publishing to CMS platforms like WordPress or Webflow.
- Support multilingual content generation for global audiences.
- Implement user authentication and dashboards for managing projects.
- Add scheduling to automate content generation at specific intervals.
- Enable image generation and automatic insertion into articles.
- Convert the pipeline into a deployable application.
FAQ’s
What is bulk inference in simple terms?
Bulk inference means running an AI model on many inputs at once instead of one by one. It allows you to process a list of topics or prompts automatically. This makes the workflow much faster and more efficient. It is especially useful when you need to generate content at scale.
Do I need a GPU to run this pipeline?
No, you can run this pipeline on a CPU or locally as well. However, using a GPU will significantly speed up the process. This is especially important when working with large batches of topics. A GPU helps reduce waiting time and improves performance.
Can I use a different LLM instead of Llama 3?
Yes, you can use any LLM that supports API-based inference. The pipeline is flexible and allows you to switch models easily. You just need to update the model name and API configuration. This makes it easy to experiment with different models.
What file formats are supported for input topics?
The pipeline supports both .csv and .txt files. In a CSV file, topics are usually read from the first column. In a TXT file, each line is treated as a separate topic. This makes it simple to prepare and upload input data.
How are the generated articles stored?
Each article is saved as a Markdown (.md) file. The file includes the topic, SEO brief, and the full article content. All files are organized inside a folder for easy access. At the end, everything is compressed into a ZIP file for download.
Can I customize the content generation?
Yes, you can customize the prompts used for both SEO briefs and articles. This allows you to control tone, structure, and style. You can also modify the code to support different content types. This makes the pipeline highly flexible for different use cases.
Conclusion
This article demonstrates how you can transform content creation into a fully automated and scalable workflow using Serverless Inference. By combining SEO brief generation with article writing, the pipeline ensures that every piece of content is both structured and optimized from the start. The use of a simple, modular architecture makes it easy to understand, extend, and adapt for different use cases such as blogging, marketing, or e-commerce.
Additionally, integrating this pipeline with a GPU-enabled droplet significantly improves performance, allowing you to handle large batches efficiently. Overall, this approach not only saves time but also enables you to produce high-quality content consistently at scale.
As you build on this foundation, you can enhance the pipeline with features like parallel processing, model selection, or direct CMS publishing, turning it into a powerful production-ready system for AI-driven content generation.
Resources
- Build and Deploy Apps on DigitalOcean App Platform with Custom Domain
- How to use serverless inference on the DigitalOcean AI Platform
- VS Code + Claude Code on DigitalOcean Droplets
- Setting Up the GPU Droplet Environment for AI/ML Coding - Jupyter Labs
- Serverless inference with the DigitalOcean AI Platform
- Git repo seo-content-pipeline-automation
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
This was a practical example of using AI beyond simple prompt calls and turning it into an actual production-style workflow. I liked that the tutorial focused on building a complete pipeline, topic input, SEO brief generation, article creation, file handling, and packaging outputs, rather than treating content generation as a one-step process. Using serverless inference also makes the setup more flexible because you can scale usage without managing model infrastructure directly. Overall, this is a solid foundation for moving from manual content creation into a repeatable AI content pipeline.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
