By Adrien Payong and Shaoni Mukherjee

Introduction
Models with hundreds of billions or even trillions of parameters achieve state-of-the-art performance in natural language processing, vision, and other areas. Training or even running these large language models can be computationally expensive with current hardware. To scale these models to higher levels of parallelism, researchers have applied techniques to distribute a model’s computation over many processors or graphics processing units (GPUs). Approaches such as data parallelism, tensor parallelism, and pipeline parallelism have pushed boundaries.
However, parallelism alone isn’t enough to address inefficiencies of computing every part of a network for every token. To further address this problem, researchers proposed the mixture‑of‑experts (MoE) architecture, which splits a network into a set of smaller, specialized subnetworks, known as experts.
Expert parallelism goes one step further, distributing these experts across multiple GPUs or nodes. In this article, we will cover what expert parallelism is, how it works, how it differs from other parallelism techniques, and why it is an essential component of modern AI systems.
Key Takeaways
- Efficient Scaling Through Expert Sharding: Expert Parallelism is an approach that shards entire experts of a Mixture-of-Experts model across GPUs or nodes. This allows for efficient training of trillion-parameter models since each GPU does not need to store the full model parameters, unlike data parallelism.
- Sparse Activation for Compute Savings: The sparse activation mechanism in MoE ensures that for any given token, only a subset (top-k) of the experts is activated, reducing the computational cost of training such high-capacity models.
- Synergy with Other Parallelisms: Expert Parallelism can be used in conjunction with data, tensor, and pipeline parallelism. This provides opportunities for novel hybrid parallel training strategies that trade off between compute, communication, and memory for large GPU clusters.
- Framework and Implementation Support: DeepSpeed, Megatron-LM, and TensorRT-LLM support MoE and expert parallel training through configurations like ep_size and num_experts parameters.
- Challenges and Optimizations: The use of gating for routing in Expert Parallelism can introduce communication overheads and load-balancing issues. These challenges are often mitigated through careful design of the gating mechanism, the use of high-bandwidth, low-latency interconnects, and hybrid parallel configurations.
What Is Expert Parallelism?
At a high level, expert parallelism is the process of splitting a model’s experts across devices and routing each input to the appropriate device(s). Within a mixture‑of‑experts layer, each expert is a feed‑forward network (typically a multilayer perceptron) that operates on a set of tokens independently. Vanilla MoE uses a learned routing network to select the top‑k most relevant experts for each input.
The selected experts process the input in parallel, and their outputs are combined using gating values that specify the contribution of each expert to the final output.
The sparse activation refers to the fact that at most k experts are active for each token, leaving the other experts inactive, thus saving computation. Expert parallelism exploits this sparsity by assigning different experts to different devices, so each device is only responsible for the tokens assigned to its experts.
Expert parallelism reduces memory and computational overhead by distributing the experts. Since each GPU only stores the parameters of its experts (rather than the entire set), it enables the system to scale to MoE models with a large number of experts. As each token only “touches” a small subset of the model’s parameters, very large networks can be trained within a restricted hardware budget.
How Expert Parallelism Works
It may be helpful to walk through the internal process of how expert parallelism works in practice, including how tokens are routed, how experts are selected, and how their computations are coordinated across GPUs.When an input token arrives at an MoE layer using expert parallelism, the following occurs:
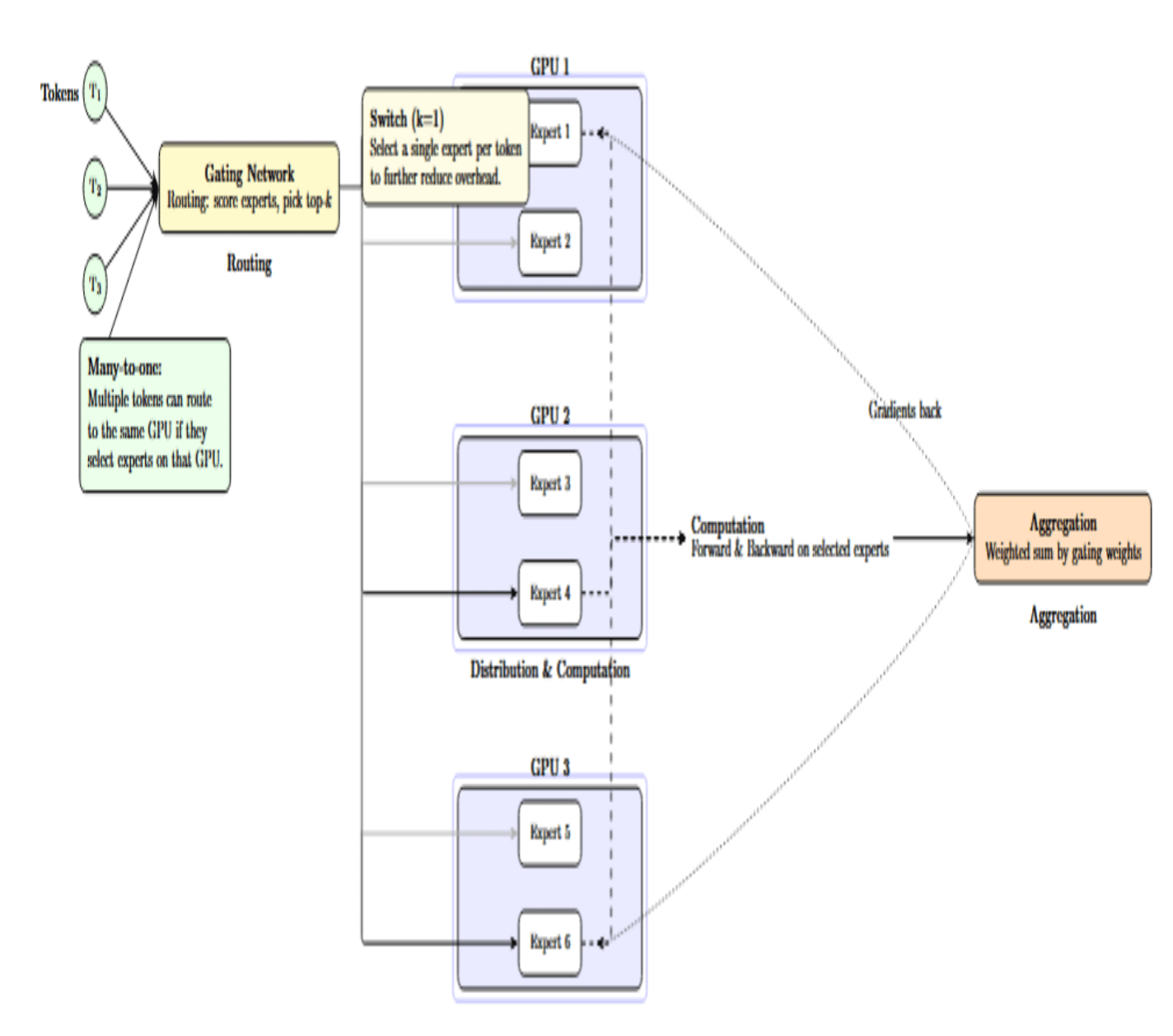
- Routing: A gating network calculates scores for each expert. The top‑k highest‑scoring experts are selected for that token. Some variants, such as Switch Transformers, take this idea further by selecting a single expert (k=1) for each token, further reducing overhead.
- Distribution: The tokens are sent to the GPUs where the selected experts reside. Since each GPU only stores a subset of the experts, there is a many‑to‑one relationship: multiple tokens can be routed to the same GPU if they have the same set of chosen experts.
- Computation: The GPUs with the selected experts then process their assigned tokens. Each GPU performs a forward and backward pass through the expert’s network and computes partial gradients.
- Aggregation: After each expert has computed its output, the outputs are returned to the router and aggregated using the gating weights. During backpropagation, gradients are similarly sent back to each expert.
GPU Communication
Expert Parallelism introduces communication overhead, as tokens must be dispatched to and gathered from the correct GPUs. Typically, all-to-all communication patterns are used; each GPU may need to send and receive data from every other GPU, especially as the number of experts or GPUs increases.
Framework Integration
Expert parallelism is supported in several deep‑learning frameworks. In DeepSpeed, the MoE API takes an ep_size parameter, which is the number of processes in an expert parallel group. The total number of experts is split across these processes. For instance, num_experts=8 and ep_size=2 means each group of two GPUs will have four experts, and tokens will only be exchanged within the group.
TensorRT‑LLM and Megatron‑LM support Hybrid parallelism, where users specify --moe_ep_size (expert parallel size) and --moe_tp_size (tensor parallel size) when converting a checkpoint. With tensor and expert parallelism, expert weights are split evenly across devices, while entire experts are spread across GPU groups. Hybrid parallelism finds a tradeoff between memory, computation, and communication costs. An example MoE pipeline might use data parallelism to scale across nodes, tensor parallelism to split a large matrix within each expert, and expert parallelism to distribute experts across GPUs.
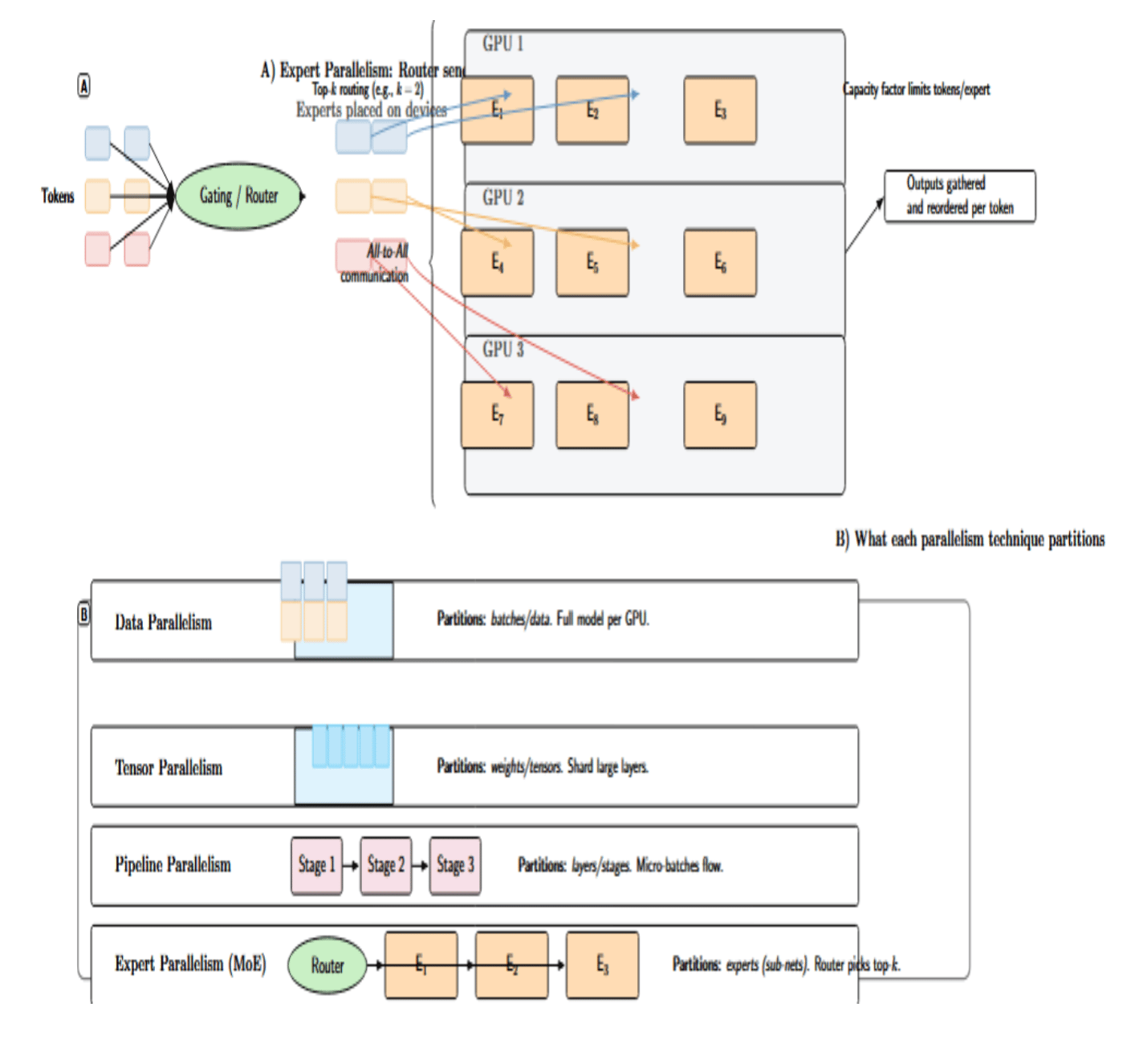
Expert Parallelism vs. Other Parallelism Techniques
Parallel training strategies have different notions of workload splitting across devices. The table below contrasts the most common strategies, showing how expert parallelism relates to data, tensor, and pipeline parallelism.
| Parallelism type | Description | Use case |
|---|---|---|
| Data parallelism | Replicates the entire model on each GPU and splits the dataset into shards. Each GPU processes its shard, computes gradients, and synchronizes updates via all-reduce. |
Simple training tasks when the model fits in GPU memory; widely used in standard training pipelines. |
| Tensor parallelism | Splits the weights of each layer across GPUs (e.g., splitting weight matrices column-wise). Each GPU performs partial matrix multiplications; outputs are collected via all-gather. |
When the model’s layers are too large to fit on a single GPU; used in large Transformer models. |
| Pipeline parallelism | Splits the model into stages, each residing on a different GPU. During the forward pass, activations are passed from one stage to the next; backward pass propagates gradients in reverse. | Deep models with sequential structure; reduces memory by spreading layers. |
| Expert parallelism | Places whole experts of an MoE layer on different GPUs. A gating network selects the top-k experts for each token, and only the GPUs hosting those experts process the token. | Sparse models, such as Mixture-of-Experts, allow scaling to trillions of parameters with fewer compute resources. |
The diagram below is to help understand expert parallelism and how it contrasts with other approaches. The first visualization shows how the gating network sends tokens to the experts spread across the GPUs. The second contrasts data, tensor, pipeline, and expert parallelism, and illustrates which dimension of the model/data each method partitions.
Advantages of Expert Parallelism
Expert parallelism brings several important benefits for large‑scale deep learning. Let’s consider some of them:
- Efficient memory and compute utilization: Since each GPU only holds a subset of the experts, the memory footprint per device is significantly reduced. This allows for models with an enormous number of parameters (the total sum across all experts) to be instantiated without exceeding the memory of a single GPU.
- Scalability to massive models: Expert parallelism is one of the fundamental enablers for scaling to trillion-parameter models and beyond. We can increase model size almost linearly by adding more experts (and more GPUs to host them), without encountering the same bottlenecks as dense models. In practice, MoE models such as Switch Transformer, GShard, GLaM, and others have already achieved hundreds of billions to trillions of parameters with the help of expert parallelism techniques.
- Reduced training time and cost: As more of the model’s capacity can be used without a linear growth in computation, a given model quality can be trained faster. MoE models have seen large speed-ups in training; e.g., Switch Transformer reported a ~4x pre-training speedup over a dense model of similar quality.
Implementation Example
Let’s examine a practical implementation of Expert Parallelism, where we configure distributed experts on GPUs using the DeepSpeed library. The code snippet below shows how to integrate a Mixture-of-Experts layer into a Transformer-style model.
Example Code Using DeepSpeed
Below is a simplified PyTorch/DeepSpeed code snippet illustrating how to configure a Mixture‑of‑Experts layer with expert parallelism:
import torch
from deepspeed.moe.layer import MoE
from deepspeed.pipe import PipelineModule
class ExpertLayer(torch.nn.Module):
def __init__(self, model_dim, hidden_dim):
super().__init__()
self.ff1 = torch.nn.Linear(model_dim, hidden_dim)
self.ff2 = torch.nn.Linear(hidden_dim, model_dim)
self.activation = torch.nn.ReLU()
def forward(self, x):
return self.ff2(self.activation(self.ff1(x)))
# Define the expert parallel group size and number of experts
ep_size = 2 # number of GPUs per expert group
num_experts = 8
# Create an MoE layer with distributed experts
moe_layer = MoE(
hidden_size=1024,
expert_class=ExpertLayer,
num_experts=num_experts,
ep_size=ep_size,
k=1, # top‑1 gating (Switch style)
expert_args=(1024, 4096)
)
# Integrate into a pipeline or Transformer model
model = PipelineModule(layers=[moe_layer, ...], loss_fn=torch.nn.CrossEntropyLoss())
This code defines a minimal feed-forward expert (ExpertLayer) and then uses DeepSpeed’s MoE layer to implement a Mixture-of-Experts block, which shards whole experts across GPUs using expert parallelism (ep_size=2 puts the GPUs used by this layer into 2 groups). With num_experts=8 total experts, and k=1 (Switch-style, top-1 routing), a lightweight gating network within MoE decides which token is assigned to which expert. The individual experts each implement a 2-layer MLP (Linear → ReLU → Linear), which maps hidden width 1024 → 4096 → 1024. DeepSpeed will manage the token routing across the EP group behind the scenes. Finally, the moe_layer is added to a PipelineModule, illustrating how the MoE block would be inserted into a larger Transformer/pipeline and trained end-to-end with a standard CrossEntropyLoss.
Illustrative “Expert Parallelism” Config
The following pseudo-configuration shows how DeepSpeed manages multiple parallelism dimensions when training an MoE model. It leverages bfloat16 (bf16) mixed precision, uses AdamW with a learning rate of 2e-4, and applies ZeRO stage-2 to shard optimizer, states, and reduce memory.
It provides a hybrid parallelism of data parallel size 4 ( this replicates the model across 4 groups), tensor parallel size 2 (partition large matrices across 2 GPUs), pipeline parallel 1 (no pipelining), and expert parallel size 4 (shard experts across 4 GPUs).
{
"bf16": { "enabled": true },
"optimizer": { "type": "adamw", "params": { "lr": 2e-4 } },
"zero_optimization": { "stage": 2 },
"parallelism": {
"data_parallel_size": 4,
"tensor_parallel_size": 2,
"pipeline_parallel_size": 1,
"expert_parallel_size": 4
},
"moe": {
"enabled": true,
"num_experts": 64,
"top_k": 2,
"capacity_factor": 1.25,
"load_balancing_loss_coef": 1e-2,
"router": "softmax",
"token_drop_policy": "capacity" // or "dropless" depending on framework
}
}
MoE Settings:
- Enabled: true — required to use MoE.
- Num Experts: 64 — a somewhat typical number of experts.
- top_k = 2 — a common choice of only routing each token to the top 2 experts.
- capacity_factor = 1.25 — how many tokens each expert is allowed to process, with typical values being ~1.0–2.0.
- load_balancing_loss_coef = 0.01 — how hard to enforce usage balancing between experts, with a small coefficient preferred to avoid excessive load balancing.
- router = “softmax” — a standard choice of gating network.
- token_drop_policy = “capacity” or “dropless” —How to route tokens when an expert is over capacity. These are two mechanisms that have been implemented in existing frameworks, but with varying effects.
Use Cases and Applications
Expert parallelism is particularly well‑suited to models and tasks that have a large capacity and a limited compute budget:
- Training Large Language Models: Training enormous LLMs (GPT‑4, Switch Transformers, Mixtral, and others) often involves using MoE layers to scale up parameter counts while controlling computation. Expert parallelism allows these models to run across clusters of GPUs.
- Sparse Transformer Architectures: MoE layers are typically interleaved with multi‑head attention layers within Transformer models. In Mixtral 8×7B, top‑k gating (k=2) is applied, meaning two experts are selected per token and their outputs are combined with their associated gate values. In the expert parallelism design, each expert can be placed on a different device for efficient training.
- Efficient Fine‑Tuning: If you have a huge pre-trained MoE model, then you can fine-tune a subset of experts for a new task (leaving the rest fixed). Expert parallelism makes this training efficient because only the GPUs hosting the experts that you are fine-tuning must participate in the training.
- Adaptive Inference: During inference, expert parallelism reduces latency by activating only relevant experts. The gating networks decide which subset of experts will be applied per input token, while the “inactive” experts consume no compute resources. This property enables the deployment of high‑capacity networks with manageable throughput.
Challenges and Considerations
Despite its benefits, expert parallelism introduces new complexities:
Communication Overhead
Routing tokens to the appropriate GPUs requires all‑to‑all communication. Each token is sent to the GPUs that hold its selected experts, and then those GPUs return the outputs of the experts to the tokens on the originating devices. If there are large numbers of tokens and experts, this communication can dominate the training time. As such, communication overhead is a primary consideration in the design of expert parallelism. Researchers often pair expert parallelism with data parallel or tensor parallel strategies to balance workload and reduce overhead. In their paper on the Switch Transformer, the authors formalize these trade‑offs by using a binary assignment matrix that specifies which tokens are assigned to which experts, along with a measure of communication costs.
Load Balancing
If some experts are assigned more tokens than others, then the GPUs with those experts become bottlenecks. The gating network must balance between accuracy (routing tokens to the best expert) and load balancing (making sure no single expert/GPU is overloaded). There are more complex gating strategies that can redistribute tokens to make better use of all the experts(like load‑balanced gating). However, these may sacrifice the model’s ability to send tokens to the best expert. The capacity factor (which determines how many tokens an expert is allowed to process before overflowing or dropping excess tokens) and the gating algorithm must be carefully tuned to prevent hot spots.
Hardware and Infrastructure Requirements
Expert parallelism can increase pressure on the GPU interconnect and CPU memory. The all-to-all operations for dispatch, if not optimized, can result in a large number of small messages, which may overload the networking hardware. Leverage of modern interconnect technologies (NVSwitch intra-node, InfiniBand, or NVLink inter-node) is almost a requirement for large-scale expert parallel training.
FAQ SECTION
How does Expert Parallelism differ from other forms of model parallelism?
In Expert Parallelism, entire experts (sub-networks) are distributed across GPUs, while other techniques partition the model differently: data parallelism partitions a batch of tokens, tensor parallelism partitions a matrix, and pipeline parallelism partitions layers of a model. Also, only the experts selected for each token are activated, reducing the computation and memory requirements.
Why do we use Mixture-of-Experts (MoE) layers with Expert Parallelism?
The gating network is used to route each token to only a few experts (top-k), making the MoE layer sparse. Expert Parallelism enables those experts to be placed on different GPUs or nodes. As a result, the number of experts (and therefore the capacity of the model) can scale to orders of magnitude larger than would fit on a single GPU. The combination of MoE and Expert Parallelism enables us to build trillion-parameter models that remain computationally feasible.
What are the main challenges in implementing Expert Parallelism?
Communication, load balancing, and hardware interconnect speed are the major challenges for implementing expert parallelism. Each token must be routed to the GPUs that contain the experts who were chosen for that token. This requires all-to-all communication at every layer, which can be quite expensive. If the gating network isn’t smart, it can cause some GPUs to become bottlenecks by sending too many tokens to a small number of experts.
Routing algorithms, careful regularization of the gating losses to ensure load balance, and high-bandwidth GPU interconnects (like NVLink or InfiniBand) are key to overcoming these issues.
Conclusion
Data, tensor, and pipeline parallelism are the three general approaches for model parallelism. These distribute computation across devices by splitting the data, matrices, or layers. On the other hand, expert parallelism distributes model capacity by spreading the experts of a mixture‑of‑experts layers across GPUs. Since each input token is routed to only a few experts, only those GPUs will perform computations.
Mixture‑of‑experts architectures and expert parallelism have opened the door for training significantly larger and more specialized models without prohibitive costs. In the future, we can expect routing algorithms and communication strategies to improve, further alleviating some of the concerns associated with load‑balancing and communication bottlenecks. Expert parallelism will likely be combined with data, tensor, and pipeline parallelism to create a hybrid approach that will become the standard for training future LLMs and sparse models. For hands-on resources, you can look at the following guides:
Resources
- A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training
- Mixture of Experts Explained
- Mixture-of-Experts with Expert Choice Routing
- Toward Efficient Inference for Mixture of Experts
- Mixture of Experts package
- Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
