AI/ML Technical Content Strategist

Published May 21, 2026 · By James Skelton, DigitalOcean
Kimi K2.6, Moonshot AI’s 1-trillion-parameter MoE model, launched on DigitalOcean Serverless Inference in May 2026: bringing frontier-tier agentic coding capability to an OpenAI-compatible endpoint billed alongside DigitalOcean’s existing cloud stack.
The invoice that ended the per-token era
You typed one sentence into a prompt box: “Refactor this repository into microservices and open a PR for each service.” You hit enter, walked away, came back to a working branch and a sensible commit history, and felt, briefly, like you were living in the future.
Then the invoice arrived.
That single call had quietly turned into a long loop - the agent reading files, calling tools, reasoning over the results, planning the next move, and circling back for another pass. Dozens of inference calls. Each one carries a growing context window. Each one is billed at full token price. Your forecast said the task would cost about forty cents. The line item says fourteen dollars. Multiply that by a product feature running thousands of times a day, and the math your finance team signed off on last quarter quietly stops working.
This isn’t a billing error. It’s the moment the pricing model most of us have been using for two years stopped fitting the workload. Per-token pricing was designed for chat: one human, one prompt, one completion, a token count you could estimate within a reasonable margin. Long-horizon agentic workflows aren’t chat. They’re loops that decide for themselves how many model calls a task is worth, and frontier models like Kimi K2.6 are now capable of deciding that the answer is a lot.
The good news is that this is a solvable problem. The bad news is that solving it requires retiring some habits that have felt like common sense since 2023. This post is going up the week Kimi K2.6 went live on DigitalOcean Serverless Inference, and that’s not a coincidence. Let’s walk through what changed, why per-token math breaks under agentic load, and what to budget instead.
Kimi K2.6 is the model that makes the old budgeting math impossible to keep using.
Key Takeaways
- Per-token pricing was designed for chat workloads, not agentic ones. Long-horizon agents make dozens of inference calls per task with non-deterministic spend.
- The fix is to budget the task envelope, not the call. Track median task cost, P95 task cost, cost per successful outcome, and headroom ratio.
- Kimi K2.6 launched on DigitalOcean Serverless Inference in May 2026. It’s available via an OpenAI-compatible endpoint at
inference.do-ai.run/v1/chat/completions.
Meet Kimi K2.6

Before we get into why your cost model is about to break, it’s worth grounding the conversation in the specific model making it break.
Kimi K2.6 is Moonshot AI’s latest flagship, and it’s purpose-built for the kind of long-horizon, autonomous work that chat-era models were never asked to do. A few specs matter for the economics discussion ahead:
- 1 trillion parameters, 32 billion active. A sparse Mixture-of-Experts architecture, which means frontier-level reasoning at a fraction of the inference cost of a comparable dense model.
- 256K token context window. Wide enough to ingest entire codebases or document sets in one shot: which also means individual calls can be dramatically heavier than a typical chat turn.
- State-of-the-art coding performance. Outperforms major frontier models on SWE-Bench Pro, with particular strength in Rust, Go, and Python.
- Native multimodality. Text, images, and UI layouts processed in the same architecture via the MoonViT encoder.
- Open weights under a Modified MIT license. Portable, auditable, and now fully managed on DigitalOcean’s infrastructure.
Here’s how that performance lands in independent benchmarks across general agents, coding, and visual tasks:
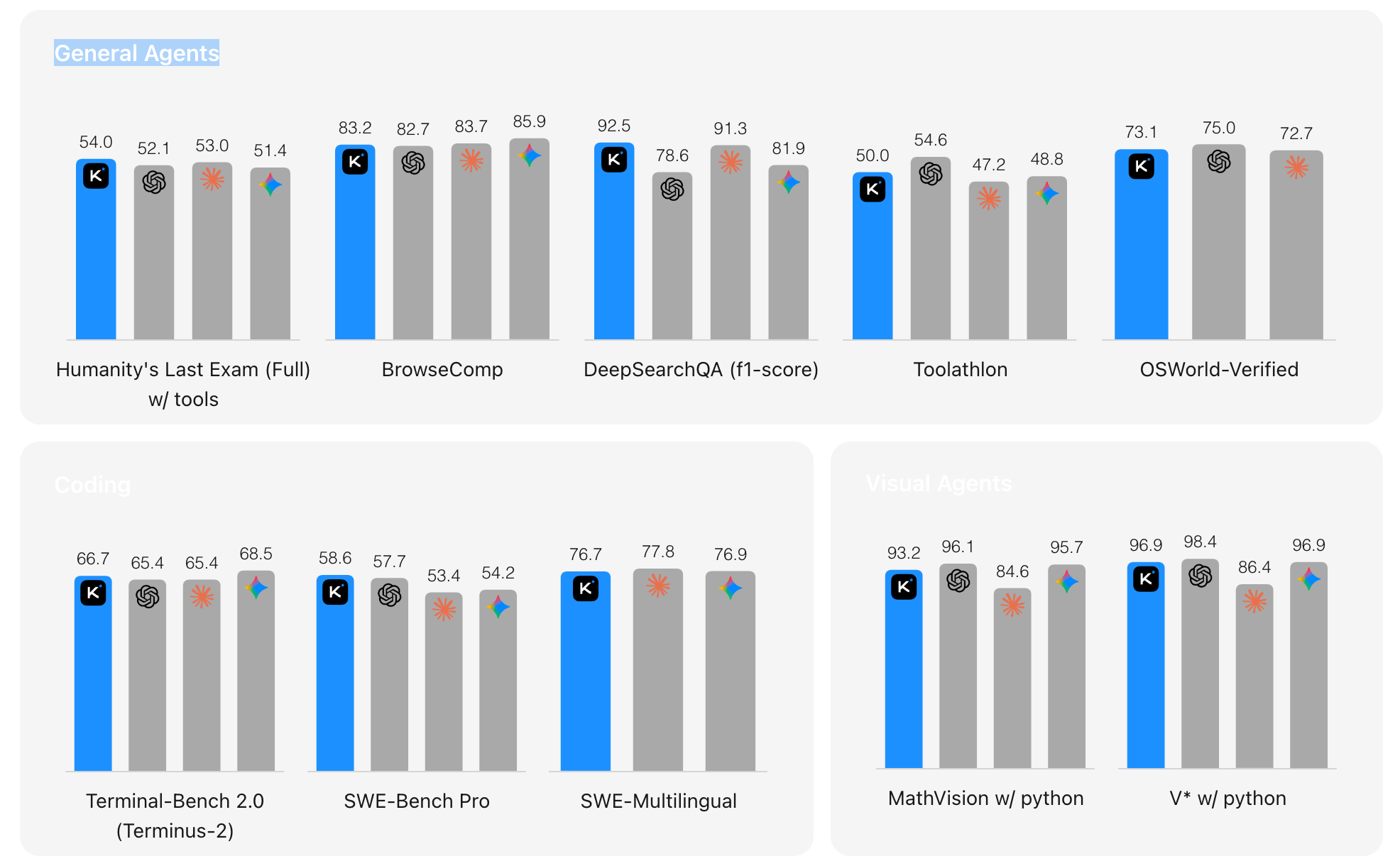
Above is a Bar chart comparing Kimi K2.6 against GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro across ten agentic benchmarks in three categories: General Agents (Humanity’s Last Exam, BrowseComp, DeepSearchQA, Toolathlon, OSWorld-Verified), Coding (Terminal-Bench 2.0, SWE-Bench Pro, SWE-Multilingual), and Visual Agents (MathVision, V). Kimi K2.6 leads on SWE-Bench Pro (58.6%), DeepSearchQA (92.5%), BrowseComp (83.2%), and Humanity’s Last Exam with tools (54.0%), while remaining competitive across the other benchmarks.* Source
The short version: Kimi K2.6 isn’t a chatbot you call from a form field. It’s a model built to be the engine inside a long-horizon agent - the kind your orchestration layer will hit again and again as it works through a multi-step task. That shift - from one call per intent to many calls per intent - is the entire reason the rest of this post exists.
The old mental model (and why it held up)
For about two years, AI cost forecasting was a spreadsheet problem.
You picked a model. You looked up its per-token rate. You estimated how many tokens an average request consumed: a few hundred in, a few hundred out, maybe a thousand if your users were chatty. You multiplied that by your expected request volume, added a buffer for growth, and handed the number to finance. They asked one or two clarifying questions and signed off.
The reason this worked is that every request had roughly the same shape. A user typed something. The model responded. The interaction ended. Token counts varied, but they varied within a narrow band, because the rate-limiting factor on the whole system was a human being deciding what to type next. People can only ask so many questions per minute. They get tired. They go to lunch. The natural ceiling on usage was the natural ceiling on human attention.
That made the unit of cost - the token - and the unit of work - the request - line up cleanly. One request, one bounded token count, one predictable line item. You could build dashboards on top of that. You could price features against it. You could promise a CFO a number and hit it.
The mental model held up because the workload it described was, fundamentally, a chat workload. And for chat, per-token pricing isn’t just reasonable: it’s elegant. The trouble is that chat is no longer the workload most of us are deploying.
What changes with long-horizon agentic workflows
“a single user-facing “task” becomes a probability distribution over inference spend, not a number”
A long-horizon agent doesn’t make one request. It makes a loop.
The shape is familiar by now: the agent plans, calls a tool, reads the result, reasons about what to do next, and goes again. Each pass through that loop is its own inference call, a full round-trip to the model, with the entire accumulated context coming along for the ride. A task that looks like one request to the user is, underneath, ten or twenty or fifty.
Three things break at once when you move from chat to that loop.
The number of calls per task is no longer fixed. A chat turn is one call. A ReAct loop runs until the agent decides it’s done: which could be three iterations on an easy task or thirty on a hard one. You don’t know in advance, and neither does the agent.
Each call gets heavier as the task progresses. Every tool result, every intermediate plan, every observation gets folded back into the context for the next iteration. By step fifteen, you’re not sending a 500-token prompt; you’re sending a 40,000-token conversation history. On a 256K context model like Kimi K2.6, that ceiling is high enough that “context bloat” stops being a theoretical concern and starts being a line item.
Fan-out is non-deterministic. Run the same task twice and you’ll get two different token bills. The agent’s path through the problem depends on what the tools return, what the model decides to investigate, and whether it second-guesses itself. Variance isn’t a bug here: it’s the point. An agent that always took the same path wouldn’t be much of an agent.
Multiply those three together and a single user-facing “task” becomes a probability distribution over inference spend, not a number. Which is a problem, because the budgeting tools most teams are using were built to handle numbers, not distributions.
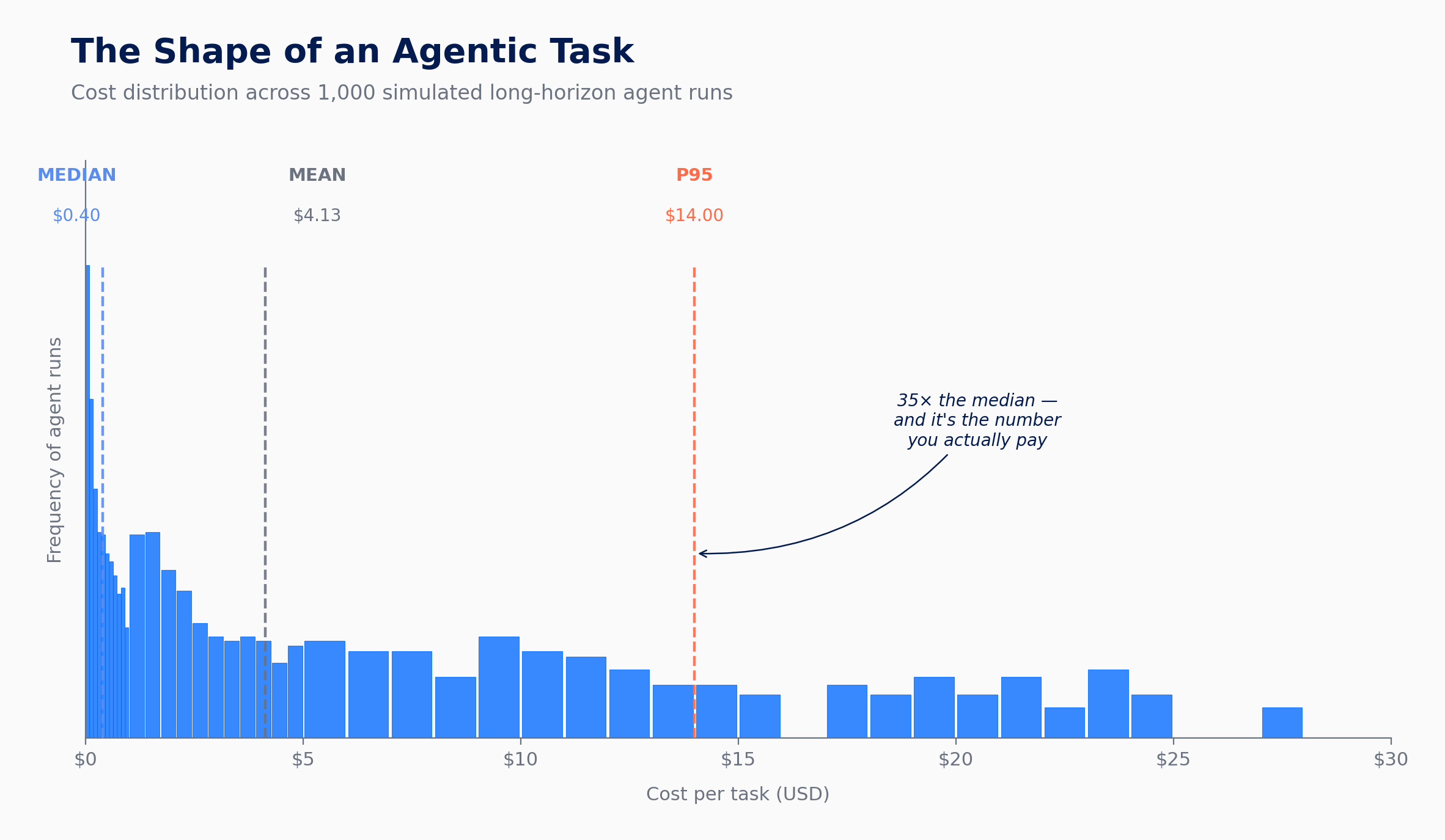
This is what an illustrative agentic cost distribution looks like: 1,000 simulated runs of the same long-horizon task, with most runs clustering cheaply near a median of $0.40, and a long right tail extending well past $30. The median is the number you’d quote in a meeting. The mean, pulled rightward by the tail, lands at $4.13, already an order of magnitude higher. And the P95, the number you actually have to provision for, sits at $14: roughly 35 times the median, and the line item your finance team will see when traffic spikes. The same prompt produced all of these. The agent decided, on each run, how much work the task was worth.
Why per-token budgeting quietly breaks
Once a task is a distribution rather than a number, three things go wrong at once, and they go wrong quietly, which is worse. Variance becomes the headline number. The same prompt that costs forty cents on a Tuesday afternoon costs fourteen dollars on a Wednesday morning, because the agent took a longer path through the problem. The median looks fine. The mean looks tolerable. The P95 is what actually shows up on the invoice when traffic spikes, and almost nobody is forecasting against it.
You can’t price what you can’t bound. If a feature’s underlying cost ranges across a 30x spread, you can’t put a flat price on it without either bleeding margin on the expensive tasks or overcharging on the cheap ones. Usage-based pricing only kicks the problem down the road. Your customer now has the same forecasting problem you did, and they trust you less for handing it to them.
Teams cap defensively, and capability bleeds out. When engineers can’t predict the cost of a task, the rational response is to clamp it: lower the max iterations, tighter context limits, hard timeouts at five minutes. The agent gets dumber. The product gets worse. The capability you bought a frontier model for - the long-horizon part - is exactly the part you’re now afraid to let it use.
The failure mode is rarely a single shocking invoice. It’s a slow drift: forecasts that quietly stop matching reality, features that quietly get less ambitious, and engineering teams that quietly lose trust in the cost model they’re working against. None of these show up as a fire. They show up as a ceiling.
The fix isn’t to find a cheaper model or a better discount. It’s to change the unit you’re budgeting in.
The unit shift: from price-per-token to price-per-completed-task
If the unit of work is no longer a request, the unit of cost can’t be a token.
The fix is to budget the way the workload actually behaves. A user doesn’t pay you to call a model; they pay you to finish a task: refactor the repo, draft the brief, reconcile the ledger. That’s the unit that matters to them, and it’s the unit that should matter to you. Everything else is implementation detail.
Three shifts make that practical.
Define a task envelope, not a token budget. Before an agent runs, decide what “done” looks like and what “too far” looks like. A maximum number of iterations. A wall-clock ceiling. A hard token cap that triggers a graceful exit rather than a runaway loop. The envelope doesn’t constrain what the agent can do, it constrains what it’s allowed to do before it has to come back and check in. That’s the difference between a budget and a panic button.
Budget at the envelope, not the call. Once the envelope is defined, your unit cost is the worst-case spend inside it, not the average spend of a single inference call. This is the number you forecast against. It’s higher than your old per-call estimate, and that’s fine. It’s also dramatically more stable, because the envelope is something you control. You’ve traded a low-and-volatile number for a higher-and-predictable one, which is exactly the trade finance teams actually want.
Treat partial failure as a line item, not an exception. Some tasks won’t finish. The agent will hit the envelope, take a wrong turn, or get stuck. Per-token budgeting tends to hide these costs because the inference still happened and still got billed. Price-per-completed-task forces you to count them honestly: every failed run is spend that produced no outcome, and that ratio is a real number you should be tracking, not an embarrassment you should be optimizing away from.
The shift sounds small, but it’s load-bearing. Once your unit of cost is the completed task, your forecasts get stable, your pricing gets defensible, and your engineers stop capping the agent into mediocrity to protect a budget that was measuring the wrong thing in the first place.
That’s the reframing. The next section turns it into four numbers you can actually put on a dashboard.
A practical budgeting framework (4 numbers every CTO should track)
The envelope reframing is only useful if it produces metrics you can actually put in front of a team. Four do most of the work.
-
Expected task cost (the median). The midpoint of your real-world task spend: half of runs cost less, half cost more. This is the number you quote internally when someone asks “what does it cost to run an agent.” It’s not the number you forecast against. Median spend is a useful sanity check; on its own, it’s a trap, because it hides the long tail of expensive runs that will eventually show up on the invoice.
-
P95 task cost (the planning number). The cost at which 95% of your runs come in at or below. This is what you actually budget against, because it’s the cost shape your infrastructure has to absorb on a normal busy day. A healthy P95-to-median ratio is around 2-3x. If you’re seeing 10x or higher, your envelope is too loose or your agent is exploring more than it’s executing. Both are fixable, but only if you’re measuring.
-
Cost per successful outcome. Total inference spend divided by the number of tasks that actually completed and produced a usable result. This is the metric that catches failed runs, abandoned loops, and silent timeouts - the spend that happened without producing value. If this number is meaningfully higher than your raw cost-per-task, your agent is failing more than you think it is, and you’re paying full price for it.
-
Headroom ratio. Your current peak concurrent task volume divided by the volume your provider can absorb before throttling or queueing kicks in. Long-horizon agents are bursty by nature; the difference between “agent feels snappy” and “agent feels broken” often comes down to headroom, not raw capacity. Track this, and you’ll see capacity problems coming weeks before they hit users.
Put together, these four numbers tell you something the per-token dashboard never could: not just what you’re spending, but whether you’re spending it well.
Most teams already have the raw data to compute all four. What’s usually missing is the discipline to look at them as a set: because each one in isolation can paint a flattering picture, and only the combination tells the truth.
Why Kimi K2.6 is the model worth budgeting for
A budgeting framework only matters if the workload it enables is worth running. Most agentic features fail not because the budgeting is wrong, but because the underlying model can’t actually finish the task, and you end up paying for a long loop that produces nothing.
Kimi K2.6 changes that calculus along three axes that matter for long-horizon work specifically.
Reasoning that doesn’t degrade across steps. Kimi K2.6 scores 58.6% on SWE-Bench Pro, the highest of any open-weight model, and ahead of GPT-5.4 (57.7%) and Claude Opus 4.6 (53.4%) on one of the hardest real-world coding benchmarks in current use. On a 20-step refactoring task, the marginal cost of each additional iteration only pays off if the model is still making sharp decisions at step 18. That’s the part most models quietly fail at, and the SWE-Bench Pro lead is the strongest signal currently available that Kimi K2.6 holds its quality across the long horizon.
MoE efficiency at frontier capability. 1 trillion total parameters, 32 billion active. In practice that means you’re paying inference economics closer to a 30B dense model for reasoning quality that competes with frontier dense models 10-20x its active size. For the cost per successful outcome metric from the previous section, that ratio is what makes the math work.
A 256K context window that earns its keep. For a chat workload, 256K is overkill. For a long-horizon agent that accumulates tool results, file contents, and intermediate plans across thirty iterations, it’s the difference between completing a task and timing out trying. The context size isn’t a marketing number here. It’s a structural enabler of the workload itself.
Add to that native multimodality (text, images, UI layouts in the same architecture via MoonViT) and open weights under a Modified MIT license, and what you have is a model whose specifications match the workload shape this post has been describing. The budgeting framework is the discipline; Kimi K2.6 is what makes the discipline worth practicing.
Why serverless inference fits this spend pattern
Once you’re budgeting in task envelopes instead of token counts, the question of where you run inference becomes a question about variance.
A long-horizon agent’s call volume isn’t smooth. A user kicks off a task; the agent makes thirty inference calls in two minutes; then nothing for an hour; then six tasks fire at once because three customers are doing morning standup at the same time. That’s not a load curve you can provision for cleanly. It’s bursty, spiky, and indifferent to your capacity planning spreadsheet.
You have two options for absorbing that shape.
You can provision for the peaks. Stand up your own GPU cluster sized for the worst hour of the worst day, eat the cost of it sitting mostly idle, and accept that “mostly idle” is the price of “never throttled.” This is defensible at scale, but the break-even point keeps moving. And the engineering hours required to keep INT4 quantization, batching, and cold-start behavior tuned aren’t free either.
Or you can let someone else absorb the variance. Serverless inference is built for exactly this spend shape: capacity that scales with your task volume in both directions, with the provisioning, quantization, and tuning handled by the team whose actual job that is. The bursts are theirs to absorb. The idle hours aren’t billed. Your variance lives in the only place it should live: in your task envelope math, where you can actually do something about it.
There’s a second, quieter advantage that matters more than it looks. When inference is just another line item on the same invoice as your Droplets, your databases, and your Kubernetes clusters, the budgeting framework from the last section is genuinely operable. You’re not reconciling a separate AI vendor’s billing portal against your cloud spend; you’re looking at one number, in one place, against one forecast. For a CTO trying to defend an agentic feature’s unit economics to a CFO, that consolidation isn’t a convenience. It’s the difference between a credible forecast and a hand-wave.
(There’s even a third option: a standalone inference API from a vendor whose business is only the model. That works, but it leaves you reconciling a separate invoice, a separate dashboard, and a separate procurement relationship: exactly the kind of overhead the budgeting framework above was designed to eliminate.)
The right infrastructure for a workload doesn’t just match its average shape. It matches its variance.
K2.6 on DigitalOcean Serverless Inference: the concrete example
Everything in this post has been abstract until now. Let’s make it real.
The argument boils down to two halves: the model creates the call volume, and the infrastructure has to absorb it. Kimi K2.6 on DigitalOcean Serverless Inference is one of the cleaner examples of that pairing currently in production.
What the infrastructure brings to the equation. Serverless inference is built for exactly the spend shape we’ve been describing: bursty, unpredictable, with quiet stretches between tasks where a self-hosted cluster would be sitting idle and billing you anyway. The provisioning of H100s, the quantization, the cold-start engineering: none of that is on your team’s plate. Your variance lives in your task envelope math, not in your ops rota.
What it looks like in practice. The endpoint is OpenAI-compatible, so the integration is whatever your existing tooling already does:
curl -X POST 'https://inference.do-ai.run/v1/chat/completions' \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "kimi-k2.6",
"messages": [
{
"role": "user",
"content": "Analyze this repository and suggest a microservices migration plan."
}
]
}'
That’s the full integration surface. Find your access key in the Serverless Inference console and you’re calling a frontier model from your existing project, with the usage rolling up onto the same invoice as your Droplets, your Managed Databases, and your Kubernetes clusters clusters.
What’s available today on DigitalOcean Serverless Inference:
- Kimi K2.6 via OpenAI-compatible endpoint at
inference.do-ai.run/v1/chat/completions - 256K context per call, no separate provisioning
- Usage billed to your existing DigitalOcean account
- Works with LangGraph, LlamaIndex, the OpenAI SDK, or any orchestration layer that speaks OpenAI’s API
Where your orchestration plugs in. Worth being explicit here: the endpoint above serves the model. The long-horizon agent = the ReAct loop, the planning step, the tool-call dispatcher, the retry logic - lives in your code, or in a framework like LangGraph or LlamaIndex that you run on top. Drop the endpoint URL into whichever orchestration layer you prefer, and you have the full setup we’ve been budgeting for: a frontier model on demand, an orchestration layer you control, and a task envelope you defined.
The reason this combination is interesting for the economics conversation isn’t that it’s magical. It’s that the layer split is clean. The model is one line item, on one invoice, behind one key. Your orchestration is your own code, where it belongs. And the budgeting framework from earlier in this post applies cleanly across both, because there’s nothing hidden between them.
Which is, in the end, what you actually want from infrastructure: a place where the variance is yours to manage, and the boring parts aren’t.
Closing thoughts: budget the envelope, ship the agent
Per-token thinking is a 2023 habit. The workload has moved on; the budgeting model needs to move with it. Budget the envelope, track the four numbers, and your agents stop being a cost risk and start being a multiplier.
The fastest way to put this framework to work is to point it at a model worth running it against. Kimi K2.6 is live on DigitalOcean Serverless Inference today - frontier intelligence, OpenAI-compatible endpoint, zero ops on your side, billed alongside the rest of your DigitalOcean stack.
Start building with Kimi K2.6 on Serverless Inference →
- Spin up an access key in the Serverless Inference console
- Read the Serverless Inference quickstart in the DigitalOcean docs
Spin up a key, drop the endpoint into your orchestration layer, and ship the agent you’ve been budgeting for.
Frequently Asked Questions
What is Kimi K2.6
Kimi K2.6 is Moonshot AI’s flagship open-weight language model, released in April 2026. It’s a 1-trillion-parameter Mixture-of-Experts (MoE) model with 32 billion active parameters, a 256K context window, and state-of-the-art coding performance: scoring 58.6% on SWE-Bench Pro.
How do I access Kimi K2.6 on DigitalOcean
Kimi K2.6 is available via DigitalOcean Serverless Inference at inference.do-ai.run/v1/chat/completions. The endpoint is OpenAI-compatible. You’ll need a model access key from the Serverless Inference console.
What is the pricing model for Kimi K2.6 on DigitalOcean Serverless Inference?
Usage is billed alongside your existing DigitalOcean resources (Droplets, Kubernetes, Managed Databases) rather than as a separate vendor invoice. See the Serverless Inference console for current per-token pricing.
How does Kimi K2.6 compare to GPT-5.4 and Claude Opus 4.6
On SWE-Bench Pro, Kimi K2.6 scores 58.6%, ahead of GPT-5.4 at 57.7% and Claude Opus 4.6 at 53.4%. It’s the highest-scoring open-weight model on that benchmark. What is “task envelope” budgeting?
| Budgeting unit | Works for chat? | Works for agents? | Why |
|---|---|---|---|
| Per-token estimate | Yes | Weakly | Ignores loop count and variance |
| Per-request estimate | Yes | No | One user task may trigger many calls |
| Per-completed-task envelope | Yes | Yes | Captures median, P95, failures, and caps |
Task envelope budgeting replaces per-token cost forecasting with a per-completed-task budget — defining maximum iterations, wall-clock time, and token ceilings per agent run, then forecasting against the worst-case spend within that envelope rather than against individual call costs.
Why does agentic AI cost more than chat?
Agentic AI usually costs more than chat because a single user-facing task can trigger many model calls behind the scenes. A chat request is often one prompt and one response; a long-horizon agent may plan, call tools, inspect results, revise its plan, call more tools, and repeat that loop dozens of times.
Each loop can also become more expensive as the context grows. Tool outputs, intermediate reasoning, file contents, and prior observations may be carried into later calls, so the agent is not just making more requests. It is often making heavier requests as the task progresses. That turns one “task” into a distribution of possible costs rather than a predictable per-request bill.
What is P95 task cost?
P95 task cost is the cost level at which 95% of agent runs come in at or below. For example, if your P95 task cost is $14, that means 95% of completed runs cost $14 or less, while the most expensive 5% cost more.
For long-horizon agents, P95 is often more useful than the average or median because it shows what you need to plan for during normal high-variance usage. It is the budgeting number that helps teams avoid being surprised by expensive but expected agent runs.
Why is median AI task cost misleading?
Median task cost is misleading because it hides the long tail. If most runs are cheap, the median can look reassuring even when a meaningful minority of runs are dramatically more expensive.
In the article’s example, the median run costs $0.40, but the P95 run costs $14 — roughly 35 times higher. If a team budgets around the median, it may badly underestimate the real cost of running agents in production, especially when traffic spikes or tasks become more complex.
How should CTOs budget for long-horizon AI agents?
CTOs should budget for long-horizon agents at the task level, not the individual token or API-call level. The core unit should be the completed task: the repository refactor, the support investigation, the financial reconciliation, the research brief, or whatever outcome the agent is expected to deliver.
A practical budgeting framework should track four numbers: median task cost, P95 task cost, cost per successful outcome, and headroom ratio. Teams should also define a task envelope before agents run, including maximum iterations, wall-clock limits, token ceilings, and graceful exit behavior. This gives finance and engineering a shared way to forecast cost without capping the agent so aggressively that it loses capability.
When should I use serverless inference instead of dedicated GPUs?
Serverless inference is a strong fit when your agentic workloads are bursty, unpredictable, or unevenly distributed throughout the day. Long-horizon agents may make many calls in a short window, then sit idle, then spike again when multiple users launch tasks at once. That shape is difficult to provision efficiently with dedicated GPUs unless you have enough steady volume to keep the hardware busy.
Dedicated GPUs can make sense at sustained scale, especially when you can keep utilization high and have the team to manage provisioning, quantization, batching, cold starts, and capacity planning. Serverless inference is usually better when you want to absorb variable demand without operating GPU infrastructure yourself.
Does DigitalOcean Serverless Inference support OpenAI-compatible APIs?
Yes. The article describes Kimi K2.6 on DigitalOcean Serverless Inference as available through an OpenAI-compatible endpoint:
https://inference.do-ai.run/v1/chat/completions
That means teams can use existing OpenAI-compatible tooling, SDK patterns, and orchestration frameworks such as LangGraph or LlamaIndex while running the model through DigitalOcean Serverless Inference.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
