AI Technical Writer

Context engineering has been gaining momentum ever since Andrej Karpathy highlighted it in his Twitter post. Most people think of prompts as short task descriptions you’d casually feed into an LLM. But in real-world, industrial-strength applications, that’s only scratching the surface. Context engineering is the art and science of shaping the entire context window with just the right mix of information for the next step: task descriptions, few-shot examples, RAG outputs, multimodal data, tools, state, history, and more.
Key Takeaways:
- Context engineering goes beyond prompt engineering by focusing on managing and structuring the information an AI model sees.
- Writing context externally (scratchpads, memories) helps preserve critical information without overloading the context window.
- Selecting context ensures only the most relevant notes, tools, and knowledge are retrieved to reduce noise.
- Compressing context through summarization and pruning helps manage token budgets effectively.
- Isolating context across agents, environments, or runtime states improves specialization and reduces clutter.
- Practical techniques include RAG, dynamic context windows, hybrid sources, and persistent role/system prompts.
What is Context Engineering?
Context engineering can be understood as the advanced step of prompt engineering. It is the practice of carefully structuring and designing the input (context) and then providing this context to the large language model (LLM) so that the LLM provides useful, accurate, and relevant outputs. Now, for example,
Weak Prompt:
Write about Paris.
→ Output may be random: history, culture, geography, or just generic text.
Better Prompt (engineered):
Write a 150-word travel blog post about Paris, focusing on food, local cafés, and romantic spots. Use a friendly and conversational tone.
→ Output becomes targeted, useful, and aligned with your needs.
Unlike prompt engineering, which often focuses on writing clever single-line prompts, context engineering is about managing the entire context window that is the set of information (instructions, examples, retrieved documents, system messages, conversation history, constraints, etc.) that the model sees before generating a response.
Why Context Engineering Matters
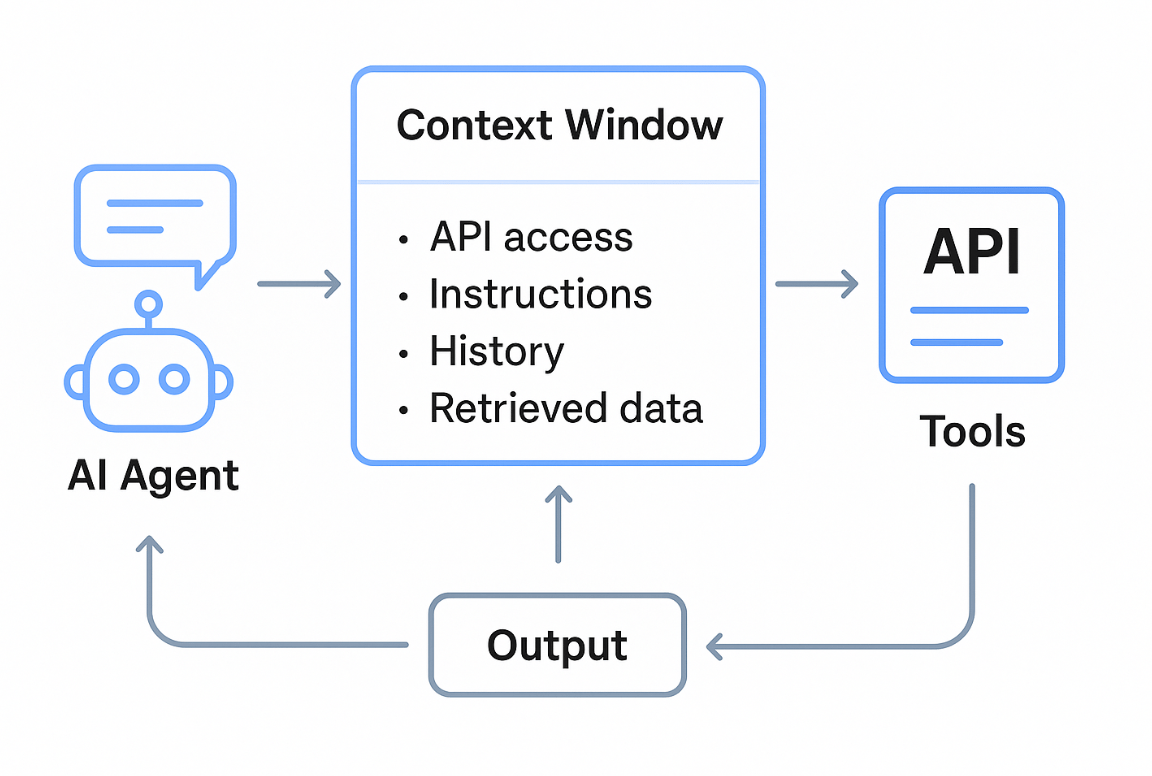
Let us understand why Context Engineering matters using an example of Agents. An AI agent is more than just an LLM prompt–response system. It can reason, plan, and take actions by using external tools or APIs.
Imagine a travel booking agent powered by an LLM, and you ask the agent to book a trip to Tokyo next month for 5 days, staying in a budget-friendly hotel near the city center. Here, the agent will perform a number of tasks such as:
- Uses tools (APIs) to check flight options.
- Queries hotel booking services.
- Plans an itinerary based on your preferences.
- Returns a structured plan with flights, hotels, and sightseeing suggestions.
Here, the agent is not just generating text, but it is reasoning, retrieving external information, and taking actions step by step autonomously.
For this task, the agent must be guided by a role-specific context (e.g., “always prioritize budget-friendly options within 10km of Tokyo city center”). Furthermore, Agents often have access to multiple APIs/tools. Context engineering helps the model know when to call which tool. Information like budget, travel style, or dietary restrictions must be injected into the context so the agent can personalize results correctly. Also, if there is a problem with any of the prompts in between, the result might be incomplete or inconsistent since the agent relies on each step’s context to guide the next action. LLMs don’t remember past runs; they only “see” what’s in the context window.
Properly engineered context ensures models act consistently, align with business needs, and handle complex tasks.
Context Window
The context window is the maximum amount of text (tokens) a model can “see” at once. Think of it as the model’s short-term memory. It includes:
- Your latest prompt
- Previous conversation turns (if appended)
- System instructions (like “respond politely” or “answer in JSON”)
- Any retrieved documents or examples you insert
If your inputs + history + instructions exceed the context window, the model will truncate older parts (usually from the beginning), which can lead to lost information.
When you interact with an LLM (or an AI agent), each new prompt isn’t treated in isolation. Instead, the model remembers the conversation history within its context window. Adding new messages to the existing context or appending to the context is a process by which the model sees both the past and the new input together. This allows the model to maintain continuity, memory, and coherence across turns. However, if you keep appending, the context grows, and eventually, the model will suffer from context overflow or might run out of context window.
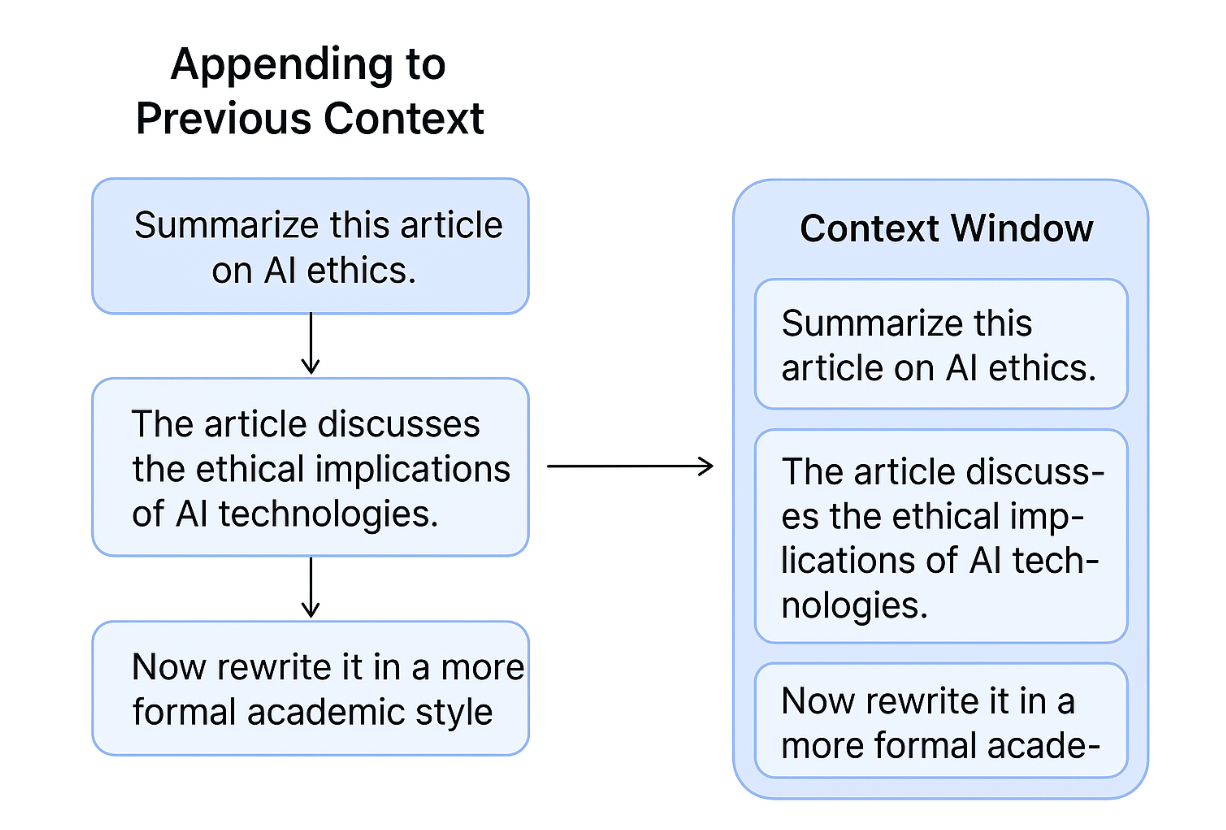
Example:
- User: “Summarize this article on AI ethics.”
- Model: (gives summary)
- User: “Now rewrite it in a more formal academic style.”
- → The model appends this new instruction to the previous conversation so it knows what “it” refers to (the summary).
Long content in context windows can fail for a few key reasons:
- When the context window contains an excessive amount of text, there’s a risk of information dilution, making it difficult for the model to prioritize key information. This can result in a lack of focus and an inability to identify the most important elements within the extensive content. It may pick up irrelevant parts of the context instead of focusing on key instructions.
- LLMs rely on attention mechanisms to decide which parts of the input matter. With very long content, the attention is spread thin, making it harder for the model to connect distant pieces of information accurately.
- If multiple instructions appear in the context (e.g., early ones vs. later ones), the model may follow the most recent or more strongly worded one, ignoring earlier but critical details.
Failing Long Context Example
Context window content (too long & cluttered):
- Full 20-page research paper pasted in raw form.
- User instructions appear at the very top: “Summarize this paper in 300 words for a non-technical audience.”
- Buried in the middle: references, equations, raw datasets, irrelevant appendices.
- At the very end: “Make the summary academic.”
What happens:
- The model sees way too much text.
- Earlier instruction (“non-technical audience”) is forgotten because the later one (“make academic”) overrides it.
- Summary ends up long, technical, and confusing—not aligned with the original goal.
Well-Engineered Shorter Context Example
Context window content (focused & structured):
- Instruction at the top:
“Summarize this research paper in 300 words, targeting a non-technical audience. Use simple language.” - Instead of pasting the full paper, only the abstract, key results, and discussion section are included.
Formatting helps:
-
[Paper Abstract] … -
[Key Findings] … -
[Conclusion] … -
The model only sees relevant parts.
-
Clear instruction at the start guides the tone.
-
Output: a crisp, simplified 300-word summary, exactly what’s needed.
Long, unfiltered content overwhelms the context window, while a curated, structured context makes the model accurate and efficient.
Therefore, Context Engineering is needed. “+1 for “context engineering” over “prompt engineering”.
People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. “ -Andrej Karpathy
For large-scale LLM applications, achieving consistent, high-quality outputs is crucial. This requires precisely populating the context window with the optimal amount and high quality of right information.
How to Get the Right Content for the Context Window
The challenge is not to dump everything into the context window, but to curate, filter, and inject only the most useful content.
1. Knowledge (Domain or Reference Data)
This includes the information your model needs to reason correctly for the given task.
-
Static Knowledge:
-
Dynamic Knowledge:
- Current inventory, updated pricing, or live research results.
- Pulled in on-demand via APIs or databases.
2. Instructions (Control and Behavior Shaping)
LLMs are general-purpose, so you must constrain and guide them. Instructions define what to do, how to respond, and in what style.
- System Prompts / Role Definitions:
- Example: “You are a travel assistant. Always respond in JSON format. Prioritize budget-friendly results unless the user specifies otherwise.”
- Formatting Requirements:
- E.g., output should be in markdown, table, or structured JSON for downstream applications.
- Examples (Few-shot learning):
- Injecting 2–3 examples of desired outputs helps the model mimic the exact structure.
Tools and API Calls (Dynamic Context Injection)
Instead of bloating the context window with static data, you can fetch fresh data when needed:
-
API Calls for Real-Time Data:
- Weather API → for travel apps.
- Stock API → for financial assistants.
- Search API → for news summarization.
-
Database Queries:
- Customer details from a CRM.
- Product catalogs from e-commerce systems.
-
Custom Tools (agents):
- Agents decide which tool to use (e.g., flight booking API vs. hotel booking API).
- Results from these tools are appended to the context window so the LLM can reason over them.
Filtering and Prioritization
Even after collecting knowledge, instructions, and tool outputs, you still can’t dump everything into the context window. You must:
- Prioritize the most relevant chunks (based on similarity search or ranking).
- Summarize long docs before inserting.
- Chunk large inputs into smaller, context-fit segments.
- Append selectively (keep the last few important interactions, not the entire conversation).
Common Strategies for Context Engineering
A few of the common key strategies for Context Engineering include:
Writing Context (Externalizing Information)
- When context doesn’t fit into the window, it is written outside and retrieved later.
- Scratchpads: temporary notes for step-by-step planning, intermediate calculations, or saving plans that might get truncated; often implemented as a tool (file write) or part of the runtime state.
- Memories: persistent information that lasts across sessions, such as episodic memory (past behaviors), procedural memory (rules/instructions), and semantic memory (factual knowledge); managed via embeddings, retrieval, or knowledge graphs to enable long-term personalization.
Selecting Context (Choosing What to Load)
- Deciding which externalized information should be brought back into the active context window.
- Scratchpad selection: retrieving saved notes via tool call or state exposure.
- Memory selection: fetching only relevant facts, rules, or examples using embeddings/knowledge graphs to avoid irrelevant intrusions.
- Tool selection: using RAG on tool metadata to load only the most relevant tools, preventing confusion and improving accuracy.
- Knowledge selection: leveraging hybrid RAG techniques (AST parsing, grep, embedding search, re-ranking) to navigate large codebases or enterprise datasets.
Compressing Context (Keeping Only What Matters)
- Managing token budgets when interactions get long.
- Summarization: LLM-generated summaries to reduce token load while preserving meaning; strategies include recursive, hierarchical, or agent handoff summarization (e.g., Claude Code compacts when context hits 95% of the window).
- Trimming/Pruning: dropping irrelevant or stale context using heuristics (e.g., remove old turns) or trained methods (e.g., Provence, a context pruner).
Isolating Context (Divide and Conquer)
- Splitting context across agents or environments to reduce noise and token bloat.
- Multi-agent systems: distributing tasks across specialized agents, each with its own context window (e.g., research agent → planning agent → writing agent).
- Environment isolation (sandboxing): executing structured instructions/code externally and only passing results back to the LLM, keeping large artifacts out of context.
- Runtime state isolation: maintaining a schema where some fields (like [messages]) are exposed while others ([knowledge]) remain hidden until explicitly retrieved.
Context Engineering vs. Prompt Engineering
Here’s a breakdown of the two approaches:
| Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
| Definition | Crafting instructions or questions to guide the LLM’s behavior. | Designing and managing the entire informational environment for the LLM. |
| Focus | The phrasing and structure of the input query. | The data, history, and external knowledge surrounding the query. |
| Key Tools | Instructions, formatting, examples, and chain-of-thought cues. | Retrieval systems, knowledge graphs, embeddings, and metadata injection. |
| Scalability | Limited—new prompts are often needed for each task. | High—context pipelines can be reused across domains. |
| Reliability | May result in hallucinations if the prompt lacks grounding. | Reduces hallucination by grounding outputs in external knowledge. |
| Use Cases | Quick prototyping, creative exploration, one-off queries. | Enterprise AI, production-grade systems, domain-specific tasks. |
| Analogy | Asking a question cleverly. | Building the right library around the model before asking. |
FAQ’s
Q1. How is context engineering different from prompt engineering? Prompt engineering focuses on crafting single, well-structured instructions for LLMs. Context engineering manages the broader flow of information—what is stored, retrieved, compressed, or isolated for effective reasoning.
Q2. Why is context engineering important for real-world AI applications? In production, tasks often exceed context window limits. Context engineering ensures relevant information is available without overwhelming the model, improving accuracy, personalization, and efficiency.
Q3. What are scratchpads, and how are they used? Scratchpads are temporary notes or intermediate steps stored outside the context window. They help models plan, calculate, or keep track of progress without losing track of instructions.
Q4. How does memory help in context engineering? Memory provides persistent knowledge across sessions, whether it’s remembering past interactions (episodic), saving rules (procedural), or storing facts (semantic). This supports personalization and continuity.
Q5. Can context engineering be applied to code agents and enterprise systems? Yes. For code agents, context engineering ensures rule files and relevant knowledge are loaded while irrelevant data is excluded. For enterprises, it enables efficient retrieval from large datasets using RAG and hybrid search.
Q6. When to prompt engineering and when to use context engineering?
- Use prompt engineering when you need quick experiments, creativity, or lightweight use cases.
- Use context engineering when building scalable, domain-specific, and reliable AI applications that integrate with external data sources.
In practice, both techniques are complementary: a strong prompt can help steer a model, but a well-engineered context ensures the model has the knowledge and structure to answer accurately.
Conclusion
Context engineering represents the next evolution in how we interact with LLMs. It shifts the focus from what we ask to what the model knows and how it interprets. As AI adoption expands across industries, context engineering will be the foundation of scalable, trustworthy, and intelligent systems. Instead of seeing it as a replacement for prompt engineering, think of it as the bigger picture; prompting is the spark, but context engineering is the architecture that sustains reliable performance.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
