AI Technical Writer

Introduction
Modern language models struggle when input sequences become very long because traditional attention mechanisms scale quadratically with the sequence length. This makes them computationally expensive and memory-intensive. Sliding window attention is a practical solution to this problem. It limits how much of the sequence each token attends to by focusing only on a fixed-size local context, reducing both compute and memory requirements while still capturing meaningful dependencies.
Instead of every token attending to every other token, sliding window attention allows each token to attend only to its nearby neighbors within a defined window. This idea is inspired by how humans often process information locally before integrating global understanding.
The research paper talks about two important methods that have been developed to handle long sequences efficiently. These generally fall into two categories: sparse attention mechanisms, which reduce computation by limiting attention calculations, and recurrent-style models like linear attention and state space models, which process sequences through hidden states. However, these approaches come with trade-offs. They either sacrifice performance for efficiency or introduce complex architectures that are difficult to implement and deploy. As a result, there is a growing need for simpler, efficient solutions that build on the standard Transformer architecture without adding significant complexity.
Key Takeaways
- Sliding window attention reduces computation from O(n2) to O(n⋅w), making it practical for long sequences.
- It focuses on local context, and deeper layers help propagate information to capture wider dependencies.
- Longformer improves this by adding global attention, allowing important tokens to access the full sequence.
- Mistral optimizes sliding window attention for real-world use with efficient KV cache and faster inference.
- SWAT enhances sliding window attention using sigmoid (no token competition), balanced ALiBi (better positional bias), and RoPE (stronger position encoding).
- Despite improvements, all methods involve trade-offs between efficiency, performance, and complexity.
- For very long sequences, combining these techniques with memory or hybrid approaches often gives the best results.
How Traditional Attention Works
To understand sliding window attention, it helps to first understand standard self-attention.
In a transformer, each token is converted into three vectors: query Q, key K, and value V. Attention is computed as:
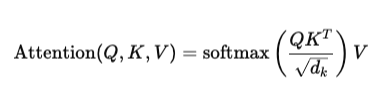
Here, every token compares itself with every other token. If the sequence length is n, then the attention matrix is of size n×n, leading to a complexity of O(n2).
This becomes a bottleneck for long documents, such as your RAG pipelines or large context AI agents you often work with.
Good to know concepts
- Quadratic complexity: In standard attention, every token interacts with every other token, leading to O(n2) computation. This becomes very expensive as sequence length increases, which is why efficient methods like sliding window attention are needed.
- Causal mask: A causal mask ensures that a token can only attend to previous tokens, not future ones. This is important for autoregressive models (like text generation) so they don’t “peek ahead.”
- Softmax: Softmax converts attention scores into probabilities that sum to 1. It creates competition between tokens, meaning that if one token gets high attention, others get lower weights.
- Attention sink phenomenon: Sometimes, certain tokens (like special tokens or punctuation) receive consistently high attention even when not important. These “attention sinks” can reduce model efficiency and distract from meaningful context.
- KV cache (Key-Value cache): During text generation, models store past keys and values so they don’t recompute them every step. This speeds up inference significantly, especially in long sequences, and is optimized in models like Mistral.
What is Sliding Window Attention?
Sliding window attention restricts attention to a local window of size w. Each token attends only to tokens within a fixed range before and after it.
If token i is being processed, it only attends to tokens in the range:
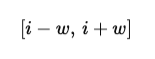
This reduces the complexity from:
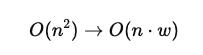
Since w≪n, this is significantly more efficient than vanilla attention. To reduce this complexity while preserving the sequential information, sliding window attention (SWA) is introduced in Longformer.
Complexity Comparison
Full attention has complexity O(n2)
Sliding window attention reduces it to:
O(n⋅w)
If n=10,000 and w=512 then:
n2=100,000,000, n⋅w=5,120,000
This is nearly a 20x reduction in computation.
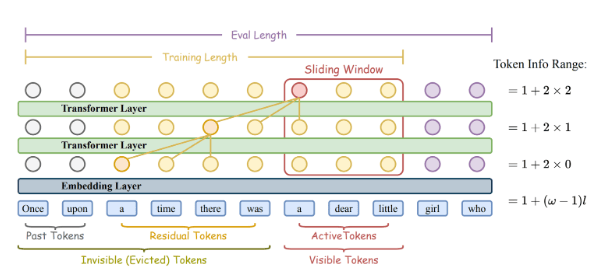
The demonstration of the SWA mechanism in Transformers (Source: Research Paper)
Think of a sliding window of size 3 moving across a sentence as shown in the figure. At any moment, the model can only “see” 3 tokens at a time; these are called active tokens (for example, “a dear little”).
Tokens outside this window are not directly visible and are called evicted tokens. However, their information is not completely lost. Some of it is passed forward to nearby tokens through each transformer layer. This means even if a token disappears from the window, traces of its meaning are carried by neighboring tokens.
As the model goes deeper (more layers), this information spreads further. The total range a token can influence grows with depth and is calculated as:
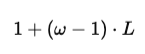
With window size ω=3 and depth L=2, the range becomes:
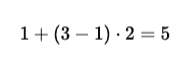
In simple terms, even though the model only looks at 3 tokens at a time, after 2 layers, it can effectively capture information from up to 5 tokens.
Understanding SWAT Attention in a Simple Way
What SWAT is Trying to Do
SWAT is a modified attention mechanism designed to make sliding window attention more stable and effective. It improves three key things at once: how attention weights are computed, how position information is added, and how tokens retain meaningful context within a limited window.
Step 1: Replacing Softmax with Sigmoid
In standard transformers, attention uses softmax:
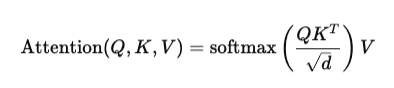
The problem with softmax is that it forces competition between tokens. If one token gets high attention, others get suppressed.
SWAT replaces softmax with sigmoid:
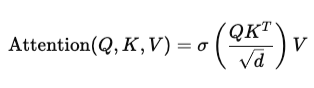
Here, σ\sigmaσ is the sigmoid function.
This means:
- Each token gets attention independently
- Tokens don’t suppress each other
- Multiple tokens can be important at the same time
So instead of “pick the most important token,” it becomes “consider all relevant tokens.”
Step 2: Adding Positional Bias with Balanced ALiBi
Since sigmoid does not naturally encode positional preference like softmax, SWAT adds a positional bias:
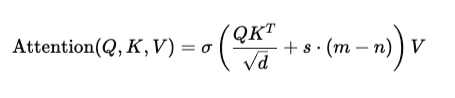
Here:
- m = current token position
- n = neighboring token position
- s = slope (controls how much position matters)
This term s⋅(m−n) tells the model how far apart two tokens are.
Key Idea
SWAT uses balanced ALiBi, meaning:
- Half the attention heads look forward (future tokens)
- Half look backward (past tokens)
The slopes are:

This allows:
- Some heads to focus on recent tokens
- Some heads to focus on older tokens
So the model captures both short-term and long-term patterns.
Step 3: Adding RoPE for Stronger Position Encoding
Even with ALiBi, position signals are still weak.
So, SWAT adds RoPE (Rotary Positional Embedding), which rotates query and key vectors based on position.
Final attention becomes:
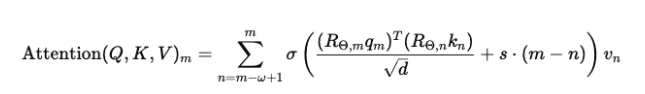
What this means in simple terms
- Only tokens inside the sliding window are considered
- Queries and keys are rotated to include position info
- Distance bias is added
- Sigmoid computes attention weights
- Values are combined to produce output
You can think of SWAT as:
- Sliding window → limits how much we look
- Sigmoid → lets multiple tokens matter
- ALiBi → adds distance awareness
- RoPE → strengthens positional understanding
Step 4: Efficiency of SWAT
Even with these improvements, SWAT stays efficient.
The cost is:
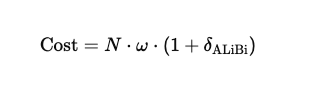
Where:
- N = sequence length
- ω = window size
- δALiBi = small extra cost
Since δALiBi is very small, the complexity is still:
O(N⋅ω) So it remains linear and scalable. SWAT makes sliding window attention smarter by letting tokens cooperate (sigmoid), understand distance (ALiBi), and encode position properly (RoPE), all while staying efficient.
Sliding window attention works because most language dependencies are local. Words depend heavily on nearby words rather than distant ones. This assumption allows models to retain performance while reducing computational cost.
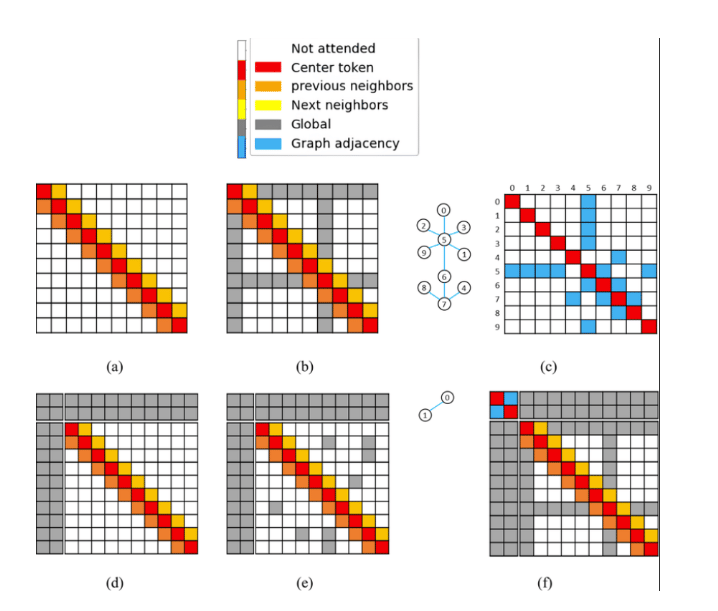
Sliding Window Attention in Modern Architectures
Longformer: Extending Local Attention with Global Context
The Longformer builds directly on sliding window attention but improves its ability to capture long-range dependencies. While pure sliding window attention is limited to local neighborhoods, the Longformer introduces a hybrid attention mechanism that combines local attention with selective global attention.
In Longformer, most tokens still follow sliding window attention. For a token at position i, it attends to tokens within a window size w, exactly as discussed earlier:
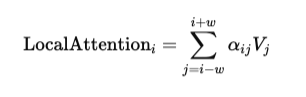
However, Longformer introduces a second type of attention called global attention. Certain tokens are marked as “global tokens,” and these tokens can attend to all other tokens in the sequence, and all tokens can attend to them.
Mathematically, if G represents the set of global tokens, then for any token i, the attention becomes:
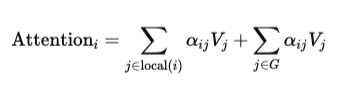
This simple addition solves a major limitation of sliding window attention. Information no longer has to propagate layer by layer across distant tokens. Instead, global tokens act as information hubs. For example, in a long document, tokens like the title, section headers, or question tokens in QA tasks can be designated as global tokens. These tokens gather information from the entire sequence and redistribute it efficiently.
This results in a complexity of:
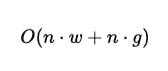
where g is the number of global tokens. Since g is typically small, the model remains efficient while gaining global context awareness.
The key improvement Longformer brings is this balance between efficiency and global reasoning. It retains the scalability of sliding window attention while selectively restoring full-context awareness where it matters.
Mistral Sliding Window Attention
Mistral takes sliding window attention further by optimizing it for real-world efficiency, especially during inference. Its approach is not just about limiting attention but also about how memory is handled using the KV (key-value) cache. In Mistral’s architecture, sliding window attention is implemented with a fixed attention span. Each token only attends to a fixed number of previous tokens, rather than the entire sequence. This is particularly important during autoregressive generation.
If the window size is w, then at time step t, the model only attends to:
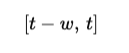
This means that instead of storing the entire KV cache of size t, the model only needs to retain the most recent www tokens. This significantly reduces memory usage during inference.
Formally, the KV cache size reduces from:
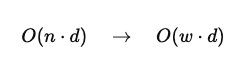
where d is the hidden dimension.
Another important improvement in Mistral is the use of Grouped Query Attention (GQA). Instead of having separate key and value projections for every attention head, multiple query heads share the same key-value pairs. This reduces memory bandwidth and improves inference speed without significantly affecting performance.
The combination of sliding window attention and GQA makes Mistral highly efficient on GPUs, which aligns closely with your work around optimizing GPU usage for AI workloads.
Unlike Longformer, Mistral does not explicitly introduce global tokens. Instead, it relies on deeper layers and efficient information flow to propagate context. The focus is more on practical efficiency and strong performance rather than architectural complexity.
What Improved Over Basic Sliding Window Attention
The evolution from basic sliding window attention to architectures like Longformer and Mistral highlights two key directions of improvement.
The Longformer improves expressiveness. It solves the limitation of missing long-range dependencies by introducing global attention. This makes it suitable for tasks like document understanding, question answering, and summarization, where global context matters.
Mistral improves efficiency. It optimizes how sliding window attention is implemented in practice, especially for inference. By limiting KV cache size and introducing grouped query attention, it achieves faster performance and lower memory usage, making it ideal for production systems and GPU-constrained environments.
In simple terms, Longformer answers the question, “How do we make local attention smarter?” while Mistral answers, “How do we make local attention faster and cheaper?”
Basic Limitations
SWAT is sensitive to hyperparameters like window size, depth, and ALiBi slopes, so it requires careful tuning to perform well. As models grow larger, they may rely more on memorization than context, reducing the effectiveness of sliding window attention. Also, SWAT has a limited attention range based on window size and depth, which can lead to information loss in very long sequences. For such cases, it may need to be combined with other methods like memory or hybrid architectures.
FAQ’s
What is sliding window attention and why is it useful? Sliding window attention limits each token to attend only to nearby tokens instead of the full sequence. This reduces computation from quadratic to linear, making it efficient for long inputs. It works well because most language dependencies are local.
How is sliding window attention different from standard attention? Standard attention compares every token with every other token, which is expensive. Sliding window attention only looks at a fixed neighborhood, saving memory and computation. The trade-off is that it may miss long-range dependencies.
How does information travel beyond the window? Even though tokens only see a small window, information passes through layers. Each layer spreads context slightly further, so deeper models can capture a wider range. This allows indirect long-range understanding.
What improvements does Longformer bring? Longformer adds global attention to sliding windows. Some tokens can attend to the entire sequence, helping capture long-range dependencies. This makes it more powerful for tasks like document understanding.
What makes Mistral’s approach different? Mistral focuses on efficiency during inference. It uses sliding window attention with optimized KV cache and grouped query attention. This reduces memory usage and speeds up generation.
What is SWAT and how is it different? SWAT replaces softmax with sigmoid so tokens don’t compete for attention. It also adds balanced ALiBi and RoPE for better positional understanding. This makes training more stable and improves information flow.
Why does SWAT use sigmoid instead of softmax? Softmax forces tokens to compete, which can suppress useful information. Sigmoid allows multiple tokens to contribute independently. This helps retain richer context within a window.
What are the main limitations of SWAT? SWAT is sensitive to hyperparameters like window size and depth. It also has a limited attention range, which can cause information loss in very long sequences. Larger models may also rely more on memorization.
Conclusion
Sliding window attention is a simple yet powerful idea that makes transformers scalable for long sequences by focusing on local context. Over time, it has evolved through models like Longformer, which adds global reasoning, and Mistral, which improves efficiency for real-world use. Sliding Window Attention takes this further by refining how attention is computed and how positional information is handled, making the approach more stable and effective.
However, no single method fully solves the challenge of long-context understanding. Each approach balances efficiency, performance, and complexity in different ways. In practice, combining these techniques with memory or hybrid architectures often leads to the best results, especially when building large-scale AI systems like RAG pipelines or long-context agents.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
