By Mark Drake
Manager, Developer Education

Introduction
Database management systems (DBMS) are computer programs that allow users to interact with a database. A DBMS allows users to control access to a database, write data, run queries, and perform any other tasks related to database management.
In order to perform any of these tasks, though, the DBMS must have some kind of underlying model that defines how the data are organized. The relational model is one approach for organizing data that has found wide use in database software since it was first devised in the late 1960s, so much so that, as of this writing, four of the top five most popular DBMSs are relational.
This conceptual article outlines the history of the relational model, how relational databases organize data, and how they’re used today.
History of the Relational Model
Databases are logically modelled clusters of information, or data. Any collection of data is a database, regardless of how or where it is stored. Even a file cabinet containing payroll information is a database, as is a stack of hospital patient forms, or a company’s collection of customer information spread across multiple locations. Before storing and managing data with computers was common practice, physical databases like these were the only ones available to government and business organizations that needed to store information.
Around the middle of the 20th century, developments in computer science led to machines with more processing power, as well as greater local and external storage capacity. These advancements led computer scientists to start recognizing the potential these machines had for storing and managing ever larger amounts of data.
However, there weren’t any theories for how computers could organize data in meaningful, logical ways. It’s one thing to store unsorted data on a machine, but it’s much more complicated to design systems that allow you to add, retrieve, sort, and otherwise manage that data in consistent, practical ways. The need for a logical framework for storing and organizing data led to a number of proposals for how to harness computers for data management.
One early database model was the hierarchical model, in which data are organized in a tree-like structure, similar to modern-day filesystems. The following example shows how the layout of part of a hierarchical database used to categorize animals might look:
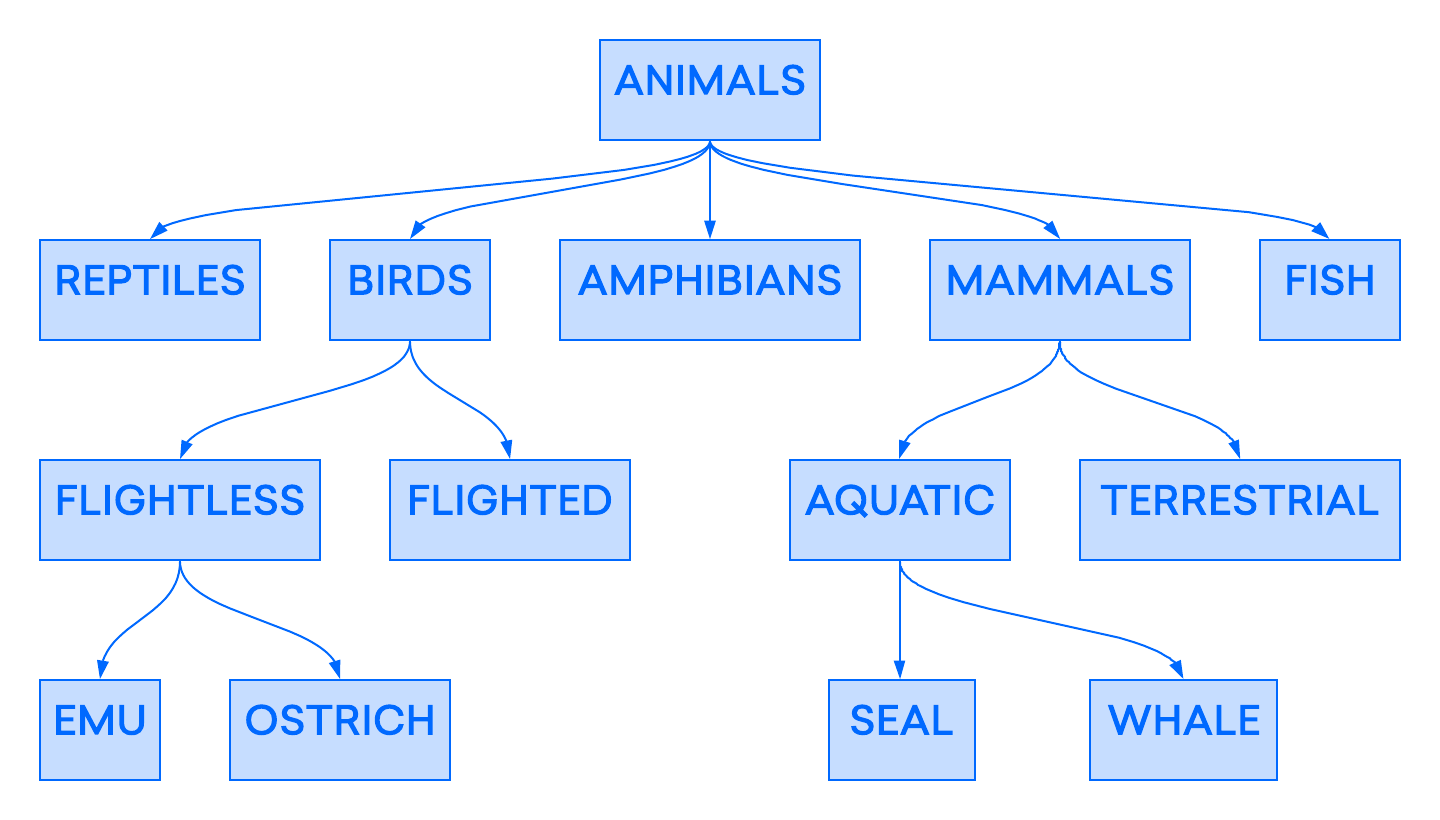
The hierarchical model was widely implemented in early database management systems, but it also proved to be somewhat inflexible. In this model, even though individual records can have multiple “children,” each record can only have one “parent” in the hierarchy. Because of this, these earlier hierarchical databases were limited to representing only “one-to-one” and “one-to-many” relationships. This lack of “many-to-many” relationships could lead to problems when you’re working with data points that you’d like to associate with more than one parent.
In the late 1960s, Edgar F. Codd, a computer scientist working at IBM, devised the relational model of database management. Codd’s relational model allowed individual records to be associated with more than one table, thereby enabling “many-to-many” relationships between data points in addition to “one-to-many” relationships. This provided more flexibility than other existing models when it came to designing database structures, and meant that relational database management systems (RDBMSs) could meet a much wider range of business needs.
Codd proposed a language for managing relational data, known as Alpha, which influenced the development of later database languages. Two of Codd’s colleagues at IBM, Donald Chamberlin and Raymond Boyce, created one such language inspired by Alpha. They called their language SEQUEL, short for Structured English Query Language, but because of an existing trademark they shortened the name of their language to SQL (referred to more formally as Structured Query Language).
Due to hardware constraints, early relational databases were still prohibitively slow, and it took some time before the technology became widespread. But by the mid-1980s, Codd’s relational model had been implemented in a number of commercial database management products from both IBM and its competitors. These vendors also followed IBM’s lead by developing and implementing their own dialects of SQL. By 1987, both the American National Standards Institute and the International Organization for Standardization had ratified and published standards for SQL, solidifying its status as the accepted language for managing RDBMSs.
The relational model’s wide use across multiple industries led to it becoming recognized as the standard model for data management. Even with the rise of various NoSQL databases in more recent years, relational databases remain the dominant tools for storing and organizing data.
How Relational Databases Organize Data
Now that you have a general understanding of the relational model’s history, let’s take a closer look at how the model organizes data.
The most fundamental elements in the relational model are relations, which users and modern RDBMSs recognize as tables. A relation is a set of tuples, or rows in a table, with each tuple sharing a set of attributes, or columns:
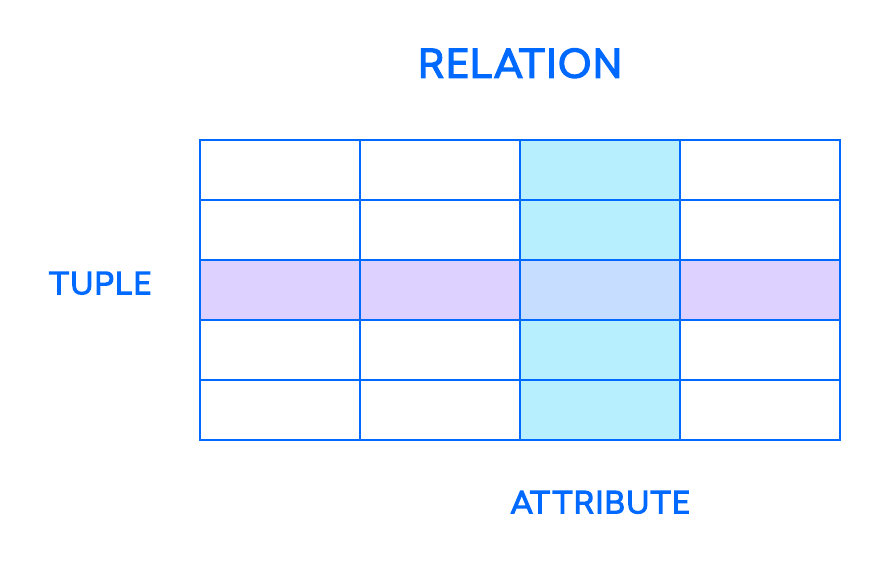
A column is the smallest organizational structure of a relational database, and represents the various facets that define the records in the table. Hence their more formal name, attributes. You can think of each tuple as a unique instance of whatever type of people, objects, events, or associations the table holds. These instances might be things like employees at a company, sales from an online business, or lab test results. For example, in a table that holds employee records of teachers at a school, the tuples might have attributes like name, subjects, start_date, and so on.
When creating columns, you specify a data type that dictates what kind of entries are allowed in that column. RDBMSs often implement their own unique data types, which may not be directly interchangeable with similar data types in other systems. Some common data types include dates, strings, integers, and Booleans.
In the relational model, each table contains at least one column that can be used to uniquely identify each row, called a primary key. This is important, because it means that users don’t need to know where their data is physically stored on a machine; instead, their DBMS can keep track of each record and return them on an ad hoc basis. In turn, this means that records have no defined logical order, and users have the ability to return their data in whatever order or through whatever filters they wish.
If you have two tables that you’d like to associate with one another, one way you can do so is with a foreign key. A foreign key is essentially a copy of one table’s (the “parent” table) primary key inserted into a column in another table (the “child”). The following example highlights the relationship between two tables, one used to record information about employees at a company and another used to track the company’s sales. In this example, the primary key of the EMPLOYEES table is used as the foreign key of the SALES table:
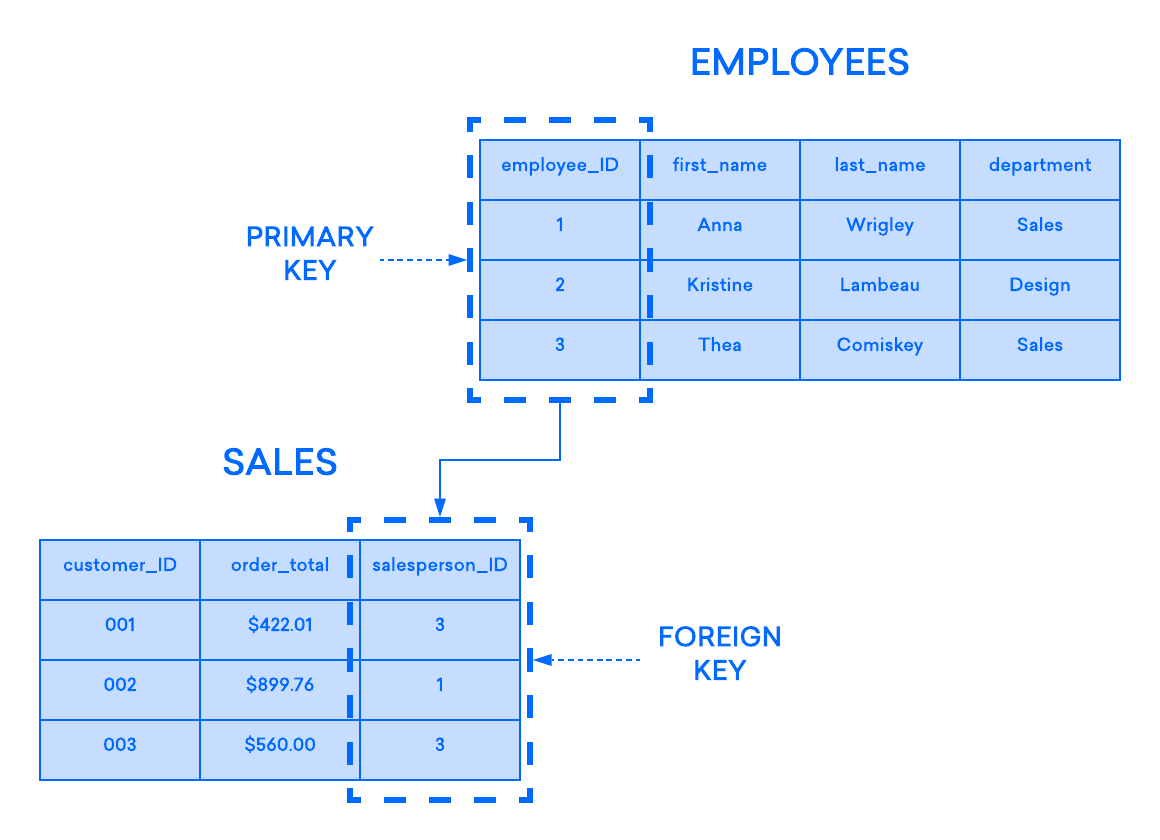
If you try to add a record to the child table and the value entered into the foreign key column doesn’t exist in the parent table’s primary key, the insertion statement will be invalid. This helps to maintain relationship-level integrity, as the rows in both tables will always be related correctly.
The relational model’s structural elements help to keep data stored in an organized way, but storing data is only useful if you can retrieve it. To retrieve information from an RDBMS, you can issue a query, or a structured request for a set of information. As mentioned previously, most relational databases use SQL to manage and query data. SQL allows you to filter and manipulate query results with a variety of clauses, predicates, and expressions, giving you fine control over what data will appear in the result set.
Advantages and Limitations of Relational Databases
With the underlying organizational structure of relational databases in mind, let’s consider some of their advantages and disadvantages.
Today, both SQL and the databases that implement it deviate from Codd’s relational model in several ways. For instance, Codd’s model dictates that each row in a table should be unique while, for reasons of practicality, most modern relational databases do allow for duplicate rows. There are some that don’t consider SQL databases to be true relational databases if they fail to adhere to each of Codd’s specifications for the relational model. In practical terms, though, any DBMS that uses SQL and at least somewhat adheres to the relational model is likely to be referred to as a relational database management system.
Although relational databases quickly grew in popularity, a few of the relational model’s shortcomings started to become apparent as data became more valuable and businesses began storing more of it. For one thing, it can be difficult to scale a relational database horizontally. Horizontal scaling, or scaling out, is the practice of adding more machines to an existing stack in order to spread out the load and allow for more traffic and faster processing. This is often contrasted with vertical scaling which involves upgrading the hardware of an existing server, usually by adding more RAM or CPU.
The reason it’s difficult to scale a relational database horizontally has to do with the fact that the relational model is designed to ensure consistency, meaning clients querying the same database will always retrieve the same data. If you were to scale a relational database horizontally across multiple machines, it becomes difficult to ensure consistency since clients may write data to one node but not the others. There would likely be a delay between the initial write and the time when the other nodes are updated to reflect the changes, resulting in inconsistencies between them.
Another limitation presented by RDBMSs is that the relational model was designed to manage structured data, or data that aligns with a predefined data type or is at least organized in some predetermined way, making it easily sortable and searchable. With the spread of personal computing and the rise of the internet in the early 1990s, however, unstructured data — such as email messages, photos, videos, etc. — became more common.
None of this is to say that relational databases aren’t useful. Quite the contrary, the relational model is still the dominant framework for data management after over 40 years. Their prevalence and longevity mean that relational databases are a mature technology, which is itself one of their major advantages. There are many applications designed to work with the relational model, as well as many career database administrators who are experts when it comes to relational databases. There’s also a wide array of resources available in print and online for those looking to get started with relational databases.
Another advantage of relational databases is that almost every RDBMS supports transactions. A transaction consists of one or more individual SQL statements performed in sequence as a single unit of work. Transactions present an all-or-nothing approach, meaning that every SQL statement in the transaction must be valid; otherwise, the entire transaction will fail. This is very helpful for ensuring data integrity when making changes to multiple rows or tables.
Lastly, relational databases are extremely flexible. They’ve been used to build a wide variety of different applications, and continue working efficiently even with very large amounts of data. SQL is also extremely powerful, allowing you to add and change data on the fly, as well as alter the structure of database schemas and tables without impacting existing data.
Conclusion
Thanks to their flexibility and design for data integrity, relational databases are still the primary way data are managed and stored more than fifty years after they were first conceived of. Even with the rise of various NoSQL databases in recent years, understanding the relational model and how to work with RDBMSs are key for anyone who wants to build applications that harness the power of data.
To learn more about a few popular open-source RDBMSs, we encourage you to check out our comparison of various open-source relational SQL databases. If you’re interested in learning more about databases generally, we encourage you to check out our complete library of database-related content.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: How To Use SQL
Series Description
Structured Query Language — commonly known as SQL — is a language used to define, control, manipulate, and query data held in a relational database. SQL has been widely adopted since it was first developed in the 1970s, and today it’s the predominant language used to manage relational database management systems.
Ideal for managing structured data (data that can fit neatly into an existing data model), SQL is an essential tool for developers and system administrators in a wide variety of contexts. Also, because of its maturity and prevalence, candidates with SQL experience are highly sought after for jobs across a number of industries.
This series is intended to help you get started with using SQL. It includes a mix of conceptual articles and tutorials which provide introductions to various SQL concepts and practices. You can also use the entries in this series for reference while you continue to hone your skills with SQL.
Note: Please be aware that the tutorials in this series use MySQL in examples, but many RDBMSs use their own unique implementations of SQL. Although the commands outlined in this tutorial will work on most RDBMSs, the exact syntax or output may differ if you test them on a system other than MySQL.
Browse Series: 27 tutorials
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Thanks for the clear explanation! I’m curious—how do you decide when to use a relational database over a NoSQL database, especially in modern web applications with large, unstructured data?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
