By Adrien Payong and Shaoni Mukherjee

Large‑language‑model deployment has evolved from research experiments into production‑scale chatbots, AI‑powered search engines, and enterprise‑class assistants. While model accuracy continues to improve thanks to engineering advances in transformer architecture, business challenges revolve around cost, latency, and scale. GPU failure is rare due to insufficient FLOPs; most limitations are from memory bandwidth and the increasing memory footprint of attention states and growing context. Attention context windows are increasing rapidly towards thousands or even millions of tokens. This makes naive inference pipelines struggle to keep up. A critical technique for mitigating redundant computation is key‑value (KV) caching, which stores intermediate attention states rather than recomputing them for every token.
This article breaks down how KV caching works internally, why inference is memory‑bound, and how modern engines exploit caching, paging, and batching to slash inference costs. We’ll also contrast KV caching with prefix/prompt caching and discuss design trade‑offs.
Key Takeaways
- KV caching reduces redundant computation during LLM decoding. Instead of recomputing key and value tensors for all previous tokens at every generation step, the model stores and reuses them.
- LLM inference is often limited by memory bandwidth, not only computation. Prefill is usually compute-heavy, while decoding is memory-heavy because each new token requires access to model weights and KV-cache blocks.
- KV cache memory grows linearly with sequence length and batch size. Long-context workloads and large batches can make the KV cache memory rival or exceed model weight memory.
- Modern serving systems reduce KV-cache waste through paged attention, continuous batching, prefix caching, quantization, eviction, and offloading. These techniques improve GPU utilization and reduce infrastructure cost.
- KV caching is powerful but not always equally effective. Short sequences, small models, highly dynamic prompts, sliding-window attention, memory limits, and slow offloading tiers can reduce its benefits.
What Is KV Caching?
In transformer models, each output token can attend to all previously generated tokens through multi‑head attention. At each decoding step, queries (Q), keys (K), and values (V) are computed for each token. Without caching, then computing K and V for all previous tokens must be done N times to generate N tokens. As a result, the runtime and memory cost of attention scale quadratically with sequence length.
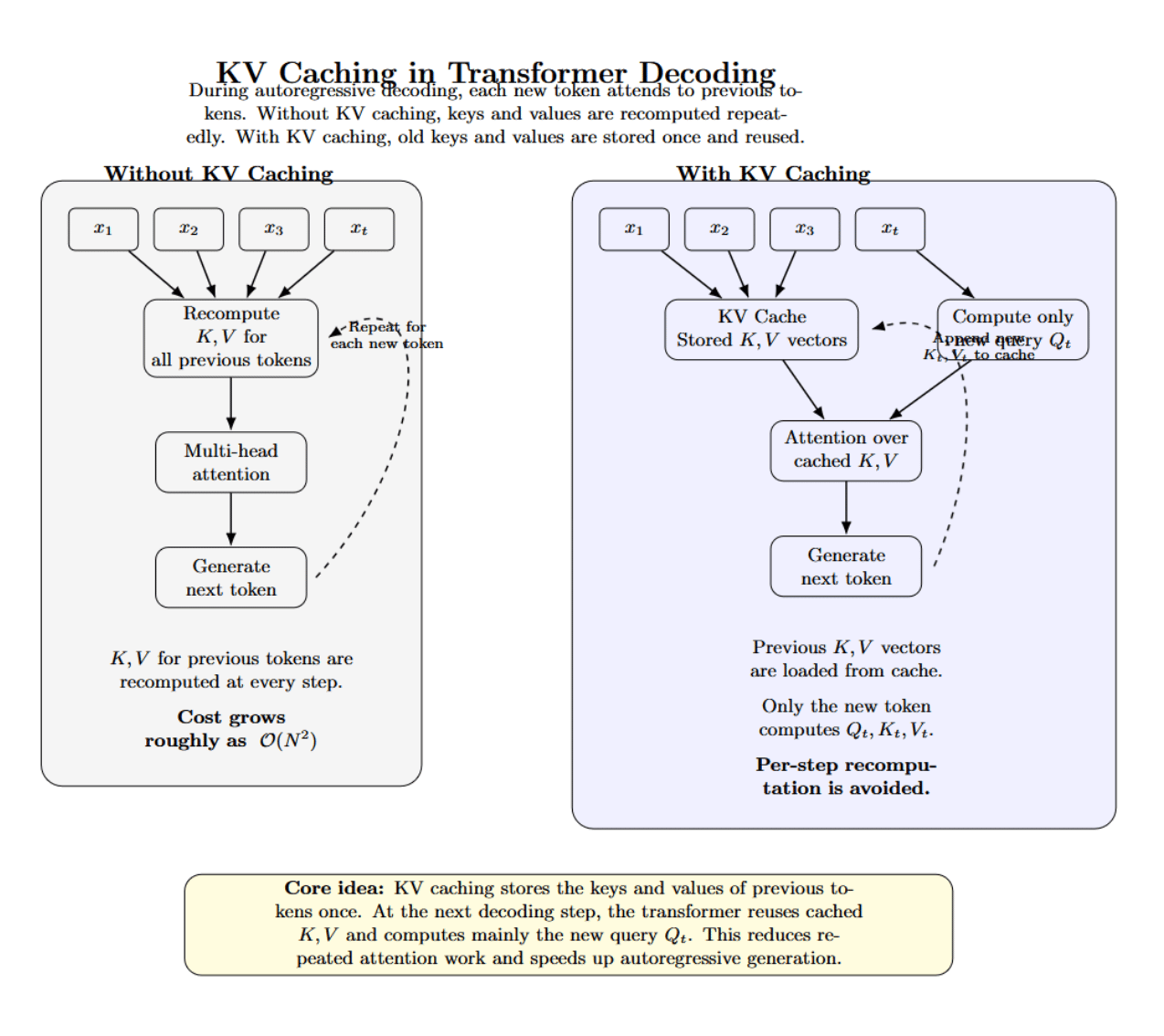
KV caching alleviates this by storing the K and V vectors for each token after they are computed and reusing those vectors at every subsequent decoding step. Rather than recomputing K and V during each iteration, they are simply loaded from the cache. The model only needs to compute the query vector for the new token.
Why LLM Inference Gets Expensive at Scale
LLM inference becomes expensive at scale because serving a model involves more than raw compute. It is also about memory bandwidth, cache growth, batching efficiency, and how many useful tokens each GPU can produce per second.
Memory‑Bound vs Compute‑Bound
Intuitively, you might expect that upgrading to a GPU with higher FLOP throughput would always make inference faster, but large portions of LLM decoding are memory-bound and not compute-bound. While decoding, the model generates one token at a time. For each token generated, the model needs to read the model weights once, and the KV cache. However, there’s relatively little computation done per token.
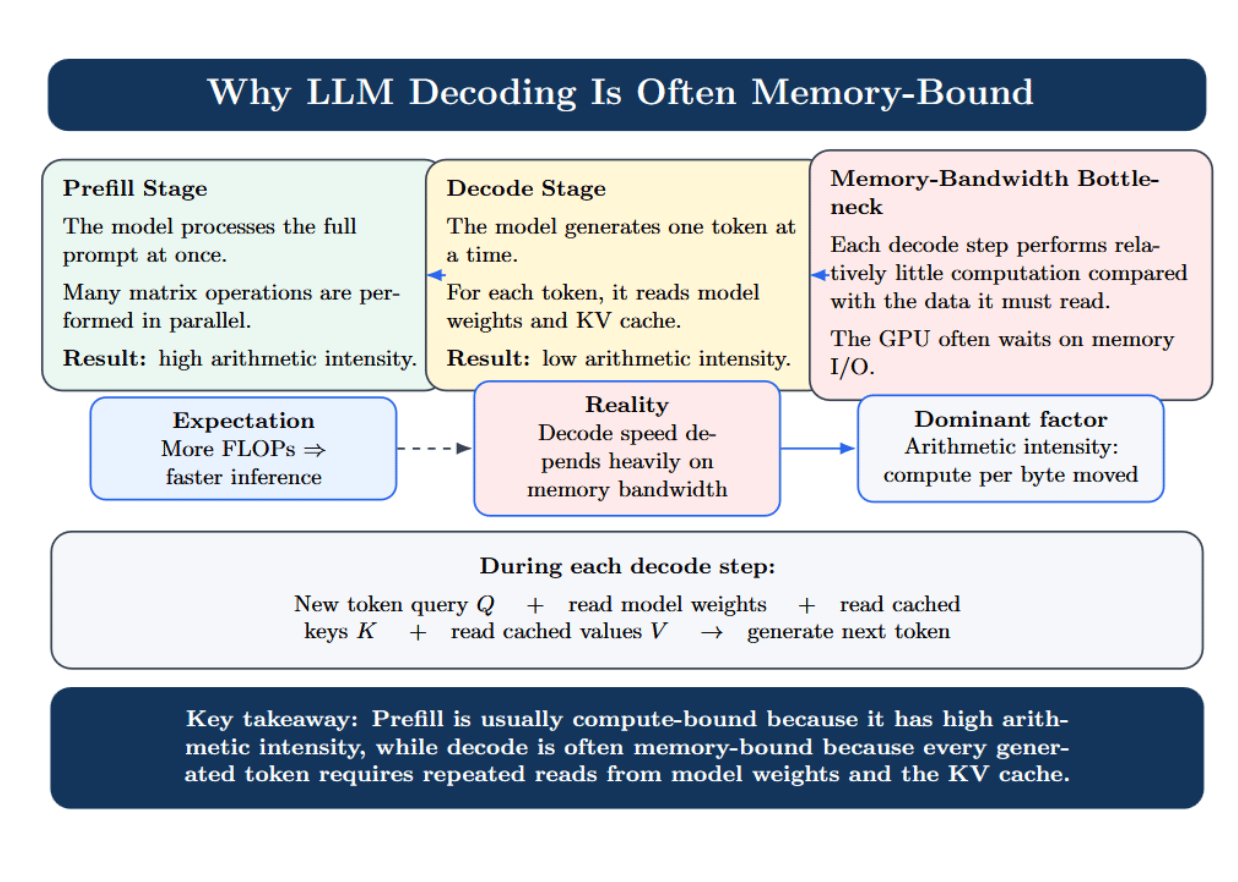
Therefore, arithmetic intensity (amount of computation performed per byte read/written) becomes the dominant factor. Prefill generally has high arithmetic intensity, so GPUs are compute-bound for that stage; decode arithmetic intensity is much lower, so time is spent waiting on memory. Empirically, you’ll often see this as high memory traffic and low compute utilization. Upgrading GPUs will only help you so much if the bottleneck is really memory bandwidth.
Growth of Cache and Context
KV cache grows with context windows, and can easily become the largest GPU memory consumer. For every new token, cached key and value tensors are added to every layer of the model’s attention mechanism.
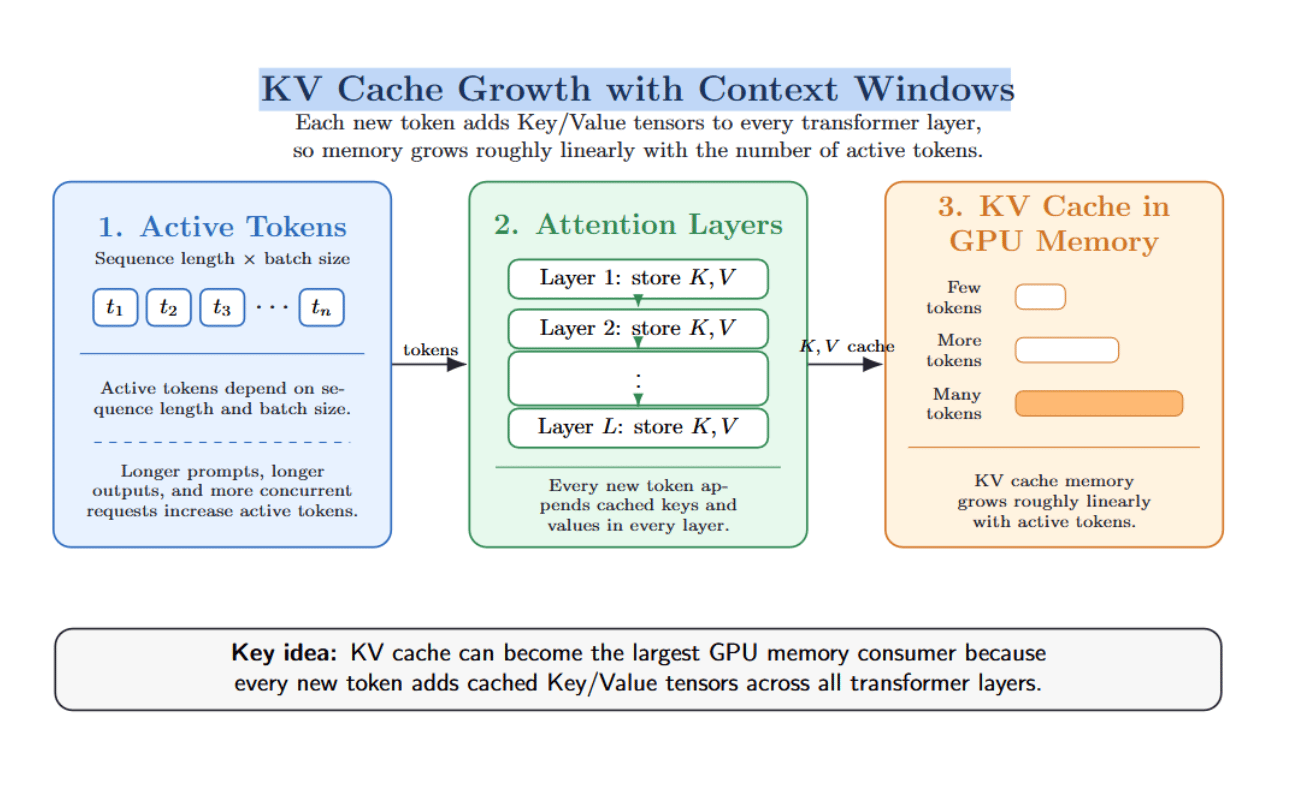
The amount of cache used grows roughly linearly with the number of “active” tokens, including sequence length and batch size. For Llama-2-7B in half-precision, Pierre Lienhart estimates the KV cache requires about 0.5 MB per token. In this case, 28k total active tokens will correspond to roughly ~14 GB of KV-cache memory(28,000 tokens×0.5 MB/token≈14,000 MB≈14 GB), which is on par with the model’s FP16 weights. KV cache growth, therefore, becomes as important as raw model size when considering whether an LLM workload will fit in GPU memory and how efficiently it will run.
Serving Costs and Economics
Inference computation and memory use determine inference cost. Prompt tokens primarily affect prefill compute and KV- cache creation cost. Generated tokens incur repeated decode compute and place repeated pressure on memory bandwidth, as they continue to use the KV-cache.
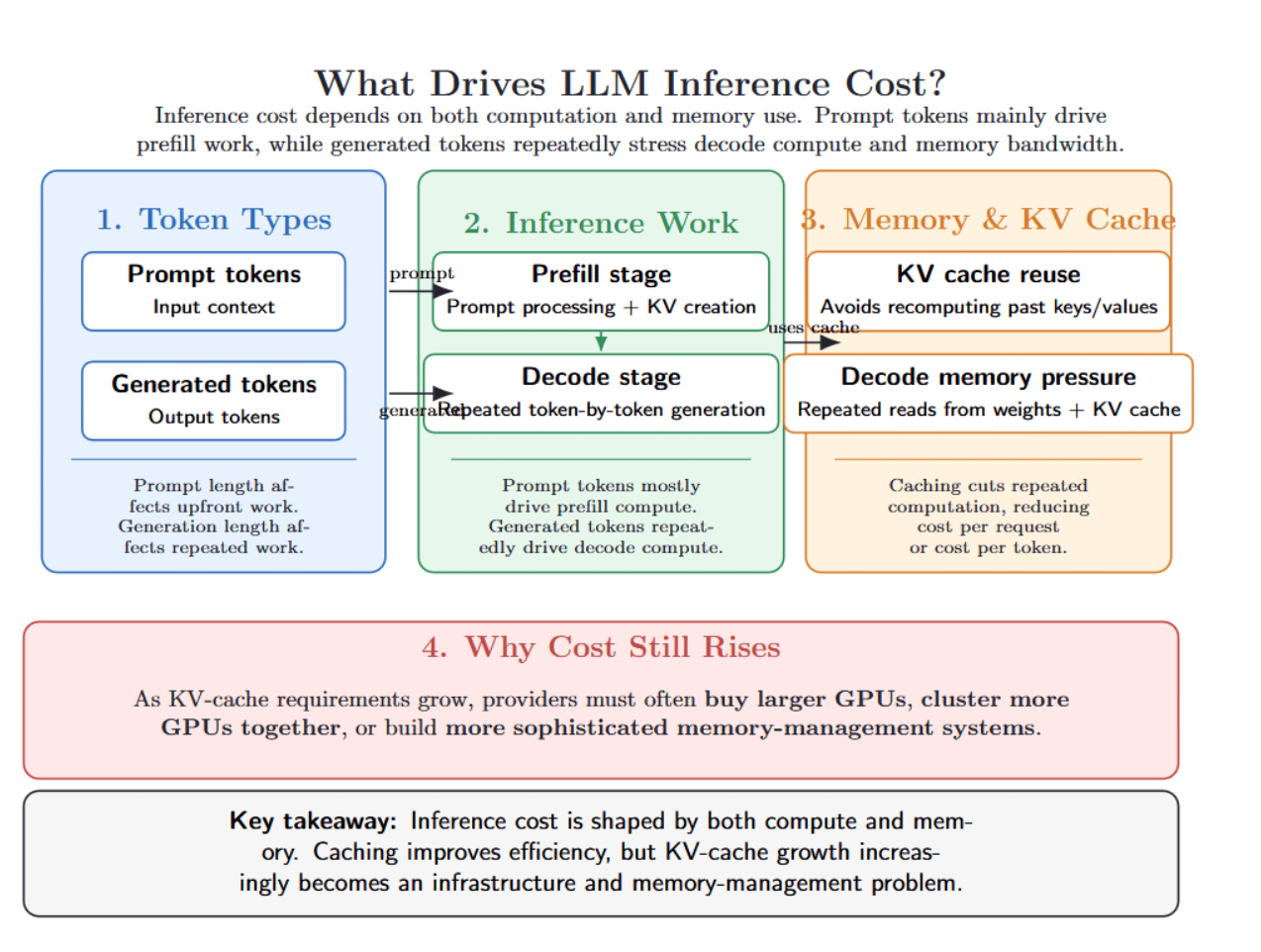
Caching alleviates this repeated computation, reducing either cost per request or cost per token. However, growth in KV- cache requirements will continue to force providers to buy larger GPUs, cluster more GPUs together, or build more sophisticated memory management systems.
How KV Caching Works
At a high level, KV caching works like this:
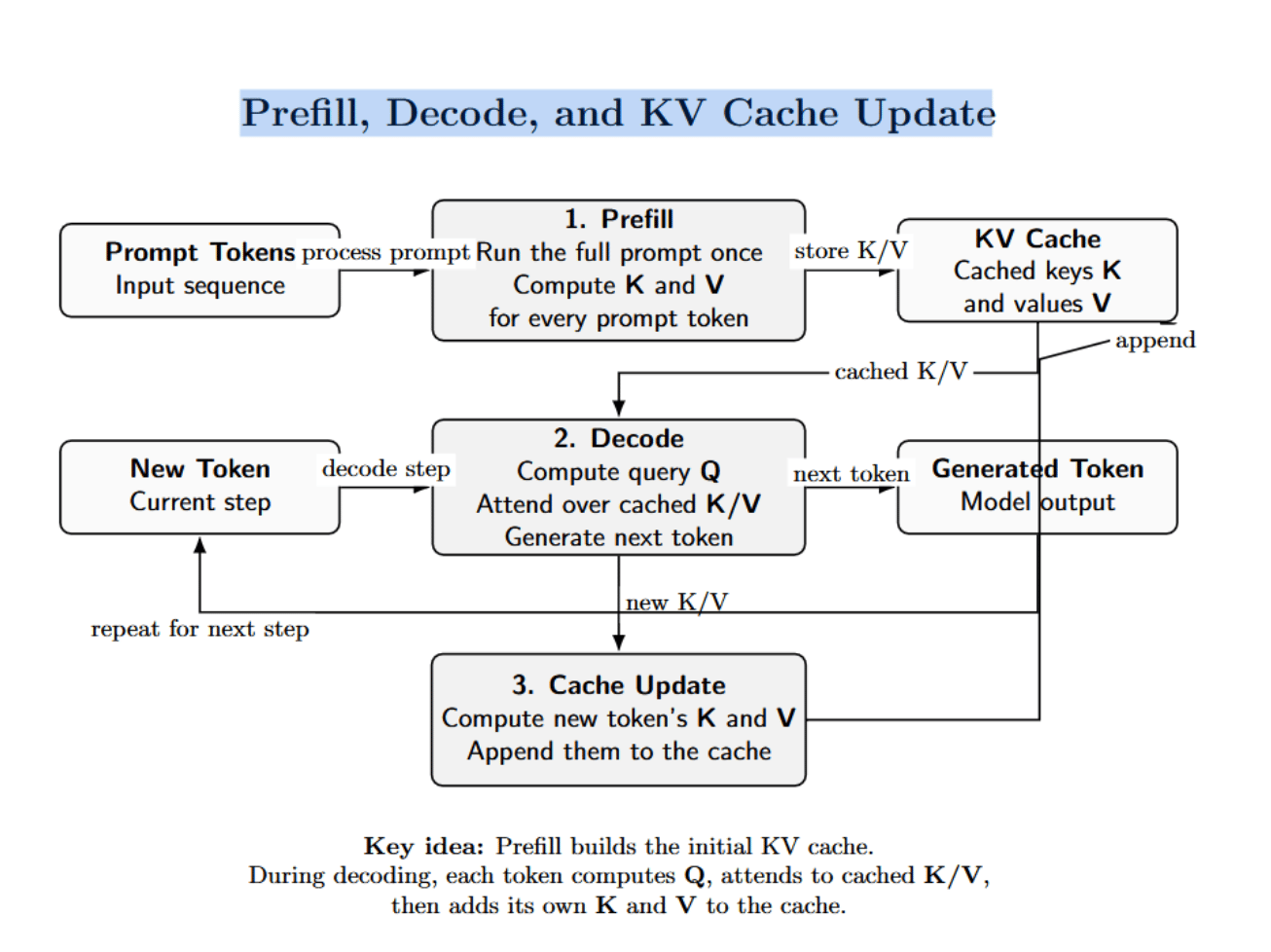
- Prefill: the model runs the prompt through once and computes per-layer, per-head key (K) and value (V) vectors for each token in the prompt; it stores those K/V tensors in a cache so it doesn’t have to recompute them later.
- Decode: For every decoding step, the model computes the query (Q) for the new token and uses Q to attend over the cached keys and values (the cached Ks are used to compute attention weights, and the cached Vs provide the attended outputs). The model also computes the new token’s K and V for caching after generation.
- Cache update: After generating a token, its K and V tensors are added to the cache for subsequent decoding steps.
Memory Footprint Calculation
The KV cache memory can be approximated as:
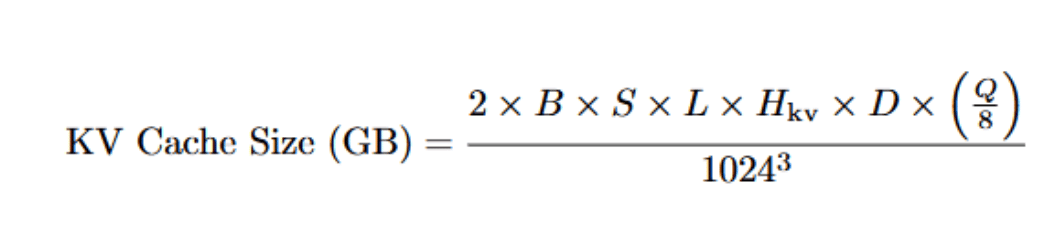
where B is batch size, S is sequence length, L is the number of layers, Hkv is the number of key/value heads, D is the head dimension, and Q is the number of bits per cache element. The factor of 2 accounts for the storage of both keys and value tensors. From this formula, we can observe a linear growth in batch size and sequence length.
Real Performance Gains from KV Caching
- 5.2× faster generation: Reported generation speedup of 5.21× times faster from a Hugging Face community benchmark run on a T4 GPU showed results of 11.7 seconds (with KV caching) versus 1 minute 1 second (without KV caching).
- Up to 5× faster TTFT with early reuse: NVIDIA TensorRT-LLM mentions that early KV cache reuse can improve TTFT by up to 5× for workloads that allow shared system prompts. NVIDIA separately mentions up to 14× faster TTFT on H100 systems using CPU offload to reuse KV cache.
- Up to 23× throughput improvement: Anyscale states throughput improvement up to 23× with continuous batching and vLLM-specific memory optimizations.
- 2–4× throughput via PagedAttention: According to the vLLM/PagedAttention paper, there is a 2–4× throughput improvement over prior serving systems at similar latency. vLLM has <4% KV- cache memory waste, compared to much higher waste for traditional contiguous allocation systems.
- Up to 50% KV-cache memory reduction with NVFP4: NVIDIA states that NVFP4-accelerated KV cache quantization can reduce KV-cache memory footprint by up to 50% (versus FP8) on their Blackwell GPUs, with reported accuracy losses of <1% on selected benchmarks.
KV Caching vs Prompt Caching
KV caching is scoped to the decode stage of a single request. Without it, the K/V would need to be recomputed for all previous tokens on each new token, leading to quadratic cost. In comparison, prompt caching (sometimes referred to as prefix caching) is across multiple requests. It stores the KV cache for a static prefix (i.e., system prompt + tool definitions + reference documents) so that future requests can bypass the prefill stage and continue computing from that cached prefix onwards.
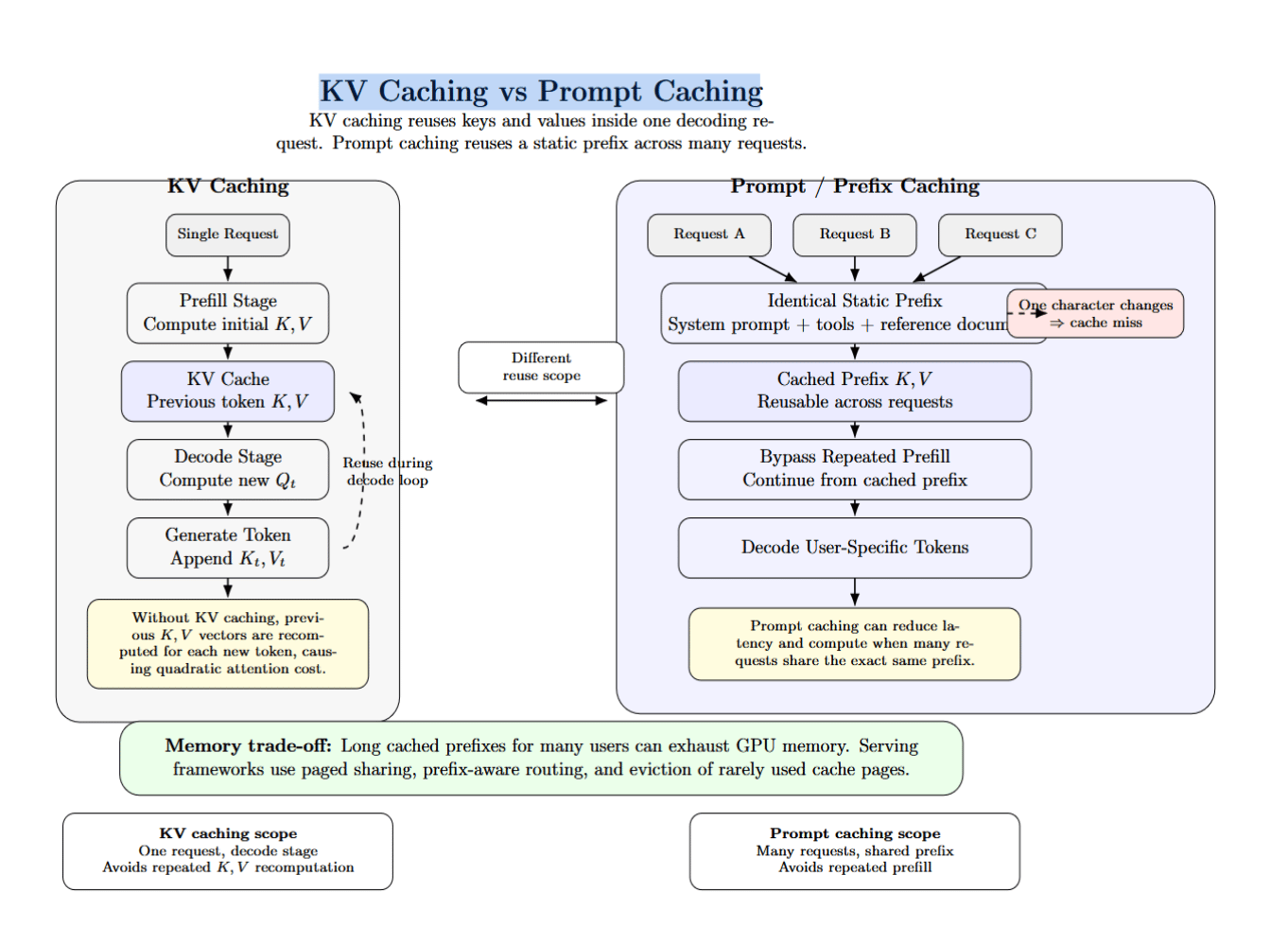
Prompt caching only works for identical prefixes – even a single character difference results in a cache miss. Prompt caching can reduce compute and latency by an order of magnitude when conditions are met.
Infrastructure Challenges and Trade‑Offs
Despite its benefits, KV caching introduces operational challenges:

- Memory footprint and fragmentation: KV cache sizes can grow large enough to exceed model weights, particularly on long-context and high-batch workloads. Using contiguous allocation can lead to significant GPU memory waste due to fragmentation and over-reservation. PagedAttention limits memory waste by storing KV cache in fixed-sized, non-contiguous blocks that are allocated on demand and released when sequences complete. vLLM claims memory waste under 4%, at the cost of complex block tables, cache management, and scheduling.
- Cache eviction: Decisions about which cached tokens to retain when memory is constrained must be made by the serving engine. Eviction policies used by previous work include sliding-window attention, attention-score-based eviction, and layer-aware/entropy-guided allocation of cache budget. Methods like H2O and Scissorhands demonstrate that keeping only recent and important tokens can reduce KV-cache memory usage by roughly 2–5× on benchmarked tasks with little or no quality loss.
- Memory-bandwidth bottleneck: Memory bandwidth may also be a limiting factor in throughput, even when there is sufficient memory capacity. Each decoding step must read model weights and corresponding blocks from the KV cache, so generation speed often depends more on memory I/O than raw compute. Prefill/decode architectures alleviate this memory bandwidth pressure by colocating compute-intensive prefill work and memory-bound decoding work on separate workers, transferring KV cache between them over fast RDMA connections.
- Idle sessions: Chat, RAG, and agent workflows allow users to take pauses between turns. Retaining inactive KV caches in GPU memory consumes precious capacity. KV cache offloading dynamically moves idle or reusable KV blocks to CPU memory, disk, or remote storage and reloads them on demand. LMCache enables multi-tier KV cache reuse across serving instances and reports 3×–10× delay savings in multi-round QA and RAG workloads.
- Granularity and reuse: Early reuse works best when many requests share a common prefix (think system prompt, tool definition, or document prefix). TensorRT-LLM’s flexible block sizing splits the cache into smaller blocks, allowing for better reuse across partially overlapping prompts. NVIDIA reports up to 7% TTFT improvement on LLAMA70B when reducing the block size of 64 tokens to 8 tokens. However, smaller blocks increase metadata overhead and complexity.
vLLM, Paged Attention, and Continuous Batching
Modern LLM serving stacks optimize KV caching through three approaches: improved memory layout, improved batching, and improved hardware-aware kernels.
vLLM and Paged Attention
vLLM is an open‑source inference engine for high‑throughput LLM serving. Paged attention is a caching technique introduced by vLLM that treats the KV cache like an operating system’s virtual memory.
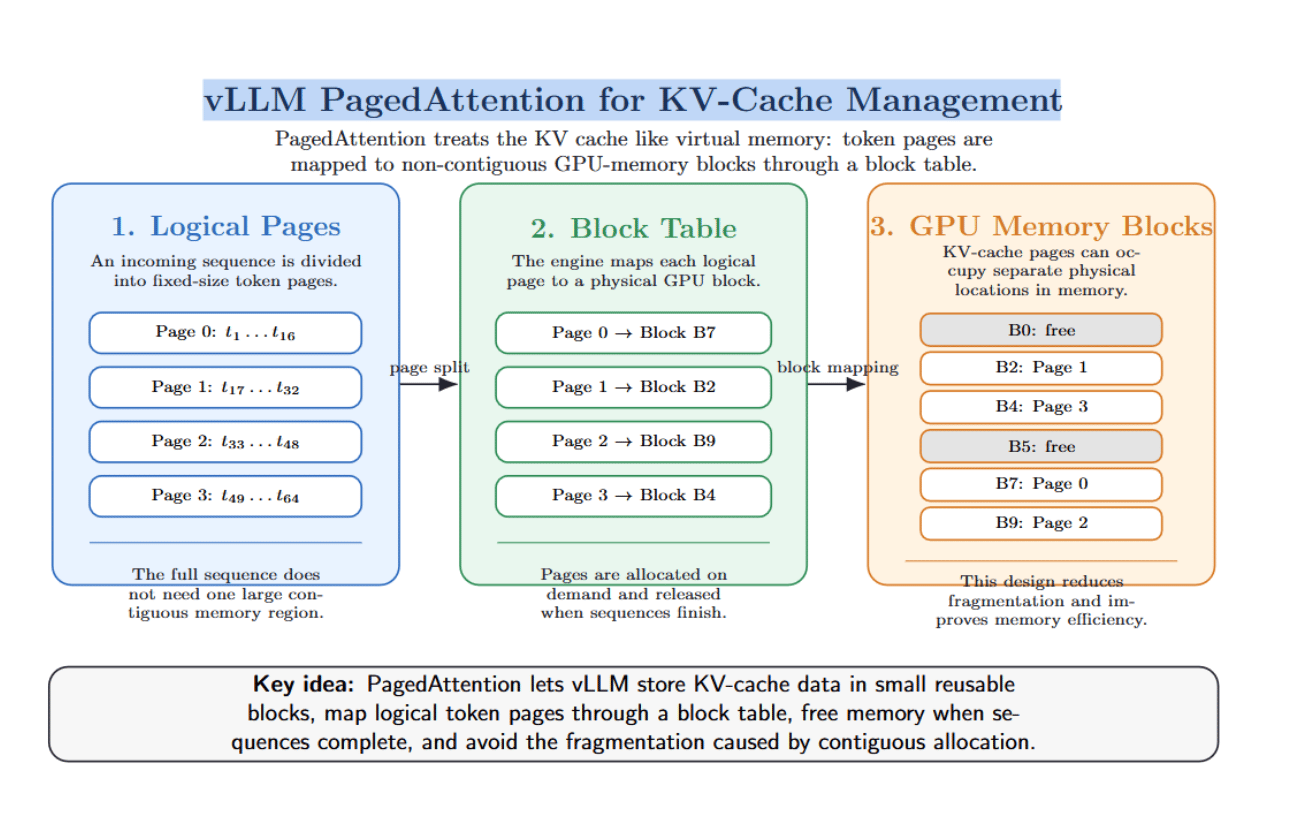
Rather than reserving a contiguous memory region for each incoming sequence, vLLM partitions its cache into pages (e.g., blocks of 16 tokens). It maintains a block table that maps logical token positions to their physical location in GPU memory. This allows the inference engine to allocate pages on demand, free pages when sequences complete, and eliminates memory fragmentation.
Continuous Batching
Continuous batching is another crucial optimization used for LLM serving. You may have also heard it referred to as iteration-level scheduling. In this batching technique, the server updates the batch at every decoding step rather than waiting for an entire batch to finish processing.

Static batching, where a static batch of requests enters the GPU together, struggles with inputs that generate different numbers of tokens. If a batch generates requests that finish early and others that continue generating longer sequences, the server must wait for the longest request to finish before starting the next batch. This results in GPU capacity being wasted.
Continuous batching avoids this waste. When a request in a batch finishes, the serving engine can immediately insert a new request into the open slot. This allows the GPU to be used more frequently and reduces idle time.
When KV Caching Is Less Effective
Despite its advantages, KV caching does not always produce the same performance gains.
- Short sequences or small models: When sequence length is short, batch size is small, or the model is lightweight, the amount of recomputation avoided may be limited. KV caching can still help. However, in that case, the gain is often smaller than in long-context generation.
- Memory-constrained environments: For models served on GPUs with limited memory, the KV cache is competing with model weights and other active requests for memory. High eviction, recomputation, or offloading can reduce the performance benefit. Quantization and offloading can reduce memory usage, but do not remove the KV cache’s memory budget.
- Highly dynamic prompts: This impacts prefix caching rather than per-request KV caching. If early tokens change frequently, prefix reuse across requests is unlikely.
- Models with local or sliding-window attention: Models like Mistral-7B that use local/sliding-window attention patterns utilize rolling cache buffers. When using this type of architecture, storing K/V tensors far outside the attention window may provide little direct benefit(though the older tokens themselves can still influence later layers indirectly).
- Slow storage tiers: KV-cache offloading only provides benefit when fetching cached data from CPU RAM/disk or remote storage is faster or cheaper than recomputing it. If the storage tier is slow or saturated, offloading can increase latency rather than reducing it.
FAQ
1. What is KV caching in LLM inference?
KV caching is a technique that stores the key and value tensors produced by transformer attention layers. During decoding, the model reuses these cached tensors instead of recomputing them for every previous token.
2. Why does KV caching reduce inference cost?
It reduces repeated computation during token generation. This can lower latency, increase throughput, and allow the same GPU to serve more requests. However, the cache itself consumes GPU memory, so efficient cache management is still necessary.
3. Why can KV cache become a memory problem?
Each new token adds key and value tensors across multiple layers. As context length and batch size increase, the cache grows linearly. In long-context workloads, the KV cache can become as large as, or larger than, the model weights.
4. What is the difference between KV caching and prompt caching?
KV caching works inside a single request during decoding. Prompt caching, also called prefix caching, reuses cached KV states across multiple requests that share the exact same prefix, such as a system prompt or reference document.
5. Which techniques improve KV-cache efficiency?
Important techniques include paged attention, continuous batching, prefix caching, cache quantization, cache eviction, and cache offloading. Frameworks such as vLLM, TensorRT-LLM, and LMCache use these ideas to improve throughput and reduce memory waste.
Conclusion
LLM inference is quickly becoming a memory-engineering problem, rather than solely a compute‑intensive one. Longer context lengths and model sizes mean that cost‑effective inference will require more than faster GPUs: it will need smarter memory usage. KV caching is a critical component of this new paradigm. By caching and reusing attention states, caching can slash redundant computation and reduce latency. However, this introduces additional constraints: caches grow linearly with sequence length and can exceed model weights! To balance computation and memory, cutting‑edge engines will use a number of techniques, including paged allocation, to prevent memory fragmentation. They also use continuous batching to alternate between compute‑bound and memory‑bound phases, and prompt caching to reuse common static prefixes. Finally, they apply quantization to shrink the cache footprint, cache eviction to discard tokens with low importance, and finally, offloading to other tiers of memory.
These innovations enable us to serve long‑context models efficiently, opening up new application scenarios and user experiences. In the future, hybrid memory architectures, adaptive caching strategies, KV-cache quantization, cache offloading, sparse attention, sliding-window attention, and hardware–software co-design will continue to push the boundaries of efficient LLM inference. Infrastructure and infrastructure teams building generative AI services should understand KV caching and trade‑offs to build scalable, cost‑efficient systems.
DigitalOcean’s related resources on Inference as a Service, What is AI Inference, GPU Inference Solutions, Monitoring GPU Utilization, and Finding the Optimal Batch Size explore these topics further and offer practical guidance for deploying LLMs at scale.
References
- LLM Inference Optimization 101
- LLM Inference Series: 4. KV caching, a deeper look
- KV Caching Explained: Optimizing Transformer Inference Efficiency
- KV Cache Optimization: Memory Efficiency for Production LLMs
- Why LLM Inference Is Memory-Bound (Not Compute-Bound)
- Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 KV Cache
- How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
