Sr Technical Content Strategist and Team Lead

Introduction
Hyperparameter tuning is a crucial step in optimizing machine learning models. One of the most effective techniques for hyperparameter tuning is grid search, which systematically evaluates combinations of hyperparameters to find the best-performing configuration.
In this tutorial, you’ll learn how to apply grid searching using Python with GridSearchCV from scikit-learn, compare grid search with random search, and explore best practices to avoid overfitting and optimize execution time.
What is Grid Search in Python?
In machine learning, a hyperparameter is a setting that is chosen before training a model. Examples of hyperparameters include learning rate, batch size, and number of hidden layers in a neural network.
The right combination of hyperparameters can significantly impact the performance of a model. Grid search is a method used to find the best combination of hyperparameters for a model by systematically trying all possible combinations within a specified range. This exhaustive search helps identify the optimal set of hyperparameters that result in the best performance of the model.
How Does Grid Search Work?
The process of grid search can be broken down into the following steps:
-
Define a set of hyperparameter values for the model: This is the range of values that the grid search will consider for each hyperparameter. For example, if you are tuning the learning rate of a neural network, you might define a range of values from 0.001 to 0.1.
-
Train the model using all possible combinations of those hyperparameters: Grid search will then train the model using every possible combination of hyperparameters within the defined range. For example, if you have 3 hyperparameters and each has 5 possible values, the grid search will train the model 5^3 = 125 times.
-
Evaluate performance using cross-validation: After training the model with each combination of hyperparameters, grid search will evaluate the model’s performance using cross-validation. This is a technique used to assess how the model will generalize to an independent data set.
-
Select the best hyperparameter combination based on performance metrics: Finally, grid search will select the combination of hyperparameters that resulted in the best performance. This is typically done by choosing the combination that resulted in the highest accuracy, but it can also be based on other performance metrics such as precision, recall, or F1 score.
The following table illustrates how a grid search works:
| Hyperparameter 1 | Hyperparameter 2 | Hyperparameter 3 | … | Performance |
|---|---|---|---|---|
| Value 1 | Value 1 | Value 1 | … | 0.85 |
| Value 1 | Value 1 | Value 2 | … | 0.82 |
| … | … | … | … | … |
| Value 2 | Value 2 | Value 2 | … | 0.88 |
| … | … | … | … | … |
| Value N | Value N | Value N | … | 0.79 |
In this table, each row represents a different combination of hyperparameters, and the last column represents the performance of the model when trained with that combination. The goal of grid search is to find the combination of hyperparameters that results in the highest performance.
Implementing Grid Search in Python
In this section, you will learn the step-by-step implementation of grid search in Python using the GridSearchCV class from scikit-learn. You will use a simple example of tuning the hyperparameters of a support vector machine (SVM) model.
Step 1 - Import Libraries
First, we need to import the necessary libraries. We will use scikit-learn for the SVM model and grid search, and numpy for data manipulation.
import numpy as np
from sklearn import svm
from sklearn.model_selection import GridSearchCV
Step 2 - Load Data
Next, you will load the dataset. For this example, you will use the iris dataset, which is a popular dataset in machine learning.
from sklearn import datasets
iris = datasets.load_iris()
# Inspect the dataset
print("Dataset loaded successfully.")
print("Dataset shape:", iris.data.shape)
print("Number of classes:", len(np.unique(iris.target)))
print("Class names:", iris.target_names)
print("Feature names:", iris.feature_names)
OutputDataset loaded successfully.
Dataset shape: (150, 4)
Number of classes: 3
Class names: ['setosa' 'versicolor' 'virginica']
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Step 3 - Define the Model and Hyperparameters
Now, you will define the SVM model and the hyperparameters you want to tune. For the SVM model, you will tune the kernel and C hyperparameters.
# This code block initializes a Support Vector Machine (SVM) model and defines a parameter grid for hyperparameter tuning.
# The SVM model is created using the svm.SVC() function from the scikit-learn library.
# The parameter grid is a dictionary that specifies the hyperparameters to be tuned and their possible values.
# In this case, the hyperparameters are 'C' (regularization parameter) and 'kernel' (type of kernel to use).
# The values for 'C' are [1, 10, 100, 1000], indicating that the model will be trained with these different regularization strengths.
# The values for 'kernel' are ['linear', 'rbf'], indicating that the model will be trained with both linear and radial basis function (RBF) kernels.
model = svm.SVC()
param_grid = {'C': [1, 10, 100, 1000], 'kernel': ['linear', 'rbf']}
Step 4 - Perform Grid Search
In this step, you will execute a grid search using the GridSearchCV class from scikit-learn. The purpose of a grid search is to find the optimal hyperparameters for your model by systematically trying out all possible combinations of specified hyperparameters and evaluating their performance using cross-validation.
Here, you will use 5-fold cross-validation (cv=5) to assess the performance of each hyperparameter combination. This means that the dataset will be split into 5 subsets, and the model will be trained and evaluated on each subset. The average performance across these subsets will be used to determine the best hyperparameters.
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(iris.data, iris.target)
The above code block initializes a GridSearchCV object with the following parameters:
model: The SVM model defined earlier.param_grid: The dictionary specifying the hyperparameters to be tuned and their possible values.cv=5: The number of folds for cross-validation.
The fit method is then called on the grid_search object, passing in the feature data (iris.data) and the target values (iris.target). This starts the grid search process, which will evaluate the model’s performance for each hyperparameter combination and identify the best set of hyperparameters.
Step 5 - View Results
Finally, you can view the results of the grid search. The best hyperparameters and the corresponding accuracy score will be displayed.
print("Best hyperparameters: ", grid_search.best_params_)
print("Best accuracy: ", grid_search.best_score_)
# Visualizing the best hyperparameters
import matplotlib.pyplot as plt
import numpy as np
C_values = [1, 10, 100, 1000]
kernel_values = ['linear', 'rbf']
scores = grid_search.cv_results_['mean_test_score'].reshape(len(C_values), len(kernel_values))
plt.figure(figsize=(8, 6))
plt.subplots_adjust(left=.2, right=0.95, bottom=0.15, top=0.95)
plt.imshow(scores, interpolation='nearest', cmap=plt.cm.hot)
plt.xlabel('kernel')
plt.ylabel('C')
plt.colorbar()
plt.xticks(np.arange(len(kernel_values)), kernel_values)
plt.yticks(np.arange(len(C_values)), C_values)
plt.title('Grid Search Mean Test Scores')
plt.show()
OutputBest hyperparameters: {'C': 1, 'kernel': 'linear'}
Best accuracy: 0.9800000000000001
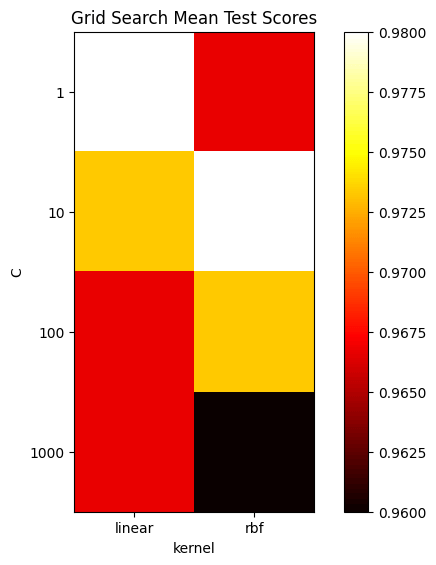
The best value for the hyperparameter ‘C’ is 1, which controls the regularization strength. A smaller value of ‘C’ means stronger regularization. The best value for the hyperparameter ‘kernel’ is ‘linear’, which specifies the type of kernel to be used in the algorithm.
The best accuracy achieved with these hyperparameters is 0.98, indicating that the model correctly predicts 98% of the instances in the cross-validation process.
That’s it! You have now implemented a grid search in Python. You can apply this technique to tune the hyperparameters of any machine learning model.
Grid Search vs. Random Search
Another popular hyperparameter tuning technique is random search, which selects random hyperparameter combinations instead of testing all possibilities.
| Feature | Grid Search | Random Search |
|---|---|---|
| Search Method | Exhaustive search of all possible combinations | Random sampling of hyperparameter space |
| Computational Cost | High due to exhaustive search, can be computationally expensive | Lower due to random sampling, faster computation |
| Accuracy | Potentially higher accuracy due to exhaustive search, but may overfit | Lower accuracy due to random sampling, but faster results |
| Best Use Case | Best for small to medium-sized hyperparameter spaces where exhaustive search is feasible | Best for large hyperparameter spaces where exhaustive search is impractical or computationally expensive |
| Hyperparameter Tuning | Suitable for tuning a small number of hyperparameters | Suitable for tuning a large number of hyperparameters |
| Model Complexity | More suitable for simple models with few hyperparameters | More suitable for complex models with many hyperparameters |
| Time Complexity | Time complexity increases exponentially with the number of hyperparameters | Time complexity is relatively constant regardless of the number of hyperparameters |
from sklearn.model_selection import RandomizedSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load dataset and split into training and test sets
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# Define the parameter grid
param_distributions = {'C': [1, 10, 100, 1000], 'kernel': ['linear', 'rbf']}
# Initialize the RandomizedSearchCV object
random_search = RandomizedSearchCV(SVC(), param_distributions=param_distributions, n_iter=5, cv=5, scoring='accuracy', random_state=42)
# Fit the model
random_search.fit(X_train, y_train)
# Print the best parameters
print("Best Parameters:", random_search.best_params_)
OutputBest Parameters: {'kernel': 'linear', 'C': 1}
When to Use Grid Search vs. Random Search?
Choosing between grid search and random search depends on several factors, including the size of the hyperparameter space, the computational resources available, and the specific requirements of your machine learning project.
Grid search is ideal when:
- Hyperparameter Space is Small: If the number of hyperparameters and their possible values are limited, grid search can efficiently explore all combinations.
- Computational Resources are Abundant: Since grid search is computationally intensive, it is suitable when you have access to powerful hardware or cloud resources.
- High Accuracy is Crucial: Grid search can potentially yield higher accuracy by exhaustively searching all possible combinations, making it suitable for critical applications where performance is paramount.
- Model Simplicity: It works well with simpler models that have fewer hyperparameters, ensuring that the exhaustive search remains feasible.
Random search is preferable when:
- Hyperparameter Space is Large: For models with a large number of hyperparameters or a wide range of possible values, random search can efficiently sample the space without the need for an exhaustive search.
- Limited Computational Resources: Random search is less computationally demanding, making it suitable for scenarios with limited hardware or time constraints.
- Faster Results are Needed: If you need quicker results and are willing to trade off some accuracy, random search can provide a good balance between performance and computational cost.
- Complex Models: It is more suitable for complex models with many hyperparameters, where an exhaustive search would be impractical.
In summary, use grid search when you have a smaller hyperparameter space and can afford the computational cost for potentially higher accuracy. Opt for random search when dealing with larger hyperparameter spaces, limited resources, or when faster results are needed.
Optimizing Grid Search Execution Time
Grid search can be computationally expensive due to the exhaustive nature of evaluating all possible combinations of hyperparameters. Here are some strategies to optimize the execution time of grid search:
-
Use a Smaller Search Space: By limiting the number of hyperparameters and their possible values, you can significantly reduce the computational load. For example, instead of testing a wide range of values for each hyperparameter, focus on a smaller, more relevant subset. This can be achieved by conducting preliminary experiments to identify the most promising hyperparameter ranges.
-
Use Parallel Processing: Grid search can be parallelized to take advantage of multiple CPU cores, thereby speeding up the computation. In
GridSearchCV, you can set then_jobsparameter to-1to utilize all available cores. This allows the grid search to evaluate multiple hyperparameter combinations simultaneously, reducing the overall search time. -
Use a Smaller Dataset for Tuning: Perform hyperparameter tuning on a smaller subset of your data to quickly identify the best hyperparameter combinations. Once the optimal parameters are found, you can apply them to the full dataset for final model training. This approach can save a considerable amount of time, especially when working with large datasets.
-
Use Early Stopping Techniques: Some machine learning libraries, such as XGBoost, support early stopping. This technique allows the training process to halt early if the model’s performance stops improving on a validation set. By reducing the number of iterations, early stopping can help speed up the grid search process while still identifying effective hyperparameters.
By implementing these strategies, you can make the grid search process more efficient and manageable, even when dealing with complex models and large datasets.
FAQs
1. What does GridSearchCV() do?
GridSearchCV automates hyperparameter tuning by performing cross-validation to find the best combination of hyperparameters.
2. How to apply grid search in Python?
You can use GridSearchCV from scikit-learn to train a model with different hyperparameter values and select the best one.
3. What is the difference between randomized search and grid search?
-
Grid Search tests all possible combinations exhaustively.
-
Random Search selects random combinations, reducing computation time.
4. What does grid() do in Python?
In matplotlib or GUI frameworks, .grid() is used for creating a grid layout. It is unrelated to machine learning grid search.
5. How to apply grid search?
To apply grid search in Python, you can leverage the GridSearchCV class from scikit-learn by following these steps:
- Import the necessary libraries.
- Define your model and the hyperparameters you want to tune.
- Create a GridSearchCV object by providing the model, a dictionary of hyperparameters, and your desired cross-validation settings.
- Fit the GridSearchCV object to your dataset.
- Retrieve the best hyperparameters and evaluate your model.
Below is an example that demonstrates the process:
import numpy as np
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
# Load the iris dataset
iris = datasets.load_iris()
# Define the SVM model
model = svm.SVC()
# Set up the hyperparameter grid
param_grid = {
'C': [1, 10, 100],
'kernel': ['linear', 'rbf']
}
# Create a GridSearchCV object with 5-fold cross-validation
grid_search = GridSearchCV(model, param_grid, cv=5)
# Fit the grid search to the data
grid_search.fit(iris.data, iris.target)
# Retrieve and display the best hyperparameters and corresponding score
print("Best hyperparameters:", grid_search.best_params_)
print("Best cross-validation score:", grid_search.best_score_)
This example tunes an SVM classifier on the iris dataset by searching over different values for the regularization parameter and kernel type.
6. How to do a grid search for missing people?
While the term “grid search” is renowned in machine learning for hyperparameter tuning, applying its concept to locate missing people involves adapting a systematic search strategy. In practice, this means dividing the search area into a structured grid, then methodically scouting each segment. Here’s how that can work:
- Partition the search region into equal grid cells to ensure every area is covered.
- Allocate teams or deploy resources (e.g., drones, volunteers) to each grid segment.
- Systematically search each cell, ensuring no overlapping efforts.
- Adjust the grid based on terrain, data insights, or emerging clues to focus on higher-priority zones.
This grid-based approach helps organize search operations and ensures thorough coverage, though real-world searches also require coordination with local authorities and emergency services.
Conclusion
Grid search is a powerful method for hyperparameter tuning in machine learning models. While it provides optimal parameter selection, it can be computationally expensive, making random search a useful alternative. By following the best practices, such as limiting the search space and using parallel processing, you can efficiently optimize model performance.
For more advanced machine learning tutorials, check out:
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
