By Adrien Payong and Shaoni Mukherjee

Every AI leadership conversation in 2023 focused on training costs. By 2026, the bigger challenge is no longer only training—it is inference. Training occurs once or occasionally. Inference occurs on every user prompt, agent tool call, RAG retrieval, or app-generated response.
The shift from training compute to inference compute transforms AI economics from a static model-building cost into a variable, usage-based cost that scales with product demand.
This article details how the focus of AI cost centers shifted from training to inference and why your cloud strategy needs to evolve with it. We’ll review why training cost dominated AI infrastructure conversations between 2022 and 2024. Then, we’ll break down why inference is now the variable cost of running AI at scale, how token throughput, latency, and GPU utilization determine inference economics. We’ll also explore how inference-first infrastructure differs from general-purpose cloud infrastructure and what DigitalOcean’s AI growth signals about the marketplace. Additionally, we will examine how the demands of agentic AI impact unit economics.
Takeaways
- AI infrastructure strategy has shifted from training-first to inference-first. Training is expensive, but inference becomes the recurring cost every time users send prompts, agents call tools, or RAG systems retrieve context.
- Inference costs scale directly with product usage. More users, longer prompts, larger responses, retries, tool calls, and agentic workflows all increase token consumption and infrastructure cost.
- Cost per token is more useful than cost per GPU hour. A cheaper GPU can still be expensive if throughput is low, batching is poor, latency is unstable, or GPU utilization is inefficient.
- Agentic AI multiplies inference demand. Unlike a simple chatbot, an agent may plan, retrieve documents, call tools, query databases, verify outputs, and generate final responses, creating many inference calls from one user request.
- Inference-first cloud architecture will become a competitive advantage. Smart routing, observability, batching, model flexibility, latency tracking, and cost transparency help companies control margins while scaling AI products.
The Era of Large-Scale AI Training in 2022–2024
Training dominated AI infrastructure discussions from 2022 through 2024 because GPT-3 and GPT-4 made scale the defining narrative of generative AI. GPT-3 demonstrated to the industry that ultra-large language models could generalize to many tasks with a few examples. It also showed that these models didn’t need to be retrained for every specific use case. The unprecedented 175-billion-parameter scale of the model kicked off the AI arms race: bigger models trained on larger datasets with more GPUs and more expensive training runs.
GPT-4 amplified that narrative. While OpenAI shared only limited technical details about GPT-4, the model’s capabilities sent a clear signal: frontier models had shifted from small research efforts to organizations capable of building, training, and deploying large models at scale. It required massive compute infrastructure, cutting-edge distributed training systems, high-quality data pipelines, model evaluation and testing infrastructure, and safety testing. It also requires teams that can operate across all of those systems. For CTOs and engineering leaders, GPT-4 solidified the understanding that the companies driving the next era of AI will be the ones that can operate at this level of technical and organizational scale.
Training a large foundation model isn’t a simple engineering challenge. Organizations must build datasets (and often clean those datasets themselves), coordinate thousands of GPUs across research teams or cloud regions, and debug and learn from failures in long-running training jobs. They must also tune memory and network I/O, iterate on hyperparameters, and run experiments until a model has sufficiently converged. A single failed run can waste large amounts of compute. For most companies, accessing the expertise and capital to train competitive foundational models at this scale wasn’t feasible.
The typical organization doesn’t need to train its own next-gen GPT-3 or GPT-4 model. They must build useful AI products and applications on top of these models. For these organizations, their largest long-term expense does not come from building a foundation model. It comes from running models continuously in production.
GPT-3 and GPT-4 demonstrated the capabilities of large-scale foundation models, but open-source/open-weight models transformed the economics of accessibility. Open models like Llama, Mistral, Qwen, and DeepSeek. gave organizations more alternatives than ever before. Hugging Face and other model hubs simplified the developer experience. Finding, testing, fine-tuning, and deploying models no longer mean starting from scratch. Training wasn’t going away; it became easier to access high-quality pretrained models.
The Inflection Point: Inference as Variable Cost
Training costs are typically fixed or periodic. You train/fine-tune/adjust a model, then amortize that expense over time. After the model is trained, the training bill doesn’t grow every time a user sends a request. Inference is different. It scales with use. The more users your product has, the more you’ll pay to serve the model.
Each interaction directly results in inference demand. Prompts are input tokens. Responses are output tokens. Agent steps may prompt additional model calls. Retrieval-augmented generation pipelines may concatenate additional context from documents, databases, or vector stores. Retries, tool calls, API requests, workflow branches, and validation steps all increase the compute needed to complete the task.
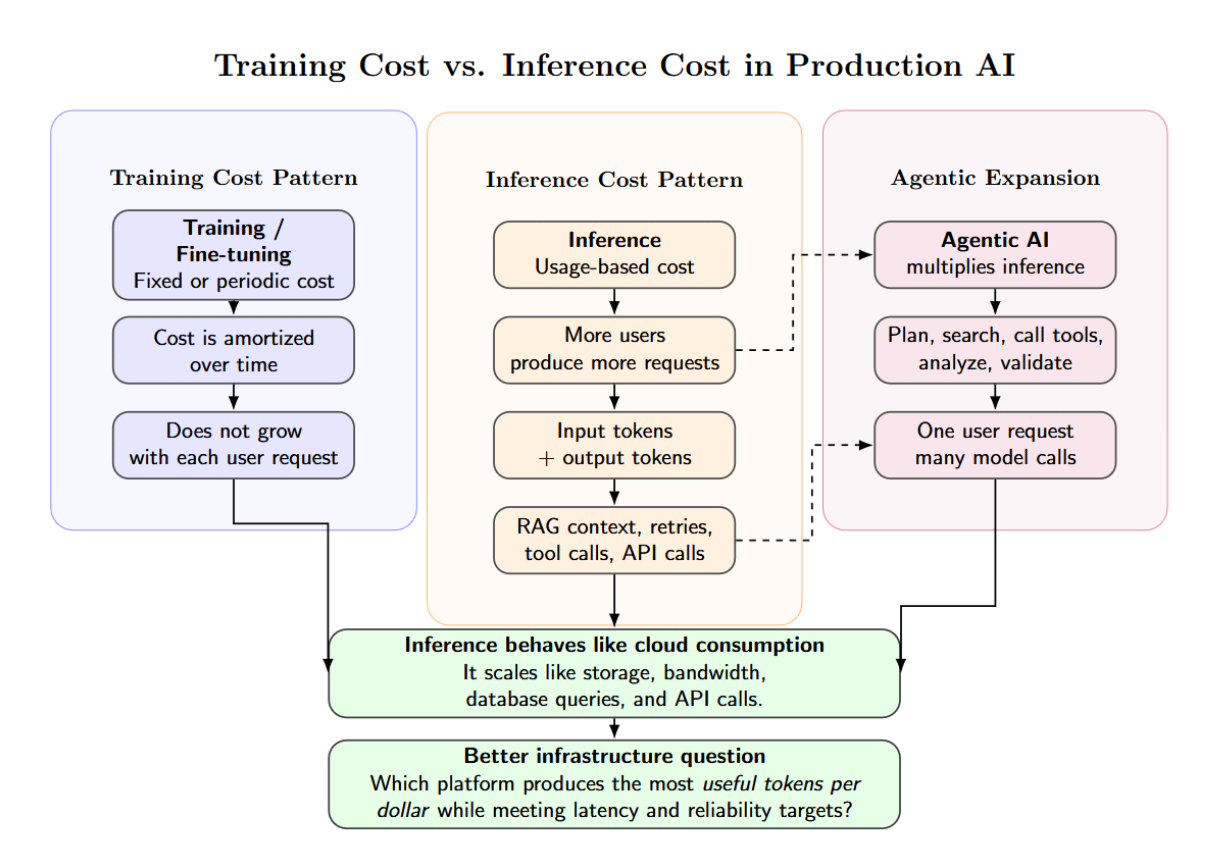
This is why inference behaves more like cloud storage, bandwidth, database queries, or API calls than model training does. It scales with adoption. A startup may be able to absorb AI experimentation costs during development when traffic is light and usage is constrained. The real challenge often shows up when the product hits production traffic. At that point, inference becomes an operational cost that expands faster than the engineering team expects.
This phenomenon becomes increasingly important as we build agentic AI. Many traditional AI use cases map to a single prompt and a single response. An agent requires systems to plan, call tools, look things up, analyze intermediate steps, re-plan, converse with other agents, and synthesize a final response. Essentially, a user request can translate to many model/inference calls and system actions.
The main question is no longer just, “Which provider has the lowest GPU hourly price?” The better question is, “Which infrastructure produces the most useful tokens per dollar while still meeting latency and reliability targets?”
Inference Economics: Tokens, Throughput, Latency
Inference economics begins with the token. A token is roughly equivalent to a unit of text that’s processed by (or generated from) the model. Many providers bill separately for input and output tokens. However, there’s more nuance to economics than a price sheet. Let’s consider the four variables that matter most:
- The token volume corresponds to the amount of data the models process. Long prompts, large context windows, RAG pipelines, and agent memory requirements all contribute to input token volume. Lengthy answers, complex multi-step plans, and generated reports raise output token volume.
- Throughput describes the rate at which your infrastructure processes work over time. It is measured in tokens per second, requests per second, or queries per second. Increasing throughput means the same fleet of GPUs can serve more tokens.
- Latency affects the user’s perception of speed. Time-to-first-token, latency between tokens, p95 latency, and p99 latency will always be more important than average latency across the system. Low average latency doesn’t guarantee that real users aren’t suffering from tail latency.
- GPU utilization tells you whether your organization is paying for productive compute or idle compute capacity. GPUs can still be expensive when they are underutilized. The infrastructure can also appear busy while serving fewer useful tokens than you expect if the chosen workload is memory-bound, getting blocked waiting on KV-cache movements, or stalled by poor batching.
A simple formula captures the idea:
Cost per million tokens = GPU cost per hour ÷ tokens per hour × 1,000,000
Notice how changing the denominator affects the outcome. Batching, routing, caching, and model selection can all increase your tokens per second, which drops your cost per token. Retries, idle GPUs, lengthy prompts, and an otherwise fragmented infrastructure will reduce the productive throughput and increase the per-token costs.
Why Inference Costs Can Overtake Training Costs
In many AI production use cases, the inference cost will surpass the cost of training/fine-tuning in a matter of months. This is because while you may only train once or a few times, you will do inference every time someone uses your product.
Imagine you had a product with 100,000 daily active users. If each person made 10 requests to your AI per day, you would have:
100,000 users × 10 requests = 1,000,000 inference requests per day
If each request averages 1,500 input tokens and 500 output tokens. That is 2,000 total tokens per request.
1,000,000 requests × 2,000 tokens = 2 billion tokens per day
At this scale, even a small difference in token cost becomes important. If one cloud platform is slightly cheaper per million tokens, the savings do not happen once. They repeat every day, every week, and every month.
This cost accelerates even more with agentic AI. While a traditional chatbot might only need a single call to a model to reply to a user, an AI agent will often take multiple steps. It will plan, search documents, call tools, query a database, validate intermediate results, and finally generate. Each of these steps incurs more tokens and more computation.
Let’s say an agentic version of the same product uses 15× more tokens. Instead of processing 2 billion tokens per day, it might process:
2 billion tokens × 15 = 30 billion tokens per day
This drives the big economic change. Now the main cost is not original model training or fine-tuning. The main cost is the daily model running costs. Essentially, you are no longer paying to build the model. You are paying to run the model.
The Inference-First Cloud Shift
A general-purpose cloud can run many workloads: web apps, databases, storage, analytics, networking, containers, and VMs. You can run AI inference on top of that foundation, but inference-first changes how the underlying platform is optimized specifically for model serving.
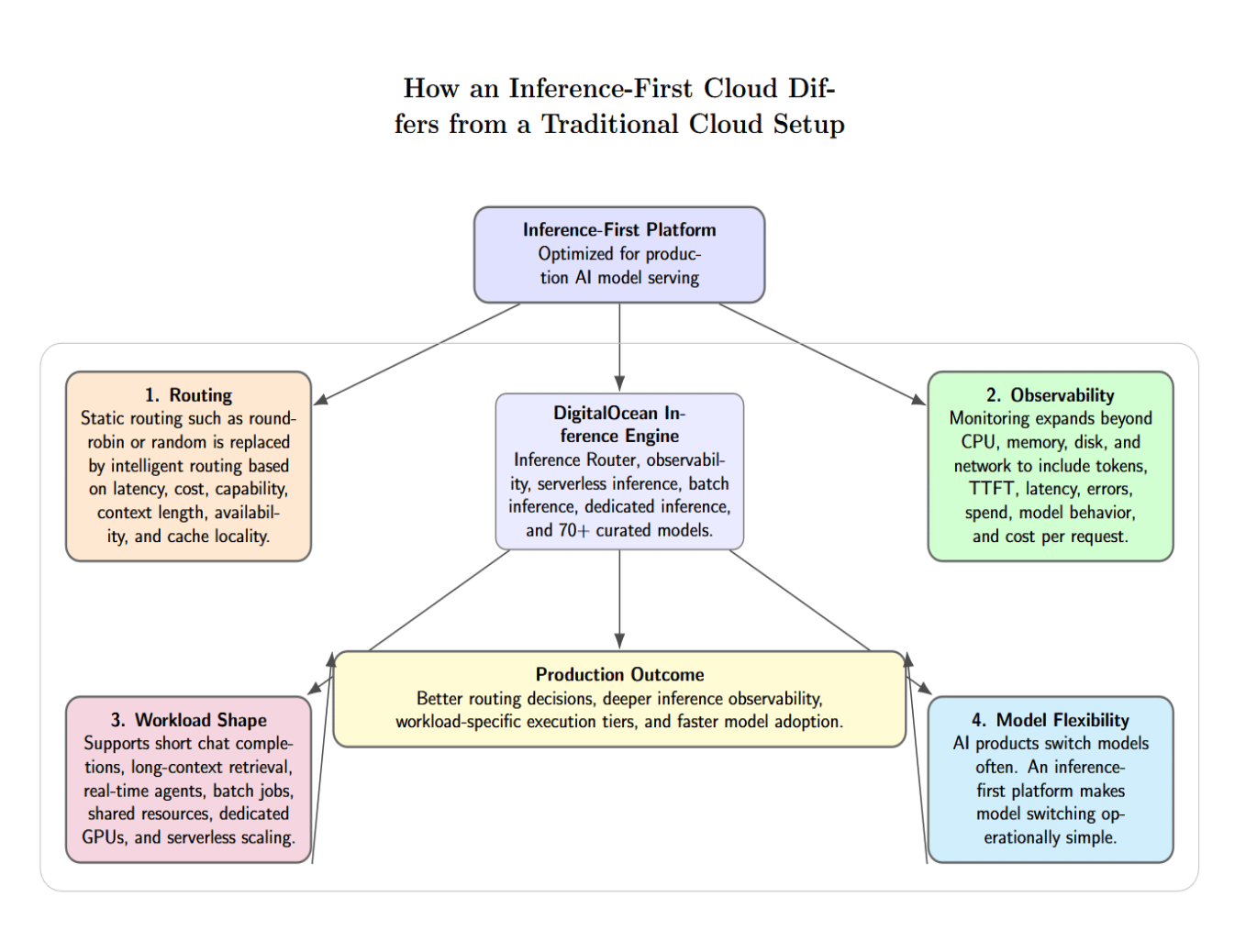
Routing is the first difference. In a typical setup, Multi-model requests are routed to available model endpoints in a simple, static order (for example, round‑robin or random). Inference-first routing considers latency requirements, cost, model capability, context length, availability, and cache locality. DigitalOcean advertises Inference Router as a control plane that intelligently chooses from a fleet of models and optimizes across inference calls based on policies such as cost and latency.
The second difference is observability. Whereas traditional cloud monitoring includes CPU, memory, disk, and network, inference monitoring requires token usage, time to first token, latency, errors, spend, model behavior, and cost per request. DigitalOcean’s Inference Engine highlights built-in observability for tokens, latency, errors, and spend.
The third difference is workload shape. Inference workloads come in all shapes and sizes. Some tasks are short-lived chat completions. Some take minutes to process long-context document retrieval. Some calls must be made within milliseconds for real-time agents. Others can be batch enrichment jobs. Some models can run on shared resources, others need dedicated GPUs. Some teams want serverless elastic scaling, others need predictable performance with dedicated resources.
DigitalOcean bundles serverless, batch, and dedicated inference tiers into a single production system. Their batch inference tier sounds ideal for asynchronous workloads, and dedicated inference is built for sustained workloads where your team must control and predict performance.
The fourth difference is model flexibility. AI-powered products switch models every few months as new, better, cheaper, or faster models are released. Operating at this pace requires an inference-first platform that makes switching models operationally simple. DigitalOcean supports 70+ curated models. This allows customers to bring their own models.
What DigitalOcean’s AI Growth Tells Us
The company’s AI-Native Cloud messaging describes five integrated layers: managed agents, data and learning, Inference Engine, core cloud, and infrastructure. It also highlights an end-to-end stack where inference, databases, Kubernetes, networking, storage, and GPUs are part of the same platform.
DigitalOcean published a detailed case study on Workato, which saw 67% higher throughput per GPU, lower latency under load, and 67% lower model cost with fewer GPUs. The gains weren’t simply the result of better hardware. Workato’s performance increased thanks to architectural improvements, including NVIDIA Dynamo, vLLM, Kubernetes, KV-aware routing, prefix reuse, and scheduling.
That should be the future of inference economics. While the model matters, it’s increasingly the systems around the model that determine cost.
The Unit Economics of the Agentic Era
Agentics AI fundamentally changes cloud economics because a single request can trigger a workflow of operations.
For example, a user could ask an agent to analyze sales. The agent may retrieve documents, query a database, call a forecasting model, synthesize Python code, verify the results, summarize insights, and compose an email. Each step might involve tokens, CPU, memory, network traffic, storage access, and observability.
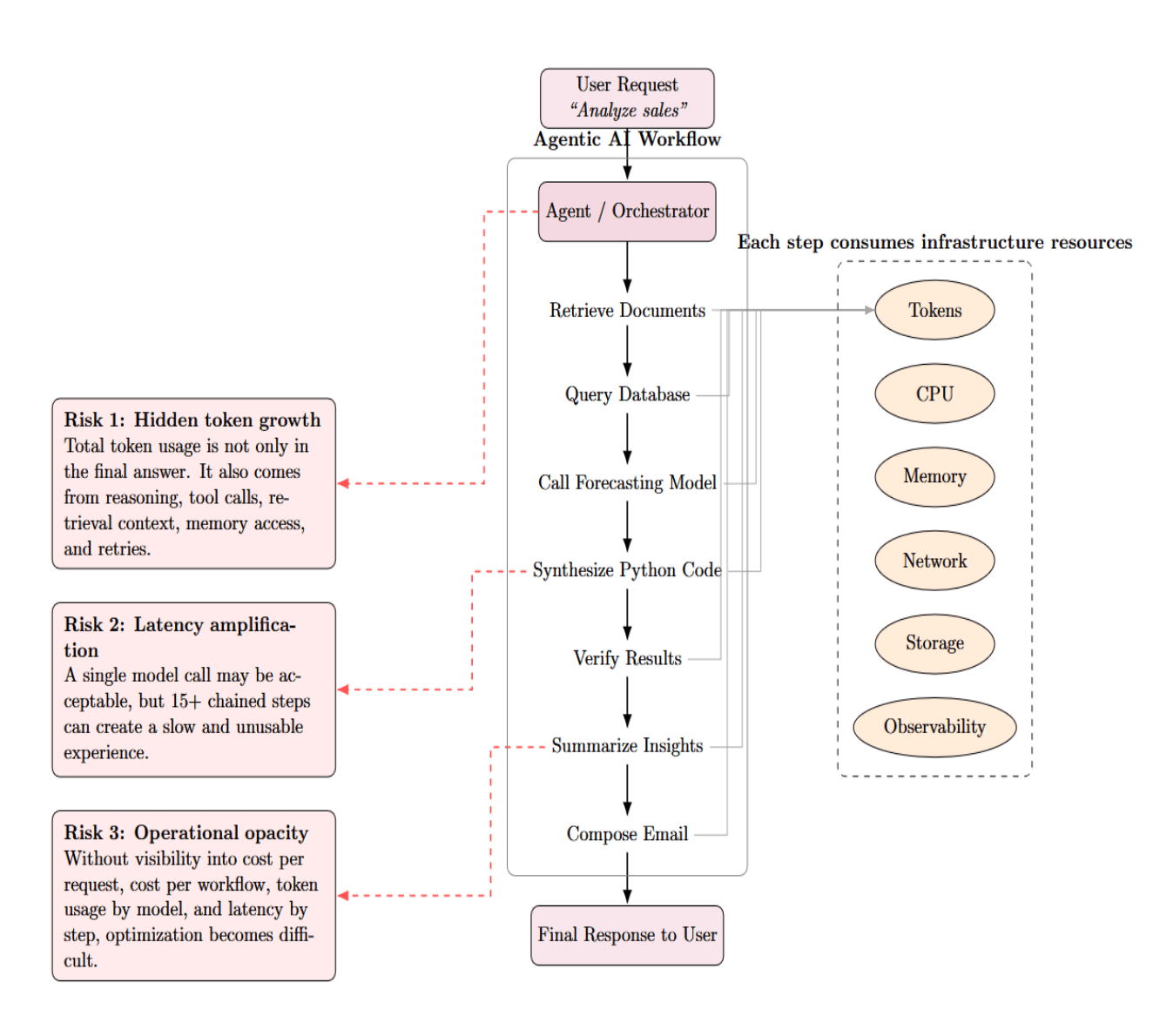
This creates three risks:
- The first risk is hidden token growth. Engineers may estimate costs based only on tokens in the final answer. However, agentic workflows also spend tokens throughout the reasoning process: intermediate steps, tool calls, retrieval context, memory access, and retries. As a result, total token usage can grow by orders of magnitude.
- The second risk is latency amplification. Latency for one model call may be acceptable. But what happens when the agent runs a workflow of 15+ linear calls? If each step adds a delay, we will create an unusable experience for users.
- The third risk is operational opacity. If you can’t see the cost per request, cost per workflow, token consumption by model, and latency by step, then you can’t take actions to improve.
That’s why Chief Technology Officers (CTOs) should evaluate AI platforms on production metrics, not benchmark headlines. Don’t ask, “Which provider has the cheapest model call?” Ask yourself, “Which platform gives us the best cost, latency, and reliability for our actual workload?”
A Framework for Evaluating Inference Cloud Platforms
Engineering leaders should evaluate inference platforms using five criteria. Let’s consider some of them:
- Look at the build-to-run ratio. How many engineer-months does it take to go from prototype to production readiness? If it takes months to learn Kubernetes (or equivalents), implement routing logic, deploy models at scale, and instrument everything with observability, then a platform that handles those capabilities can shave many months off engineering cycle time.
- Evaluate latency predictability. Don’t settle for average latency. Teams should measure p95, p99, time-to-first-token, and inter-token latency under realistic concurrency.
- Require cost transparency. Engineering teams need visibility into where tokens are being used, why retries happened, which models were chosen, and how much each workflow costs. If your AI platform doesn’t surface this information, then AI margins become guesswork.
- Assess model catalog breadth and switching flexibility. Teams should expect their platform to power frontier, open, fine-tuned models, and bring-your-own-models workflows. Choosing a model should not require application rewrites.
- Test operational fit. Does the platform support real-time inference, batch inference, dedicated inference, agent workflows, knowledge bases, evaluation, and monitoring? On DigitalOcean’s AI Platform documentation page, you can note how the platform is framed around managed agents, knowledge bases for RAG implementations, multi-agent routing, and guardrails.
What the Next Two Years Look Like
The table below summarizes the major shifts that will shape AI inference economics over the next few years. It shows why falling token prices alone will not guarantee lower costs, and why model routing, observability, and inference-first cloud architecture will become essential for controlling spend at scale.
| Trend | What It Means | Business Impact |
|---|---|---|
| Token prices may fall, but usage will grow faster | As models become cheaper, developers will use them more often across copilots, agents, workflow automation, multimodal generation, and persistent memory. | Lower unit prices will not automatically reduce total AI spend if token consumption expands across the business. |
| Model routing will become standard | Applications will stop sending every task to the same model. Simple tasks will use cheaper models, while complex reasoning will use stronger models. | Companies will reduce costs by matching each workload to the right model and serving strategy. |
| Long-context and batch workflows will need specialized infrastructure | Long-context workflows require different serving strategies, and batch jobs should not always run through real-time endpoints. | Teams will need more flexible inference architectures to control latency, throughput, and cost. |
| Observability will become a board-level concern | AI costs will move beyond experimental R&D budgets and become visible in gross margin, customer acquisition cost, support cost, and product profitability. | Executives will need clear metrics for AI usage, latency, cost per request, and cost per customer. |
| Cloud architecture will become a competitive advantage | Teams that build on inference-first infrastructure will ship faster and control margins better. | Companies using fragmented systems may face hidden egress costs, duplicated tooling, poor latency visibility, and expensive operational complexity. |
FAQs
1. Why did training dominate AI infrastructure discussions from 2022 to 2024?
Training dominated because GPT-3 and GPT-4 made large-scale model building the center of AI competition. As such, investments around distributed GPU training, large datasets, distributed GPU training, and model evaluation were paramount for organizations hoping to build frontier models.
2. Why is inference becoming more important than training?
Inference happens every time an AI product is used. Training may happen once or occasionally, but inference repeats continuously across prompts, responses, tool calls, RAG pipelines, and agent workflows.
3. What makes inference cost difficult to control?
Token volume, throughput, latency requirements, GPU utilization, retry penalties, routing decisions, context lengths, and model choice all affect inference cost. Small inefficiencies become expensive when multiplied across millions of requests.
4. How does agentic AI increase inference costs?
A single user request can lead to many internal steps. The agent can search, reason, call tools, retrieve information from memory, validate results, and then synthesize a final answer. Each of these individual steps may consume tokens and compute.
5. What should CTOs evaluate when choosing an inference cloud platform?
CTOs should evaluate latency predictability, cost transparency, model routing, observability, model-switching flexibility, GPU efficiency, batch inference support, and whether the platform can support real production workloads, not only benchmark claims.
Conclusion
The AI infrastructure conversation has moved beyond the cost of training large models. Training large models is expensive and still important, but for most businesses, inference is the bigger challenge from both a cost and architectural standpoint. Every prompt sent by a user, response generated by the model, agentic loop workflow, retrieval call, retry, and tool call incurs cost. As a result, inference budgets are turning AI from a one-time research spend into a recurring operational expense that increases along with product usage.
For CTOs, platform teams, and technical founders everywhere, it’s no longer only about whether you can access powerful models. It’s about whether you can serve them reliably, quickly, and economically at scale. Token price, throughput, latency, routing, batching, observability, and GPU efficiency determine whether an AI product goes from prototype to sustainable engineering system.
Running AI in production requires more than general-purpose cloud infrastructure. Inference-first architecture is quickly becoming essential for building production AI. Engineering teams need platforms that empower them to control latency, reduce wasted compute, route requests smarter, observe costs at the token level, and adjust as their models and use cases evolve.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
