By Mark Drake
Manager, Developer Education

Introduction
Data is central to how many of today’s applications and websites function. Comments on a viral video, changing scores in a multiplayer game, and the items you left in a shopping cart on your favorite online store are all bits of information stored somewhere in a database.
This conceptual article serves as an introduction to numerous database topics. It provides a brief overview of what databases are in the context of cloud computing and highlights a few concepts central to their design and function. It also contains links to relevant conceptual and procedural tutorials throughout.
What are Databases?
Broadly speaking, a database is any logically modeled collection of information. A database does not necessarily have to be stored on a computer, and things like a stack of patient files in a hospital, a set of contacts in a rolodex, or file cabinet filled with old invoices all qualify as examples of databases.
In the context of websites and applications, when people refer to a “database” they’re often talking about a computer program that allows them to interact with their database. These programs, known more formally as a database management system (DBMS), are often installed on a virtual private server and accessed remotely.
Redis, MariaDB, and PostgreSQL are a few examples of open-source DBMSs, but there are many different ones available today. Different DBMSs usually have their own unique features and associated toolsets, but they generally fall into one of two categories: relational and non-relational databases.
Relational Databases
Since the 1970s, most DBMSs have been designed around the relational model. The most fundamental elements in the relational model are relations, which users and modern relational DBMSs (RDBMSs or relational databases) recognize as tables. A relation is a set of tuples, or rows in a table, with each tuple sharing a set of attributes, or columns:
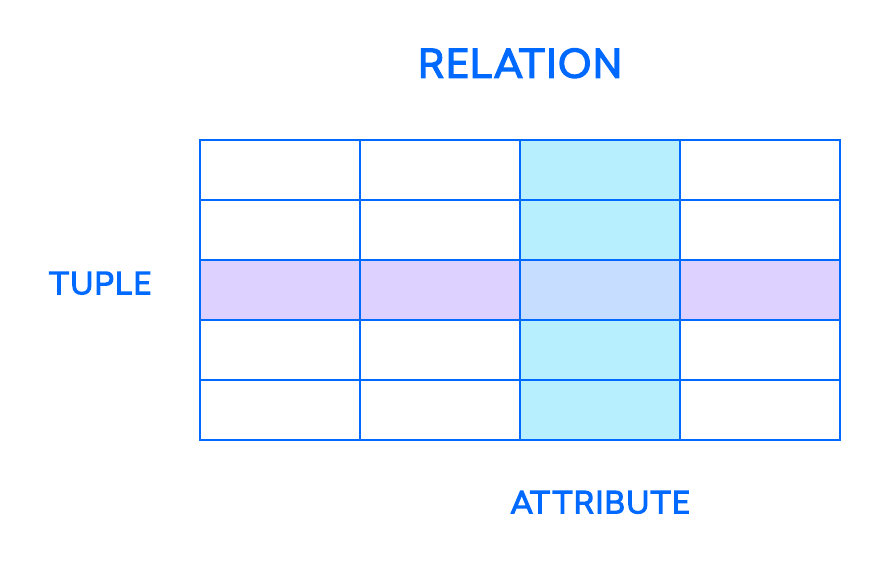
You can think of each tuple as a unique instance of whatever type of people, objects, events, or associations the table holds. These instances might be things like employees at a company, sales from an online business, or test results in a medical lab. For example, in a table that holds employee records of teachers at a school, the tuples might have attributes like name, subjects, start_date, and so on.
In the relational model, each table contains at least one column that can be used to uniquely identify each row, called a primary key. Building on the example of a table storing employee records of teachers at a school, the database administrator could create a primary key column named employee_ID whose values automatically increment. This would allow the DBMS to keep track of each record and return them on an ad hoc basis. In turn, it would mean that the records have no defined logical order, and users have the ability to return their data in whatever order or through whatever filters they wish.
If you have two tables that you’d like to associate with one another, one way you can do so is with a foreign key. A foreign key is essentially a copy of one table’s (the “parent” table) primary key inserted into a column in another table (the “child”). The following example highlights the relationship between two tables, one used to record information about employees at a company and another used to track the company’s sales. In this example, the primary key of the EMPLOYEES table is used as the foreign key of the SALES table:
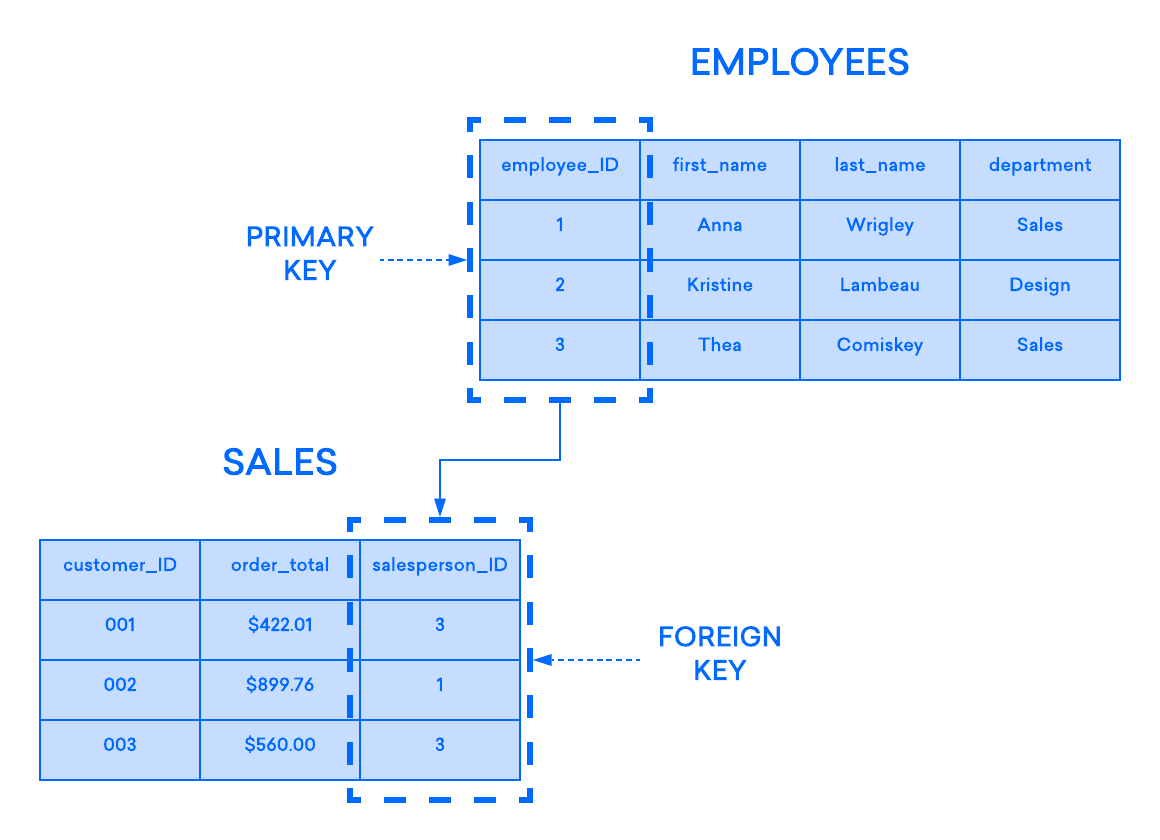
The relational model’s structural elements help to keep data stored in an organized way, but storing data is only useful if you can retrieve it. To retrieve information from an RDBMS, you can issue a query, or a structured request for a set of information. Most relational databases use a language called Structured Query Language — better known as SQL and informally pronounced like “sequel” — to manage and query data. SQL allows you to filter and manipulate query results with a variety of clauses, predicates, and expressions, giving you fine control over what data will appear in the result set.
There are many open-source RDBMSs available today, including the following:
Non-relational Databases
Today, most applications still use the relation model to store and organize data. However, the relation model cannot meet the needs of every application. For example, it can be difficult to scale relational databases horizontally, and though they’re ideal for storing structured data, they’re less useful for storing unstructured data.
These and other limitations of the relational model have led to the development of alternatives. Collectively, these database models are often referred to as non-relational databases. Because these alternative models typically don’t implement SQL for defining or querying data, they are also sometimes referred to as NoSQL databases. This also means that many NoSQL databases implement a unique syntax to insert and retrieve data.
It can be helpful to think of “NoSQL” and “non-relational” as broad umbrella terms, as there are many database models that are labeled as NoSQL, with significant differences between them. The remainder of this section highlights a few of the more commonly used non-relational database models:
Key-Value Databases
Key-value databases, also known as key-value stores, work by storing and managing associative arrays. An associative array, also known as a dictionary or hash table, consists of a collection of key-value pairs in which a key serves as a unique identifier to retrieve an associated value. Values can be anything from simple objects, like integers or strings, to more complex objects, like JSON structures.
Redis is an example of a popular, open-source key-value store.
Document-Oriented Databases
Document-oriented databases, or document stores, are NoSQL databases that store data in the form of documents. Document stores are a type of key-value store: each document has a unique identifier — its key — and the document itself serves as the value. The difference between these two models is that, in a key-value database, the data is treated as opaque and the database doesn’t know or care about the data held within it; it’s up to the application to understand what data is stored. In a document store, however, each document contains some kind of metadata that provides a degree of structure to the data. Document stores often come with an API or query language that allows users to retrieve documents based on the metadata they contain. They also allow for complex data structures, as you can nest documents within other documents.
MongoDB is a widely used document database. The documents you store in a MongoDB database are written in BSON, which is a binary form of JSON.
Columnar Databases
Columnar databases, sometimes called column-oriented databases, are database systems that store data in columns. This may seem similar to traditional relational databases, but rather than grouping columns together into tables, each column is stored in a separate file or region in the system’s storage. The data stored in a columnar database appears in record order, meaning that the first entry in one column is related to the first entry in other columns. This design allows queries to only read the columns they need, rather than having to read every row in a table and discard unneeded data after it’s been stored in memory.
Apache Cassandra is a widely used open-source column store.
Databases as part of an application
By itself, a database management system isn’t very useful. You can use a DBMS to query and interact with a database directly, but in most real-world contexts you’ll likely want to combine it with other tools since DBMS cannot serve or display content on its own. When done so, a database becomes an essential component of a larger application.
There are a number of popular open-source technology stacks that include a DBMS. Here are a few examples:
- LAMP stack: “LAMP” is an acronym made up of the technology that typically makes up this stack: the Linux operating system, the Apache web server, the MySQL database, and PHP for dynamic content processing. It is increasingly common to see pieces of the LAMP stack swapped in and out (e.g., PostgreSQL or SQLite in lieu of MySQL, Flask or Django in lieu of PHP, and Nginx in lieu of Apache). It is also common to see other L*MP options such as LEMP with E being for Nginx (pronounced engine-x)
- Elastic stack: Formerly known as the ELK Stack, the Elastic stack is built around Elastic search, a search engine that’s also described as a document-oriented database. This is often used for storing software output logs at scale.
These technology stacks are often deployed on the same server — an architecture pattern referred to as a monolithic architecture. In such cases, it is fairly trivial to connect the other stack components to a DBMS. Alternatively, you can set up a remote database by installing the DBMS on a remote server. Most DBMSs operate on a dedicated port that you can use to connect an application server to your remote database. For example, MySQL’s default port is 3306 and Redis’s is 6379. Using a remote database server like this can be a highly scalable solution compared to a monolithic application, as it allows you to scale your database separately from your application.
However, setting up a remote database like this increases the attack surface of your application, since it adds more potential entry points for unauthorized users. It also requires your data to be sent from the database server to the application server over a network connection, which means the data packets could be intercepted by malicious actors. To protect your data from sniffing attacks like this, many DBMSs allow you to encrypt your data. Encryption is the process of converting a piece of information from plaintext, the information’s original form, into ciphertext, an unreadable form that can only be read by a person or computer that has the right cipher to decrypt it. If a malicious actor were to intercept a piece of encrypted data, they wouldn’t be able to read it until they’re able to decrypt it.
Many DBMSs allow you to encrypt communications between your database server and whatever clients or applications need access to it by configuring it to require connections that use Transport Layer Security, also known as TLS. Like its predecessor, Secure Sockets Layer (SSL), TLS is a cryptographic protocol that uses certificate-based authentication to encrypt data as it’s transmitted over a network. Note that TLS only encrypts data as it moves over a network, otherwise known as data in-transit. Even if you’ve configured Mongo to require connections to be made with TLS, the static data stored on the database server, called data at rest, will still be unencrypted unless your DBMS offers a form of data at rest encryption.
Working with Databases
Most database management systems come installed with a command line tool that allows you to interact with the database installation. Examples include the mysql command line client for MySQL, psql for PostgreSQL, and the MongoDB Shell. There are also third-party command line clients available for many DBMSs. One such example is Redli, which serves as an alternative to Redis’s default redis-cli tool and comes with certain added features.
However, managing data through a command line interface may not be intuitive for every user, which is why there are graphical database administration tools available for many open-source DBMSs. Some, like phpMyAdmin or pgAdmin, are browser-based while others, like MySQL Workbench or MongoDB Compass, are meant to connect to a remote database from a local machine.
As an application continues to operate and grow, the data held within the database will require more and more storage, to the point where it could slow down the entire application. There are several common strategies for dealing with issues like this, the two most common of which are replication and sharding.
Replication is the practice of synchronizing data across multiple separate databases. When working with databases, it’s often useful to have multiple copies of your data. This provides redundancy in case one of the database servers fails and can improve a database’s availability and scalability, as well as reduce read latencies. Many DBMSs include replication as a built-in feature, including MongoDB and MySQL. Some like MySQL even provide multiple replication methods for greater flexibility.
Database sharding is the process of splitting up data records that would normally be held in the same table or collection and distributing them across multiple machines, known as shards. Sharding is especially useful in cases where you’re working with large amounts of data, as it allows you to scale your base horizontally by adding more machines that can function as new shards.
Conclusion
By reading this article, you should have a better understanding of what databases are and how you can use them. We encourage you to check out the rest of our databases content.
Additional resources
Tutorials
- How To Troubleshoot Issues in MySQL. This series serves as a troubleshooting resource and starting point as you diagnose your MySQL setup. It outlines some of the more common issues that MySQL users encounter and provides guidance for troubleshooting specific problems.
- How To Migrate a MySQL Database to PostgreSQL Using pgLoader. Migrating a database can be a difficult task, especially when you’re moving data from one DBMS to another. This tutorial highlights pgLoader, an open-source database migration tool, and outlines how to use it to migrate a MySQL database to PostgreSQL.
- How To Connect to a Managed Redis Instance over TLS with Stunnel and
redis-cli. Oftentimes, databases contain sensitive data. This tutorial outlines how to connect to a managed Redis database over a secure tunnel created with Stunnel. - How To Perform CRUD Operations in MongoDB. CRUD (Create, Read, Update, and Delete) operations are the four fundamental operations one expects a DBMS to perform. This tutorial outlines what CRUD operations are and how to perform them on a MongoDB database.
DigitalOcean Products
-
DigitalOcean offers a variety of Managed Databases, allowing you to provision and use a database server without the need to configure it, perform backups, or update it in the future. Currently, DigitalOcean offers Managed Databases for the following four DBMSs:
-
You can also find a variety of Database solutions on the DigitalOcean Marketplace. These allow you to launch a database server in just a few clicks, with options like MySQL, MongoDB, RethinkDB, and others.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Getting Started With Cloud Computing
This curriculum introduces open-source cloud computing to a general audience along with the skills necessary to deploy applications and websites securely to the cloud.
Browse Series: 39 tutorials
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
