Building the Next Generation of DigitalOcean Networking
By Luca Salvatore
- Published:
- 3 min read
On April 15th, we opened our newest datacenter in Frankfurt. The blog post announcing FRA1 mentioned that the new datacenter was built using 40G networking and faster SSDs. What that blog didn’t mention was that the entire network was actually redesigned from the ground up to allow us to grow and scale to some pretty impressive numbers. On top of that, we have also started retrofitting some of our older locations with this new design, which includes 40G networking and newer, faster hypervisors.
In this blog, we’ll go into more detail about how we’ve been upgrading live DCs to the new architecture, and also take a look into how we are building out future datacenters.
Frankfurt’s Design
First, let’s look at the at the new design that we used in Frankfurt. It is based on the widely used Clos topology which utilizes spine and leaf switches to build a highly scalable and redundant network. In this case, leaf switches are top of rack (TOR) switches, and spine switches act as an aggregation layer before heading into the core of the network.
Here’s how it all looks:
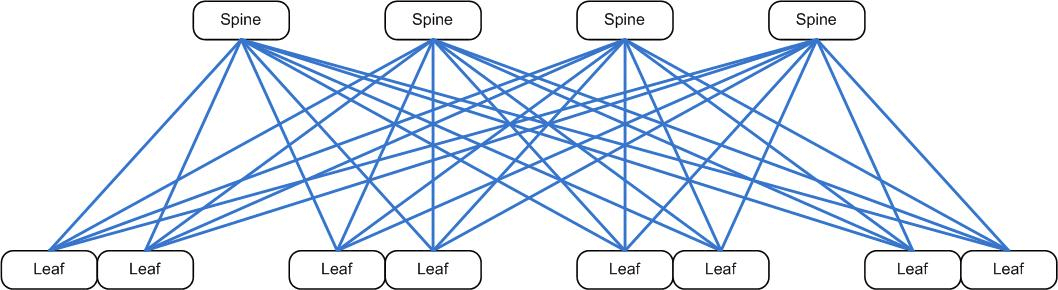
The leaf switches in this diagram represent TOR switches. Each hypervisor in the rack has a 40G connection to both leaf switches. From there, every leaf switch connects to every spine (again, with 40G connections). This allows for huge amounts of bandwidth and provides a high level of redundancy.
Scaling the Network
The diagram above only shows 4 pairs of leaf switches, which means 4 racks in this case. In reality, the number of racks each pod supports is limited to the number of ports in the spine. Each spine switch can have a maximum of 32 40G ports. We reserve some uplinks for the connections to the cores, so the number we work with is 12 racks per pod, i.e., 24 ports per spine. Once the spine is full, we scale out horizontally.
This diagram shows another pod added, along with the connections up to the core:
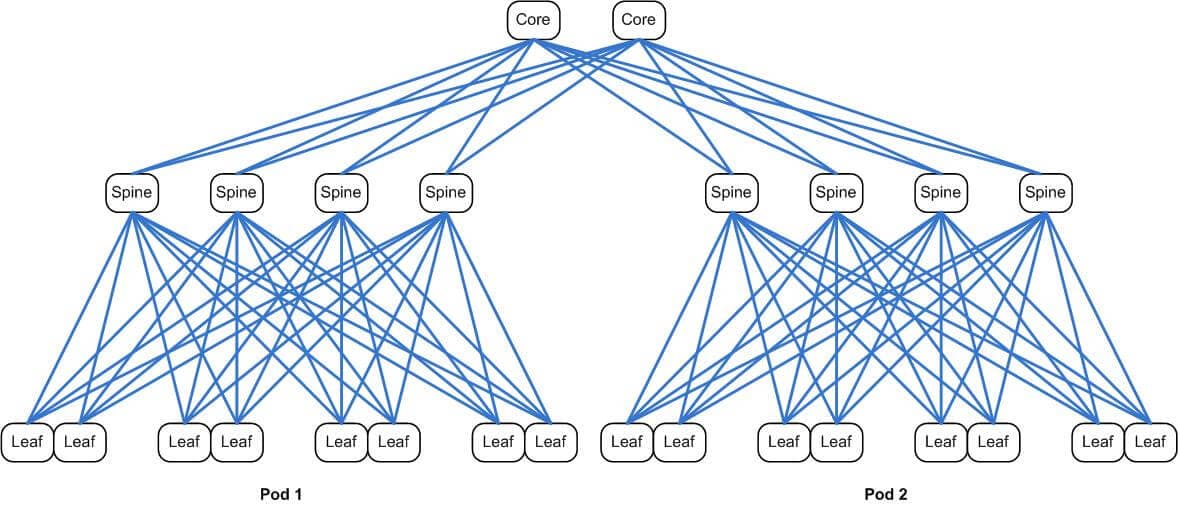
Scaling the network out in this manner presents an interesting problem. All switches have limits on the amount of information they can hold. These are things like MAC addresses, ARPs entries, and routing information. In the core of our network, we are mainly concerned with the number of ARP entries that the core switches can store. The maximum number on the ARPs we support in the core is 256,000. While this may seem like a big number (and it is), only the biggest switches can support ARP tables that size.
Using Zones
The solution to this problem is to split the network into zones. Where each pod has its own set of spine switches, each zone has its own set of core switches. Expanding on the diagram above, we can now have a network which looks like the diagram below, which also includes edge routers to show how two (or more) zones would connect to each other.
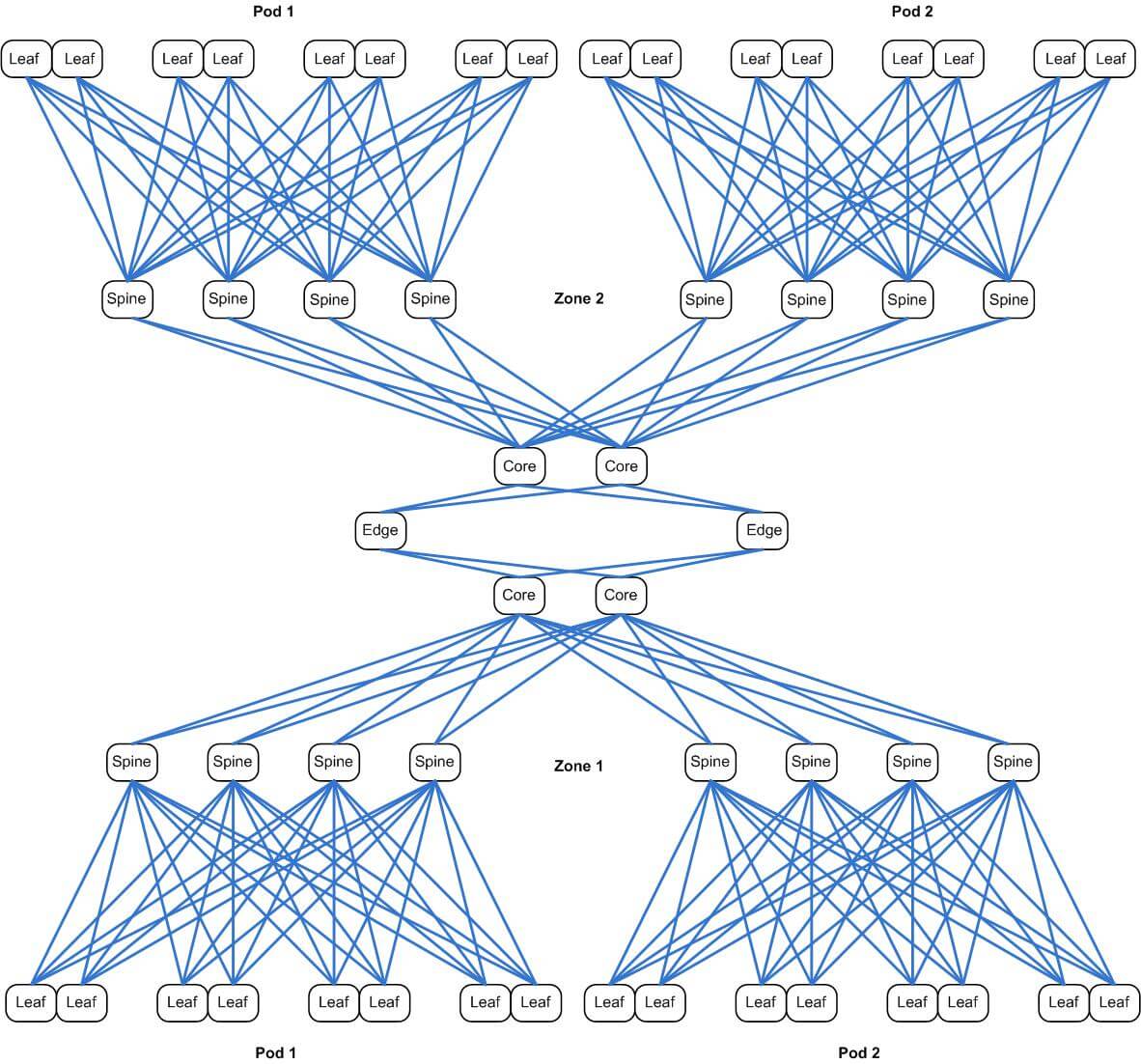
With this design, we are now able to scale out the network horizontally. The limiting factor becomes the availability of ports on the edge routers. Because that count is quite large, this design will last us for some time to come. Each different level of the network is connected using 40G interfaces, including the hypervisors. In most cases, these are configured using aggregation (802.3ad), so the bandwidth could be 80G or even 160G at some points.
Current and Future DCs
Using this design, it’s very easy to retrofit our existing locations. We simply build out the network in new racks, and when it’s all working, we connect the new cores to the edge routers, make some changes in our backend code, and the new zone is live!
This new 40G design is what we will be using in all future DCs, and has already been deployed in FRA1, NYC1, and NYC3. We will also be adding this design into two more locations in the next few months. With this type of architecture, the DigitalOcean network will be able to continue to scale and serve our customers for many years to come.
About the author
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read