By Adrien Payong and Shaoni Mukherjee

Introduction
Modern artificial intelligence relies on neural networks to analyze patterns and make smart decisions. This guide will provide a fundamental explanation of neural networks, including their working principles and training techniques.
We will explore critical neural network concepts such as neurons, layers, activation functions, and backpropagation through examples(like the XOR problem and MNIST handwritten digit recognition). Along the way, we’ll compare different types of neural networks while pointing out typical training errors and addressing popular questions to assist you in your deep learning journey.
Key Takeaways
- Neural networks mimic the human brain to process and learn from data, forming the backbone of modern AI systems.
- Core components include:
- Input layer – receives raw data features.
- Hidden layers – process inputs through weighted connections and activation functions.
- Output layer – produces final predictions or classifications.
- Weights and biases – adjust during training to minimize error.
- Activation functions – introduce non-linearity (e.g., ReLU, sigmoid).
- Loss function – measures how far predictions are from actual values.
- Optimizer – updates weights to reduce loss (e.g., SGD, Adam).
- Training involves forward and backward propagation, where the model iteratively adjusts weights to minimize prediction error.
- Hyperparameter tuning and data preprocessing are critical for optimizing performance and avoiding overfitting.
- Neural networks power real-world applications like image recognition, natural language processing, and recommendation systems.
- Types of neural networks serve different purposes:
- Feedforward Neural Networks (FFNNs) – simplest form, where data flows one way.
- Convolutional Neural Networks (CNNs) – excel in image and spatial data analysis.
- Recurrent Neural Networks (RNNs) – designed for sequential data like time series or text.
- Understanding the building blocks—layers, activation functions, loss functions— lays the foundation for exploring advanced AI models.
Prerequisites
- Understand basic mathematical structures such as vectors, matrices, and matrix multiplication.
- Understand the chain rule for backpropagation, gradients, and partial derivatives.
- Familiarity with probability distributions and statistical concepts such as variance, and common loss(e.g., cross-entropy, MSE).
- Proficiency in Python plus experience with numerical and ML libraries like NumPy, TensorFlow, or PyTorch.
- Knowledge of supervised learning, training/validation/test splits, overfitting vs. underfitting, and basic model evaluation metrics.
What Is a Neural Network?
A neural network, often called an artificial neural network (ANN), represents machine learning models drawing their design inspiration from the human brain. This configuration involves several layers of interconnected “neurons” (nodes), processing input data to generate useful results. Each neuron takes input from the preceding layer, applies weights, and uses an activation function to produce outputs that feed into the next layer. This mechanism enables neural networks to analyze raw data and progressively extract complex features.
Neural networks function as programs that detect patterns in data to make predictions and decisions. For example, a trained neural network can analyze an image input to generate a label that identifies the object within it.
Key Components of a Neural Network
To understand how neural networks work, let’s break down their basic components:
Layers (Input, Hidden, Output)
Neural networks organize neurons into layers. The input layer of a neural network receives the raw data inputs (e.g., image pixels or dataset features). Hidden layers transform data through weight and activation function processes. The output layer provides the network’s final prediction through outputs like class labels or numerical values.
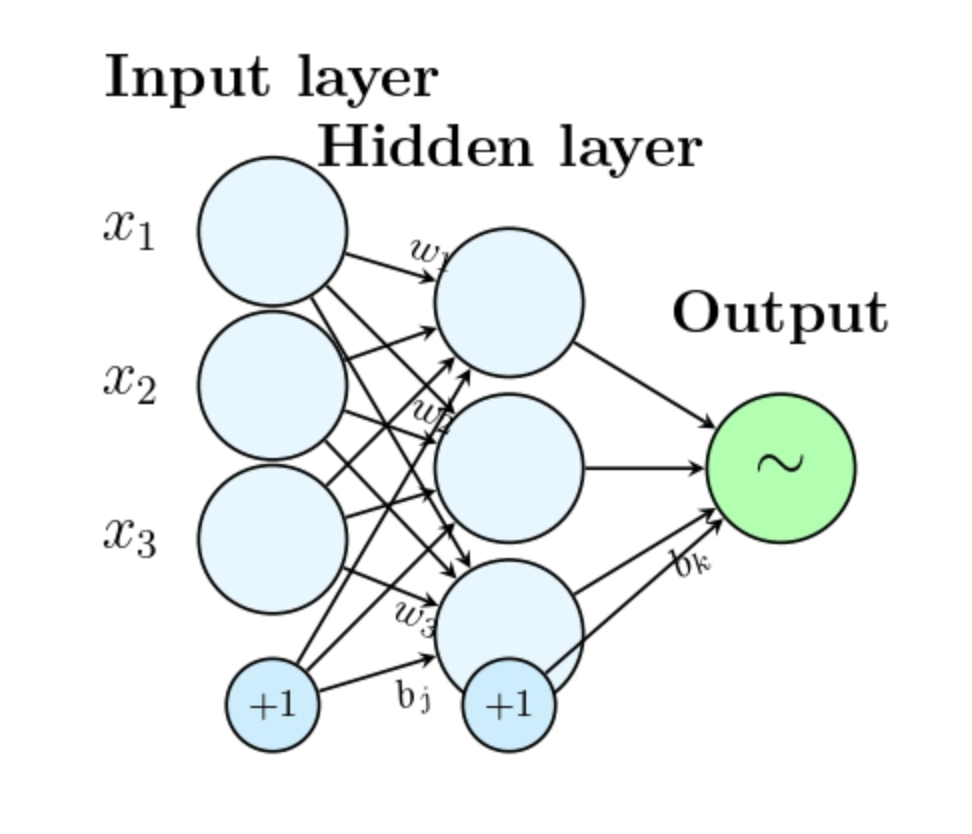
Neurons and Weights Every neuron operates as a computation unit that takes input, multiplies each by its corresponding weight, sums them, and adds a bias term if applicable. Weights are parameters that determine the importance of each input. The training process involves adjusting these weights to minimize the network’s error rate.
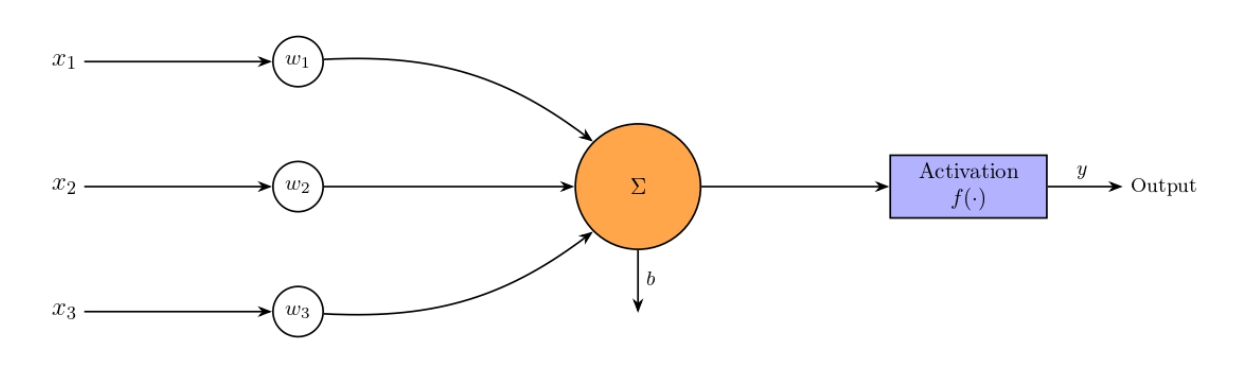
Activation Function Once the weighted sum is computed, the neuron uses an activation function to determine its output. The network requires this non-linear property to learn beyond simple linear relationships. Common activation functions include:
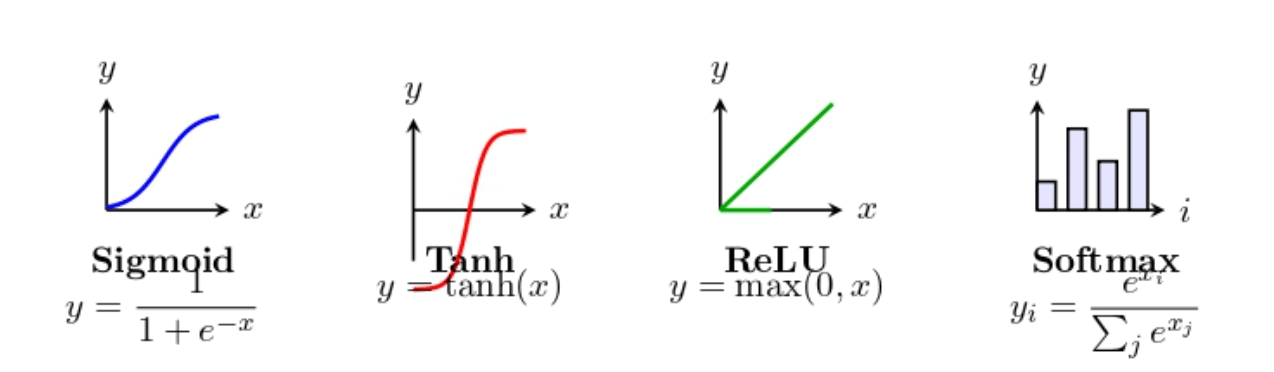
- Sigmoid and tanh transform outputs into ranges between 0 to 1 or -1 to 1.
- ReLU provides 0 for negative inputs and linear values for positive inputs.
- Softmax serves output layers by generating class probabilities.
Output
Output layer neurons provide the final prediction results. The output layer of a classification task consists of multiple neurons, each representing a different class (applying softmax to generate class probabilities). The output layer of a regression task might include a single neuron that produces a continuous value.
How Backpropagation Drives Learning
Training a neural network involves teaching it to perform specific tasks (such as image classification or trend forecasting) through example training data. The learning process commonly follows the following steps:
Forward Pass
The network’s input layer receives the input data, which moves through multiple hidden layers to produce the final output. This process is called forward propagation.
Calculate Loss
We assess the network’s output by comparing it to the expected output. Using a loss function (e.g., mean squared error in regression or cross-entropy in classification), we compute the loss, which indicates how much the prediction deviates from the actual result.
Backpropagation
Backpropagation improves the network by adjusting its weights based on the loss. Once the network makes a prediction(during the forward pass), the backpropagation algorithm starts its backward journey to evaluate each weight’s contribution to the error. It then makes small tweaks to reduce that error. We achieve this by applying calculus—specifically, the chain rule—to compute gradients, which guide how each weight should be updated to minimize the loss.
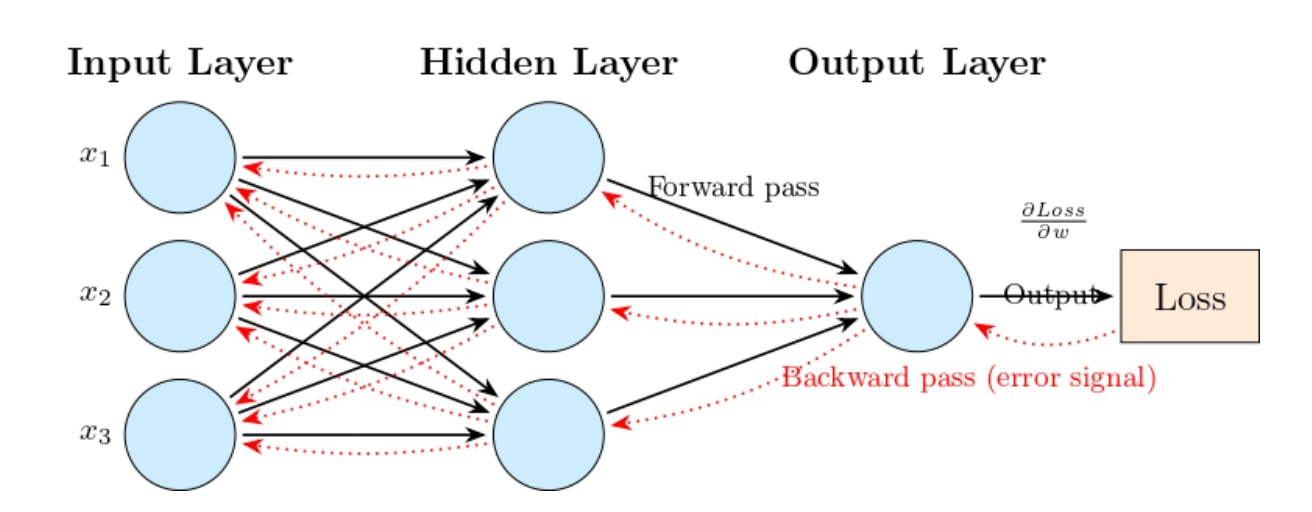
Red dotted arrows show the “backpropagation” (backward pass) from right to left—loss back through output, hidden, and input layers.
Weight Update
The optimization algorithm (e.g., gradient descent or Adam) applies these gradients to adjust weights. The goal of these adjustments is to reduce the prediction error. The optimizer adjusts each weight upwards or downwards to enhance the accuracy of subsequent predictions.
Repeat for Many Iterations The forward-pass and backpropagation steps undergo multiple iterations across the entire dataset. An epoch is defined as a complete pass through the entire training dataset. Training processes typically require multiple epochs. During training sessions, models use separate validation data to track performance metrics and prevent overfitting.
Python Demo: Learn y = 2x with a Single Neuron
This simple Python demonstration guides you through each previous step in an easy-to-understand format:
import numpy as np
# Simple backprop for one neuron learning y = 2*x
# 1. Data
x = np.array([1.0, 2.0, 3.0, 4.0])
y = 2 * x # true outputs
# 2. Initialize parameters
w = 0.0 # weight
b = 0.0 # bias
lr = 0.1 # learning rate
print(f"{'Epoch':>5} {'Loss':>8} {'w':>8} {'b':>8}")
print("-" * 33)
# 3. Training loop
for epoch in range(1, 6):
# Forward pass: compute predictions
y_pred = w * x + b
# Compute loss (mean squared error)
loss = np.mean((y_pred - y) ** 2)
# Backward pass: compute gradients
dw = np.mean(2 * (y_pred - y) * x) # ∂Loss/∂w
db = np.mean(2 * (y_pred - y)) # ∂Loss/∂b
# Update parameters
w -= lr * dw
b -= lr * db
# Print progress
print(f"{epoch:5d} {loss:8.4f} {w:8.4f} {b:8.4f}")
Output:
Epoch Loss w b
---------------------------------
1 30.0000 3.0000 1.0000
2 13.5000 1.0000 0.3000
3 6.0900 2.3500 0.7400
4 2.7614 1.4550 0.4170
5 1.2653 2.0640 0.6061
- Data: We want our neuron to learn y=2x.
- Parameters: w and b are both set to zero.
- Forward pass: Compute your guesses y^=w x+b.
- Loss: We measure the error using mean squared error.
- Backward pass: we compute how much to change w and b by computing their gradients.
- Update: Apply a small adjustment to w and b by multiplying the gradient with the learning rate.
- Repeat: The loss decreases and w gets closer to 2 while b moves toward 0.
How to Train a Neural Network
Though it appears complex, neural network training follows well-defined recipes. We will go through the basic steps to train a neural network:
Gather and Prepare Data Choose a dataset that matches your task requirements. Supervised learning tasks require a labeled dataset as input. This could be a labeled dataset for supervised learning (e.g., images with labels, or a spreadsheet of examples). The dataset should be divided into a training set for model learning and a test set for final evaluation. During training, allocate a separate validation set for tuning model parameters. Normalize numerical features and scale pixel values to the [0,1] range, encode categorical labels (e.g. one-hot encoding for multi-class labels), etc. Proper data preparation accelerates network training time and enhances performance.
Choose a Model Architecture
Choose the neural network type and its architecture. How many input features? How many layers and neurons? What activation functions? If you are building a basic classifier, you can start with a feed-forward network that contains one or two hidden layers.
You can choose CNNs for image processing, whereas RNNs are better suited for handling text or time-series data.
Initialize Weights and Biases
Neural network libraries handle this process, but initial weights are set to small random values. The random values break symmetry between neurons to prevent identical learning patterns. These values are typically generated from suitable distributions like Gaussian or uniform, depending on the type of layer. Setting all initial weights to zero is not recommended, as it hinders effective training.
Select a Loss Function and Optimizer
Choose a loss function that fits your specific task requirements. You can use cross-entropy loss when performing classification tasks and mean squared error for regression tasks.
Then choose the optimizer. It is the algorithm responsible for updating weights to reduce the loss. Stochastic Gradient Descent and Adam remain the top selections among other optimizers. You will need to configure hyperparameters such as the learning rate, which determines the size of weight updates, and the batch size, which indicates how many examples are processed during each forward/backpropagation pass.
Forward Pass
The framework manages the batch of training through the network. Current network weights determine the outputs/predictions produced by the network.
Calculate Loss
This involves comparing the network’s outputs against the true target values for that batch.
Backward Pass (Backpropagation) During backpropagation, the framework computes how the loss changes with respect to each weight in the network.
Update Weights The optimizer adjusts the weights and biases using the computed gradients. For example, SGD updates each weight by subtracting the product of the learning rate and the gradient from the current weight value. This completes one training iteration for that batch.
Repeat for Many Iterations Keep inputting new data batches and repeatedly perform forward and backward propagation. The loss value should typically decrease over time. The validation set performance should be tracked to identify potential overfitting.
Tune Hyperparameters as Needed
If the model struggles to learn effectively, consider adjusting the learning rate, testing other optimizers, and increasing the number of neurons or layer depth.
Evaluate the Test Set Once you’ve completed sufficient training epochs or if validation performance stops improving, evaluate the finalized model using the hold-out test set. Testing the final model on the hold-out test set provides an unbiased estimate of its performance on new, unseen data.
Training a Neural Network on MNIST (Handwritten Digits)
To illustrate the training process, we will build a basic feed-forward neural network using the MNIST dataset. The following steps will adhere to the training process described previously:
Load and preprocess data
We start by loading the MNIST dataset and reshaping each 28x28 pixel image into a 784-dimensional vector. We improve training efficiency by scaling pixel values from the range 0-255 to 0-1. Then we partitioned the dataset into separate training and test sets.
import tensorflow as tf
from tensorflow.keras import layers
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Preprocess: flatten 28x28 images to 1D, normalize pixel values
x_train = x_train.reshape(-1, 784).astype("float32") / 255.0
x_test = x_test.reshape(-1, 784).astype("float32") / 255.0
Define the model
We choose a network architecture. Our network architecture starts with 784 input values that move through a neural layer with 128 neurons using ReLU activation. The network ends with an output layer with 10 neurons and utilizes Softmax activation. This setup produces a probability distribution across the ten digit classes.
# Define a simple feed-forward neural network
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(784,)), # hidden layer
layers.Dense(10, activation='softmax') # output layer for 10 classes
])
Compile the model
We’ll choose an appropriate loss function, such as SparseCategoricalCrossentropy, which works well with integer labels or one-hot encoded labels used with Softmax outputs. We can apply the Adam optimizer, a well-known gradient descent variant. We will also track accuracy as a metric.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Train the model
The fit function allows us to train the model for a fixed number of epochs(e.g. 5) while using a batch size (e.g., 32). We can provide a validation_split parameter of 0.1 to monitor validation accuracy during model training or use a distinct validation dataset.
# Train the model for 5 epochs
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.1)
Evaluate the model
After training, we evaluate the model against the test set to assess its performance on unseen data.
# Evaluate on test data
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test accuracy: {test_acc:.4f}")
This network reaches approximately 97% accuracy on the test set, after training for 5 epochs. While a deeper network or a CNN would enhance accuracy, this network already properly identifies the majority of handwritten digits.
Solving the XOR Problem
We will explore how solving the traditional XOR problem demonstrates these fundamental principles. The XOR operation returns 1 if its two binary inputs are different (for instance, 0 XOR 1 produces 1). However, it returns 0 if both binary inputs are identical (such as 1 XOR 1 results in 0). The XOR problem cannot be solved by a single-layer perceptron because it’s not linearly separable. However, an artificial neural network featuring one hidden layer can learn the XOR function.
In the following code, we will train a basic neural network using the XOR truth table. We will build a neural network using TensorFlow/Keras, which consists of 2 input neurons, a hidden layer with 2 neurons, and 1 output neuron.
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# XOR input and outputs
X = np.array([[0,0],[0,1],[1,0],[1,1]], dtype="float32")
y = np.array([0, 1, 1, 0], dtype="float32")
# Define a simple 2-2-1 neural network
model = keras.Sequential([
layers.Dense(2, activation='relu', input_shape=(2,)), # hidden layer with 2 neurons
layers.Dense(1, activation='sigmoid') # output layer with 1 neuron
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X, y, epochs=1000, verbose=0) # train for 1000 epochs
# Test the model
preds = model.predict(X).round()
print("Predictions:", preds.flatten())
When presented with the input sets [[0,0],[0,1],[1,0],[1,1]], the neural network should produce outputs that match the sequence [0, 1, 1, 0]. The hidden layer converts input data into a space where the output neuron can perform linear separation. Through deeper learning approaches, neural networks demonstrate the ability to learn functions that surpass the capabilities of single-layer models.
Explore our tutorial on constructing neural networks from scratch to see how to implement an XOR-solving network using NumPy while thoroughly explaining the mathematical principles involved.
Types of Neural Networks (FFNN vs. CNN vs. RNN)
Neural networks come in various architectures, each suited to different kinds of data:
| Neural Network Type | Characteristics & Structure | Common Applications |
|---|---|---|
| Feed-Forward Neural Network (FFNN) | Neurons in a network are structured into fully-connected layers, and information moves unidirectionally from input toward output without any loops. The networks lack any built-in mechanism to interpret the order or spatial structure of data. | Structured data (tabular) classification/regression Basic pattern recognition tasks |
| Convolutional Neural Network (CNN) | Incorporates convolutional layers that apply filters over local regions of the input (e.g., image patches) to extract spatial features. Typically includes pooling layers for downsampling and fully-connected layers for final classification. Some architectures use global pooling layers instead of final fully-connected layers to reduce each feature map to a single value. | Image and video analysis (computer vision) Object detection and facial recognition Any tasks involving grid-like data (images, etc.) |
| Recurrent Neural Network including LSTM, GRU & Feedback Networks | Recurrent Neural Networks process sequential data using connections that create feedback loops to maintain information across time steps. LSTM and GRU variants can learn long-term dependencies in sequence data. | Time-series forecasting (e.g., stock prices, weather) in Python Natural language processing (text generation, translation) |
Feed-forward networks perform best with independent data points, while CNNs are designed to process spatial or grid-like data such as images. RNNs are great when working with sequential or temporal data structures. Choosing the right architecture is essential. For example, you can choose a CNN for image classification and an RNN to handle language modeling tasks.
Common Training Pitfalls and How to Avoid Them
Training neural networks can be challenging. Here are some common issues and tips for avoiding them:
| Training Pitfall | Description | How to Avoid |
|---|---|---|
| Overfitting | The model memorizes training data, including noise, which leads to excellent training accuracy but low validation/test accuracy. | Apply regularization (e.g., dropout, weight decay) Use early stopping based on validation loss Increase the dataset size or use data augmentation |
| Underfitting | Due to its simplicity and insufficient training duration, the model fails to identify core patterns, resulting in poor performance on training and test sets. | Increase model capacity (more layers or neurons) Train for more epochs Reduce regularization strength |
| Poor Hyperparameter Selection | Inappropriate settings for hyperparameters like learning rate, batch size, etc., may lead to training processes that diverge, oscillate, or learn too slowly. | Perform systematic tuning of hyperparameters such as learning rate, batch size, and model architecture. Use validation data to evaluate each configuration Consider automated search techniques such as grid search, random search, and Bayesian optimization. |
You will develop more effective models by understanding these issues. You need to monitor training and validation performance metrics during the entire process. By plotting learning curves against epochs, you can identify overfitting or underfitting in the network, allowing you to make appropriate adjustments.
Popular Tools and Libraries for Neural Networks
Modern frameworks simplify the process of building and training neural networks. Novice and experienced professionals can find these popular tools useful:
- TensorFlow (with Keras): It is an open-source library from Google. Keras is integrated with TensorFlow to offer beginner-friendly tools for defining and training machine learning models.
- PyTorch: Meta (Facebook) developed PyTorch, which provides dynamic computation graphs and a Pythonic style. It is widely used across research fields and industry applications.
- Scikit-learn: A general machine learning library in Python. It features basic neural network models such as MLPClassifier, which work well for small-scale problems or as a starting point.
- Others: We can include frameworks like MXNet, Caffe, Microsoft CNTK, and high-level tools like FastAI or Hugging Face Transformers.
FAQ SECTION
What is the difference between a neural network and deep learning?
A Neural network is a computational model that draws inspiration from the structure of the human brain and consists of connected layers of nodes that process data.
Deep learning represents a specialized area within machine learning that leverages deep neural networks composed of multiple layers to learn complex patterns from large datasets.
Can I train a neural network without code?
Yes—Users can perform simple classification tasks without writing code through platforms such as Google Teachable Machine and Azure ML, which offer no-code interfaces.
How long does it take to train a neural network?
The time required for training depends on factors such as the data size, model complexity, and the type of hardware used (CPU vs. GPU/TPU).
What tools do I need to train a neural network?
To train a neural network, you require Python 3, a deep-learning library such as TensorFlow or PyTorch, and ideally a CUDA-enabled GPU for optimal speed.
What is backpropagation in simple terms?
Backpropagation is like adjusting every knob in a sound mixer after hearing noise. The algorithm computes each weight’s contribution to the error before adjusting weights to minimize loss.
Conclusion
In summary, neural networks offer a powerful, brain‐inspired approach to pattern recognition and decision-making. They use simple computation units (neurons), which they organize into layers and adjust connections through iterative backpropagation and optimization algorithms to extract complex features from data. Whether working on simple problems such as XOR or complex tasks like handwritten digit recognition, successful model design depends on understanding the role of layers, activation functions, loss functions, and optimizers. By exploring various neural network architectures(such as feed-forward, convolutional, and recurrent models) and avoiding common issues like overfitting and suboptimal hyperparameter selections, you will develop the intuition and expertise needed to apply deep learning to practical problems.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
