By Andrew Dugan
Senior AI Technical Content Creator II

Introduction
Text diffusion models are Large Language Models (LLMs) that generate text by using diffusion to “denoise” a set of generated tokens, instead of predicting one next token at a time as autoregressive (AR) LLMs do. Diffusion techniques are now common in image generation models such as Midjourney, but they have been less successful in language models so far, largely due to the differences in data types between image pixels and text.
Text diffusion models have been getting more attention recently as some papers, such as the LLaDA and SEDD papers, have shown different kinds of text diffusion approaches to have the potential for faster, more accurate, and more flexible models in certain cases. This article explains the architectural differences, benefits, and potential use cases for text diffusion models.
Key Takeaways
-
The most successful text diffusion models so far use token masking, rather than Gaussian noise to predict output tokens iteratively in parallel.
-
Text diffusion models have not been as effective as autoregressive LLMs for most cases, but they have shown some promise in gap-filling tasks and tasks that require large outputs with faster throughput.
-
LLaDa and SEDD are two of the most popular demonstrations, and LLaDA is available for download on Hugging Face.
How Diffusion Models are Architecturally Different
There are three main categories of text diffusion models. The first uses continuous diffusion on token-level embeddings (Diffusion-LM, Genie). The second encodes text into compressed semantic latents, which are abstract, high-level representations of meaning. Diffusion is then applied in that latent space before the latents are decoded back to text. The third uses discrete diffusion over tokens by masking tokens directly (LLaDA, D3PM, SEDD). This third paradigm currently performs best in reported results, so it is the focus here.
This text diffusion method is different from image diffusion models in that it uses token masking as the noise instead of Gaussian noise. It is still actual diffusion, just adapted for discrete data (text). Models have currently shown masking to be more effective for discrete data, like language, because it treats text as categorical data, allowing the model to fill in blanks, whereas Gaussian noise is better suited for continuous data, like image pixels.
The pre-training steps for a text diffusion model have some similarities with autoregressive models. Text diffusion models also do not need labeled data during pre-training. They just need a large amount of raw text data. A max length (i.e. 4096 tokens) is decided, and a percentage of the tokens are masked. In the case of LLaDA pre-training, it samples t uniformly from [0,1], then masks each token independently with probability t. The tokens that are selected to be masked will be replaced with a <MASK> token. For a percentage of the training passes, lengths of sequences are randomly sampled between 1 and 4096 and padded so that the model is exposed to sequences of all sizes. For LLaDA, it trains at sequence length 4096, with 1% of pre-training data sampled to random lengths uniformly from [1,4096] for variable-length robustness.
The entire sequence is then fed into a transformer-based model, transforming all input embedding vectors into new embeddings. A classification head is then applied to each masked token to predict the original token, and the loss averages cross-entropy over masked positions. In LLaDA, the predictor uses non-causal attention, so it can attend to the full sequence for masked-token prediction. This bidirectional setup changes compute behavior relative to causal AR decoding, and LLaDA also reports incompatibility with key-value (KV) caching in its setup while using vanilla multi-head attention. For reference, LLaDA 8B pre-training compute is reported as about 0.13 million H800 GPU hours.
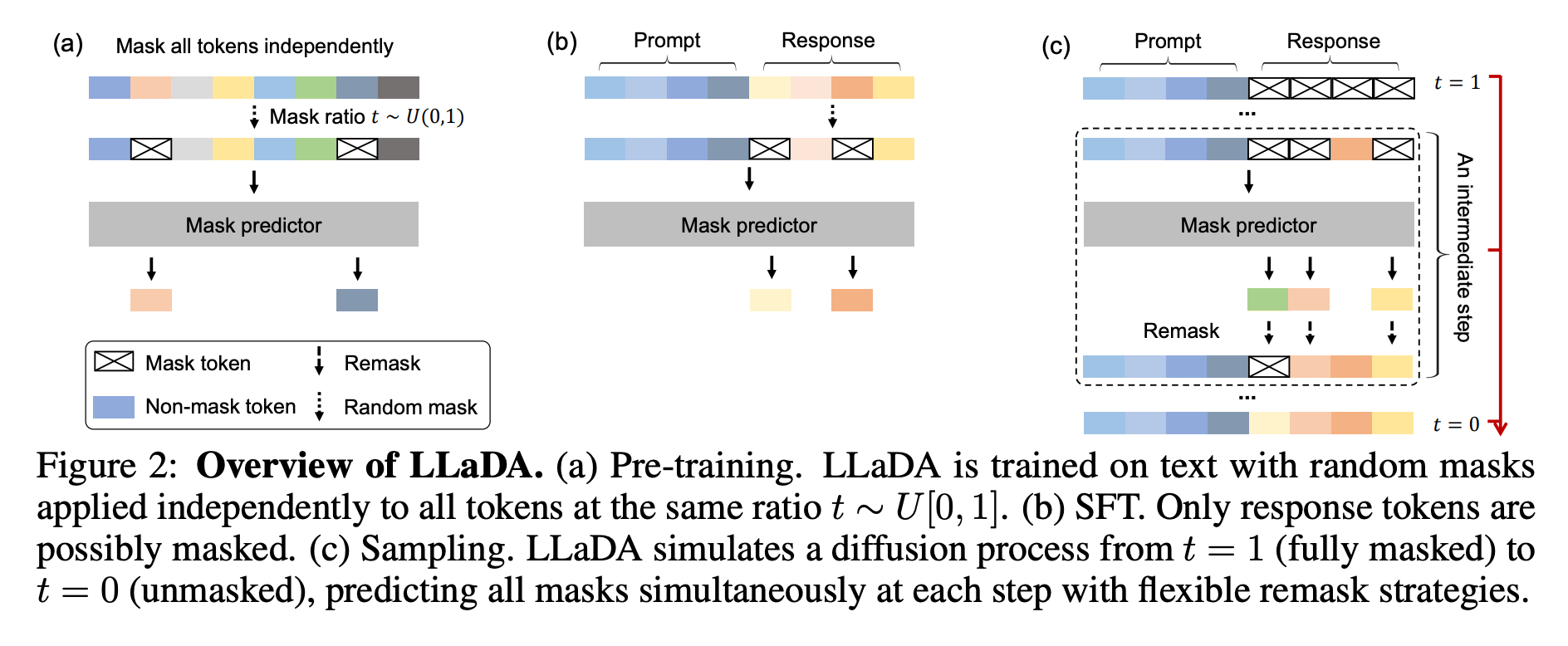
Supervised fine-tuning (SFT) mimics pre-training. The prompt is left unchanged, random tokens are masked only in the response, and the model predicts those missing response tokens conditioned on both prompt and masked response. For LLaDA 8B, supervised fine-tuning is reported on 4.5 million prompt-response pairs over 3 epochs.
At this point, the model can predict masked text, but inference must generate a full response from only a prompt. To do this, a sequence of <MASK> tokens is initialized alongside the prompt, and masked tokens are predicted in parallel. LLaDA treats both total reverse sampling steps and initial response length as explicit inference hyperparameters, creating a quality-versus-speed trade-off. By default it uses uniformly distributed timesteps; when stepping from time t to s, it remasks an expected fraction s/t of predicted tokens, and in practice it uses low-confidence remasking rather than purely random remasking. After generation, tokens after the end-of-sequence (EOS) token are discarded.
Previously unmasked tokens can be masked again if confidence is low, allowing for previously generated tokens to be updated. This is one of the major advantages of text diffusion models over autoregressive models.
Why Use Text Diffusion at All?
There are three main areas where text diffusion models show promise. First, they have potential for faster inference for longer text in some settings, when compared to autoregressive models, because they don’t have to predict a single token at a time. They are predicting all of the tokens in parallel through multiple rounds. Second, they also have potentially better outputs in some settings because tokens can be replaced anywhere in the string. Whereas if an autoregressive model has generated an incorrect token, it cannot go back and change it.
Finally, there is a higher level of flexibility in the prompts. Prompting does not need to only be a prefix, as it is in an autoregressive model. The prompt can be the entire document with missing text in the middle of the document. This makes it able to support gap-fill tasks like completing a PDF form and rewriting a middle paragraph or block of code.
It is unlikely that text diffusion models are going to fully replace autoregressive models because they typically require a higher amount of compute, and they haven’t been shown to outperform autoregressive models more broadly. Diffusion decoding typically requires multiple denoising iterations, which can increase latency depending on step count and implementation.
Below, you can see LLaDA 2.0 Flash scores comparably on benchmarks with Qwen3-30B and Ling-flash-2.0, even though LLaDA 2.0-Flash is much faster than the other two models with a token per second throughput of over 380 TPS, compared to 256 and 237 for Ling-flash and Qwen3-30B, according to the LLaDA paper.

FAQ
Can diffusion and autoregressive models be combined?
Yes. Hybrid and semi-autoregressive approaches combine strengths from both paradigms, such as generating token blocks in parallel and then refining them with autoregressive decoding. These designs are still emerging, but they aim to balance quality, latency, and controllability.
Are text diffusion models currently available for use or just experimental?
There are models currently available. The LLaDA 2.0 collection is one of the best places to start with open-weight text diffusion models. Most options are still early-stage compared to mainstream autoregressive models, but they are practical for experimentation and benchmarking.
What tasks are text diffusion models best suited for today?
Text diffusion models are currently strongest in structured editing and gap-fill style workflows, such as filling missing sections, rewriting spans in the middle of a document, and constrained generation where global consistency matters. They are also promising for longer outputs when parallel denoising can offset decoding bottlenecks.
Are text diffusion models likely to replace autoregressive LLMs?
It’s unlikely they will completely replace autoregressive models. It’s likely they will grow in popularity for specific use cases, but they currently fit best as specialized models rather than universal replacements, and that will probably continue to be the case in the future.
Conclusion
Text diffusion models are a meaningful alternative to autoregressive decoding models for specific workflows, especially where gap-filling and iterative refinement are valuable. While they are not yet the default choice for general-purpose LLM tasks, recent masking-based approaches such as LLaDA and SEDD show that diffusion can be practical for language when adapted to discrete tokens.
In this tutorial, you reviewed how text diffusion architectures work, why masking-based methods are currently the strongest approach, and where these models can outperform traditional next-token decoding. As these systems continue to mature, they are likely to become an important complement to autoregressive models in production pipelines that prioritize controllability and editing flexibility.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Andrew is an NLP Scientist with 8 years of experience designing and deploying enterprise AI applications and language processing systems.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
