By Adrien Payong and Shaoni Mukherjee

Introduction
The size of datasets and neural networks increases at an explosive rate. At some point, it becomes clear that a single device is not an efficient approach to do a specific task. You may be training a convolutional network on a few million images or scaling up a large language model to billions of parameters. Data parallelism is a core technique for speeding up workloads in machine learning. It forms the foundation for scalable, distributed training across multiple GPUs or even entire data centers, enabling efficient processing of large-scale models. In this article, we will explain the mechanics of data parallelism and how it differs from task and model parallelism. We will illustrate how it can be implemented using popular frameworks such as PyTorch, TensorFlow, DeepSpeed, FSDP, and their applications in training large language models.
Key Takeaways
- Data Parallelism refers to the distribution of data across multiple devices to enable simultaneous processing. This results in faster training and efficient handling of massive datasets and large models.
- In data parallelism, each worker (GPU, CPU, or node) performs the same model operation but on a different data chunk. Results (e.g., gradients) are synchronized and aggregated to maintain consistent model updates across all workers.
- Leading machine learning frameworks such as PyTorch (including DataParallel and DistributedDataParallel), TensorFlow with tf.distribute.Strategy, Horovod, and Ray provide comprehensive APIs for scaling data parallelism effectively. Besides, advanced systems like FSDP and DeepSpeed are designed to handle large-scale models efficiently, offering flexible options for distributed training across different environments.
- Data parallelism works if your model can fit on a single device, and the dataset is large. However, for huge models, model parallelism or hybrid approaches (FSDP, ZeRO) may be necessary to address memory and bandwidth limitations.
- Task parallelism involves running different operations on the same data in parallel, while model parallelism splits the model itself across devices.
What Is Data Parallelism
Data parallelism is a parallel computing technique where the data or computational workload is divided into chunks that are distributed to multiple processing units (typically GPUs). Each device performs the same operation on different subsets of the data simultaneously. Data parallelism boosts training and processing speeds by making better use of concurrent tasks. In other words, with more devices, more data can be processed in the same wall-clock time.
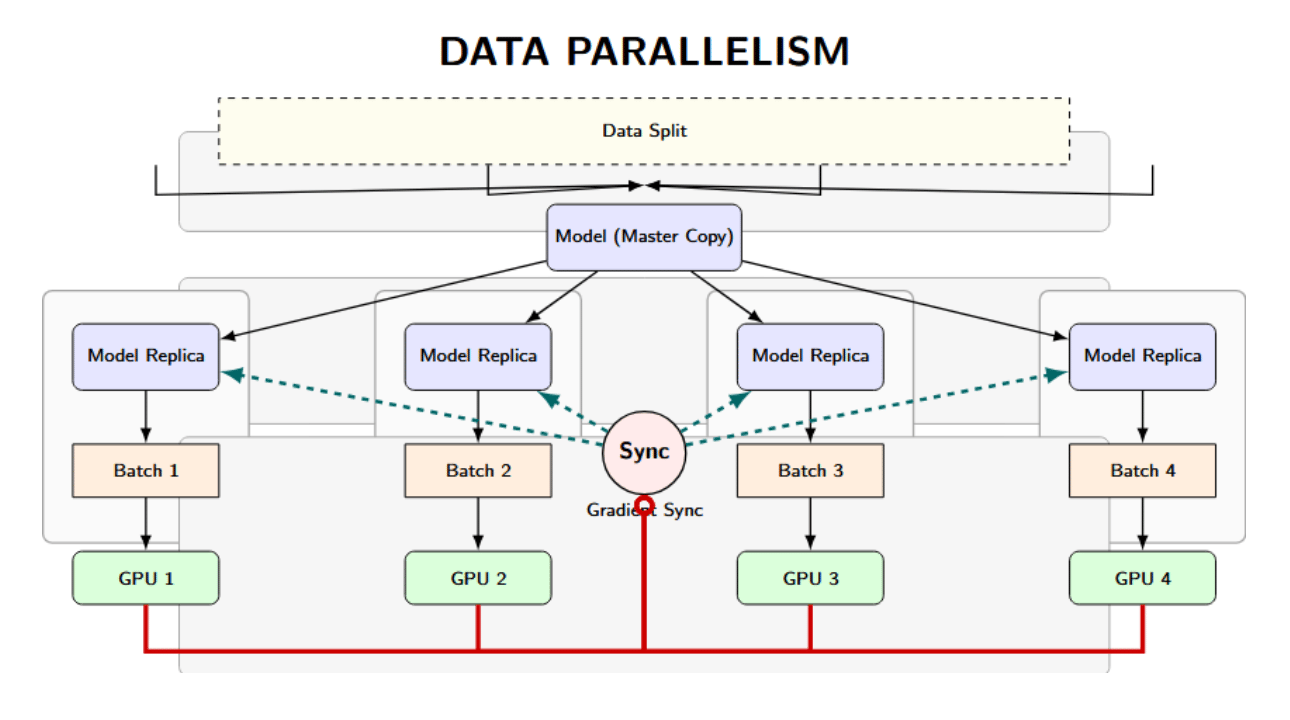
The arrows visualize the parallel and synchronized workflow of data parallelism:
- Downward arrows: Set up and distribute the work and the models.
- Upward/sync arrows: Aggregate results so all model copies learn together.
How Data Parallelism Works
Let’s walk through what a typical data parallelism workflow looks like. We will do this in the context of training an ML model on multiple GPUs (same logic applies for CPUs, multi-node clusters):
- Replicate the Model: First, we load an identical copy of the model (with the same initial weights) on each device (GPU/worker). By doing this, each device processes its own data simultaneously during the forward and backward passes. With 4 GPUs, for example, you will have 4 replicas of the neural network, one per GPU.
- Split the Data: The entire training dataset (or incoming batch of data) is split into N equal-sized chunks, where N is the number of parallel workers (GPUs). Each worker (GPU) receives a different slice of the data. This can be done through a data loader or a special sampler that automatically hands each device a unique subset of the data. So, if we had 4 GPUs, a single batch of 128 samples would be split into 4 sub-batches of 32 samples each.
- Parallel Processing: Each GPU (with its own model replica) processes its data subset in parallel. All the GPUs compute the forward pass (predictions) and backward pass (gradients) simultaneously, without communication during this step. The model replicas get different data. Therefore, each of them will compute (potentially) different gradient updates for the model parameters.
- Gradient Synchronization: After completing local computation for a training step, the workers all synchronize and consistently update the model. In synchronous data parallelism, all GPUs exchange and aggregate the computed gradients. An All-reduce (a collective communication pattern) is often used to sum the gradients from all the processes and distribute the summed gradients back to each process. Practically, deep learning libraries implement gradient synchronization using the Ring All-Reduce algorithm to minimize communication overhead. After this step, each GPU holds the same set of summed gradients, as if the entire batch had been processed on a single device.
- Model Update: Each GPU (or master process) uses the aggregated gradients to update the model weights (e.g., one step of gradient descent or Adam). Since each GPU used the same aggregated gradients, their model parameters remain identical after the update step.
- Repeat: Load the next batch of data and repeat the process (split data, parallel forward/backward, sync, update). Continue until training is complete. Devices will regularly synchronize with each other at the end of each iteration (or at a regular interval) during training, to stay in lockstep on the same model parameters.
The above process makes it possible to work with larger batches more efficiently and reduces training time. If done over multiple machines (distributed data parallelism), the concept is the same, except communications happen over the network instead of within one machine.
Synchronous vs. Asynchronous Data Parallelism
The above describes synchronous data parallel training. When designing distributed machine learning systems, one important question to answer is whether one should synchronize the update across all workers (synchronous training) or allow updates at each worker’s own pace (asynchronous training). The two flavors have their pros and cons with regard to stability, speed, and system complexity. The table below summarizes the core differences:
| Aspect | Synchronous Data Parallelism | Asynchronous Data Parallelism |
|---|---|---|
| How it works | All workers do each step together, then sync | Workers work at their own pace, no syncing |
| Updates | The model is updated only after all workers finish the step | The model is updated as soon as a worker finishes |
| Speed bottleneck | Slowed by the slowest (straggler) worker | Not slowed by any single worker |
| Model consistency | All model copies stay identical | Model copies may be slightly different |
| Stability | More stable, easier to tune and debug | Can be less stable, needs careful tuning |
| Communication | Uses “all-reduce” (direct worker-to-worker) | Uses “parameter server” (central coordinator) |
| Common use cases | Most deep learning frameworks (e.g., DDP, Horovod) | Edge devices, unreliable or mixed-speed clusters |
| When to use | When you need accuracy and consistency | When speed and hardware utilization are critical |
In summary, synchronous data parallelism provides stability and consistent updates, which is the standard choice for most deep learning frameworks, particularly when training with large-scale GPU clusters. Asynchronous data parallelism can achieve the best hardware utilization if the environment is highly heterogeneous or unreliable, but it also requires careful tuning to achieve good convergence.
Comparing Data and Task Parallelism
Data parallelism is different from task parallelism. While they both fall under the parallel computing model umbrella, they refer to different strategies:
Data Parallelism: All workers are doing the same task or operation, but on different subsets of the data simultaneously. For example, suppose you have a large array of numbers to sum. On a dual-core system using data parallelism, Thread A could be summing the first half of the array, while at the same time, Thread B sums the second half. Once both threads are completed, we will combine the partial results from each to get the final sum of the entire array. Each thread performed the same summation operation on a different data chunk.
Task Parallelism: Multiple workers (threads or processes) perform distinct tasks, on the same or different subsets of data, in parallel. For instance, given an input dataset, Thread A is filtering the data, while Thread B is sorting it simultaneously. They are both performing different operations at the same time (filtering vs sorting).
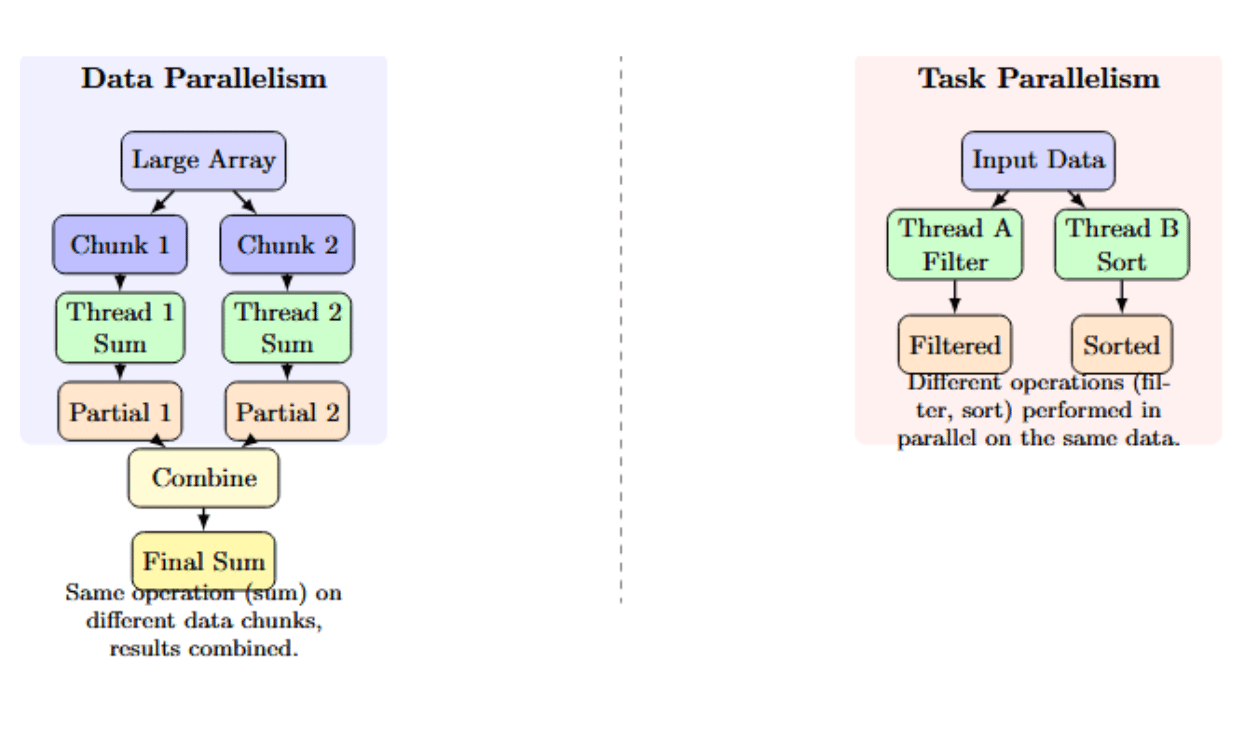
In summary:
- Data parallelism = same work, different subsets of data.
- Task parallelism = Multiple work, same or different subsets of data.
The two forms can be combined in a complex system, but understanding the distinction is useful when designing parallel algorithms or distributed ML training approaches.
Understanding the Difference: Data Parallelism and Model Parallelism
In contrast to data parallelism, where we split the data across copies of a model, model parallelism splits the model across multiple devices. Model parallelism is useful when a model is too large to fit in a single device’s memory, or to further accelerate computation by parallelizing different parts of the model’s operations. The distinction between the two can be made by presenting them side-by-side:
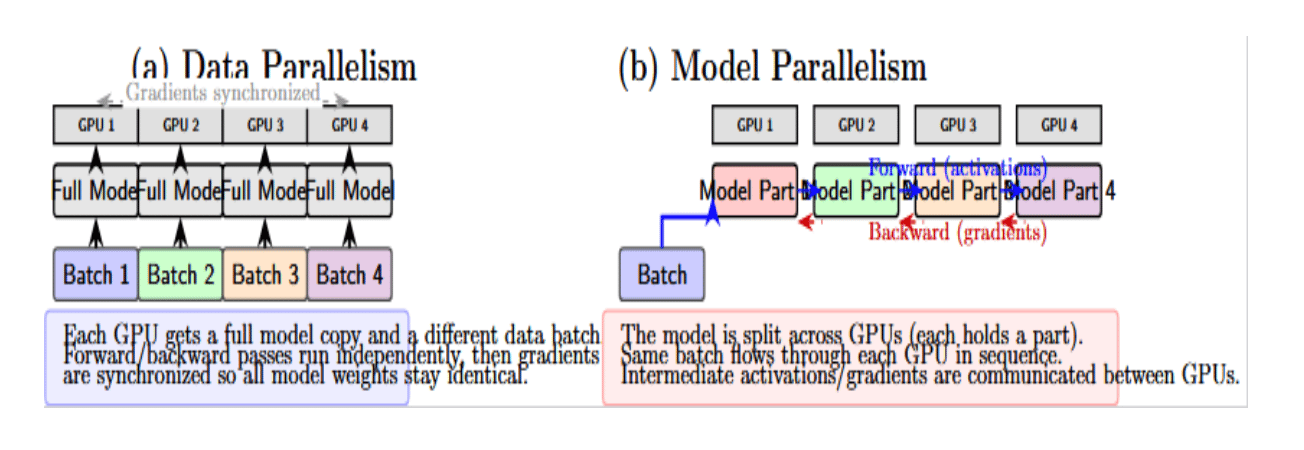
In simpler terms:
- Data parallel = clone the model and split the data into subsets.
- Model parallel = split the model, clone the data (each device often gets the full dataset or batch).
Data Parallelism: Key Advantages and Limitations
Data parallelism is a popular strategy for accelerating machine learning and deep learning. However, it has its own trade-offs that you must be aware of. Here is a detailed comparison of its key benefits and drawbacks:
| Pros | Cons |
|---|---|
| Speed-Up and Efficiency Tasks complete faster by dividing work over multiple processors. For large workloads, data parallelism can achieve near-linear speed-up as resources increase. | Memory Overhead Each worker holds a full copy of the model or data, causing duplicated memory usage and limiting scalability for very large models. |
| Simplicity of Replication The same code or model runs on each worker; frameworks handle splitting and merging, so you usually don’t need major code changes. | Communication Overhead Combining results (like synchronizing gradients) adds network traffic, which can become a bottleneck as model or cluster size grows. |
| Scalability Easy to handle more data or bigger models by adding more workers; widely used for scaling to hundreds or thousands of machines. | Synchronization Penalty In synchronous setups, the fastest workers must wait for the slowest, making performance sensitive to hardware imbalance or stragglers. |
| Fault Isolation If one worker fails, only its portion of the data is lost. With checkpointing, work can resume with minimal loss, improving reliability. | Diminishing Returns Adding more workers eventually yields less benefit due to communication and merge overhead, and can affect ML model quality if batches become too large. |
| Balanced Workload Splitting by data often naturally balances the work (assuming data complexity is uniform), keeping all processors equally busy. | Applicability Not all problems split easily by data; tasks with strong dependencies or that require global state need different parallelization strategies. |
Data parallelism can really help speed up and scale your machine learning workflows, making the entire process much more efficient. However, it also comes with additional system overhead, complexity, and tuning requirements. Evaluate these factors carefully to find the best solution for your workload.
Implementations and Frameworks for Data Parallelism
Several frameworks and tools are available to help simplify data parallel computing. PyTorch provides two main methods to parallelize training.
DataParallel: DataParallel is a simple API for training a model on multiple GPUs with a single machine. It slices the input batch data across the provided devices, runs the computation in parallel, and then gathers and returns the results. However, it’s not very efficient when used on multiple nodes and can create a bottleneck on the main process.
DistributedDataParallel: If you need a highly scalable and efficient way to do multi-GPU and multi-node training, you can use the DistributedDataParallel module. In this mode, each process runs a replica of the model on a single GPU and then performs an all-reduce operation across all processes to synchronize the gradients after each backward pass. We recommend using this API to scale the training to multiple machines. Example Pseudo Code:
import torch
import torch.nn as nn
# DataParallel usage (single machine, multiple GPUs)
model = nn.DataParallel(MyModel())
output = model(input)
# DistributedDataParallel usage (scalable, multi-GPU)
import torch.distributed as dist
dist.init_process_group(backend="nccl")
model = nn.parallel.DistributedDataParallel(
MyModel().to(local_rank), device_ids=[local_rank]
)
The code wraps a model for parallel execution. With DataParallel, the model splits the input batch and computes results on each device. DistributedDataParallel synchronizes gradients across multiple processes.
TensorFlow: tf.distribute.Strategy
TensorFlow has a unified API for distributed training with the tf.distribute.Strategy module. It provides an abstraction to scale training workloads across different hardware configurations with minimal code changes. The following strategies are available:
- MirroredStrategy: It is used for synchronous training on multiple GPUs on a single machine.
- MultiWorkerMirroredStrategy: Synchronous training on multiple machines with one or more GPUs per machine.
- TPUStrategy: It supports distributed training on TPU clusters.
- ParameterServerStrategy: It is used for asynchronous training with parameter servers.
- CentralStorageStrategy: (Experimental) Stores variables on a single device for some special use cases.
Example Pseudo Code:
import tensorflow as tf
# Example: Synchronous multi-GPU training
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = build_model(...)
model.fit(dataset, epochs=..., ...)
This code will automatically split batches and aggregate gradients behind the scenes.
Horovod: Distributed Training Across Clusters
Horovod is a framework-agnostic library for large-scale distributed deep learning. It can be used with TensorFlow, PyTorch, and MXNet. It also simplifies the distributed training of deep learning models across multiple GPUs, nodes, and clusters. Horovod relies on high-performance communication libraries like MPI(Message Passing Interface) and NCCL to synchronize the gradients. Key features of Horovod include:
- Minimal code changes to scale from a single GPU to multi-node clusters.
- Approach linear scaling with an increase in resources.
- It incorporates gradient compression and fault tolerance solutions for performance optimization.
- Data and model parallelism support.
Example Pseudo Code:
import horovod.torch as hvd
hvd.init()
model = MyModel().to(hvd.local_rank())
optimizer = optim.Adam(model.parameters(), lr=0.001 * hvd.size())
# Wrap the optimizer with Horovod DistributedOptimizer
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# Synchronize model parameters across workers
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
The code snippet initializes Horovod for distributed training, where the optimizer’s learning rate is scaled by the number of workers. It also synchronizes the model parameters across all processes. Horovod’s DistributedOptimizer handles gradient averaging and update synchronization across multiple GPUs or nodes efficiently.
Ray: Parallel Data Processing and Orchestration
Ray is a general-purpose distributed execution framework that’s not limited to deep learning. It can be used for parallel and distributed training for various machine learning and data processing tasks.
Ray’s features include:
- Orchestrating distributed training workloads for PyTorch, TensorFlow, and more.
- It supports parallel data processing operations, hyperparameter tuning, and reinforcement learning techniques.
- Ray offers native APIs to manage distributed deep learning workloads.
Ray is flexible and easy to use, making it a common choice for building complex, scalable machine learning pipelines. Let’s examine an example in Python of a distributed training program using Ray, which runs a simple training loop in parallel across multiple workers.
pip install ray
import ray
import numpy as np
# Initialize Ray
ray.init()
# Dummy training function to simulate model training on a data shard
@ray.remote
def train_worker(data_shard):
# Initialize model weights randomly
weights = np.random.rand(10)
# Dummy "training": update weights with mean of the data shard
for batch in data_shard:
weights += batch.mean(axis=0) * 0.01
return weights
# Generate dummy data and split into shards
num_workers = 4
data = [np.random.rand(100, 10) for _ in range(num_workers)] # 4 shards of data
# Launch training jobs in parallel
results = [train_worker.remote(shard) for shard in data]
# Collect the results (trained weights) from all workers
trained_weights = ray.get(results)
# Aggregate weights (simple average)
final_weights = np.mean(trained_weights, axis=0)
print("Aggregated model weights:", final_weights)
How it works:
- Each Ray worker receives a data shard and performs a simple “training” update.
- All workers run in parallel.
- Results are aggregated (averaged) at the end, simulating model weight synchronization.
You can replace the body of train_worker with your real training code (using PyTorch, TensorFlow, etc).
Advanced Parallelism for Large Models
As models scale to billions of parameters, traditional data parallelism faces key challenges: It becomes impractical to keep many replicas of a large model in memory. This has spawned more advanced strategies that involve data and model parallelism or sharding to manage LLMs and other massive networks.
Fully Sharded Data Parallel
FSDP is a strategy (developed by Facebook AI Research) that shards a model’s parameters, gradients, and optimizer state across the data parallel workers instead of replicating them entirely on each worker. Each GPU stores only a subset of the model’s parameters at any given time.
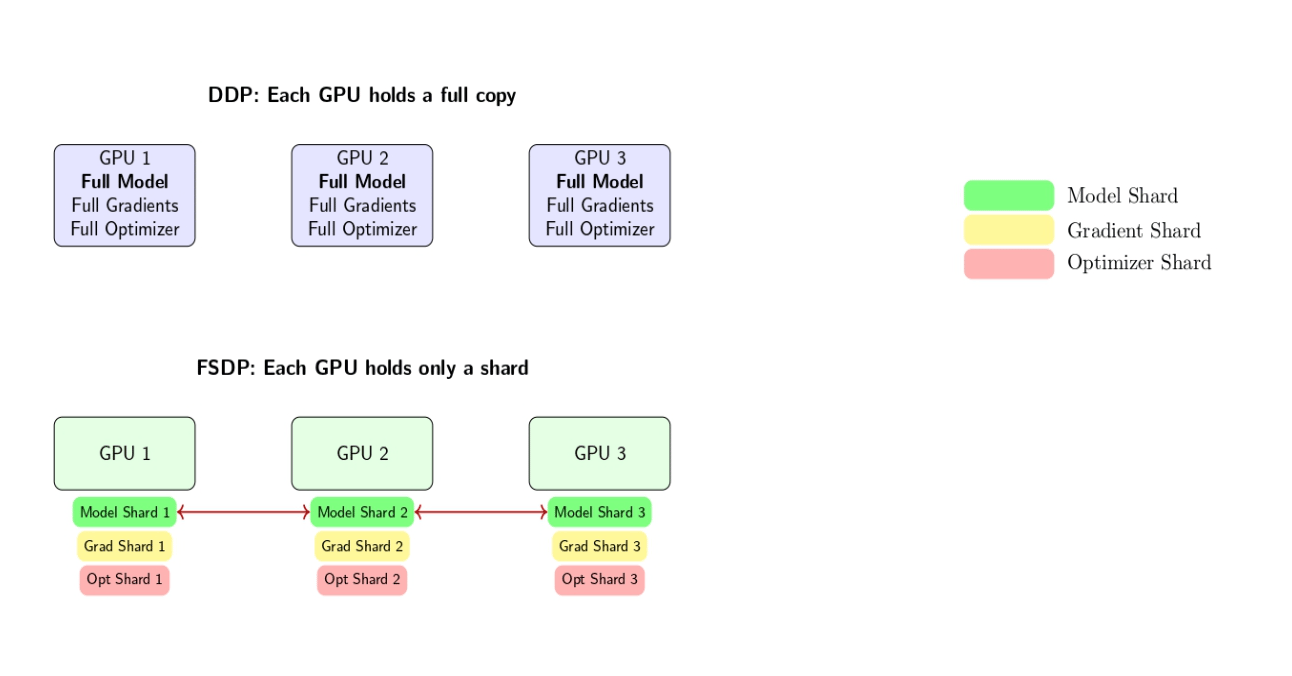
Key steps in FSDP:
- Each GPU only stores a shard of the model’s parameters, gradients, and optimizer state.
- Before a forward or backward pass, each GPU gathers the required parameter shards to assemble the complete model just in time for computation.
- After the forward or backward pass, the extra shards are discarded, leaving only the locally stored shard to reduce the memory footprint.
- Gradients are reduced-scattered so that each GPU only retains its shard of the gradients.
DeepSpeed (ZeRO)
DeepSpeed is another deep learning library for optimization from Microsoft that is most well-known for its ZeRO (Zero Redundancy Optimizer) set of techniques. ZeRO and FSDP share the same underlying principle, as both of them aim to remove redundancy in data parallelism. ZeRO has multiple stages:
- Stage 1 partitions the optimizer states only across available devices to reduce memory duplication.
- Stage 2 partitions the optimizer states and gradients for more memory savings.
- Stage 3 Partitions optimizer states, gradients, and parameters, for full sharding of the model and memory distribution.
ZeRO Stage 3 shards the main memory-consuming elements—optimizer states, gradients, and parameters across devices. Practically, it is identical to the FULL_SHARD memory strategy of PyTorch’s FSDP implementation. This makes it possible to scale up to much larger models, which previously couldn’t run effectively on standard hardware.
vLLM
FSDP and DeepSpeed are primarily focused on training, but let’s look at an example of parallelism applied to serving large language models. vLLM is an open-source, high-performance inference engine that accelerates the serving of transformer-based LLMs by optimizing GPU memory usage and enabling distributed execution. It introduces a technology called PagedAttention that supports dynamic swapping of GPU memory for the attention cache. It allows batching and parallel processing of many requests with low latency. vLLM also supports tensor parallelism and pipeline parallelism across GPUs for inference.
FAQ SECTION
What is data parallelism in machine learning? It refers to the technique of running multiple copies of a model on different hardware (GPUs or nodes), where each copy is processing a different data batch. Gradients are synchronized so learning is consistent with single-device training.
How does data parallelism differ from model parallelism? Data parallelism involves splitting data across multiple copies of the entire model, while model parallelism splits the model across different devices, each working on a part of the computation.
What are the advantages of data parallelism? Simplicity, great scalability for large datasets, easy integration with modern ML frameworks, and compatibility with existing training loops.
Which frameworks support data parallelism? Some popular machine learning frameworks that support data parallelism include PyTorch (via DataParallel and DistributedDataParallel), TensorFlow (via tf.distribute.Strategy), and more specialized libraries such as Horovod and Ray Train.
When should I use data parallelism?
Use data parallelism when you have large datasets, your model fits into a single GPU memory, and you want to leverage multiple GPUs to reduce training time.
Conclusion
Data parallelism is a foundational technique to scale machine learning/deep learning workloads. With increasing data and model sizes, practitioners use data parallelism to scale up across many GPUs/nodes/clusters to train models more quickly and run larger experiments that would otherwise be infeasible.
While data parallelism offers clear benefits, it is important to consider the system overheads, communications, and memory requirements of model replicas.
There are many considerations when choosing the right approach, whether that be pure data parallelism, model parallelism, or more advanced hybrid methods (e.g., FSDP, DeepSpeed, etc), depending on your model size, hardware, and scaling requirements.
If you’d like to go deeper, check out these resources:
- Splitting LLMs Across Multiple GPUs
- PyTorch Memory and Multi-GPU Debugging
- Optimizing Deep Learning Pipelines
- CPU vs. GPU: A Deep Learning Perspective
By understanding and applying the right parallelism strategies and frameworks, you can unlock efficient, scalable training and deployment for today’s most demanding AI workloads.
References and Resources
- Distributed Inference and Serving
- ZeRO & DeepSpeed
- Fully Sharded Data Parallel: faster AI training with fewer GPUs
- What is Distributed Data Parallel (DDP)
- Harnessing the Power of Parallelism for Faster Deep Learning Model Training with TensorFlow
- Ray
- Distributed training with TensorFlow
- Data parallelism vs Task parallelism
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
