AI Technical Writer

Introduction
Working with a large language model often requires writing multiple prompts, but as the application grows, prompt manual prompt engineering becomes quite messy, tedious, hard to scale, and sometimes inconsistent. Also, multiple prompts across workflows become time-consuming and complicated. Usually, LLMs use fixed “prompt templates” made by trial and error.
This is where DSPy comes in.
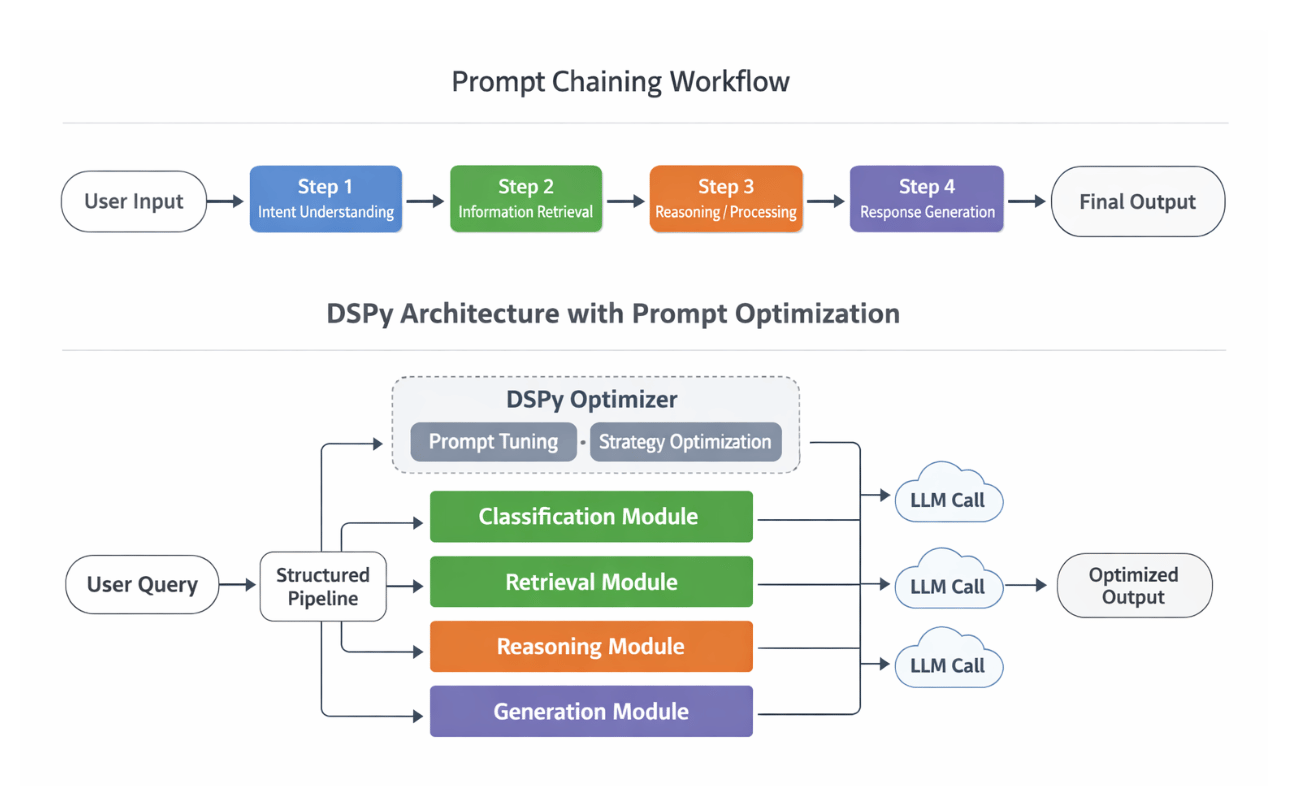
Instead of treating prompts as fixed text, DSPy treats them like programs that can be optimized. It allows you to define structured pipelines for tasks like question answering, summarization, or retrieval, and then automatically improves how these pipelines interact with language models.
DSPy is a new method that simplifies this by turning LM pipelines into easy-to-manage text transformation graphs. These graphs use modules that can learn and improve how they prompt, fine-tune, and reason.
Imagine you’re building a customer support AI assistant for an e-commerce platform.
Without DSPy
- You write multiple prompts for classification, retrieval, and response generation.
- You manually tweak them when the results are poor.
- Scaling becomes difficult as use cases grow.
With DSPy
- You define a pipeline: Understand query → Retrieve info → Generate response.
- DSPy automatically optimizes how each step interacts with the language model.
- Over time, the system improves based on data and feedback.
So instead of constantly rewriting prompts, you’re building a self-improving AI system—which is exactly what modern applications need.
DSPy includes a tool that optimizes these pipelines for better performance. Studies show that DSPy can quickly create effective LM pipelines, improving performance significantly over traditional methods. It also makes smaller, open models competitive with expert-designed prompts for advanced models like GPT-3.5.
Key Takeaways
- DSPy helps in replacing manual prompts by tweaking systematic optimization.
- DSPy helps to build reliable and reusable AI pipelines, thus improving performance without constantly rewriting prompts.
- When building real-world AI applications, developers often face problems like Prompts that work in testing but fail in production, difficulty in maintaining consistency across multiple tasks, and no clear way to measure or improve output quality.
- DSPy solves this by introducing **Declarative programming for LLMs** (you define what you want, not how to prompt it). DSPy optimizers automatically refine prompts and reasoning strategies.
- Modular components that make systems easier to debug and scale. This makes it especially useful for teams building production-grade AI systems, not just experiments.
Prerequisites
Before diving into DSPy, ensure you have the following:
- Basic Programming Knowledge: Familiarity with Python and its libraries.
- Understanding of LLMs: A good understanding of Large Language Models and their prompting mechanisms.
- Environment Setup: Access to a Python development environment, such as Jupyter Notebook or VS Code, with required libraries installed.
- PyTorch: Basic knowledge of the PyTorch framework is helpful, as DSPy is inspired by PyTorch.
What is DSPy?
DSPy is a framework that makes optimizing language model (LM) prompts and weights easier, especially when using LMs multiple times. Without DSPy, building complex systems with LMs involves many manual steps: breaking down problems, fine-tuning prompts, tweaking steps, generating synthetic examples, and fine-tuning smaller LMs, which can be a lot of manual effort and messy.
DSPy manages this by separating the program’s flow from the parameters (prompts and weights) and introducing new optimizers that adjust these parameters based on desired outcomes. This makes powerful models like GPT-4 or T5-base more reliable and effective. Instead of manual prompt adjustments, DSPy uses algorithms to update the parameters, allowing you to recompile your program to fit any changes in code, data, or metrics.
Think of it like using frameworks like PyTorch for neural networks: we don’t manually tune every detail but instead use layers and optimizers to learn the best parameters. Similarly, DSPy provides modules and optimizers that automate and enhance working with LMs, making it less about manual tweaking and more about systematic improvement and higher performance.
What does DSPy stand for?
The backronym “now” stands for “Declarative Self-improving Language Programs,” created by Stanford NLP University.
DSPy streamlines the complex process of optimizing language model (LM) prompts and weights, especially for multi-step pipelines. Traditionally, you’d have to break down the problem, refine prompts, tweak steps, generate synthetic examples, and fine-tune smaller models. This is messy and time-consuming, as any change requires reworking prompts and finetuning.
DSPy, by separating program flow from LM parameters and introducing optimizers, enhances the reliability of models like GPT-3.5, GPT-4, T5-base, or Llama2-13b. This makes them more effective and less error-prone, instilling a sense of trust and confidence in the results.
Why do we need DSPy?
“Prompt templates” are predefined instructions or demonstrations provided to the LM to guide its response to a given task. Prompt templates are often created through trial and error. This means they may work well for specific tasks or scenarios but fail or produce irrelevant results in different contexts. Since these templates are hardcoded, they lack adaptability and may not effectively handle variations in input data, task requirements, or even other language models. A given prompt template might work effectively for a particular LM pipeline or framework. Still, it may not generalize well to other pipelines, different LMs, varied data domains, or even different types of inputs. This lack of generalization limits the flexibility and applicability of the LM across diverse use cases.
Manually crafting and fine-tuning prompt templates for different tasks or LMs can be time-consuming and labor-intensive. As the complexity and diversity of tasks increase, maintaining and updating these templates becomes increasingly challenging and inefficient.
Further, other issues could be with generating the response. Using hardcoded prompt templates in language model (LM) pipelines and frameworks often leads to problems such as a lack of context and relevance, inconsistency in the output, poor quality responses, and inaccuracy. These challenges stem from the limited flexibility and scalability of prompt templates, which are manually crafted and may not effectively generalize across different LM models, data domains, or input variations.
Install DSPy
It is very easy to install DSPy. You can use pip to install DSPy:
pip install -U dspy
or
pip install git+https://github.com/stanfordnlp/dspy.git
In case you are using openai model, authenticate by setting the OPENAI_API_KEY env variable or passing api_key.
import dspy
lm = dspy.LM("openai/gpt-5-mini", api_key="YOUR_OPENAI_API_KEY")
dspy.configure(lm=lm)
Feel free to explore other models such as Anthropic, Gemini etc.,
Major Components in DSPy
Before we dive deeper, let us understand a few significant components of DSPy:
- Signatures
- Modules
- Teleprompters or Optimizers
A DSPy signature is a declaration of a function, providing a concise specification of what a text transformation needs to be taken care of, rather than detailing how a specific language model should be prompted to achieve that behavior. A DSPy signature is a tuple comprising input and output fields with an optional instruction. Each field includes a field name and optional metadata.
Signature focuses on the type of system we are building, for example:- question - > answer, english document -> french translation, or content -> summary.
Question and Answering
The first step when working with DSPy is to configure your language model.
# Authenticate via `OPENAI_API_KEY` env: import os; os.environ['OPENAI_API_KEY'] = 'here'
import dspy
lm = dspy.LM('openai/gpt-4o-mini')
dspy.settings.configure(lm=lm)
predict = dspy.Predict("question -> answer")
prediction = predict(question="who is the president of France?")
prediction.answer
Defining the signature is pretty straightforward:
Class QA(dspy.signature):
question = dspy.InputField()
answer = dspy.OutputField()
predict = dspy.Predict(QA)
prediction = predict(question = “......”)
print(prediction.answer)
qa = dspy.Predict (" question -> answer ")
qa(question =" Where is Guaran ´ı spoken?")
# Out: Prediction ( answer = ’ Guaran ´ı is spoken mainly in South America . ’)
A DSPy module is a core component for creating programs that utilize language models. Each module encloses a specific prompting technique, such as a chain of thought or ReAct, and is designed to be versatile enough to work with any DSPy Signature.
These modules have adjustable parameters, including prompt and language model weights elements, and can be called to process inputs and produce outputs. Moreover, multiple DSPy modules can be combined to form larger, more complex programs. Inspired by neural network modules in PyTorch, DSPy modules bring similar functionality to language model programming.
For example:-
The dspy.Predict is the fundamental module, and all other DSPy modules are built using this module. To use a module, we start by declaring it with a specific signature. Next, we call the module with the input arguments and extract the output fields.
sentence = "it's a charming and often affecting journey." # example from the SST-2 dataset.
# 1) Declare with a signature.
classify = dspy.Predict('sentence -> sentiment')
# 2) Call with input argument(s).
response = classify(sentence=sentence)
# 3) Access the output.
print(response.sentiment)
Output:-
Positive
import dspy
# Step 1: Configure the language model
lm = dspy.OpenAI(model="gpt-4o-mini")
dspy.settings.configure(lm=lm)
# Step 2: Define a signature (input → output)
class ClassifySentiment(dspy.Signature):
"""Classify sentiment of a sentence"""
text = dspy.InputField()
sentiment = dspy.OutputField(desc="positive, negative, or neutral")
# Step 3: Create a module
class SentimentModule(dspy.Module):
def __init__(self):
super().__init__()
self.classify = dspy.Predict(ClassifySentiment)
def forward(self, text):
result = self.classify(text=text)
return result.sentiment
# Step 4: Use the module
classifier = SentimentModule()
output = classifier("I love using DSPy, it's so efficient!")
print(output)
Here,
- Signature → Defines what goes in and what comes out
- Predict() → Handles the LLM interaction
- Module → Wraps everything into a reusable pipeline
There are a few other DSPy modules we can use:
- dspy.ChainOfThought
- dspy.ReAct
- dspy.MultiChainComparison
- dspy.ProgramOfThought
and more.
A DSPy teleprompter is used for optimization in DSPy. It is very flexible and modular. The optimization is carried out by teleprompters, which are versatile strategies guiding how the modules should learn from data.
A DSPy optimizer is an algorithm designed to fine-tune the parameters of a DSPy program, such as the prompts and language model weights, to maximize specified metrics like accuracy. DSPy offers a variety of built-in optimizers, each employing different strategies. Typically, a DSPy optimizer requires three things: your DSPy program (which could be a single module or a complex multi-module setup), a metric function to evaluate and score your program’s output (with higher scores indicating better performance), and a few training inputs (sometimes as few as 5 or 10 examples, even if they lack labels). While having a lot of data can be beneficial, DSPy is designed to deliver strong results even with minimal input.
How do the Optimizers Enhance Performance?
Traditional deep neural networks (DNNs) are optimized using gradient descent with a loss function and training data. In contrast, DSPy programs comprise multiple calls to language models (LMs) integrated as DSPy modules. Each module has three internal parameters: LM weights, instructions, and demonstrations of input/output behavior.
DSPy can optimize all three using multi-stage optimization algorithms, combining gradient descent for LM weights and LM-driven optimization for refining instructions and demonstrations. Unlike typical few-shot examples, DSPy demonstrations are more robust and can be generated and optimized from scratch based on your program. This compilation often produces better prompts than human writing, not because DSPy optimizers are inherently more creative but because they can systematically explore more options and fine-tune the metrics directly.
A few DSPy optimizers are listed below:
- LabeledFewShot
- BootstrapFewShot
- BootstrapFewShotWithRandomSearch
- BootstrapFewShotWithOptuna
- KNNFewShot
and the list goes on.
We highly recommend the DSPy documentation for further information regarding the different kinds of optimizers.
Getting started with DSPy
Let us start with installing the packages:
!pip install dspy-ai
#or
!pip install git+https://github.com/stanfordnlp/dspy.git
Import the necessary packages,
import sys
import os
import dspy
from dspy.datasets import HotPotQA
from dspy.teleprompt import BootstrapFewShot
from dspy.evaluate.evaluate import Evaluate
from dsp.utils import deduplicate
Getting started and loading the data
turbo = dspy.OpenAI(model='gpt-3.5-turbo') #model name 'gpt-3.5-turbo'
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts') #the retriever ColBERTv2
dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)
#load the data
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
HotpotQA is a question-answering dataset sourced from English Wikipedia, which comprises around 113,000 crowd-sourced questions.
Using this information, we will create a question-answering system. For this purpose, we will use 20 data points for training and 50 data points for the development or validation set.
# get the train and validation set.
trainset = [x.with_inputs('question') for x in dataset.train]
devset = [x.with_inputs('question') for x in dataset.dev]
len(trainset), len(devset)
(20, 50)
Next, we will take a look at some examples.
train_example = trainset[0]
print(f"Question: {train_example.question}")
print(f"Answer: {train_example.answer}")
Question: At My Window was released by which American singer-songwriter?
Answer: John Townes Van Zandt
dev_example = devset[18]
print(f"Question: {dev_example.question}")
print(f"Answer: {dev_example.answer}")
print(f"Relevant Wikipedia Titles: {dev_example.gold_titles}")
Question: What is the nationality of the chef and restaurateur featured in Restaurant: Impossible?
Answer: English
Relevant Wikipedia Titles: {'Robert Irvine', 'Restaurant: Impossible'}
Creating a chatbot
We’re creating a function called Basic QA with the signature for questions requiring short, factoid answers. Each question will have one answer, limited to one to five words.
This signature defines our goal: to develop a question-answering chatbot.
class BasicQA(dspy.Signature): #Signature
"""Answer questions with short factoid answers."""
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
Next, we generate the response using dspy.predict, pass the Basic QA class, and call the generate_answer function with our example question. Finally, we print the output to test if our question-answering chatbot responds correctly.
# Define the predictor.
generate_answer = dspy.Predict(BasicQA)
# Call the predictor on a particular input.
pred = generate_answer(question=dev_example.question)
# Print the input and the prediction.
print(f"Question: {dev_example.question}")
print(f"Predicted Answer: {pred.answer}")
Question: What is the nationality of the chef and restaurateur featured in Restaurant: Impossible?
Predicted Answer: American
Here, the answer is incorrect, and we need to correct it. Let us inspect how this output was generated.
turbo.inspect_history(n=1)
turbo.inspect_history(n=1)
Answer questions with short factoid answers.
---
Follow the following format.
Question: ${question}
Answer: often between 1 and 5 words
---
Question: What is the nationality of the chef and restaurateur featured in Restaurant: Impossible?
Answer: American
This chef is British and American, but we cannot know if the model just guessed “American” because it’s a standard answer.
Let us introduce the ‘chain of thought.’
Chain of Thought
Suppose we were to ask a complicated question where a simple prompt often produces incorrect answers. One way is to use the chain of thought. In this way, we are actually asking the model to think step by step and provide the correct answer.
generate_answer_with_chain_of_thought = dspy.ChainOfThought(BasicQA)
pred = generate_answer_with_chain_of_thought(question=question)
Creating a chatbot using Chain of Thought
The chain of thought includes a series of intermediate reasoning steps, significantly improving large language models’ ability to perform complex reasoning.
generate_answer_with_chain_of_thought = dspy.ChainOfThought(BasicQA)
# Call the predictor on the same input.
pred = generate_answer_with_chain_of_thought(question=dev_example.question)
# Print the input, the chain of thought, and the prediction.
print(f"Question: {dev_example.question}")
print(f"Thought: {pred.rationale.split('.', 1)[1].strip()}")
print(f"Predicted Answer: {pred.answer}")
Question: What is the nationality of the chef and restaurateur featured in Restaurant: Impossible?
Thought: We know that the chef and restaurateur featured in Restaurant: Impossible is Robert Irvine.
Predicted Answer: British
Here, the answer generated shows that some reasoning was used before the conclusion.
Feel free to run the code below and check the reasoning and how this response is generated.
turbo.inspect_history(n=1)
Creating a RAG Application
We’ll build a retrieval-augmented pipeline for answer generation. First, we will create a signature and then a module, set up an optimizer to refine it, and finally execute the RAG process by defining a class called GenerateAnswer.
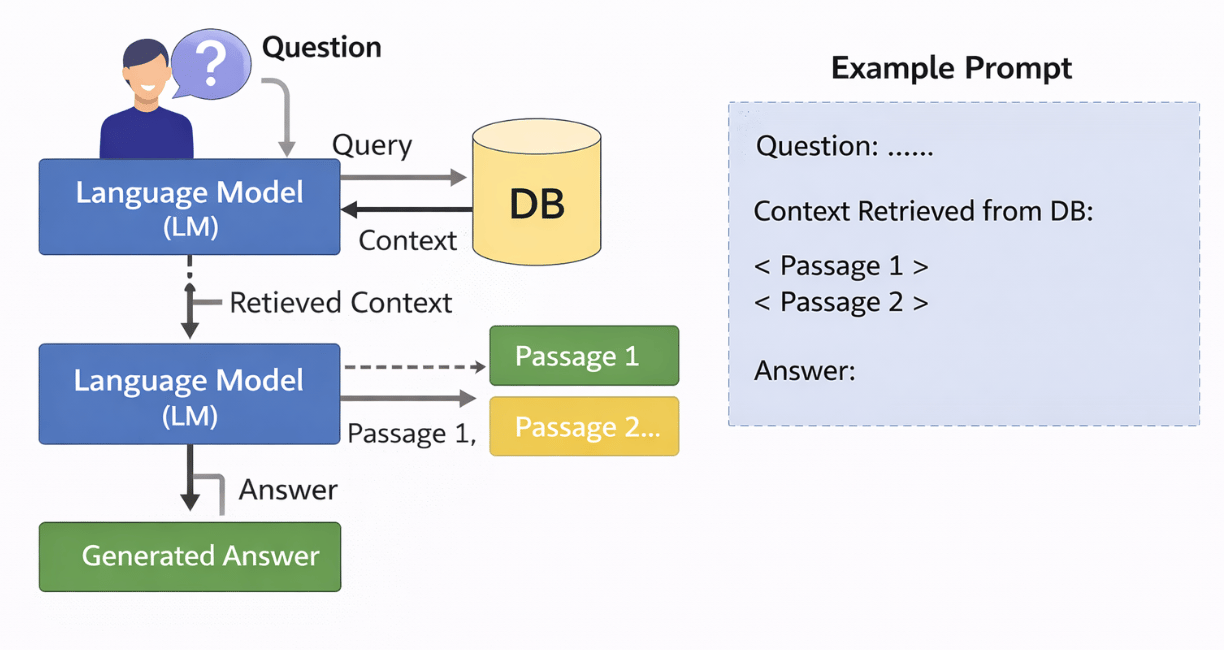
RAG Signature
Define the signature: context, question --> answer.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
RAG Module
In the RAG class, which acts as a module, we define the model in the init function. We focus on ‘Retrieve’ and ‘GenerateAnswer.’ ‘Retrieve’ gathers relevant passages as context, then ‘GenerateAnswer’ uses ‘ChainOfThought’ to provide predictions based on the user’s question.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
RAG Optimizer
Next, we are compiling the RAG program, which involves using a training set, defining a validation metric, and selecting a teleprompter to optimize the program. Teleprompters are powerful optimizers that select effective prompts for modules. We’ll use BootstrapFewShot as a simple default teleprompter, similar to choosing an optimizer in traditional supervised learning setups like SGD, Adam, or RMSProp.
# Validation logic: check that the predicted answer is correct.
# Also check that the retrieved context does actually contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
Now, let’s try executing this pipeline.
# Ask any question you like to this simple RAG program.
my_question = "What castle did David Gregory inherit?"
# Get the prediction. This contains `pred.context` and `pred.answer`.
pred = compiled_rag(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
Question: What castle did David Gregory inherit?
Predicted Answer: Kinnairdy Castle
Retrieved Contexts (truncated): ['David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinn...', 'Gregory Tarchaneiotes | Gregory Tarchaneiotes (Greek: Γρηγόριος Ταρχανειώτης , Italian: "Gregorio Tracanioto" or "Tracamoto" ) was a "protospatharius" and the long-reigning catepan of Italy from 998 t...', 'David Gregory (mathematician) | David Gregory (originally spelt Gregorie) FRS (? 1659 – 10 October 1708) was a Scottish mathematician and astronomer. He was professor of mathematics at the University ...']
Let us inspect the history.
turbo.inspect_history(n=1)
Context:
[1] «David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinnairdy Castle in 1664. Three of his twenty-nine children became mathematics professors. He is credited with inventing a military cannon that Isaac Newton described as "being destructive to the human species". Copies and details of the model no longer exist. Gregory's use of a barometer to predict farming-related weather conditions led him to be accused of witchcraft by Presbyterian ministers from Aberdeen, although he was never convicted.»
[2] «Gregory Tarchaneiotes | Gregory Tarchaneiotes (Greek: Γρηγόριος Ταρχανειώτης , Italian: "Gregorio Tracanioto" or "Tracamoto" ) was a "protospatharius" and the long-reigning catepan of Italy from 998 to 1006. In December 999, and again on February 2, 1002, he reinstituted and confirmed the possessions of the abbey and monks of Monte Cassino in Ascoli. In 1004, he fortified and expanded the castle of Dragonara on the Fortore. He gave it three circular towers and one square one. He also strengthened Lucera.»
[3] «David Gregory (mathematician) | David Gregory (originally spelt Gregorie) FRS (? 1659 – 10 October 1708) was a Scottish mathematician and astronomer. He was professor of mathematics at the University of Edinburgh, Savilian Professor of Astronomy at the University of Oxford, and a commentator on Isaac Newton's "Principia".»
Question: What castle did David Gregory inherit?
Reasoning: Let's think step by step in order to produce the answer. We know that David Gregory inherited a castle. The name of the castle is Kinnairdy Castle.
Answer: Kinnairdy Castle
Evaluate
The final step is evaluation, where we assess the RAG model’s performance: We will evaluate the basic RAG, the uncompiled RAG (without optimizer), and the compiled RAG (with optimizer). We will compare the scores obtained from these evaluations.
Basic RAG
def gold_passages_retrieved(example, pred, trace=None):
gold_titles = set(map(dspy.evaluate.normalize_text, example['gold_titles']))
found_titles = set(map(dspy.evaluate.normalize_text, [c.split(' | ')[0] for c in pred.context]))
return gold_titles.issubset(found_titles)
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=5)
compiled_rag_retrieval_score = evaluate_on_hotpotqa(compiled_rag, metric=gold_passages_retrieved)
Uncompiled Baleen RAG (Without Optimizer)
Exploring challenging questions in the training/dev sets reveals that a single search query often needs to be revised, such as when more details are needed. To address this, retrieval-augmented NLP literature proposes multi-hop search systems like GoldEn and Baleen, which generate additional queries to gather further information.
With DSPy, we can easily simulate such systems using the GenerateAnswer signature from the RAG implementation and a signature for the “hop” behavior: generating search queries to find missing information based on partial context and a question.
class GenerateSearchQuery(dspy.Signature):
"""Write a simple search query that will help answer a complex question."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
query = dspy.OutputField()
Next, create the module.
class SimplifiedBaleen(dspy.Module):
def __init__(self, passages_per_hop=3, max_hops=2):
super().__init__()
self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery) for _ in range(max_hops)]
self.retrieve = dspy.Retrieve(k=passages_per_hop)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.max_hops = max_hops
def forward(self, question):
context = []
for hop in range(self.max_hops):
query = self.generate_query[hop](context=context, question=question).query
passages = self.retrieve(query).passages
context = deduplicate(context + passages)
pred = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=pred.answer)
Baleen’s primary purpose is to automatically modify the question or query by dividing it into chunks. It retrieves the context from the chunks and then saves it in a variable, which helps generate more accurate answers.
Inspect the zero-shot version of the Baleen program
Using a program in a zero-shot (uncompiled) setting relies on the underlying language model’s ability to understand sub-tasks with minimal instructions. This works well with powerful models (e.g., GPT-4) on simple, common tasks. However, zero-shot approaches are less practical for specialized tasks, novel domains, and more efficient or open models. DSPy can enhance performance in these situations.
# Ask any question you like to this simple RAG program.
my_question = "How many storeys are in the castle that David Gregory inherited?"
# Get the prediction. This contains `pred.context` and `pred.answer`.
uncompiled_baleen = SimplifiedBaleen() # uncompiled (i.e., zero-shot) program
pred = uncompiled_baleen(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
Question: How many storeys are in the castle that David Gregory inherited?
Predicted Answer: five
Retrieved Contexts (truncated): ['David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinn...', 'The Boleyn Inheritance | The Boleyn Inheritance is a novel by British author Philippa Gregory which was first published in 2006. It is a direct sequel to her previous novel "The Other Boleyn Girl," an...', 'Gregory of Gaeta | Gregory was the Duke of Gaeta from 963 until his death. He was the second son of Docibilis II of Gaeta and his wife Orania. He succeeded his brother John II, who had left only daugh...', 'Kinnairdy Castle | Kinnairdy Castle is a tower house, having five storeys and a garret, two miles south of Aberchirder, Aberdeenshire, Scotland. The alternative name is Old Kinnairdy....', 'Kinnaird Head | Kinnaird Head (Scottish Gaelic: "An Ceann Àrd" , "high headland") is a headland projecting into the North Sea, within the town of Fraserburgh, Aberdeenshire on the east coast of Scotla...', 'Kinnaird Castle, Brechin | Kinnaird Castle is a 15th-century castle in Angus, Scotland. The castle has been home to the Carnegie family, the Earl of Southesk, for more than 600 years....']
Compiled Baleen RAG (with Optimizer)
First, we’ll define our validation logic, which will ensure that:
- The predicted answer matches the correct answer.
- The retrieved context includes the correct answer.
- None of the generated queries are too long (i.e., none exceed 100 characters).
- None of the generated queries are repetitive (i.e., none have an F1 score of 0.8 or higher than earlier ones).
def validate_context_and_answer_and_hops(example, pred, trace=None):
if not dspy.evaluate.answer_exact_match(example, pred): return False
if not dspy.evaluate.answer_passage_match(example, pred): return False
hops = [example.question] + [outputs.query for *_, outputs in trace if 'query' in outputs]
if max([len(h) for h in hops]) > 100: return False
if any(dspy.evaluate.answer_exact_match_str(hops[idx], hops[:idx], frac=0.8) for idx in range(2, len(hops))): return False
return True
Next, we will use one of the most basic teleprompters in DSPy, namely, BootstrapFewShot.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer_and_hops)
Finally, we will compile the optimizer and evaluate the retrieval quality of the compiled and uncompiled baleen pipelines.
compiled_baleen = teleprompter.compile(SimplifiedBaleen(), teacher=SimplifiedBaleen(passages_per_hop=2), trainset=trainset)
uncompiled_baleen_retrieval_score = evaluate_on_hotpotqa(uncompiled_baleen, metric=gold_passages_retrieved)
compiled_baleen_retrieval_score = evaluate_on_hotpotqa(compiled_baleen, metric=gold_passages_retrieved)
Let us print the scores for comparison now.
print(f"## Retrieval Score for RAG: {compiled_rag_retrieval_score}") # note that for RAG, compilation has no effect on the retrieval step
print(f"## Retrieval Score for uncompiled Baleen: {uncompiled_baleen_retrieval_score}")
print(f"## Retrieval Score for compiled Baleen: {compiled_baleen_retrieval_score}")
Output:-
## Retrieval Score for RAG: 26.0
## Retrieval Score for uncompiled Baleen: 48.0
## Retrieval Score for compiled Baleen: 60.0
Hence, the compiled Baleen method provides more accurate answers than the basic RAG application. Compiled Baleen divides the question into multiple small chunks, retrieves the context, and provides a more precise answer.
compiled_baleen("How many storeys are in the castle that David Gregory inherited?")
turbo.inspect_history(n=3)
Comparison with Langchain and Llamaindex
LangChain and LlamaIndex Overview
- Both langchain and llamaindex are popular libraries in the field of prompting LMs.
- Both of the libraries focus on providing pre-packaged components and chains for application developers. Further, they offer implementations of reusable pipelines (e.g., agents, retrieval pipelines) and tools (e.g., database connections, memory implementations).
Significant differences between LangChain and LlamaIndex:
- LangChain and LlamaIndex rely on manual prompt engineering, which DSPy aims to resolve.
- DSPy provides a structured framework that automatically bootstraps prompts, eliminating the need for hand-written prompt demonstrations.
- In September 2023, LangChain’s codebase contained 50 strings exceeding 1000 characters and numerous files dedicated to prompt engineering (12 prompts.py and 42 prompt.py files). In contrast, DSPy contains no hand-written prompts yet achieves high quality with various LMs.
- DSPy proves to be more modular and powerful than hard-coded prompts.
FAQs
1. What is DSPy, and how is it different from prompt engineering?
DSPy is a framework that replaces manual prompt engineering with structured, programmable pipelines. Instead of writing and tweaking prompts repeatedly, you define tasks as modules with clear inputs and outputs. DSPy then optimizes these interactions automatically. This makes your system more reliable, scalable, and easier to maintain compared to traditional prompt-based approaches.
2. Do I need to train a model to use DSPy?
No, DSPy does not require you to train your own model. It works on top of existing large language models like GPT or Claude. You simply configure a model and define your pipeline, and DSPy handles optimization internally. This makes it much faster to build production-ready applications without heavy compute requirements.
3. Can DSPy be used for real-world applications?
Yes, DSPy is designed specifically for real-world use cases. It can be used to build chatbots, AI agents, retrieval-augmented generation (RAG) systems, and automated workflows. By structuring tasks into modules and optimizing them, DSPy helps ensure consistent and high-quality outputs in production environments.
4. How does DSPy improve the performance of LLM applications?
DSPy uses optimizers to refine how prompts and reasoning steps are structured. Instead of manually experimenting with different prompts, DSPy evaluates and improves them based on defined metrics. Over time, this leads to better accuracy, more consistent responses, and reduced manual effort in maintaining the system.
5. Is DSPy only useful for developers with AI/ML experience?
No, DSPy can be used by both beginners and experienced developers. While some understanding of LLMs helps, DSPy simplifies many complex aspects of working with them. It abstracts prompt engineering into reusable components, making it easier to build advanced AI systems without deep expertise in machine learning.
6. How does DSPy relate to RAG (Retrieval-Augmented Generation)?
DSPy can be used to build and optimize RAG pipelines by structuring each step—retrieval, reasoning, and generation—into modules. It ensures that the retrieved context is effectively used by the language model. This leads to more accurate and context-aware responses compared to basic RAG implementations.
7. Can DSPy work with frameworks like LangChain?
Yes, DSPy can work alongside frameworks like LangChain, but it does not depend on them. While LangChain focuses on chaining components together, DSPy focuses on optimizing those components. You can use DSPy independently or integrate it into existing workflows for better performance.
8. What are the main benefits of using DSPy in production?
DSPy helps reduce prompt instability, improves output quality, and makes systems easier to scale. It allows teams to move from experimental setups to structured AI systems. By automating optimization and providing modular design, DSPy enables faster development and more reliable deployment of LLM-powered applications.
Conclusion
In this article, we explored DSPy, a programming and structured approach to building AI systems with language models. Instead of relying on manual prompt engineering, DSPy introduces a more reliable way to design workflows using signatures, modules, and teleprompters. These components help turn loosely defined prompts into well-organized pipelines that are easier to scale and improve over time.
By building simple Q&A chatbots and RAG-based applications, we saw how DSPy simplifies complex tasks into manageable steps. More importantly, it shows that you don’t always need large or heavily fine-tuned models to achieve strong results; well-structured pipelines and optimization can often make a significant difference.
Overall, DSPy shifts the focus from “writing better prompts” to “designing better systems.” This makes it especially valuable for real-world applications, where consistency, scalability, and performance matter. As AI systems continue to evolve, frameworks like DSPy will play an important role in helping developers build more reliable and efficient solutions with less trial and error.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
