Image and audio models from fal now available on DigitalOcean
By Grace Morgan
- Updated:
- 4 min read
We’re excited to announce the launch of four multimodal AI models from fal on the DigitalOcean Gradient™ AI Platform, now available in public preview through Serverless Inference. These models allow you to generate images and audio directly via API, without worrying about infrastructure, scaling, or vendor management. With this release, building AI-powered applications that include visual and audio content is easier than ever.
Explore the new models
The fal models, now in public preview, cover a variety of modalities, enabling you to experiment, prototype, and deploy multimodal AI features quickly:
Image generation:
-
Stable Diffusion XL fast (
fal-ai/fast-sdxl) – High-resolution image generation -
FLUX.1 (schnell) (
fal-ai/flux/schnell) – Fast image generation for quick prototyping
Audio generation:
-
Stable Audio (
fal-ai/stable-audio-25/text-to-audio) – Convert text into natural-sounding audio -
ElevenLabs TTS Multilingual v2 9 (
fal-ai/elevenlabs/tts/multilingual-v2) – Multilingual text-to-speech
These models are available via Serverless Inference, letting you generate images and audio through the same simple API-driven workflow you already use on Gradient AI Platform.
Try it out
You can start using these models through the Serverless Inference API (https://inference.do-ai.run) after opting in to the public preview in the DigitalOcean console. Here’s a quick look at how to interact with them:
First, opt in to the public preview to access the fal models on the Gradient AI Platform. Once opting in, it should take about 10 to 15 minutes for your access to be granted.
Example: Generate an Image
export MODEL_ACCESS_KEY="YOUR_KEY"
curl -sS -X POST 'https://inference.do-ai.run/v1/async-invoke' \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
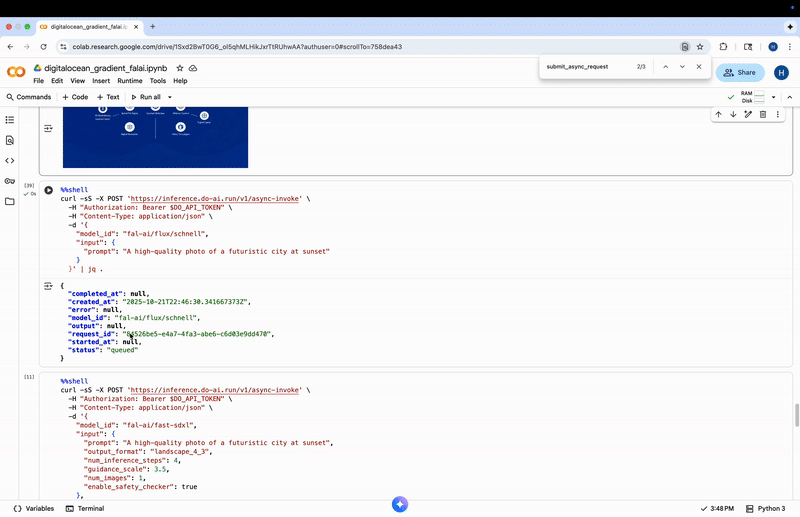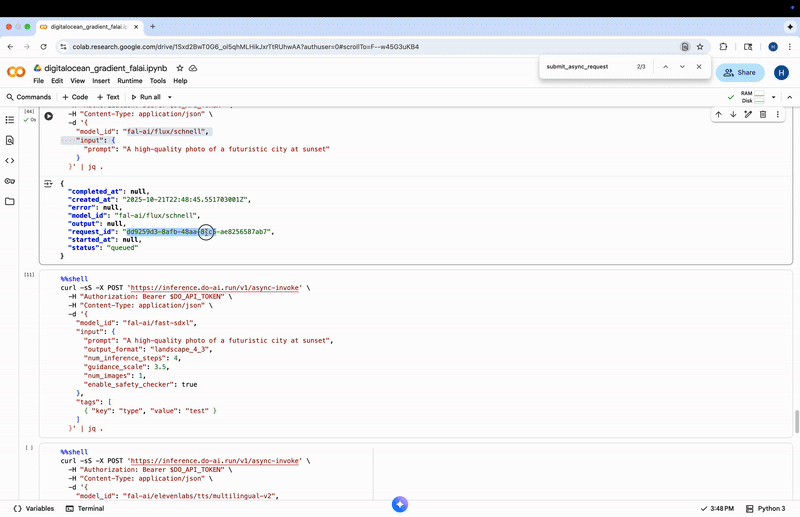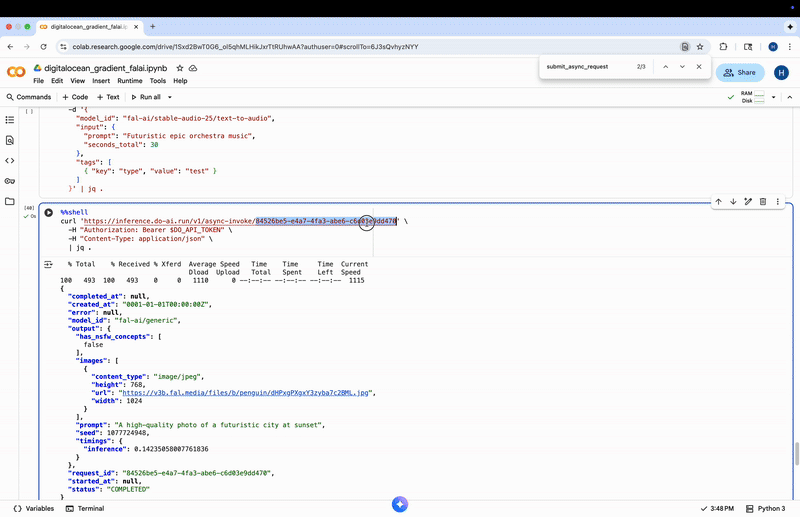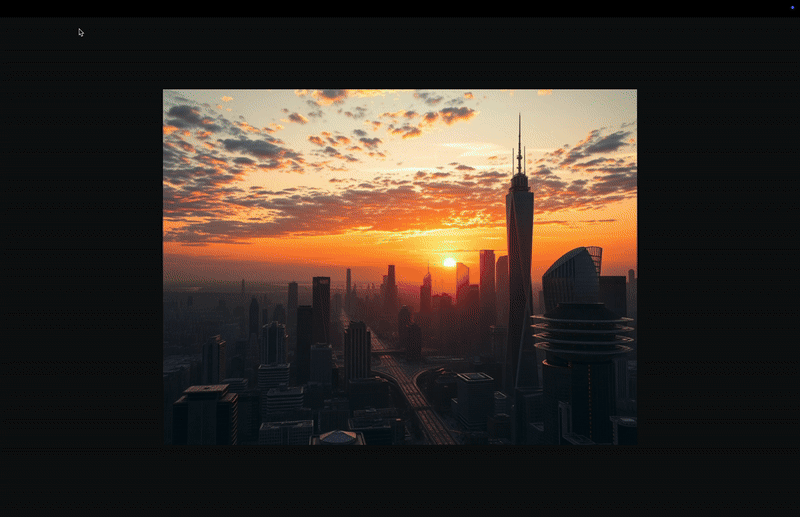
"model_id": "fal-ai/flux/schnell",
"input": { "prompt": "A high-quality photo of a futuristic city at sunset" }
}'
Example: Generate an Image with Customized Parameters
export MODEL_ACCESS_KEY="YOUR_KEY"
curl -sS -X POST 'https://inference.do-ai.run/v1/async-invoke' \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model_id": "fal-ai/fast-sdxl",
"input": {
"prompt": "A high-quality photo of a futuristic city at sunset",
"output_format": "landscape_4_3",
"num_inference_steps": 4,
"guidance_scale": 3.5,
"num_images": 1,
"enable_safety_checker": true
},
"tags": [
{ "key": "type", "value": "test" }
]
}'
Example: Generate Sound
export MODEL_ACCESS_KEY="YOUR_KEY"
curl -sS -X POST 'https://inference.do-ai.run/v1/async-invoke' \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model_id": "fal-ai/stable-audio-25/text-to-audio",
"input": {
"prompt": "Futuristic epic song",
"seconds_total": 60
},
"tags": [
{ "key": "type", "value": "test" }
]
}'
Example: Text to Speech (TTS)
export MODEL_ACCESS_KEY="YOUR_KEY"
curl -sS -X POST 'https://inference.do-ai.run/v1/async-invoke' \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model_id": "fal-ai/elevenlabs/tts/multilingual-v2",
"input": {
"text": "Hello, this is a text to speech example using Digital Ocean multilingual voice."
},
"tags": [
{ "key": "type", "value": "test" }
]
}'
Check the request status
These requests start the job and return a request_id, which you can use to check when your image is ready. Because Serverless Inference uses an asynchronous API, you’ll need to poll the request until it completes.
The /status endpoint is lightweight, so you can query it frequently to check progress. Once the job shows COMPLETE, use the /async-invoke/{request_id} endpoint to fetch the full generated result.
curl -sS -X GET "https://inference.do-ai.run/v1/async-invoke/{request_id}/status" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY"
Keep polling this endpoint until the response shows:
{ "status": "COMPLETE" }
Retrieve the final result
Once the job is complete, you can get the full response (which includes your generated image) using:
curl -sS -X GET "https://inference.do-ai.run/v1/async-invoke/{request_id}" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY"
The returned JSON includes a URL to the generated audio file, which you can download or play directly in your browser or app.
curl -O "{url}"
Bring your ideas to life with fal on DigitalOcean
With these four new multimodal models in public preview, you can now build richer AI-powered experiences, generating images and audio without managing infrastructure.
Get started today by exploring the Serverless Inference API and integrating these powerful fal models into your applications. For more resources, check out our Gradient™ AI SDK or watch our new tutorial below!
This launch marks an expansion of DigitalOcean’s partnership with fal, bringing high-performance image and voice generation models to developers through the Gradient AI Platform. Learn more about the collaboration in the official press release.
About the author
Related Articles

Upcoming GPU Pricing Updates
- July 21, 2026
- 2 min read
Scale Faster with Managed Weaviate: Now in Public Preview on DigitalOcean
- July 9, 2026
- 4 min read

DigitalOcean Evaluations: Production Model and Router Testing for the Inference Stack
- July 1, 2026
- 3 min read