
Introduction
Using containers for GPU workloads requires installing the Nvidia container toolkit and running Docker with additional flags. This tutorial explains how to set up the Nvidia container toolkit, run Docker for GPU workloads, and install Miniconda to manage Python environments. This guide focuses on PyTorch usage with GPU Droplets on DigitalOcean.
Why Use a GPU Droplet?
DigitalOcean’s GPU Droplets are NVIDIA H100s that you can spin up on-demand—try them out by spinning up a GPU Droplet today.
Step 1 - Set Up the GPU Droplet
-
Create a GPU Droplet-Log into your DigitalOcean account, create a new GPU Droplet with the OS Image set as “AI/ML Ready v1.0”, and choose a GPU plan.
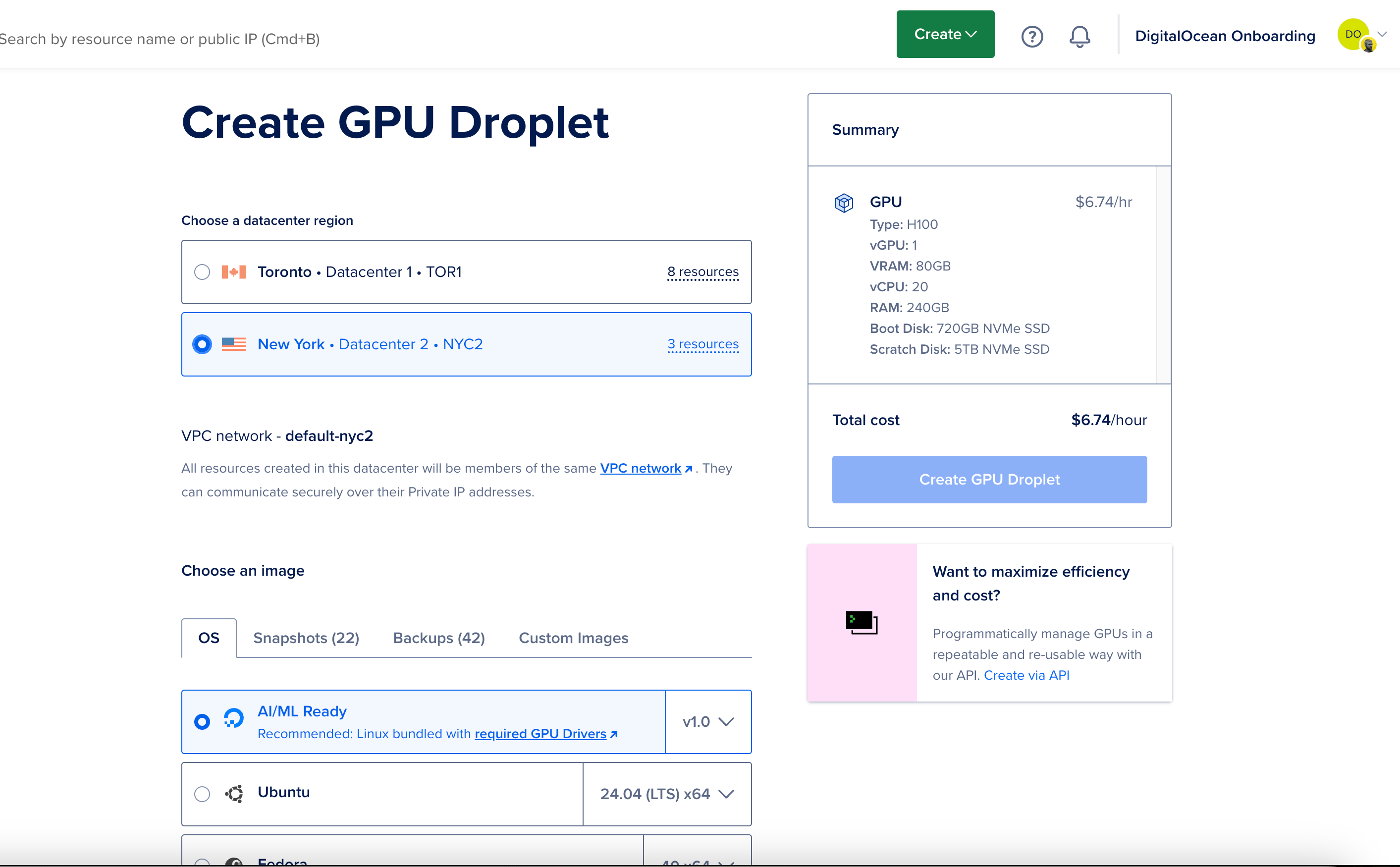
Once the GPU Droplet is created, log into its console.
-
Add a New User (Recommended)-Instead of using the root user for everything, it’s better to create a new user for security reasons:
- adduser do-shark
- usermod -aG sudo do-shark
- su do-shark
- cd ~/
Step 2 — Installing the Nvidia Container Toolkit
Using containers for GPU workloads requires installing the Nvidia container toolkit and running docker with additional flags.
Install the Toolkit and Docker
The Nvidia container toolkit replaced the previous wrapper named nvidia-docker. You can install the toolkit and Docker with the following command:
- sudo apt-get install docker.io nvidia-container-toolkit
Enable the Nvidia Container Runtime
Run the following command to enable the Nvidia container runtime:
- sudo nvidia-ctk runtime configure --runtime=docker
Restart Docker
After enabling the runtime, restart Docker to apply the changes:
- sudo systemctl restart docker
Step 3 — Running a PyTorch Container (Single Node)
When running PyTorch in a container, Nvidia recommends using specific Docker flags for sufficient memory allocation.
--gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864
These flags are responsible for:
–gpus all: Enables GPU access for the container.
–ipc=host: Allows the container to use the host’s IPC namespace.
–ulimit memlock=-1: Removes the limit on locked-in-memory address space.
–ulimit stack=67108864: Sets the maximum stack size to 64MB.
To confirm that PyTorch is working correctly in a containerized environment, run the following command:
- sudo docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/pytorch:24.08-py3 python3 -c "import torch;print('CUDA available:', torch.cuda.is_available())"
The above docker invocation will confirm pytorch is working correctly in a containerized environment. The final print from the execution should show “CUDA available: True”.
Output=============
== PyTorch ==
=============
NVIDIA Release 24.08 (build 107063150)
PyTorch Version 2.5.0a0+872d972
Container image Copyright (c) 2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2024 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
The NVIDIA Deep Learning Container License governs this container image and its contents.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
NOTE: CUDA Forward Compatibility mode ENABLED.
Using CUDA 12.6 driver version 560.35.03 with kernel driver version 535.183.01.
See https://docs.nvidia.com/deploy/cuda-compatibility/ for details.
CUDA available: True
Step 4 — Running a PyTorch Container (Multi-Node)
Use the same base arguments for multi-node configurations as for the single-node setup, but include additional bind mounts to discover the GPU fabric network devices and NCCL topology.
--gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --network=host --volume /dev/infiniband:/dev/infiniband --volume /sys/class/infiniband/:/sys/class/infiniband/ --device /dev/infiniband/:/dev/infiniband/ -v /etc/nccl.conf:/etc/nccl.conf -v /etc/nccl:/etc/nccl
These flags are responsible for:
– gpus all: Enables access to all available GPUs in the container.
– ipc=host: Uses the host’s IPC namespace, allowing better inter-process communication.
– ulimit memlock=-1: Removes the limit on locked-in-memory address space.
– ulimit stack=67108864: Sets the maximum stack size to 64MB.
– network=host: Uses the host’s network stack inside the container.
– volume /dev/infiniband:/dev/infiniband: Mounts the InfiniBand devices into the container.
– volume /sys/class/infiniband/:/sys/class/infiniband/: Mounts InfiniBand system information.
– device /dev/infiniband/:/dev/infiniband/: Allows the container to access InfiniBand devices.
– -v /etc/nccl.conf:/etc/nccl.conf: Mounts the NCCL (NVIDIA Collective Communications Library) configuration file.
– -v /etc/nccl:/etc/nccl: Mounts the NCCL directory for additional configurations.
To confirm that PyTorch is functioning in a containerized multi-node environment, execute the following command:
- sudo docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --network=host --volume /dev/infiniband:/dev/infiniband --volume /sys/class/infiniband/:/sys/class/infiniband/ --device /dev/infiniband/:/dev/infiniband/ -v /etc/nccl.conf:/etc/nccl.conf -v /etc/nccl:/etc/nccl nvcr.io/nvidia/pytorch:24.08-py3 python3 -c "import torch;print('CUDA available:', torch.cuda.is_available())"
The above docker invocation will confirm that PyTorch is working correctly in a containerized multi-node environment. The final print from the execution should show “CUDA available: True”.
Output=============
== PyTorch ==
=============
NVIDIA Release 24.08 (build 107063150)
PyTorch Version 2.5.0a0+872d972
Container image Copyright (c) 2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2024 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
NOTE: CUDA Forward Compatibility mode ENABLED.
Using CUDA 12.6 driver version 560.35.03 with kernel driver version 535.183.01.
See https://docs.nvidia.com/deploy/cuda-compatibility/ for details.
CUDA available: True
Step 5 — Installing Miniconda
Miniconda is a lightweight version of Anaconda, providing an efficient way to manage Python environments. To install Miniconda, follow these steps:
Download and Install Miniconda
Use the following commands to download and install Miniconda.
- mkdir -p ~/miniconda3
- wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
- bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
- rm -rf ~/miniconda3/miniconda.sh
Initialize Miniconda
- ~/miniconda3/bin/conda init bash
Exit and log back in to apply the changes.
- exit
Now log back in as the do-shark user.
- su do-shark
Verify the conda version.
- conda --version
Outputconda 24.7.1
Step 6 — Setting Up a PyTorch Environment with Miniconda
With Miniconda installed, you can set up a Python environment for PyTorch:
Create and Activate a New Environment
- conda create -n torch python=3.10
- conda activate torch
Install PyTorch
To install PyTorch with CUDA support, use the following command. CUDA, which stands for Compute Unified Device Architecture, is a parallel computing platform and programming model for general computing on graphical processing units (GPUs).
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
Conclusion
You have successfully set up Nvidia Container Toolkit and Miniconda on your DigitalOcean GPU Droplet. You are now ready to use containerized PyTorch workloads with GPU support. For further information, you can explore the official documentation for Nvidia’s Deep Learning Containers and PyTorch.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I help Businesses scale with AI x SEO x (authentic) Content that revives traffic and keeps leads flowing | 3,000,000+ Average monthly readers on Medium | Sr Technical Writer(Team Lead) @ DigitalOcean | Ex-Cloud Consultant @ AMEX | Ex-Site Reliability Engineer(DevOps)@Nutanix
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
