AI Technical Writer

Large language models have transformed the way we build intelligent applications. Generative AI Models can summarize documents, generate code, and answer complex questions. However, they still face a major limitation: they cannot access private or continuously changing knowledge unless that information is incorporated into their training data.
Retrieval-Augmented Generation (RAG) addresses this limitation by combining information retrieval systems with generative AI models. Instead of relying entirely on the knowledge embedded in model weights, a RAG system retrieves relevant information from external sources and provides it to the language model during inference. The model then generates a response grounded in this retrieved context.
An end-to-end RAG pipeline refers to the full system that manages this process from beginning to end. It includes ingesting documents, transforming them into embeddings, storing them in a vector database, retrieving relevant information for a user query, and generating an answer using a large language model.
This architecture is increasingly used in modern AI systems such as enterprise knowledge assistants, internal documentation search engines, developer copilots, and AI customer support tools. Organizations adopt RAG because it allows models to remain lightweight while still accessing large knowledge bases that change frequently.
In this tutorial, we will walk through how to design and build a complete RAG pipeline. Along the way, we will explore architectural considerations, optimization strategies, and production challenges developers encounter when deploying retrieval-based AI systems.
Key Takeaways
- RAG combines retrieval and generation for more accurate AI systems: Retrieval-Augmented Generation (RAG) bridges the gap between static language models and dynamic, real-world data. Instead of relying only on pre-trained knowledge, it fetches relevant information at runtime and uses it to generate answers. This makes responses more accurate, up-to-date, and context-aware. It is especially useful for applications like chatbots, internal knowledge assistants, and search systems. Overall, RAG helps reduce hallucinations and improves trust in AI-generated outputs.
- Vector embeddings are the foundation of semantic search in RAG: Embeddings convert text into numerical vectors that capture meaning rather than exact wording. This allows the system to understand similarity between queries and documents even if they use different phrasing. As a result, retrieval becomes more intelligent and context-driven instead of keyword-based. High-quality embedding models like text-embedding-3-large or bge-large-en can significantly improve retrieval performance. Choosing the right embedding model directly impacts the overall quality of your RAG system.
- Each component of the pipeline plays a critical role: A RAG system is made up of multiple steps, including ingestion, chunking, embedding, storage, retrieval, and generation. If any one component is poorly optimized, it can affect the entire pipeline’s performance. For example, bad chunking can lead to irrelevant retrieval, even if your embedding model is strong. Similarly, weak retrieval will result in poor answers, no matter how powerful the language model is. This is why building an end-to-end RAG system requires careful design and tuning at every stage.
- Evaluation is essential for building reliable RAG applications: It is not enough to just build a RAG pipeline, but you must also evaluate how well it performs. This includes checking whether the system retrieves the correct documents and whether the generated answers are accurate and grounded. Metrics like precision and recall help measure retrieval quality, while human evaluation helps assess answer correctness. Creating benchmark datasets with known questions and answers makes it easier to track improvements over time. Continuous evaluation ensures your system remains reliable in production.
Understanding the RAG System Architecture
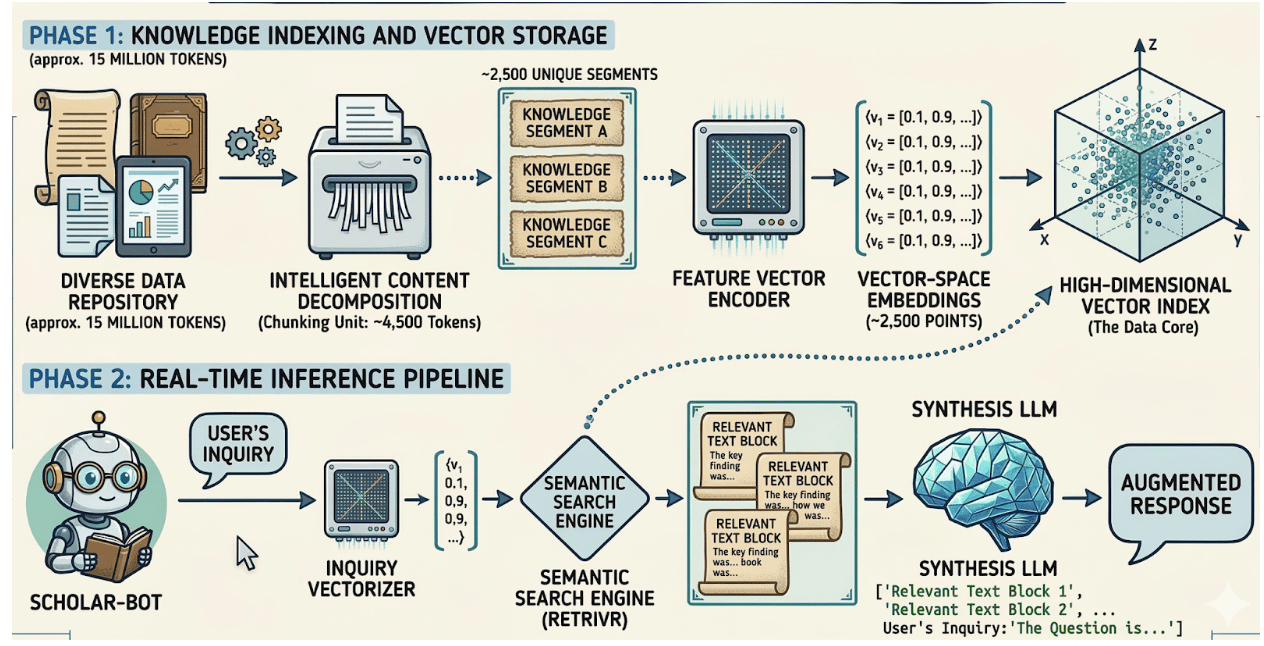
Before implementing the pipeline, it is important to understand how the different components interact. A typical RAG system architecture can be divided into two major workflows: the indexing pipeline and the retrieval pipeline.
The indexing pipeline prepares the knowledge base so that it can be searched efficiently. During this stage, documents are ingested, cleaned, split into chunks, converted into embeddings, and stored in a vector database. This process is usually executed offline or periodically when new data becomes available.
The retrieval pipeline operates during inference. When a user asks a question, the system converts that query into an embedding, searches the vector database for semantically similar chunks, and provides those retrieved passages to the language model. The model then generates a response using both the query and the contextual information.
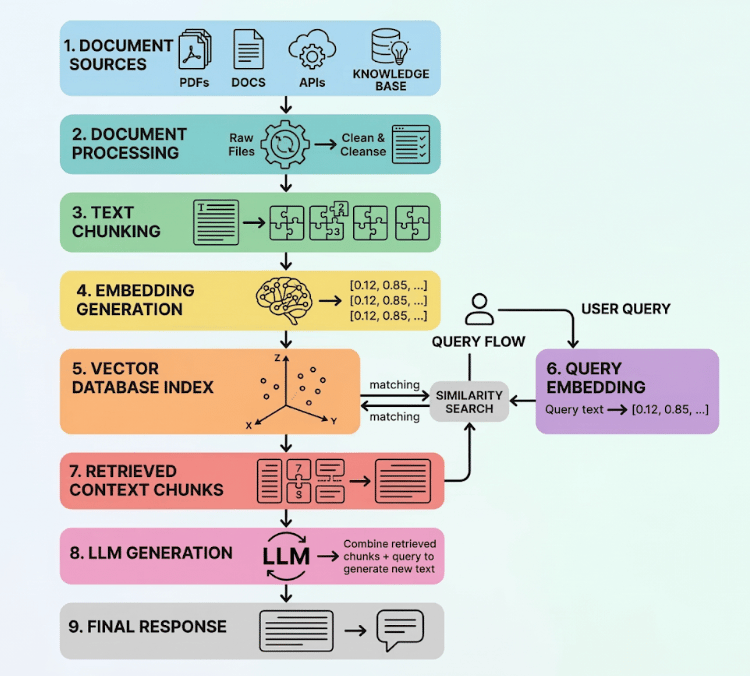
A simplified representation of the pipeline looks like this:
Document Sources
(PDFs, Docs, APIs, Knowledge Base)
|
v
Document Processing
|
v
Text Chunking
|
v
Embedding Generation
|
v
Vector Database Index
|
v
User Query → Query Embedding → Similarity Search
|
v
Retrieved Context Chunks
|
v
LLM Generation
|
v
Final Response
This architecture enables the system to retrieve information dynamically rather than relying solely on model training.
Data Ingestion in a RAG Pipeline
The first stage of the pipeline involves gathering the data that the AI system will use as its knowledge source. In many real-world applications, this information is distributed across multiple systems. Organizations may store documentation in internal knowledge bases, PDFs, wikis, product manuals, or database records.
The ingestion stage extracts textual information from these sources and prepares it for processing. Depending on the data format, ingestion may involve parsing HTML pages, converting PDFs to text, or querying APIs to retrieve structured records.
At this stage, developers often implement preprocessing steps such as removing redundant formatting, normalizing whitespace, and filtering irrelevant sections. These steps are important because retrieval performance strongly depends on the quality of the text data stored in the system.
For enterprise knowledge retrieval systems, ingestion pipelines are usually automated and scheduled. For example, an internal documentation chatbot might update its knowledge base daily by ingesting the latest documentation changes from a repository.
Text Chunking: Preparing Documents for Retrieval
After ingestion, documents must be divided into smaller pieces before they can be embedded. This step, known as text chunking, plays a critical role in the overall performance of the RAG pipeline.
Large documents cannot be embedded effectively because embedding models have token limits and because large chunks reduce retrieval precision. Instead, documents are broken into manageable segments that capture a coherent piece of information.
Chunk size is typically chosen between 200 and 500 tokens. Smaller chunks provide more precise retrieval results, while larger chunks preserve more contextual information. Many production pipelines use overlapping chunks to prevent important sentences from being split across boundaries.
The following diagram illustrates how a long document is transformed into multiple overlapping chunks:
Original Document
-------------------------------------------------------
| Paragraph 1 | Paragraph 2 | Paragraph 3 | Paragraph 4 |
-------------------------------------------------------
After Chunking
-------------------------------------------------------
| Chunk 1 | Chunk 2 | Chunk 3 | Chunk 4 | Chunk 5 |
-------------------------------------------------------
Chunk Example
Chunk 1: Paragraph 1 + part of Paragraph 2
Chunk 2: Paragraph 2 + part of Paragraph 3
Choosing an effective chunking strategy significantly improves retrieval accuracy because each chunk represents a focused semantic concept.
Embedding Generation
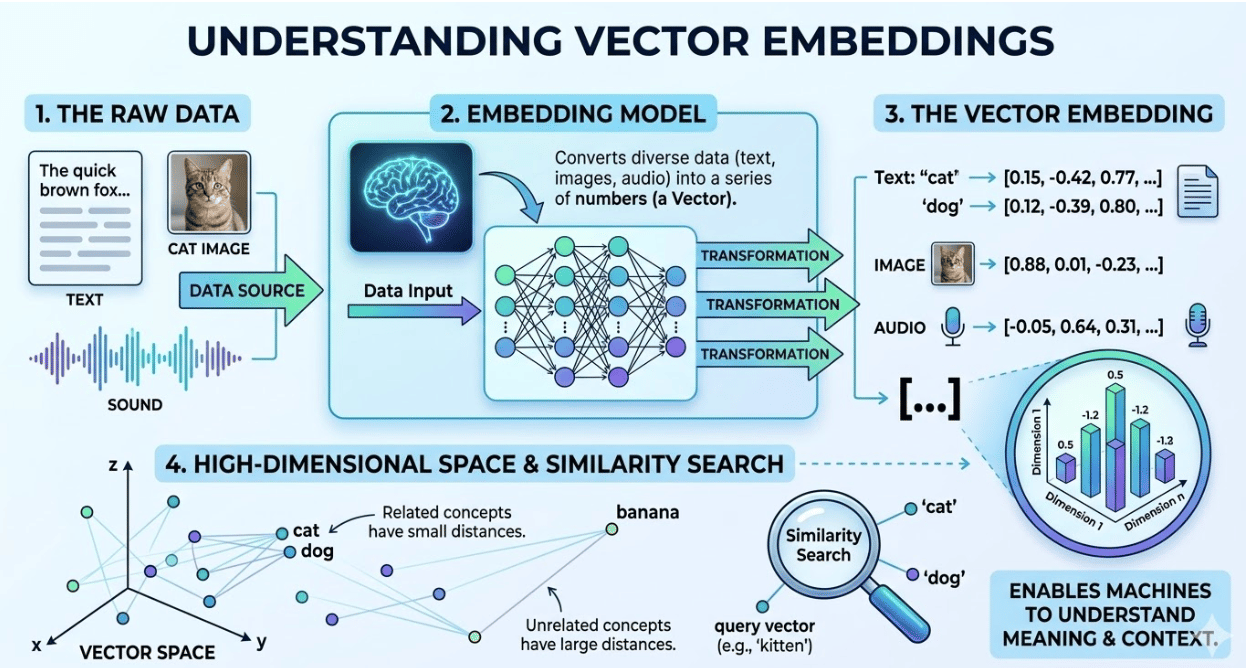
Once documents are divided into chunks, each chunk must be converted into a numerical representation called an embedding. Embeddings transform text into high-dimensional vectors that capture semantic meaning.
For example, two sentences that express similar ideas will produce vectors that are close to each other in vector space. This property allows vector databases to retrieve semantically related text even when the wording differs.
Embedding models are trained using large datasets and transformer architectures. When a chunk is processed, the model generates a vector with hundreds or thousands of dimensions. These vectors serve as the foundation for similarity search.
Embedding generation occurs during both indexing and retrieval. During indexing, embeddings are generated for each document chunk. During retrieval, the user’s query is also converted into an embedding so that it can be compared against stored vectors.
This mechanism allows the RAG system to perform semantic search, which is far more powerful than traditional keyword matching.
Vector Embedding
Vector embeddings are dense numerical representations of data, which can be text, images, or audio. Vector embeddings are used to capture the semantic meaning of the data in a high-dimensional vector space. In an end-to-end RAG pipeline, embeddings are used to convert both documents and user queries into vectors so that similarity between them can be measured using metrics like cosine similarity. This allows the system to retrieve context based on meaning rather than exact keyword matches, making responses more accurate and relevant.
For example, even if a query doesn’t contain the same words as a document, embeddings can still identify it as relevant if the underlying intent is similar. Popular embedding models used in RAG systems include text-embedding-3-large, all-MiniLM-L6-v2, bge-large-en, and e5-large-v2, each offering different trade-offs in performance, cost, and deployment flexibility.
Storing Vectors in a Database
After embeddings are created, they must be stored in a specialized database capable of performing fast similarity searches. These systems are known as vector databases and form the core of the RAG retrieval infrastructure.
Unlike traditional databases that index numeric or textual fields, vector databases are optimized to search across high-dimensional vectors. They use approximate nearest neighbor algorithms to identify vectors that are closest to a query embedding.
The structure of a stored vector typically includes the embedding itself, the original text chunk, and metadata describing the source of the information. Metadata can include document identifiers, timestamps, or categories that allow filtering during retrieval.
A simplified representation of vector storage looks like this:
Vector Database
ID Vector Embedding Text Chunk
---------------------------------------------------------
1 [0.12, -0.44, 0.92...] "RAG combines retrieval..."
2 [0.55, 0.33, -0.14...] "Vector databases enable..."
3 [-0.77, 0.08, 0.62...] "Embeddings represent..."
Popular vector database technologies include managed services and open-source platforms designed specifically for AI workloads. The choice often depends on scale, infrastructure preferences, and latency requirements.
Retrieval in a RAG Pipeline
When a user submits a question, the system begins the retrieval stage. The query is first converted into an embedding using the same embedding model used during indexing. Maintaining the same embedding model is important because similarity comparisons rely on consistent vector representations.
The query embedding is then sent to the vector database. The database performs a similarity search to find document chunks whose embeddings are closest to the query vector. These chunks represent the pieces of information most relevant to the user’s question.
The retrieved chunks are then combined and passed to the language model as contextual input. The model uses this context to generate a response grounded in actual documents rather than relying solely on its training data.
This process ensures that answers are based on real knowledge sources and can be updated whenever the underlying documents change.
Generation with a Large Language Model
The final stage of the pipeline involves generating a response using a language model. At this point, the system already has two pieces of information: the user’s question and the retrieved context.
These elements are combined into a prompt that instructs the model to answer the question using the provided information. Because the context is derived from authoritative documents, the model’s output becomes significantly more reliable and factual.
This stage also allows developers to control how responses are generated. Prompts may instruct the model to summarize information, provide citations, or answer in a specific format. Some systems also include guardrails that prevent hallucinations or restrict responses to retrieved information.
For example, if a user asks a question, the system first pulls the most relevant text from your knowledge base, then the LLM rewrites that content into a helpful answer, making it more conversational, structured, and easy to understand. This step is what makes RAG powerful, because it combines accurate, up-to-date information with fluent natural language generation, reducing hallucinations and improving answer quality.
Code Demo: Building a Simple End-to-End RAG Pipeline
The following example demonstrates how a basic rag pipeline for LLM applications can be implemented in Python. The example uses document loading, chunking, embeddings, and a vector database to create a minimal working pipeline.
Install dependencies
pip install langchain chromadb sentence-transformers openai
Load documents
from langchain.document_loaders import TextLoader
loader = TextLoader("knowledge_base.txt")
documents = loader.load()
Split documents into chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
chunks = splitter.split_documents(documents)
Generate embeddings
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
Store vectors
from langchain.vectorstores import Chroma
vector_db = Chroma.from_documents(
documents=chunks,
embedding=embeddings
)
Retrieval and generation
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_db.as_retriever()
)
response = qa_chain.run(
"What is retrieval augmented generation?"
)
print(response)
This simple implementation demonstrates how document retrieval and language models can be combined into a working RAG system.
Evaluating RAG System Performance
Evaluating a RAG system is important because you need to be sure that it is not only retrieving the right information but also generating correct and useful answers from it. In simple terms, a good RAG pipeline should find the right content and then explain it correctly.
First, let’s look at retrieval evaluation. This checks whether the system is pulling the right documents from your database. Imagine you have a knowledge base about cloud services, and a user asks, “How can I run AI models on GPUs?”. If your system retrieves documents about GPU droplets or AI infrastructure, that’s a good sign. But if it returns unrelated content like pricing pages or networking docs, retrieval quality is poor. Metrics like recall (did we find all relevant documents?) and precision (were the retrieved documents actually relevant?) help measure this. For example, if 5 documents are relevant but your system only retrieves 2, recall is low.
Next is generation evaluation, which focuses on the answer produced by the language model. Even if retrieval is correct, the model (like GPT-4 or Llama 3) might still generate incomplete or incorrect responses. For instance, if the retrieved document clearly says “GPU droplets support CUDA workloads”, but the model responds with “GPU support is limited”, that’s a problem. This is why human evaluation is often needed to check if the answer is factually correct, complete, and grounded in the provided context. Automated metrics struggle to detect things like s or subtle inaccuracies.
To make evaluation consistent, teams usually create an evaluation dataset. This is a collection of sample questions along with their correct answers and sometimes the expected source documents. For example:
- Question: “What are GPU droplets used for?”
- Expected answer: “They are used for AI/ML workloads, training models, and high-performance computing.”
You can then run your RAG system on this dataset and compare its answers against the expected ones. Over time, this helps you track improvements, catch errors, and tune your system (for example, by improving chunking, choosing a better embedding model, or adjusting prompts).
In practice, strong RAG evaluation combines:
- Retrieval checks → Did we fetch the right information?
- Answer checks → Did we explain it correctly?
- Continuous testing → Are we improving over time?
This ensures your RAG pipeline is reliable, accurate, and ready for real-world use.
Scaling and Production Considerations
Prototype RAG pipelines often work well with small datasets, but production deployments introduce additional challenges. Large organizations may store millions of document chunks, requiring scalable infrastructure for indexing and retrieval.
Latency also becomes an important concern. Vector searches, embedding generation, and LLM inference all contribute to response time. Developers must carefully optimize these components to ensure interactive performance.
Production systems frequently incorporate caching layers, query batching, and efficient indexing strategies. Monitoring tools are also used to track retrieval accuracy, system latency, and cost per query.
Cost and Latency Optimization
Operating a RAG pipeline at scale can become expensive if not carefully optimized. Each query may require embedding generation, vector search, and language model inference.
Several strategies help reduce these costs. Caching responses for frequently asked questions prevents repeated model inference. Limiting the number of retrieved chunks also reduces token usage and speeds up generation.
Another important technique is re-ranking. Instead of sending many retrieved documents to the language model, a re-ranking model selects the most relevant passages before generation. This improves response quality while reducing computational overhead.
RAG vs Fine-Tuning
A common question among developers is whether to use retrieval-augmented generation or fine-tuning.
Fine-tuning changes a model’s internal weights by training it on additional datasets. This approach works well for teaching models specific styles or behaviors. However, it is less effective for continuously changing knowledge because retraining the model is expensive and time-consuming.
RAG systems take a different approach by keeping the model unchanged while retrieving knowledge dynamically. This makes them ideal for applications where information changes frequently, such as product documentation or customer support knowledge bases.
For most knowledge-intensive applications, RAG provides a more flexible and maintainable solution.
FAQ
What is an end-to-end RAG pipeline?
An end-to-end RAG (Retrieval-Augmented Generation) pipeline is a system that combines information retrieval with a language model to generate accurate, context-aware responses. Instead of relying only on what the model learned during training, the system first searches for relevant information from external sources (like documents, PDFs, or databases) and then uses that information to generate an answer.
Think of it like this:
- Step 1 → Find the most relevant information
- Step 2 → Use a language model like GPT-4 or Llama 3 to turn that information into a natural response
This makes RAG systems more accurate, up-to-date, and reliable compared to standalone LLMs.
What components are required for a RAG system?
A typical RAG pipeline has several key components working together:
- Document Ingestion → Collect data from sources like PDFs, websites, or databases
- Text Chunking → Break large documents into smaller, manageable pieces
- Embedding Generation → Convert text into vectors using models like all-MiniLM-L6-v2
- Vector Database → Store embeddings in systems like Pinecone or Weaviate
- Retriever → Finds the most relevant chunks based on similarity
- Language Model → Generates the final answer using retrieved context
All these steps together form a complete pipeline from raw data to final response.
How do embeddings work in a RAG pipeline?
Embeddings convert text into numerical vectors that represent meaning. Instead of matching exact words, they capture semantic similarity.
For example:
- “How to train AI models?”
- “Steps to train machine learning models”
Even though the wording is different, embeddings will place these sentences close together in vector space because they mean the same thing.
In a RAG pipeline:
- Documents → converted into embeddings and stored
- User query → also converted into an embedding
- System → finds the closest matches using similarity search
Models like text-embedding-3-large and bge-large-en are commonly used for this.
Which vector database is best for RAG?
There is no single “best” vector database—it depends on your use case. Some popular options include:
- Pinecone → Fully managed, easy to scale, great for production
- Weaviate → Open-source with built-in features like filtering
- Milvus → High performance for large-scale systems
- Chroma → Lightweight and ideal for local development
Simple rule:
- Small project → Chroma
- Production SaaS → Pinecone
- Large-scale infra → Milvus or Weaviate
How do you evaluate a RAG system?
Evaluating a RAG system means checking two things:
1. Retrieval Quality
Are we getting the right documents?
Example:
If the query is “What are GPU droplets?” and the system retrieves AI infrastructure documents → good
If it retrieves unrelated content → poor retrieval
Metrics:
- Recall → Did we find all relevant documents?
- Precision → Are the retrieved documents actually useful?
2. Generation Quality
Is the answer correct and grounded?
Even if retrieval is correct, models like GPT-4 can sometimes:
- Miss important details
- Add incorrect information (s)
So teams often:
- Use human evaluation
- Create test datasets (questions + correct answers)
- Compare outputs over time
What is the difference between RAG and fine-tuning?
The main difference is how the model gets knowledge:
RAG (Retrieval-Augmented Generation)
- Fetches external data at runtime
- No need to retrain the model
- Easy to update knowledge (just update documents)
Fine-tuning
- Updates the model’s internal weights through training
- Knowledge becomes part of the model
- Requires time, data, and compute
Simple example:
- RAG → “Look it up and answer”
- Fine-tuning → “Memorize and answer”
In practice, many systems combine both.
How do you reduce latency in a RAG pipeline?
Latency (response time) is critical in production systems. Here are simple ways to improve it:
-
Optimize chunk size
- Too large → slower retrieval
- Too small → too many results
-
Limit retrieved documents (top-k)
- Instead of retrieving 10 chunks, try 3–5
-
Use efficient vector indexes
- Databases like Milvus use optimized search algorithms
-
Cache frequent queries
- Store responses for repeated questions
-
Use smaller or faster models
- Instead of heavy models, use optimized ones like Llama 3 variants
-
Parallel processing
- Run retrieval and preprocessing steps efficiently
Conclusion
Building an end-to-end RAG pipeline is about combining the strengths of retrieval systems and large language models to create applications that are both accurate and context-aware. Instead of relying only on pre-trained knowledge, a RAG system can fetch relevant information in real time and use models like GPT-4 or Llama 3 to generate clear, human-like responses grounded in that data. In this article, we understood each of the steps used to create the RAG pipeline from data ingestion and chunking to vector embeddings, retrieval, and response generation. Each component plays a critical role, and even small improvements (like better chunking strategies or choosing the right embedding model) can significantly impact overall performance. As organizations continue to build AI-powered applications, RAG stands out as a practical and scalable approach for use cases like chatbots, knowledge assistants, and document search. By continuously evaluating and refining your pipeline, you can create systems that are not only intelligent but also reliable and production-ready.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
