From 15,000 database connections to under 100: DigitalOcean's tale of tech debt
By Sunny Beatteay
- Published:
- 7 min read
A new hire recently asked me over lunch, “What does DigitalOcean’s tech debt look like?”
I could not help but smile when I heard the question. Software engineers asking about a company’s tech debt is the equivalent of asking about a credit score. It’s their way of gauging a company’s questionable past and what baggage they’re carrying. And DigitalOcean is no stranger to technical baggage.
As a cloud provider that manages our own servers and hardware, we have faced complications that many other startups have not encountered in this new era of cloud computing. These tough situations ultimately led to tradeoffs we had to make early in our existence. And as any quickly growing company knows, the technical decisions you make early on tend to catch up with you later.
Staring at the new hire from across the table, I took a deep breath and began. “Let me tell you about the time we had 15,000 direct connections to our database….”

The story I told our new recruit is the story of DigitalOcean’s largest technical rearchitecture to date. It was a companywide effort that extended over multiple years and taught us many lessons. I hope that telling it will be helpful for future DigitalOcean developers – or any developers who find themselves in a tricky tech-debt conundrum.
Where it all started
DigitalOcean has been obsessed with simplicity from its inception. It’s one of our core values: Strive for simple and elegant solutions. This applies not only to our products, but to our technical decisions as well. Nowhere is that more visible than in our initial system design.
Like GitHub, Shopify, and Airbnb, DigitalOcean began as a Rails application in 2011. The Rails application, internally known as Cloud, managed all user interactions in both the UI and public API. Aiding the Rails service were two Perl services: Scheduler and DOBE (DigitalOcean BackEnd). Scheduler scheduled and assigned Droplets to hypervisors, while DOBE was in charge of creating the actual Droplet virtual machines. While the Cloud and Scheduler ran as stand-alone services, DOBE ran on every server in the fleet.
Neither Cloud, Scheduler, nor DOBE talked directly to one another. They communicated via a MySQL database. This database served two roles: storing data and brokering communication. All three services used a single database table as a message queue to relay information.
Whenever a user created a new Droplet, Cloud inserted a new event record into the queue. Scheduler continuously polled the database every second for new Droplet events and scheduled their creation on an available hypervisor. Finally, each DOBE instance would wait for new scheduled Droplets to be created and fulfilled the task. In order for these servers to detect any new changes, they would each need to poll the database for new records in the table.
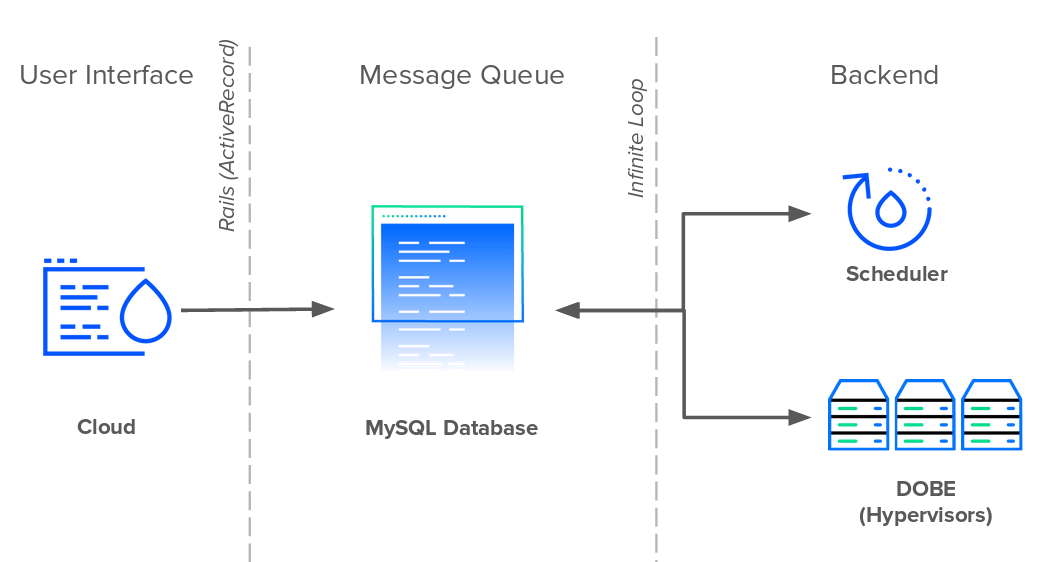
While infinite loops and giving each server a direct connection to the database may have been rudimentary in terms of system design, it was simple and it worked – especially for a short-staffed technical team facing tight deadlines and a rapidly increasing user base.
For four years, the database message queue formed the backbone of DigitalOcean’s technology stack. During this period, we adopted a microservice architecture, replaced HTTPS with gRPC for internal traffic, and ousted Perl in favor of Golang for the backend services. However, all roads still led to that MySQL database.
It’s important to note that simply because something is “legacy” does not mean it is dysfunctional and should be replaced. Bloomberg and IBM have legacy services written in Fortran and COBOL that generate more revenue than entire companies. On the other hand, every system has a scaling limit. And we were about to hit ours.
From 2012 to 2016, DigitalOcean’s user traffic grew over 10,000%. We added more products to our catalog and services to our infrastructure. This increased the ingress of events on the database message queue. More demand for Droplets meant that Scheduler was working overtime to assign them all to servers. And unfortunately for Scheduler, the number of available servers was not static.
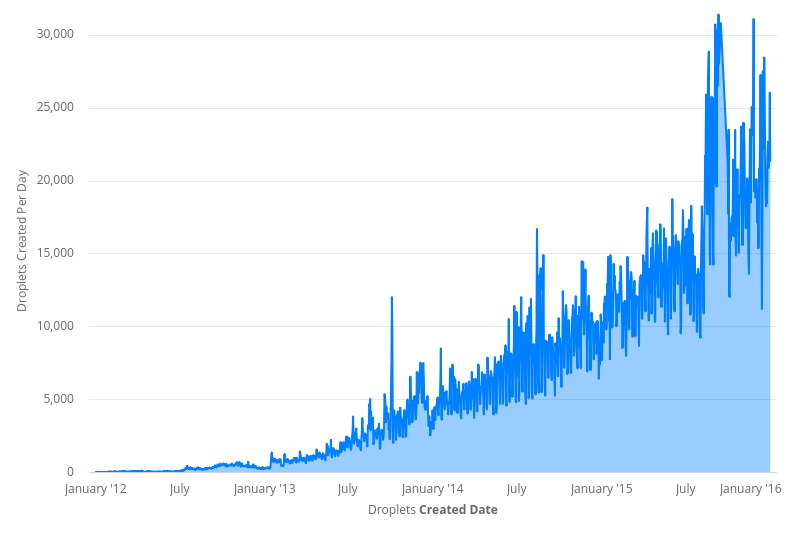
To keep up with the increased Droplet demand, we were adding more and more servers to handle the traffic. Each new hypervisor meant another persistent connection to the database. By the start of 2016, the database had over 15,000 direct connections, each one querying for new events every one to five seconds. If that was not bad enough, the SQL query that each hypervisor used to fetch new Droplet events had also grown in complexity. It had become a colossus over 150 lines long and JOINed across 18 tables. It was as impressive as it was precarious and difficult to maintain.
Unsurprisingly, it was around this period that the cracks began to show. A single point of failure with thousands of dependencies grabbling over shared resources, inevitably led to periods of chaos. Table locks and query backlogs led to outages and performance drops.
And due to the tight coupling in the system, there was not a clear or simple solution to resolving the issues. Cloud, Scheduler, and DOBE all served as bottlenecks. Patching only one or two components would only shift the load to the remaining bottlenecks. So after a lot of deliberation, the engineering staff came up with a three-pronged plan for rectifying the situation:
- Decrease the number of direct connections on the database
- Refactor Scheduler’s ranking algorithm to improve availability
- Absolve the database of its message queue responsibilities
The refactoring begins
To tackle the database dependencies, DigitalOcean engineers created Event Router. Event Router served as a regional proxy that polled the database on behalf of each DOBE instance in each data center. Instead of thousands of servers each querying the database, there would only be a handful of proxies doing the querying. Each Event Router proxy would fetch all the active events in a specific region and delegate each event to the appropriate hypervisor. Event Router also broke up the mammoth polling query into ones that were smaller and easier to maintain.
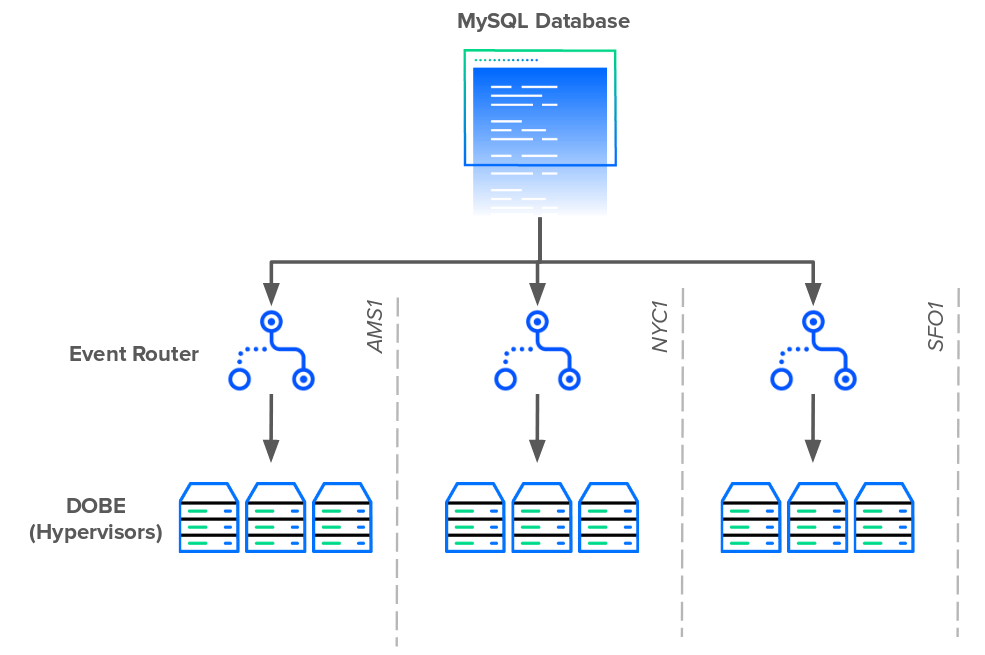
When Event Router went live, it slashed the number of database connections from over 15,000 to less than 100.
Next, the engineers set their sights on the next target: Scheduler. As mentioned before, Scheduler was a Perl script that determined which hypervisor would host a created Droplet. It did this by using a series of queries to rank and sort the servers. Whenever a user created a Droplet, Scheduler updated the table row with the best machine.
While it sounds simple enough, Scheduler had a few flaws. Its logic was complex and challenging to work with. It was single threaded and its performance suffered during peak traffic. Finally, there was only one instance of Scheduler – and it had to serve the entire fleet. It was an unavoidable bottleneck. To tackle these issues, the engineering team created Scheduler V2.
The updated Scheduler completely revamped the ranking system. Instead of querying the database for the server metrics, it aggregated them from the hypervisors and stored it in its own database. Additionally, the Scheduler team used concurrency and replication to make their new service performant under load.
Event Router and Scheduler v2 were all great achievements that addressed many of the architectural weaknesses. Even so, there was a glaring obstacle. The centralized MySQL message queue was still in use – bustling even – by early 2017. It was handling up to 400,000 new records per day, and 20 updates per second.
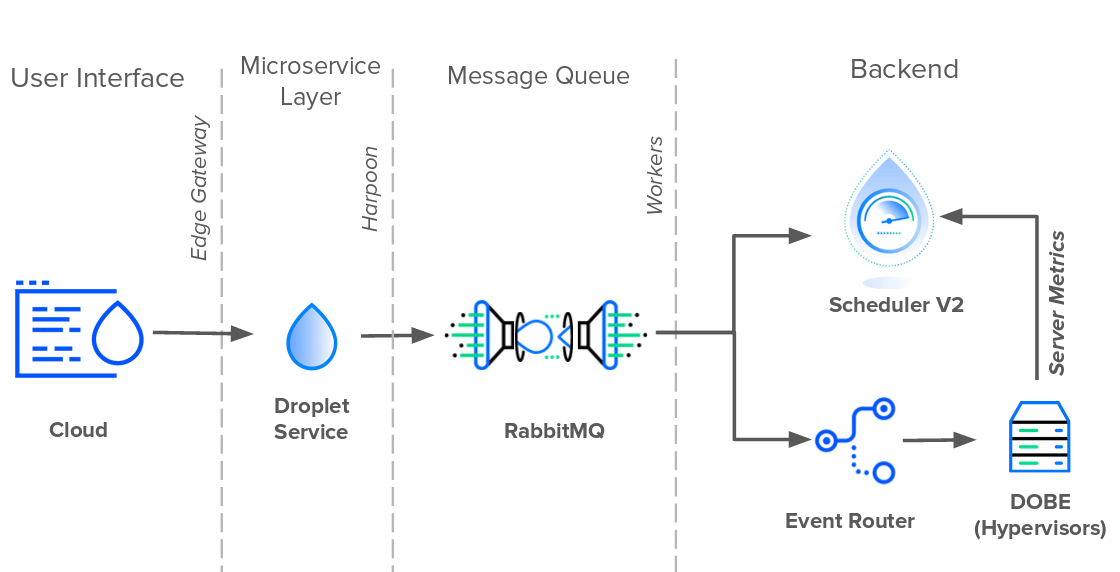
Unfortunately, removing the database’s message queue was not an easy feat. The first step was preventing services from having direct access to it. The database needed an abstraction layer. And it needed an API to aggregate requests and perform queries on its behalf. If any service wanted to create a new event, it would need to do so through the API. And so, Harpoon was born.
However, building the interface for the Event queue was the easy part. Getting buy-in from the other teams proved more difficult. Integrating with Harpoon meant teams would have to give up their database access, rewrite portions of their codebase, and ultimately change how they had always done things. That wasn’t an easy sell.
Team by team and service by service, the Harpoon engineers were able to migrate the entire codebase onto their new platform. It took the better part of a year, but by the end of 2017, Harpoon became the sole publisher to the database message queue.
Now the real work began. Having complete control of the event system meant that Harpoon had the freedom to reinvent the Droplet workflow.
Harpoon’s first task was to extract the message queue responsibilities from the database into itself. To do this, Harpoon created an internal messaging queue of its own that was made up of RabbitMQ and asynchronous workers. As Harpoon pushed new events to the queue on one side, the workers pulled them from the other. And since RabbitMQ replaced the database’s queue, the workers were free to communicate directly with Scheduler and Event Router. Thus, instead of Scheduler V2 and Event Router polling for new changes from the database, Harpoon pushed the updates to them directly. As of this writing in 2019, this is where the Droplet event architecture stands.
Onward
In the past seven years, DigitalOcean has grown from garage-band roots into the established cloud provider it is today. Like other transitioning tech companies, DigitalOcean deals with legacy code and tech debt on a regular basis. Whether breaking apart monoliths, creating multiregional services, or removing single points of failure, we DigitalOcean engineers are always working to craft elegant and simple solutions.
I hope this story of how our infrastructure scaled with our user base has been interesting and illuminating. I’d love to hear your thoughts in the comments below!
About the author
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read