Every time an AI application generates a response or flags a fraudulent transaction, it’s running inference. A trained model takes in new data and passes it through layers of learned parameters to produce an output. This happens in milliseconds and often millions of times a day. But that speed comes at a cost. Each inference request demands GPU compute and memory bandwidth that scale with model size and traffic volume. Latency spikes frustrate users. GPU bills grow faster than expected. Plus, scaling workloads across regions introduces infrastructure complexity that most teams don’t anticipate. According to our DigitalOcean’s 2026 Currents research report, inference is now consuming about 76-100% of AI budgets in many organizations.
If you’re deploying machine learning models or AI workflows, what matters most isn’t just how your model learns. It’s how efficiently it serves predictions in real time. Understanding what AI inference is and what determines its performance can help you make smarter architectural decisions for your next AI project.
Key takeaways:
-
While training develops model intelligence, inference powers applications like fraud detection, LLM chat interfaces, and recommendation systems.
-
As AI budgets shift toward deployment, throughput, cost per request, GPU utilization, and P95/P99 latency are important factors for building AI/ML applications.
-
AI inference environments like cloud, edge, and on-device inference serve different latency, privacy, bandwidth, and scalability needs. Many production systems use a hybrid approach.
-
With DigitalOcean’s GPU Droplets, Bare Metal GPUs, and Gradient™ AI Inference Cloud, you can deploy scalable, cost-efficient inference without hyperscaler complexity.
What is AI inference?
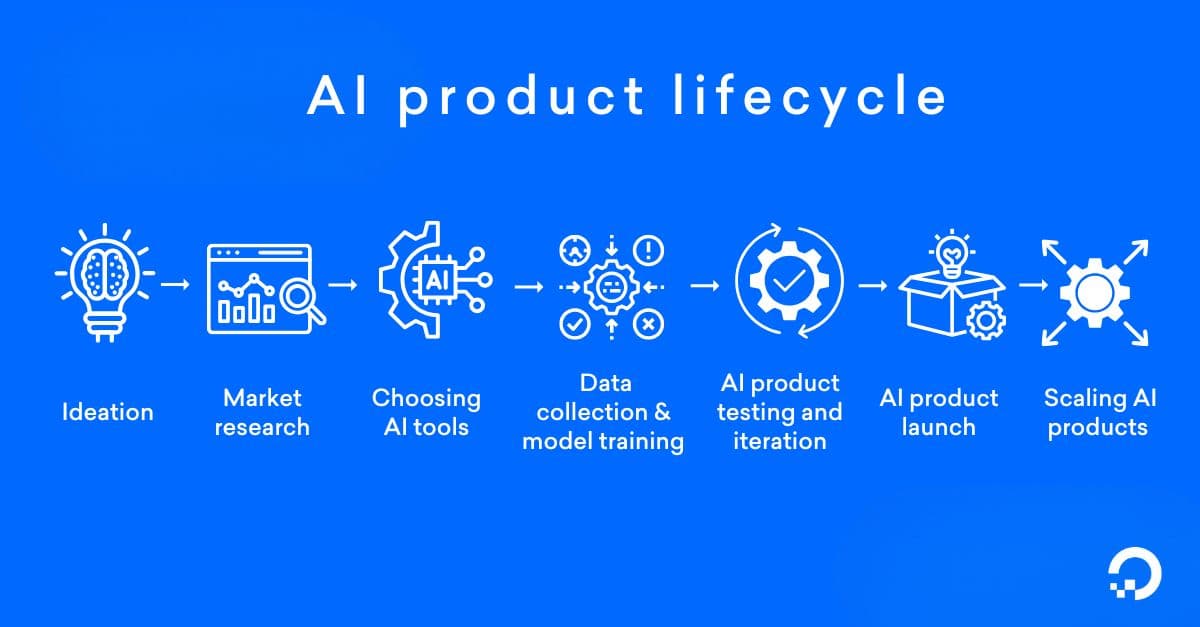
AI inference is the stage of the AI lifecycle where a trained model makes predictions or generates outputs from new data. It’s what powers live applications such as recommendation engines, medical diagnostics, and large language model (LLM) chat interfaces. In your production environments, AI inference determines how fast your users get results, how well your system handles traffic spikes, and how much each prediction costs to serve.
Workato cuts inference costs by 67%:
Running agentic AI at a trillion-workload scale, Workato partnered with DigitalOcean’s agentic inference cloud to optimize long-context LLM inference. By deploying NVIDIA Dynamo, vLLM on DOKS with KV-aware routing, they achieved 67% higher tokens/sec per GPU, and 67% lower model costs using half the GPUs.
What is the difference between training and inference?
Training is how a model learns. You feed it massive datasets, and it iteratively adjusts millions of internal parameters until it can recognize patterns on its own. The model is given input data along with the correct answers (like images with labels or text with expected outputs), and it makes predictions, compares them to the correct answers, and adjusts itself to reduce mistakes. This happens repeatedly over many cycles until the model becomes good at making accurate predictions. This process is compute-heavy but happens once or periodically. Inference is what happens after: the trained model takes in new data it hasn’t seen before and generates a prediction or response in real time.
| Factor | AI training | AI inference |
|---|---|---|
| Purpose | Learn patterns and optimize model accuracy | Generate predictions or outputs from new data |
| Data used | Large labeled datasets (e.g., historical fraud transactions, annotated medical images, sentiment-labeled reviews) | New, unseen input data |
| Output | Updated model weights (final trained model) | Prediction, score, classification, or generated response |
| Compute requirements | Very high (like distributed GPU clusters) | Lower per request but latency-sensitive |
| Time sensitivity | Offline, not user-facing | Real-time or near real-time, user-facing |
| Frequency | Occasional (initial training and retraining) | Continuous, runs on every request |
| Cost structure | High upfront training cost | Ongoing cost per request |
| Optimization focus | Accuracy and loss reduction | Latency, throughput, cost efficiency |
| Example: AI content moderation system | The system is trained on millions of posts labeled as “safe,” “spam,” “hate speech,” or “policy violation.” During training, the model learns patterns in text, tone, keywords, and context by adjusting its internal weights to distinguish harmful content from acceptable content. | When a user submits a new post, the trained model processes the text in real time and assigns probability scores for each content category. Based on these scores, the system automatically publishes, flags, limits visibility, or routes the post for human review. |
Training and inference get lumped together a lot, but they put very different demands on your infrastructure and your budget. Our piece on AI inference vs training breaks down where the money actually goes and what to prioritize when you’re running models in production.
AI inference environments
Inference can run in different locations depending on your application needs, data sensitivity, and performance requirements. It may execute in centralized cloud data centers, closer to users at the edge, or directly on local devices.
Cloud inference environments
Cloud inference environments are the most common setting for production AI inference with scalable compute resources such as GPUs. This environment supports model serving frameworks, monitoring, and integration with APIs and distributed systems.
For example, a team deploying a recommendation engine might follow the workflow below:
-
Run its inference service on DigitalOcean GPU Droplets
-
Deploy APIs using App Platform for API delivery
-
Store metadata in Managed PostgreSQL
-
Persist model artifacts in Spaces
Edge inference environments
Edge inference runs closer to the data source, like in retail stores, factories, or telecom towers, to reduce latency and bandwidth usage. For applications like video analytics, IoT monitoring, processing data locally assures that decisions are made within milliseconds instead of relying on round-trip communication to centralized cloud servers.
In a retail store, a security camera monitors checkout lanes. A small edge device installed on-site runs a computer vision model that detects suspicious behavior, such as someone skipping payment. If flagged, the system alerts store staff instantly. The summary alerts, daily analytics reports are later uploaded for centralized review.
On-device inference
On-device inference runs directly on user hardware such as smartphones, laptops, or embedded systems. It aims to improve privacy, reduce dependency on network connectivity, and for instant responses in applications like voice assistants and biometric authentication.
When a user says a wake phrase like “Hey, assistant”, a neural network model running locally on the device continuously listens for that specific trigger phrase. The audio is processed in real time on the device’s CPU or dedicated AI chip. When the wake word is detected, the system activates and sends the request to the cloud for further processing. In this setup:
-
The trained wake-word detection model is stored on the device.
-
Inference runs continuously on local hardware.
-
Raw audio does not leave the device unless activated.
-
The assistant responds instantly, even without an active internet connection.
How to choose the right AI inference environment
The inference environment you choose will depend on your latency requirements, traffic volume, data sensitivity, and cost constraints. In many production systems, teams use a hybrid approach, combining on-device or edge processing with cloud-based inference.
-
Choose cloud inference: If you need high scalability, centralized model management, and the ability to handle large traffic volumes or GPU-intensive workloads.
-
Choose edge inference: If your application requires low latency near the data source, reduced bandwidth usage, or real-time processing in distributed locations.
-
Choose on-device inference: If privacy is important, offline functionality is required, or instant response times are necessary on user hardware like smartphones.
Confused about edge vs. cloud? Start with one question: how fast does your system need to respond? Read our article on cloud vs. edge computing to understand when and how to use each effectively.
Benefits of AI inference
AI inference determines how quickly your application responds, how reliably it scales, and how efficiently you manage infrastructure costs. When implemented correctly, AI inference gives you measurable performance and operational advantages:
-
Real-time decision making: Inference continuously converts live data into structured outputs with risk scores, classifications, rankings, or generated text. These outputs are fed to applications. For instance, anomaly detection models can flag unusual activity in real time for automated alerts and faster operational responses.
-
Cost-efficient model usage: Once a model is trained, it can serve millions of predictions without retraining. While inference is expensive at scale, techniques like batching and quantization can reduce cost per request when serving high-volume workloads like LLM-driven assistants.
-
Improved user experience: Low-latency inference directly affects how “intelligent” an application feels. If an AI feature responds in 100 milliseconds instead of 2 seconds, users perceive the product as responsive, reliable, and trustworthy.
-
Scalable production deployment: As traffic grows, inference pipelines scale horizontally using distributed infrastructure and autoscaling. A generative AI writing assistant embedded in a SaaS platform may have a few hundred users during normal hours but comfortably accommodate tens of thousands after a product launch.
-
Faster experimentation and model iteration: Inference pipelines make it possible to test and roll out new model versions without retraining from scratch. You can A/B test two models by serving them to different user segments, run shadow deployments to evaluate a new model against live traffic without affecting users, or use canary releases to gradually shift traffic to a new version before full rollout.
Run generative AI models instantly, no servers required. Access multiple models with a single API key, switch providers, and keep your inference workloads running. See how to deploy Fal image and audio generation models on DigitalOcean’s Gradient AI platform using simple Python calls in a Streamlit app.
Challenges of inference
When models meet production workloads, the complexity of AI inference comes into the picture. When you move your application from experimentation to large-scale deployment, you must evaluate cost, performance, and infrastructure constraints.
-
High cost of inference at scale: According to DigitalOcean’s 2026 Currents research report, 49% of respondents identified the high cost of inference as a top challenge. Sustained GPU usage, token-based pricing, and unpredictable traffic patterns contribute to these escalating costs.
-
Latency sensitivity in production workloads: Real-time applications require consistent low-latency responses under variable traffic. Performance bottlenecks in model serving, networking, or hardware provisioning might degrade user experience and system reliability.
-
Infrastructure complexity and orchestration overhead: Many teams rely on multiple tools and APIs to run inference, increasing operational complexity. Deployment orchestration, autoscaling configuration, and observability in distributed systems require specialized expertise in GPU scheduling and load balancing.
-
Reliability and production concerns: Inference pipelines must remain stable under load while maintaining output consistency. If GPU inference nodes handling rendering assistance crash under high concurrency, active video editing sessions may fail, or previews may freeze.
Want to scale from generic GPUs to optimized inference cloud? DigitalOcean partnered with Character.AI and AMD to reduce inference costs by 50%, scaled to ~2X QPS, and delivered ~91% higher performance vs standard GPU setups.
Types of AI inference
AI inference is classified based on how and when predictions are generated. Some systems respond instantly to user inputs, while others process large volumes of data periodically or continuously as events occur. The distinction lies in:
-
Request timing: When predictions are generated: instantly per request, at scheduled intervals, or continuously as data arrives.
-
Data flow pattern: How input data moves through the system: single request-response, bulk dataset processing, or event-driven streaming.
-
Responsiveness requirements: The acceptable response time for the application: milliseconds for real-time systems or delayed results for non-urgent workloads.
Real-time (online) inference
Real-time inference processes one request at a time as it arrives and returns a prediction immediately. It follows a “request–response” pattern, where each user action or API call triggers a model prediction. Response times usually range from milliseconds to a few seconds, depending on the model’s complexity and the infrastructure.
Streaming inference
Streaming inference continuously evaluates incoming data streams rather than waiting for discrete requests or scheduled jobs. Data flows through the system in an event-driven, continuous pattern, and predictions are generated in near real time as new data arrives. It falls between real-time and batch inference in terms of responsiveness, faster than scheduled batch jobs but operating on streaming data rather than isolated requests.
Batch inference
Batch inference runs predictions on large datasets together at scheduled intervals. The system processes data in bulk, like periodic jobs that may take minutes or hours to complete. Workloads are orchestrated through job schedulers or workflow engines and executed on distributed compute clusters. The data is read from storage systems, processed in parallel, and written back as updated tables, files, or database records.
| Type | Description | Response timing | Data flow | Use cases |
|---|---|---|---|---|
| Real-time (online) inference | Processes one request at a time as it arrives | Milliseconds to seconds | Request-response | Chatbots, fraud detection, and recommendation engines |
| Streaming inference | Continuously evaluates incoming data streams | Near real-time | Event-driven continuous flow | IoT monitoring, financial event detection, anomaly detection |
| Batch inference | Runs predictions on large datasets together at scheduled intervals | Minutes to hours (scheduled jobs) | Bulk processing | Credit scoring, analytics reports, periodic model scoring |
How AI inference works
The AI inference process happens through a model serving layer that handles requests, performs computation (on CPUs or GPUs), and returns results via an API or in a specific format. Let’s understand what happens in each step when a fraud detection system evaluates a credit card transaction.
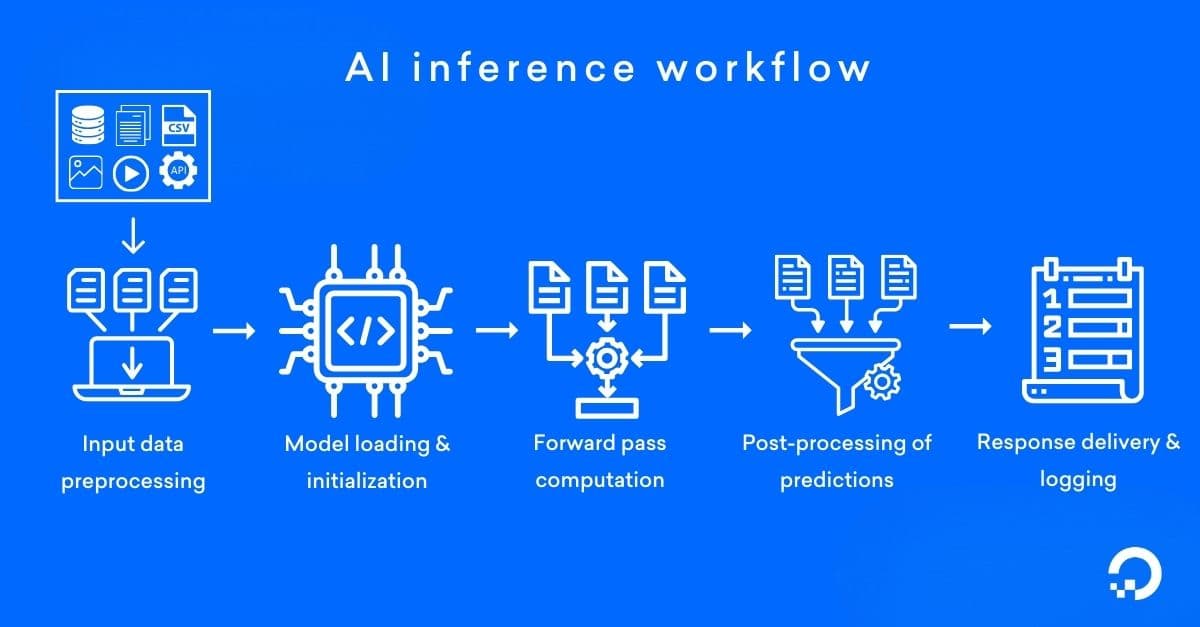
- Input data preprocessing: Raw inputs such as text, images, audio, or structured data are validated and transformed into the format the model expects. This may include tokenization (for LLMs), normalization, feature extraction, or conversion into tensors.
For example, let’s say a customer swipes their credit card for a $2,400 electronics purchase at a retailer in São Paulo—but their account is based in Chicago, and the device is one the system hasn’t seen before. The system extracts structured features from the transaction: amount, merchant category, device fingerprint, geolocation, time of day, and recent spending history. These features are normalized and converted into a numerical feature vector that the model can process.
- Model loading and initialization: The trained model, including its architecture and learned weights, is loaded into memory. In production environments, models are mostly containerized and served via frameworks such as TensorFlow Serving, TorchServe, or custom FastAPI-based services.
In this scenario, a pre-trained fraud detection neural network is already running in memory, deployed via a containerized model server using TorchServe. When the transaction comes in, the API gateway routes the feature vector to the model’s endpoint.
- Forward pass computation: The processed input is passed through the model, where matrix multiplications and activation functions compute the output. For deep learning and LLM inference, this step runs on GPUs or other accelerators to optimize latency and throughput.
Continuing with our fraud detection illustration, the model runs the feature vector through its network layers, weighing the combination of an unfamiliar device, an international location, and a high transaction amount against patterns learned from millions of historical transactions. It outputs a raw fraud probability score of 0.92.
- Post-processing of predictions: The raw model output is converted into a usable result, such as a probability score, classification label, ranked list, or generated tokens. Thresholding, decoding strategies (e.g., greedy decoding or beam search), or business rules may be applied.
In this case, a rule engine interprets the 0.92 score against the system’s business logic. Because it exceeds the 0.85 threshold and the transaction is cross-border, the engine classifies it as high-risk and flags it for step-up authentication rather than outright decline.
- Response delivery and logging: The final output is returned to APIs, databases, or downstream systems (like Kafka streams, payment gateways, alerting systems, etc.), depending on the application architecture. At the same time, metrics such as latency (P95/P99), throughput, and error rates are logged for monitoring, scaling, and performance optimization.
To wrap up the sequence, within 120 milliseconds of the original swipe, the payment gateway receives the high-risk classification and triggers an OTP verification request to the customer’s phone. Simultaneously, the system logs the model score, transaction metadata, latency (P95), and the authentication outcome—data that will feed future model retraining and performance monitoring.
Stop chasing raw FLOPs and benchmark LLM inference where it counts. Read the full guide on LLM Inference Benchmarking to learn how to measure latency, throughput, concurrency, and cost.
Key performance indicators for AI Inference
Optimizing inference starts with knowing which metrics to pay attention to. Not all of them will matter equally for your use case, but ignoring any of them can lead to slow responses, wasted compute, or costs that quietly spiral. Here are the ones that matter most:
| Performance indicator | Description | Why it matters | Example |
|---|---|---|---|
| Latency | Time taken to generate a prediction for a single request | Determines user-perceived speed; tail latency (P95/P99) reflects worst-case delays under load | A chatbot responds in 120ms on average, but 2 seconds at P99 during peak traffic |
| Throughput | Number of requests per second (RPS) or tokens per second (for LLMs) | Indicates how much traffic the system can handle before performance degrades | An LLM generating 80 tokens/sec vs. 20 tokens/sec affects response speed at scale |
| Cost per request | Compute the cost consumed for each inference call | Impacts long-term production economics and scaling viability | A GPU-backed inference costing $0.002 per request vs. $0.02 at high volume |
| Hardware utilization | Efficiency of CPU, GPU, or accelerator usage | Poor utilization increases cost and creates performance bottlenecks | A GPU running at 30% utilization wastes capacity and raises cost per prediction |
| Scalability under load | Ability to maintain performance during traffic spikes | Ensures reliability and consistent latency during peak demand | An e-commerce recommendation system handling Black Friday traffic without latency spikes |
AI inference use cases
AI inference starts the moment your application actually responds. Whether it’s scoring a transaction, ranking search results, or generating text, inference is the execution layer that turns model intelligence into user-facing action.
-
Fraud detection in financial transactions: A U.S.-based payment systems company H2o.ai processes deep learning models trained on 160 million records with 1,500 features to detect fraud in real time. When a new transaction is initiated, the deployed model scores it within milliseconds. The system blocks or flags suspicious activity before authorization.
-
Medical image analysis: In healthcare, a study on brain tumor detection shows how medical image inference works in practice. MRI scans were first labeled, resized to 150×150 pixels, and normalized before being passed into a customized convolutional neural network (CNN). During inference, the trained model classified each scan as tumorous or non-tumorous with a validation accuracy of 98.67%. To support clinical decision-making, post-processing techniques such as SHAP, LIME, and Grad-CAM produced visual heatmaps highlighting the regions that influenced the prediction.
-
Search ranking and recommendation systems: When a user submits a query or visits a page, contextual features such as past clicks, session behavior, and metadata are encoded. A ranking or recommendation model scores multiple candidate items in real time. AI inference system sorts results based on predicted relevance scores and returns a ranked list within strict latency limits. Netflix uses inference where a first-pass retrieval stage uses in-session clicks, browsing behavior, and long-term preferences to a candidate set. Then, a second-pass deep learning model computes relevance scores and delivers a ranked list in roughly 40 milliseconds.
-
Autonomous vehicle perception: Tata Elxsi integrated AI with long-range (up to 1 km) LiDAR sensors operating at 10 Hz to power real-time autonomous vehicle perception. Cloud data from LiDAR and images from cameras were fused and converted into tensors. The tensor data are then fed into deep learning models that perform inference to detect vehicles, pedestrians, and traffic signs, and to segment drivable areas. The model’s outputs, like object classifications, distance estimates, and violation detections (such as wrong-way driving or speeding), are passed directly into monitoring and control systems for immediate alerts or driving decisions under varying lighting and weather conditions.
-
Generative AI and content creation: Writer is an agentic AI platform that deploys 40-billion-parameter LLMs to generate marketing copy and enterprise content. User prompts are sent via API, processed by GPU-accelerated models served through NVIDIA Triton Inference Server, and responses are generated token by token. Here, inference supports up to a trillion API calls per month and produces 90,000 words per second.
How DigitalOcean builds next-gen inference? See how DigitalOcean engineers use Ray, vLLM, and Kubernetes to build scalable, GPU-optimized inference for generative AI. Watch the session to understand how serverless and dedicated modes, dynamic batching, and advanced KV-cache strategies work.
AI inference FAQ
What is AI inference?
AI inference is the process of using a trained machine learning model to generate predictions or outputs from new, unseen data. It is the production phase of AI, where models are executed for building real-time applications, analytics, and automated decision systems.
What is the difference between training and inference? Training builds a model by learning patterns from large datasets and adjusting its internal parameters. Inference applies the trained model to new data to produce predictions, classifications, or generated outputs.
Is inference more important than training in production? In production systems, inference is more operationally important because it runs continuously and directly impacts latency, scalability, and cost. While training determines model accuracy, inference determines user experience and production economics.
What hardware is used for AI inference? AI inference runs on GPUs and specialized accelerators such as TPUs, depending on your performance and workload requirements. GPU inference is common for deep learning and LLM workloads.
What is real-time vs batch inference?
Real-time inference generates predictions immediately when a request arrives, mostly within milliseconds or seconds. It is used in interactive applications where users or systems need instant responses, such as chatbots, fraud detection, or recommendation systems.
Batch inference processes large volumes of data at scheduled intervals instead of responding to individual requests. Models run predictions on accumulated datasets as periodic jobs to generate outputs like risk scores, demand forecasts, or analytics reports.
What are the best platforms for AI inference?
The best platforms for AI inference provide scalable GPU infrastructure, predictable pricing, and integrated model serving tools. DigitalOcean’s Gradient™ AI inference Cloud offers GPU-powered inference, autoscaling, and simplified infrastructure for production AI workloads.
Deploy on DigitalOcean’s Agentic Inference Cloud
DigitalOcean has spent over a decade building cloud infrastructure for developers, from virtual machines and managed Kubernetes to object storage, managed databases, and app hosting. DigitalOcean’s Agentic Inference Cloud extends that same simplicity to AI workloads, giving teams the tools to train, run inference, and deploy agents at scale without the operational overhead. We offer multiple paths to get your AI workloads into production:
Gradient™ AI Platform—build and deploy AI agents with no infrastructure to manage
-
Serverless inference with access to models from OpenAI, Anthropic, and Meta through a single API key
-
Built-in knowledge bases, evaluations, and traceability tools
-
Version, test, and monitor agents across the full development lifecycle
-
Usage-based pricing with streamlined billing and no hidden costs
GPU Droplets—on-demand GPU virtual machines starting at $0.76/GPU/hour
-
NVIDIA HGX™ H100, H200, RTX 6000 Ada Generation, RTX 4000 Ada Generation, L40S as well as AMD Instinct™ MI300X
-
Zero to GPU in under a minute with pre-installed deep learning frameworks
-
Up to 75% savings vs. hyperscalers for on-demand instances
-
Per-second billing with managed Kubernetes support
Bare Metal GPUs—dedicated, single-tenant GPU servers for large-scale training and high-performance inference
-
NVIDIA HGX H100, H200, and AMD Instinct MI300X with 8 GPUs per server
-
Root-level hardware control with no noisy neighbors
-
Up to 400 Gbps private VPC bandwidth and 3.2 Tbps GPU interconnect
-
Available in New York and Amsterdam with proactive, dedicated engineering support
→ Get started with DigitalOcean’s Agentic Inference Cloud
Any references to third-party companies, trademarks, or logos in this document are for informational purposes only and do not imply any affiliation with, sponsorship by, or endorsement of those third parties.
Pricing and product information are accurate as of March 2026.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
