AI Technical Writer

Introduction
Picture this: a user opens your support chat and types, “What are your business hours?”
Somewhere in your backend, that five-word question gets routed to an advanced model you might use to debug Kubernetes networking failures and explain distributed tracing across microservices. The model returns an answer in two seconds. The user says thanks and closes the chat.
You just spent frontier-model tokens on a question that a much smaller, less pricy model could have answered just as well. Now multiply that by the thousands of similar queries your support bot handles every day.
This is the most common and most expensive mistake developers make when building AI-powered applications: picking one model and calling it everywhere. Not because it is the right architectural decision, but because it is the easiest one. One API key, one endpoint, one model name hardcoded into the config, and you’re shipping.
The problem is that not all queries are created equal. A support bot answering real customer questions handles a wide range of questions, which can be simple queries or extremely advanced queries. General FAQs, such as opening hours, refund policies, and account setup, that need a fast and cheap response, not an expensive reasoning engine. Billing disputes require some contextual understanding and careful language, so a mid-tier model earns its cost. But a customer reporting that their GPU Droplet inference workload is producing inconsistent outputs after a driver update? That genuinely needs a capable model with deep technical knowledge.
When you use one model for all three, you’re either overpaying on the easy queries or underserving the hard ones. Neither outcome is acceptable in production.
The better approach is to route by complexity and match the model to the task, not to the habit. Send simple queries to a lightweight model, reserve frontier intelligence for the requests that actually need it, and let the infrastructure make that decision automatically rather than hardcoding it yourself or writing multiple if-else conditions.
That’s exactly what you’ll build in this article. Starting from an example of a real Python support bot, you’ll connect it to DigitalOcean’s Inference Router that classifies each incoming request against a set of task definitions you configure once, and matches it to the right model automatically. No routing logic in your application code, no per-vendor API keys, no manual if/else trees that break the moment your query patterns change.
Key Takeaways
- Inference routing helps AI applications automatically choose the best model based on task complexity, cost, and latency.
- Simple queries can be handled by smaller, less pricey models, while complex reasoning tasks can use larger frontier models.
- Using one expensive model for every request can significantly increase inference costs at scale.
- Inference routers are especially useful for AI agents, RAG systems, and multi-model AI applications.
Why One Model for Everything Is a Design Flaw
DigitalOcean AI Platform now includes an inference routing layer that helps applications intelligently send AI requests to different models. Instead of hardcoding one model for every request, the inference router acts as a smart traffic manager between applications and multiple LLMs.
Application → Inference Router → Different AI Models
The router decides:
- Which model should handle the request
- Whether to prioritize speed, quality, or cost
- When to fall back to another model if one becomes slow or unavailable
For example:
- Simple FAQ queries → smaller low-priced model
- Code generation → stronger coding model
- Long reasoning tasks → larger reasoning model
- Vision tasks → multimodal model
The application still uses a single API endpoint while the router handles the complexity behind the scenes.
AI agents often perform different types of tasks in one single AI pipeline, such as:-
- Summarization
- Retrieval
- Planning
- Code execution
- Vision understanding
Different models may be better for different agent steps. Routing allows agents to choose the best model for each task.
Almost any AI-powered application built in the last two years, and you’ll find the same pattern in the backend: one model, one endpoint, every request treated identically. It works. It ships. And it quietly becomes one of the most expensive architectural decisions in the codebase.
To understand why, you need to look at what’s actually happening at the query level.
Consider a support bot handling real customer traffic over the course of a single day. The queries it receives don’t form a uniform distribution of difficulty. They cluster.
A large portion of them is pure information retrieval — “What payment methods do you accept?”, “How do I reset my password?” “Where can I find my invoice?” These questions have deterministic answers that live in your documentation. Any reasonably capable model can answer them correctly. They require no reasoning, no multi-step inference, no domain expertise.
A smaller portion involves contextual understanding — “I was charged twice this month, and I already contacted support last week”, “My team plan renewal is coming up, but I want to downgrade first”. These need the model to hold context, infer intent, and respond with careful language. A mid-tier model handles them well.
A smaller portion still are genuinely hard — “My Kubernetes pod is crashing with OOMKilled errors after I scaled my inference workload on GPU Droplets”, “I’m getting inconsistent outputs from my fine-tuned model after a checkpoint reload”. These require deep technical knowledge, multi-step reasoning, and the ability to ask clarifying questions intelligently. This is where a frontier model actually earns its cost.
The mistake isn’t using a frontier model. The mistake is using it for all three tiers.
The Costs
Frontier AI models are much more expensive than smaller models, often costing 10x–50x more per request. This may not matter for small projects, but at the production scale, costs increase quickly. In agentic AI systems, additional tasks such as summarization, memory search, and tool calling also consume tokens, which further increases overall inference costs if everything is routed through expensive frontier models by default.
The Hardcoding Logic
The natural first instinct is to write routing logic:
if "billing" in query.lower():
model = "mid-tier-model"
elif any(word in query.lower() for word in ["kubernetes","gpu", "pod", "error", "crash"]):
model = "frontier-model"
else:
model = "cheap-model"
This may seem fine at first, but it fails easily. Keyword-based routing struggles when users phrase questions differently, use other languages, or ask simple-looking questions that are actually complex. It also requires constant manual updates as user queries change over time.
What Production-Grade Routing Actually Requires
For routing to work reliably at the query level, it needs four things that keyword matching can’t provide.
First, it needs semantic understanding. The classifier needs to distinguish “I have a question about my bill” from “My deployment is billing me for resources I didn’t use.” One is a simple FAQ, the other is a technical and billing hybrid that warrants a more capable model.
Second, it needs to be task-aware, not just query-aware. The same user session might move from a simple onboarding question to a complex troubleshooting issue in three turns. The routing decision needs to happen per request, not per session, based on what’s actually being asked right now.
Third, it needs fallback behavior. If a chosen model rate-limits or returns a server error, the system should automatically try the next model rather than surfacing a failure to the user.
Fourth, it needs observability. You need to know which model served which request and why, both for debugging misroutes and for understanding your actual cost distribution in production.
Building all four of these yourself is a significant engineering and hard work. DigitalOcean’s Inference Router provides many of these capabilities through configuration rather than code, which is what the rest of this article is about.
How DigitalOcean’s Inference Router Works Under the Hood
Before diving into the code, it helps to understand what happens the moment your application sends a request. The concept is simple once you see it clearly.
One Endpoint, Many Models
The starting point is the endpoint itself:
https://inference.do-ai.run/v1
This is a fixed, stable URL that never changes. Behind it sits DigitalOcean’s entire model catalog, which is over 70 models that include options like Llama 3.3 70B, DeepSeek, and Qwen, alongside frontier models from OpenAI and Anthropic.
The router sits in front of all of this. Instead of your application deciding which model to call, it sends every request to the same endpoint with router:<your-router-name> as the model name, and the platform figures out the rest.
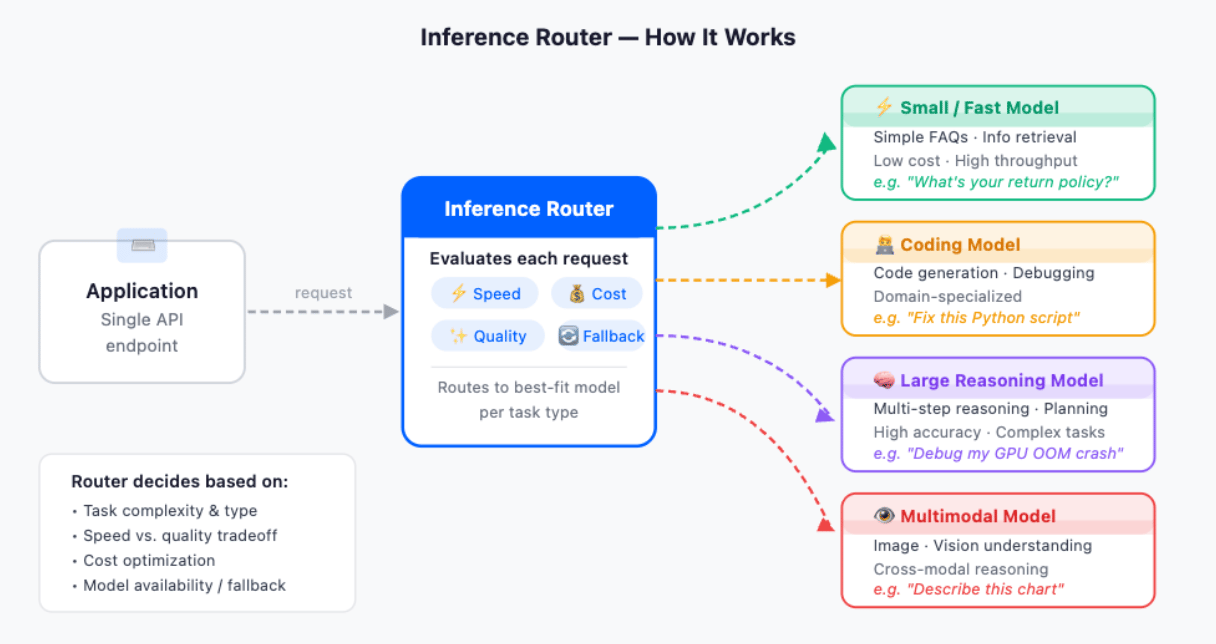
What Happens When a Request Comes In
When your application sends a message to the router, three things happen in sequence before a response comes back.
First, the router reads your request, the system message, the user message, and any conversation history, and runs it through a classifier. The classifier compares the request against the task definitions you configured when you built the router. Each task has a name and a description, and those descriptions act as the routing signal. A request about a crashing Kubernetes pod matches a technical_troubleshooting task. A question about payment methods matches a general_faq task.
Second, once the classifier picks a task, the router selects a model from that task’s pool. You can have up to three models per task, and you control how the router picks between them using a selection policy:
- Cost Efficiency — picks the cheapest model in the pool first, measured by token cost
- Speed Optimization — picks the fastest model based on Time to First Token (TTFT) on DigitalOcean’s infrastructure
- Manual Ranking — picks in the order you specified when building the task
- Optimal — available for pre-configured tasks, uses DigitalOcean’s own benchmarking to pick the best model for that task type
Third, the router sends the request to the selected model and streams the response back to your application. The response looks identical to any standard chat completion response — same format, same fields, with one addition: a model field that tells you exactly which model was selected. You don’t need to guess or log it separately; it comes back in every response automatically.
What Happens When Something Goes Wrong
For requests that don’t match any of your defined tasks, such as ambiguous queries, edge cases, or anything the classifier isn’t confident about, the router falls back to the fallback models you specified when creating the router. This means your application always gets a response, even when query patterns fall outside what you anticipated.
Keeping a Session on One Model
There’s one behavior worth understanding if you’re building a multi-turn conversation: by default, each request is routed independently. The first message in a conversation might go to one model, and the second might go to a different one if the classifier reads it differently.
For most support bot use cases, this works fine. But if you need the entire conversation to stay on one model, suppose for cache consistency or to preserve reasoning continuity across turns, then there is also a way. DigitalOcean provides an X-Model-Affinity header. Set it to a unique session identifier on your first request, and every subsequent request with the same value skips routing and pins to whichever model the first call selected. Responses include a “pinned”: true field when the session is locked in.
This header isn’t exposed natively in most client libraries yet, so implementing it requires a small proxy layer in front of the endpoint. For a straightforward support bot, it’s optional; the per-request fallback already handles reliability, and the quality difference between turns is minimal for most query types.
Model affinity helps keep the same model assigned to a session during multi-step AI workflows such as agents, tool calling, and long conversations. This improves response consistency and prevents issues caused by switching between different models mid-session. It also enables KV cache reuse, where repeated conversation history can be reused instead of recomputed, reducing latency, GPU workload, and input token costs significantly. By sending an X-Model-Affinity session ID, the router selects a model once and reuses it for future requests, improving both performance and cost efficiency.
Setting Up the Inference Router and Getting Started with Inference Router
Before writing a single line of code, you need a router configured in the Control Panel. This is a one-time setup. Once this is completed, your application just references it by name, and the platform handles everything else.
Step 1: Navigate to Inference Router
In the DigitalOcean Control Panel, click INFERENCE in the left sidebar and select Inference Router. You’ll land on a page with two options: use a preset router to get started immediately, or build a custom one from scratch.
Step 2: Choose Your Starting Point
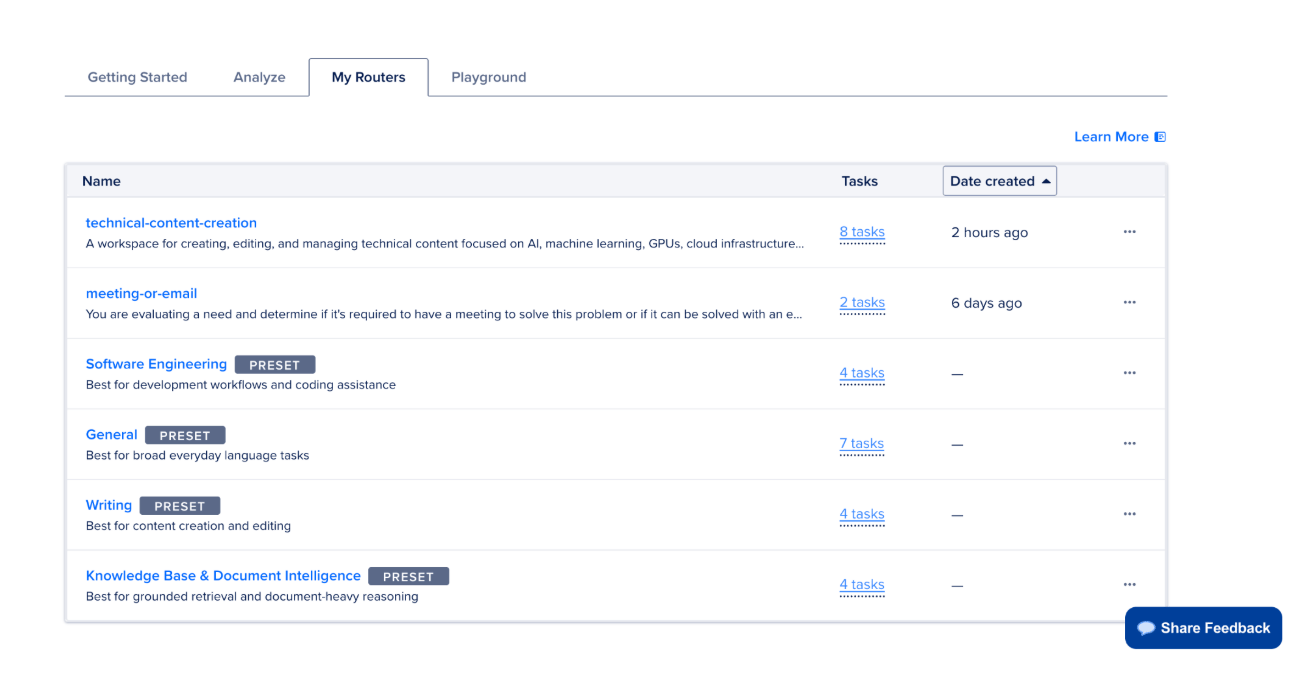
If you want a one-click setup, click See Default Routers on the Getting Started tab. DigitalOcean ships pre-configured routers optimized for common patterns — writing and content development, software engineering, and document intelligence. These are ready to use immediately and visible under the My Routers tab once selected.
For a support bot with distinct complexity tiers, a custom router gives you more control. Click Create Router in the top right to proceed.
Step 3: Name and Describe Your Router
On the Create a Router page, fill in two fields first:
- Name — pick something stable and descriptive, like support-bot-router. You’ll reference this directly in your code as router:support-bot-router, so avoid spaces or special characters.
- Description — this field is more important than it looks. It acts as the routing prompt, giving the classifier context about what the router is for. Be specific: something like “A support assistant that handles general FAQs, billing inquiries, and deep technical troubleshooting for cloud infrastructure products” gives the classifier a much better signal than a generic description.
If you want to get the step-by-step process to create an Inference Router, please feel free to check out the documentation on “Create Inference Router in the Control Panel.”
Step 4: Define Your Tasks
This is where you map query complexity to model tiers. In the Router Tasks section, you have two options.
Using pre-configured tasks is the faster path. Click Add Task from the dropdown to open the Add Tasks panel. DigitalOcean provides benchmarked tasks for things like summarization, code generation, bug fixing, and text extraction. Click the + next to any task to inspect its description, model pool, and selection policy before adding it. For a support bot, look for tasks aligned with FAQ handling, technical reasoning, and document or billing context. Once selected, click Save.
Using custom tasks gives you full control over model selection and routing policy.
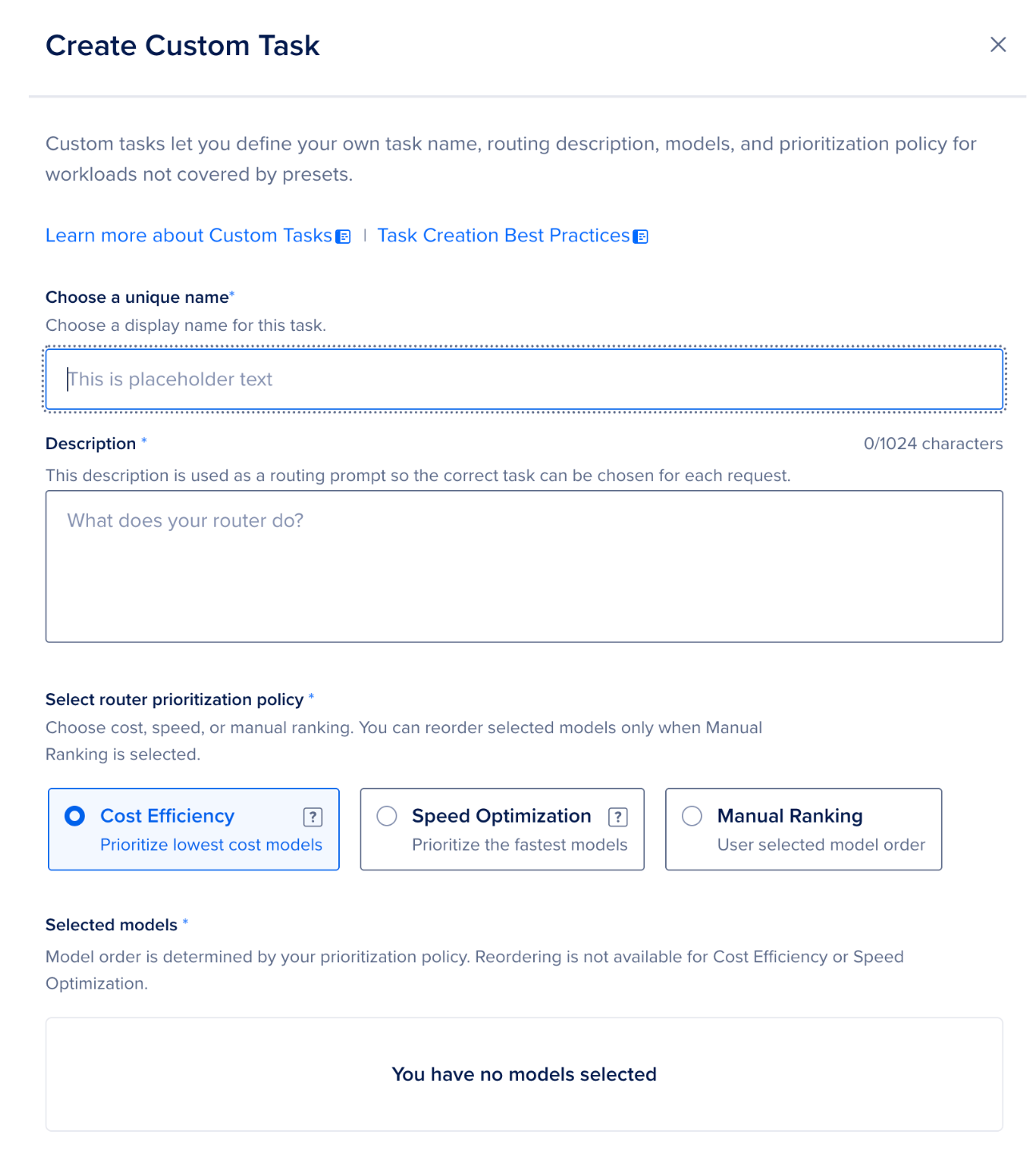
Click Add Custom Task from the dropdown and fill in the following for each task:
- Name and description — be precise and use noun-centric language. The classifier performs better when task names directly reflect their intent and descriptions have minimal overlap with each other. For example:
| Task | Good | Avoid |
|---|---|---|
| Name | technical_troubleshooting | hard_stuff |
| Description | “Diagnosing infrastructure failures, Kubernetes errors, GPU memory issues, and API debugging.” | “Anything technical or complex” |
- Selection policy — choose one of three: Cost Efficiency, Speed Optimization, and Manual Ranking.
- Model pool — select up to three models per task, in the order you want the router to try them. For the support bot, a practical starting setup looks like this: Click Save after configuring each task.
Step 5: Set a Fallback Model
Fallback models handle requests that don’t match any of your defined tasks — ambiguous queries, edge cases, or anything the classifier isn’t confident about. In the Fallback Models section, click Add Fallback Models, select one or two reliable general-purpose models, and drag to reorder them by preference. A mid-tier model like Llama 3.3 70B is a safe fallback — capable enough to handle most edge cases without frontier pricing.
Step 6: Create the Router
Click Create Router. Once creation completes, the router appears in the My Routers tab. From this point on, your application references it with a single line:
"model": "router:support-bot-router"
No other code changes needed. The router is live, and every request you send will now be classified and dispatched automatically.
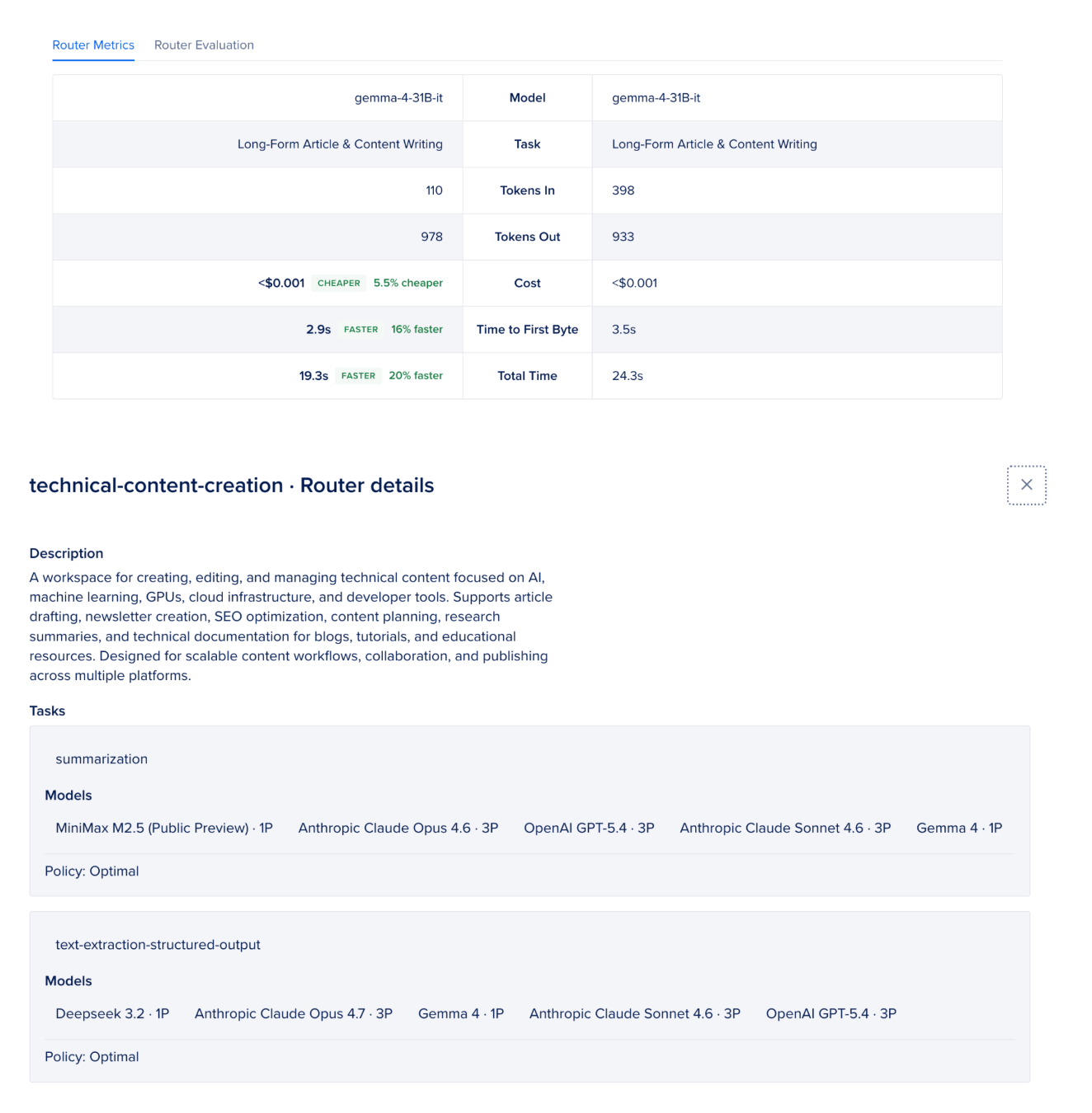
Building the Support Bot: Code Walkthrough
With the router configured, the implementation is straightforward. The entire bot fits in a single Python file, and the only library you need beyond the standard library is requests.
Prerequisites
Before running the code, make sure the following prerequisites are completed:
- A DigitalOcean account with access to the Inference product
- A model access key in sk-do-… format created under Inference → Manage → Model Access Keys
- An Inference Router created with a unique name under Inference → Inference Router
- Python 3.8+ installed along with the requests library using pip install requests
Setting Up the Client
import requests
import json
url = "https://inference.do-ai.run/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer doo_v1_xxx",
}
Two things worth noting here. First, the below endpoint is a fixed, stable URL, and it never changes regardless of which model or router is selected on the DigitalOcean side. This means you can swap models, restructure your router pool, or add new task types in the Control Panel without touching a single line of application code.
https://inference.do-ai.run/v1
Second, the Authorization header follows the standard Bearer token format, making this endpoint a drop-in replacement for any OpenAI-compatible client. If you already have an application calling api.openai.com, switching to the Inference Router is a two-line change: the base URL and the key.
The Core Function
def ask_support_bot(question):
print(f"\n{'='*60}")
print(f"Customer Query: {question}")
print(f"{'='*60}")
data = {
"model": "router:support-bot-router",
"messages": [
{
"role": "system",
"content": "You are a helpful customer support assistant. Answer billing questions, technical issues, and general FAQs clearly and concisely.",
},
{
"role": "user",
"content": question,
}
],
"stream": True,
}
The model field is where the routing happens. Instead of a specific model slug like llama3.3-70b-instruct, you pass router:<your-router-name>. This tells the Inference Engine to run the request through your router’s classifier rather than directly to a model. The router reads the full payload: system message, user message, and any prior conversation context, and matches it against the task definitions you configured.
The system message here does double duty: it gives the model its persona, and it also provides additional context that the router can use when classifying ambiguous queries. A billing question phrased vaguely (“something’s wrong with my account”) becomes easier to classify correctly when the system prompt signals this is a support context.
stream: True enables Server-Sent Events (SSE), so the response arrives as a sequence of chunks rather than a single payload. For a support bot, this is important for perceived responsiveness; users see the answer start appearing immediately rather than waiting for the full response to generate.
Reading the Stream and Capturing the Model
response = requests.post(url, headers=headers, json=data, stream=True)
model_logged = False
for line in response.iter_lines():
if line:
decoded = line.decode("utf-8")
if decoded == "data: [DONE]":
break
if decoded.startswith("data: "):
try:
chunk = json.loads(decoded[6:])
if not model_logged:
model_name = chunk.get("model", "unknown")
print(f"Model selected by router: {model_name}\n")
print("Response:")
model_logged = True
content = chunk["choices"][0]["delta"].get("content", "")
if content:
print(content, end="", flush=True)
except json.JSONDecodeError:
print("Could not parse line:", decoded)
print()
Each line in the stream follows the SSE format: data: <json_payload>. The decoded[6:] slice strips the data: prefix before parsing, which is the step most streaming implementations get wrong — passing the raw line directly to json.loads will fail every time because of that prefix.
The model_logged flag is a small but important detail. Every chunk in the stream carries the model field, which tells you which model the router actually selected for this request. Since that value is identical across all chunks in a single response, you only need to read it once from the very first chunk rather than printing it redundantly on every iteration.
The content extraction uses .get(“content”, “”) rather than direct key access because the first and last chunks in a stream often carry an empty delta — the first signals the start of the response and the last signals completion before the [DONE] sentinel arrives. Without the .get() default, those empty deltas would raise a KeyError.
Running Three Test Queries
# Simple FAQ — expect a lightweight model
ask_support_bot("What are your support hours?")
# Billing question — expect a mid-tier model
ask_support_bot("I was charged twice for my subscription this month. Can you explain why?")
# Complex technical troubleshooting — expect a frontier model
ask_support_bot("My Kubernetes pod keeps crashing with OOMKilled errors after I scaled up my inference workload on GPU Droplets. How do I diagnose and fix this?")
These three queries are deliberately chosen to span the full complexity range your router should handle. Running them in sequence is the fastest way to verify that routing is working as intended.
A correct output looks like this:
============================================================
Customer Query: What are your support hours?
============================================================
Model selected by router: gemma-4-31B-it
Response:
I'm an AI assistant available 24/7 to help answer your questions and provide support. You can reach me anytime!
However, if you need to speak with a human support representative, typical business support hours are usually Monday through Friday during business hours (often 9 AM - 5 PM in your local time zone), though this can vary by company.
For specific support hours for the service you're asking about, I'd recommend:
- Checking the company's website footer or "Contact Us" page
- Looking for support hours in your account dashboard
- Checking any welcome emails you received
Is there something specific I can help you with right now?
============================================================
Customer Query: I was charged twice for my subscription this month. Can you explain why?
============================================================
Model selected by router: anthropic-claude-4.1-opus
Response:
I apologize for the double charge on your subscription. This is certainly not supposed to happen, and I understand your concern.
Here are the most common reasons this might occur:
**Possible causes:**
- A pending charge appearing alongside the actual charge (pending charges usually drop off within 3-5 business days)
- An overlapping billing cycle due to a recent plan change or upgrade
- A technical error in our billing system
**What you should do:**
1. Check if one charge shows as "pending" - if so, it should automatically disappear
2. Review your account for any recent subscription changes or upgrades
3. If both charges have fully processed, you're entitled to a refund
**To resolve this quickly:**
- I recommend contacting our billing team directly with your account details and bank statement showing both charges
- They can investigate your specific case and process an immediate refund if needed
- Most refunds appear within 5-7 business days
Would you like me to help you locate your account information or explain how to contact our billing team?
============================================================
Customer Query: My Kubernetes pod keeps crashing with OOMKilled errors after I scaled up my inference workload on GPU Droplets. How do I diagnose and fix this?
============================================================
Model selected by router: anthropic-claude-opus-4.7
Response:
# Diagnosing and Fixing OOMKilled Errors on GPU Droplets
OOMKilled means your pod exceeded its memory limit. Here's how to diagnose and resolve it:
## 1. Confirm the Cause
```bash
# Check pod status and exit code (137 = OOMKilled)
kubectl describe pod <pod-name>
# Look for "Last State: Terminated, Reason: OOMKilled"
kubectl get events --sort-by=.metadata.creationTimestamp
```
## 2. Identify Which Memory Is Exhausted
There are **two** memory types to consider on GPU workloads:
- **System (RAM)** – governed by Kubernetes `resources.limits.memory`
- **GPU VRAM** – not managed by K8s; check with `nvidia-smi`
```bash
# Check GPU memory inside the pod
kubectl exec -it <pod-name> -- nvidia-smi
# Check system memory usage
kubectl top pod <pod-name>
```
If `nvidia-smi` shows VRAM near 100%, you have a GPU memory issue (often surfaced as a CUDA OOM, but it can also cause the process to be killed).
## 3. Common Fixes
### A. Increase Memory Limits
```yaml
resources:
requests:
memory: "16Gi"
nvidia.com/gpu: 1
limits:
memory: "32Gi"
nvidia.com/gpu: 1
```
### B. Reduce Per-Pod Workload
- Lower **batch size** for inference
- Reduce **max sequence length** / **max tokens**
- Limit **concurrent requests** (e.g., `--max-num-seqs` in vLLM)
### C. Use Memory-Efficient Inference
- Enable **quantization** (INT8, FP8, AWQ, GPTQ)
- Use **paged attention** (vLLM, TGI)
- Enable **tensor parallelism** to split model across multiple GPUs
### D. Scale Horizontally Instead of Vertically
Scale by adding more pods (HPA) rather than packing more into one:
```bash
kubectl autoscale deployment <name> --min=2 --max=10 --cpu-percent=70
```
### E. Check for Memory Leaks
If memory grows over time, you may have a leak in your serving framework. Restart pods periodically with a livenessProbe or check framework version.
## 4. Right-Size Your GPU Droplet
If you've genuinely outgrown the node, consider a larger DigitalOcean GPU Droplet (e.g., moving from a single H100 to an 8x H100 node) for more VRAM and system RAM headroom.
## 5. Monitor Going Forward
Enable DigitalOcean Monitoring or deploy **Prometheus + DCGM Exporter** to track GPU/system memory trends and set alerts before pods crash.
---
Want help with a specific config? If you share your pod YAML and the model/framework you're running (e.g., vLLM, TGI, Triton), I can give more targeted advice.
The key thing to watch is the model name changing across different queries. If the query is as simple as FAQs, then the router hits a lightweight model, while a troubleshooting question, which is genuinely complex, gets routed to Claude Sonnet or a more complex model.
Test Router Performance
- Routers can be tested against another model or router directly from the Playground.
- The Playground opens in comparison mode, allowing side-by-side testing.
- Enter a prompt to compare:
- Response quality
- Cost difference
- End-to-end latency
- Selected model
- Matched task used by the router
- The router configuration can also be reviewed from the information icon.
Analyze Router Performance
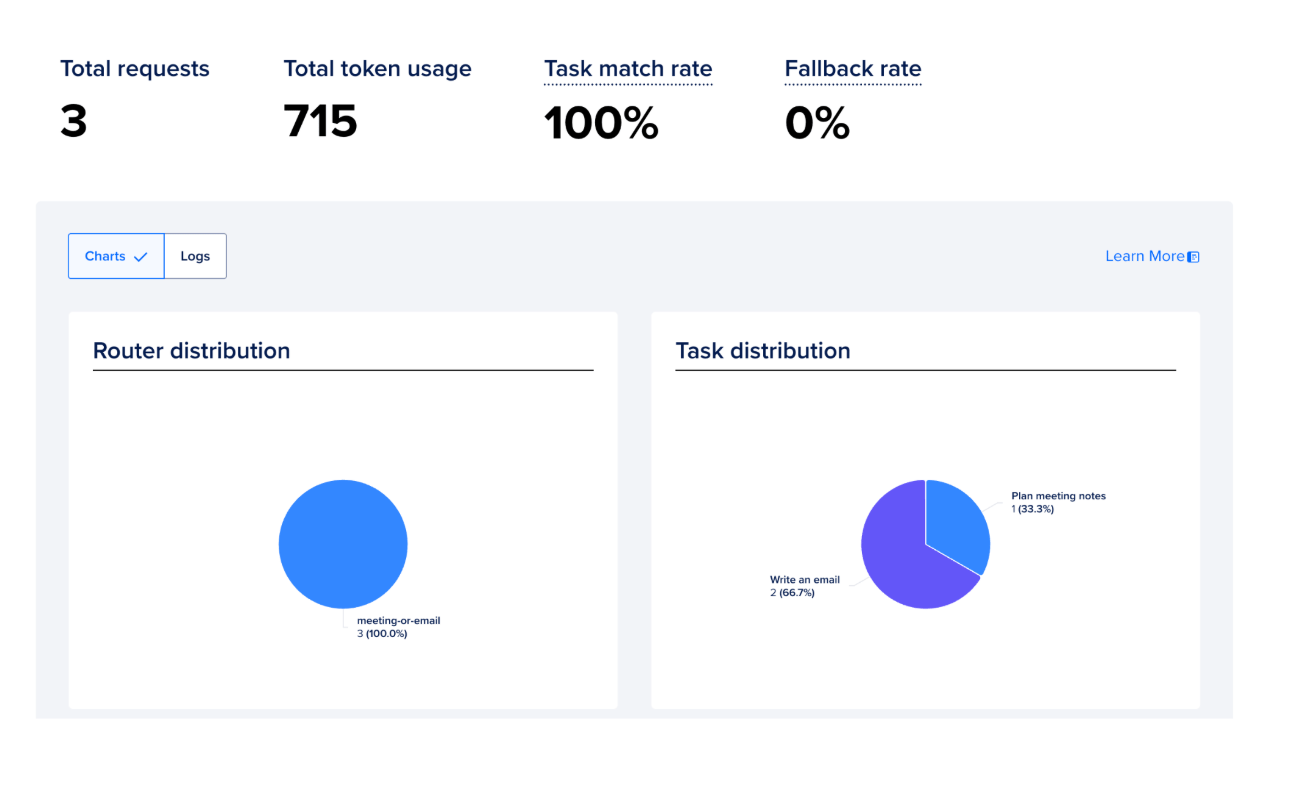
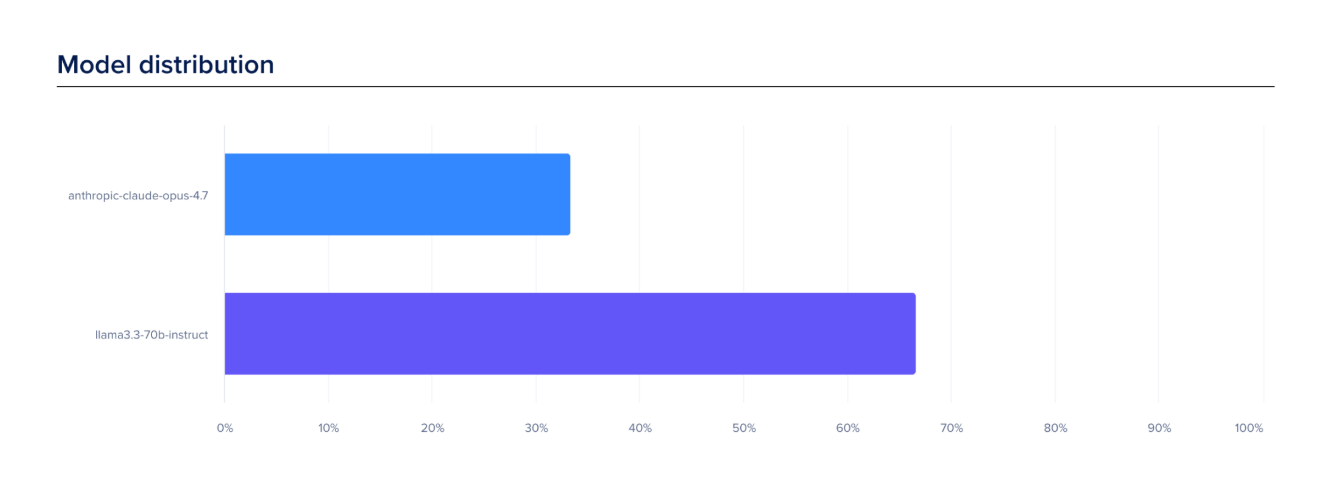
The Analyze tab provides aggregate metrics for all routers or individual routers, including:
- Total Requests — total number of requests processed
- Total Token Usage — combined input and output token usage
- Model Match Rate — percentage of requests successfully matched to configured router tasks
- Fallback Rate — percentage of requests routed to fallback models when no task matched
Test Router Accuracy
- In the Playground, select Router Evaluation to evaluate routing quality.
- Upload a dataset and run evaluation using LLM-as-a-Judge scoring.
Evaluation results include:
- Completeness — how thoroughly responses cover the prompt
- Correctness — accuracy and hallucination detection
- Tokens Used — total token consumption per request
- Latency — average and P95 response times
FAQ’s
What is a DigitalOcean Inference Router?
A DigitalOcean Inference Router is a routing layer that intelligently sends AI requests to the most suitable model based on factors such as query type, cost, latency, and model capability. It allows applications to work with multiple models through a single endpoint without manually managing model selection.
How does the router decide which model to use?
The router analyzes the incoming query and matches it against configured tasks. Each task contains a pool of eligible models and a selection policy such as:
- Lowest cost
- Lowest latency
- Best overall performance
The router then selects the most suitable model dynamically.
What are tasks in an inference router?
Tasks are categories of workloads or query types. For example:
- Customer support
- Summarization
- Coding assistance
- Technical troubleshooting
- Translation
- Reasoning
Each task can have different routing rules and model pools.
What is a model pool?
A model pool is a group of models assigned to a task. The router chooses the best model from the pool depending on routing policies and model availability.
Can custom routing rules be created?
Yes. Developers can create custom tasks, define their own model pools, and manually control model priority and fallback order.
What happens if a model fails or becomes unavailable?
The router automatically uses fallback models if the selected model:
- Times out
- Returns errors
- Becomes overloaded
- Hits rate limits
This ensures higher reliability and uninterrupted AI responses.
What is model affinity?
Model affinity keeps the same model assigned to a session or conversation. This improves:
- Response consistency
- Tool-calling stability
- KV cache reuse
- Latency
- Token cost efficiency
It is especially useful for AI agents and long-running conversations.
What is KV cache reuse?
KV caching allows models to reuse previously computed attention states when repeated conversation history is sent to the same model. This reduces recomputation, lowers latency, and decreases token processing costs.
Can routers be tested before deployment?
Yes. The Playground allows developers to compare routers against models or other routers by evaluating:
- Response quality
- Cost
- Latency
- Selected models
- Matched routing tasks
What are the practical use cases of inference routing?
Inference routing is useful for:
- AI support bots
- Multi-model AI assistants
- RAG systems
- AI agents
- Coding copilots
- Enterprise AI platforms
- Cost optimization pipelines
- High-scale inference systems
Conclusion
Building an AI-powered application doesn’t mean using the most powerful model for everything. It means using the right model for each task. When you treat every query the same, you’re not improving quality, you’re just increasing cost.
DigitalOcean’s Inference Router solves this with a simple idea: define your tasks once, set your model pools, and let the infrastructure make the routing decision automatically. No if/else logic in your code, no juggling multiple API keys, no redeployment every time you want to try a different model.
Inference routing is becoming an important part of modern AI infrastructure as applications move from prototypes to production-scale systems. Instead of relying on a single model for every request, routers help balance cost, speed, reliability, and model capability automatically.
Start simple. Pick two or three tasks, assign model pools, and run it against real traffic. Watch the model field in your responses to see the routing in action. Check your token spend in the Control Panel after a few days. With tools like DigitalOcean AI Platform, developers can simplify multi-model orchestration and focus more on building AI experiences rather than managing complex routing logic.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
