Dolphin: Mastering the Art of Automated Droplet Movement
By Jes Olson, Lucy Berman, and Roman Gonzalez
- Published:
- 10 min read
Running shared cloud infrastructure is tricky. One challenge that we have at DigitalOcean is striking the right balance between packing as many Droplets as possible onto our servers, and making sure those Droplets remain performant and available. In the process of placing Droplets, it’s common for individual Droplets to consume more resources than we anticipate. Placing Droplets is like stacking Jenga blocks, only the Jenga blocks are randomly sized and behave erratically.
DigitalOcean’s Fleet Optimization Engineering team is responsible for fitting as many Droplets as possible on our servers without degrading Droplet performance. In other words, we carefully stack jenga blocks so that our towers don’t fall over.
What if you want to move one of the Jenga blocks without knocking over the entire tower? That’s where the story of Dolphin begins.
It started out with a ping
It was a typical day at DigitalOcean. Our servers were serving. Our Droplets were…Dropleting. Business as usual. Lucy Berman, an engineer on the Fleet Optimization Engineering team, received a curious ping from one of her colleagues on the Storage team:
“Hey Lucy, how do I ensure that two of my Droplets in the same region don’t wind up on the same server? I’m sure this question has a very simple answer and won’t result in a complex multi-year project. Thanks!” -Lucy’s coworker, probably
Lucy asked the rest of her team about this, and there wasn’t a clear answer. In our world, one region equals one datacenter, which meant that two Droplets placed in the same region had the potential to wind up in the same rack, or worse, on the same server.
The initial idea of Dolphin was meant to solve that exact use-case: an internal anti-affinity service. Think of anti-affinity as a means of making Droplets allergic to one another based on specified criteria. For example, Dolphin might notice that three Elasticsearch leader Droplets have been placed on the same server, and proceed to distribute two of the leaders to other servers within the datacenter, eliminating the risk of a server failure triggering an outage.
The idea of automatically distributing Droplets to make our systems more reliable served as the foundation of the Dolphin we know and love today.
Baby Dolphin 👶🐬
Internally, we tend to use nautical names for most of our services. Within the Fleet Optimization Engineering team, we like to pick sea creature names, relating the name of the creature to the purpose of the new service.
We needed a service that could interpret many different signals and operate intelligently, and gracefully. Dolphins are known for their intelligence as well as their grace—the name was obvious.
The initial design of Dolphin took about a month, and didn’t involve much drama.
We used a form of deliberate design called “event storming.” Event storming helped us form a shared language around the various components of Dolphin. Settling on a shared language upfront allowed us to approach the implementation more systematically and made collaboration easier. The event names that we settled on during planning wound up trickling all the way down into the implementation.

rebalanceCreated := mxRoot.IncCounter(
"rebalance_created",
"increases when dolphin creates a new rebalance",
)
rebalanceCreationFailed := mxRoot.IncCounter(
"rebalance_creation_failed",
"increases when dolphin cannot create a new rebalance",
)
Like most of our internal services, we opted to write Dolphin in Go and deploy it via Kubernetes. We were very thoughtful while designing Dolphin—an automated-Droplet-moving-system-thing had the potential to do a lot of damage very quickly if it failed. With such a huge potential blast radius, safety was paramount.
With this in mind, we had the foresight to design a bunch of safety nets. For example, there is a threshold on the number of Droplets that Dolphin is allowed to move over a certain period of time. Concurrency safety, backoff mechanisms, and a “Big Red Button” have been extremely important for the success of Dolphin.
Our team has always had a culture of reliability, especially since Roman joined us—we like to play with things like supervision trees, chaos testing, and canaries. It felt very natural for us to carry these reliability practices into the implementation of Dolphin. In fact, the initial Dolphin release was in a sort of “read-only” mode, where it would log its intent without executing. This was an extra cautionary step in the interest of safety, but also made iterative development much easier!
It’s rare for an initial release of anything in the software world to happen without issue, but Dolphin was honestly quite painless. We credit the ease of Dolphin’s release to our deliberate planning, thoughtful execution, and our culture of safety and care.
Dolphin 1.0
Remember, our only initial goal was to allow internal teams at DigitalOcean to accomplish anti-affinity for their internal services—making sure their Droplets didn’t wind up on the same server.
For this to work, internal teams needed to manually mark existing Droplets with a “group ID” using an internal tool; if two Droplets shared the same group ID and lived on the same server, Dolphin would notice and move one of them somewhere else.
We named the component responsible for tracking Droplets a “Monitor.” A Monitor is a supervised goroutine that runs a state-machine, receiving inputs from multiple sources (Prometheus, Databases, etc.) and deciding whether any action is necessary. Our first monitor was named the Anti-Affinity Monitor. Here it is on our (virtual) whiteboard:

// antiAffinityDetected holds info for a detected anti-affinity violation
type antiAffinityDetected struct {
Group types.GroupID
HV types.ServerID
Workloads map[types.WorkloadID]struct{}
}
One interesting aspect of our current scheduling model is that Droplets within a region might live on the same server—there is no rule dictating that they can’t, though we try our best to avoid it. Dolphin provides a sort of “safety net,” as it notices when Droplets live on the same server that shouldn’t, and eventually shuffles them around appropriately.
We’ve dubbed this model “Eventual Anti-Affinity,” and it keeps things simple for us internally. Our scheduling system places Droplets on whichever servers it considers to be the best fit for the Droplets’ needs, while Dolphin, always watchful, keeps an eye on things and eventually moves Droplets around when necessary.
The second, more action-oriented component of Dolphin is called the Rebalancer.
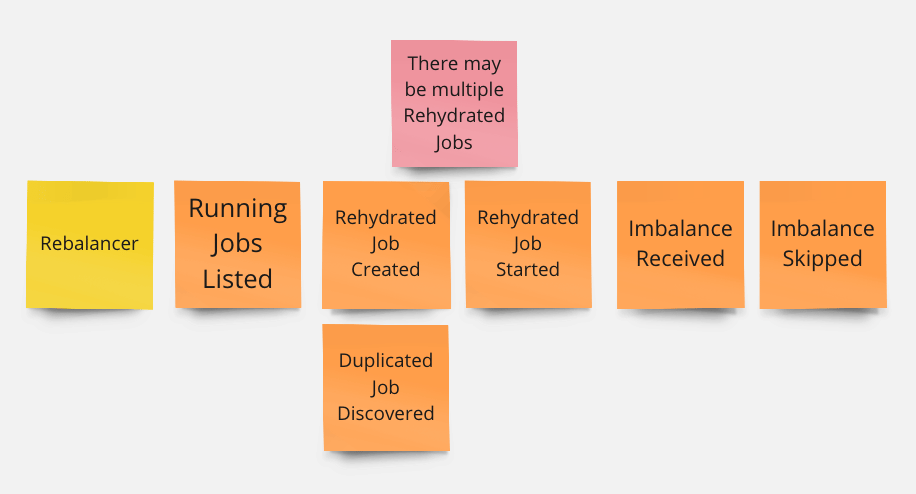
// rebalance represents the execution of a rebalance after an imbalance // is detected.
type rebalance struct {
imbalance types.Imbalance
sourceHV types.ServerID
jobs map[types.JobToken]map[types.WorkloadID]struct{}
completedJobs map[types.JobToken]struct{}
timestamp time.Time
}
The Rebalancer is responsible for moving Droplets around, and was given this name because the live migrations it triggers keep the fleet in a well-balanced state.
So, our Monitor will notice when something needs to change and the Rebalancer can take appropriate action. What about situations where things get a little…cyclical?
Imagine, if you will, a Droplet that is somehow always detected by a Monitor. Dolphin would wind up moving the Droplet between servers endlessly. What if there are tons of these Droplets? We could easily wind up in a situation where we’re just shuffling the same Droplets around forever, wasting valuable resources. Anticipating this possibility, we built a component called the Workload Journey Manager.

This struct reveals the Workload Journey Manager’s responsibilities:
// canMigrateWorkload serves as a query for the workload journey
// manager to assert if a workload may be migrated or not
type canMigrateWorkload struct {
wID types.WorkloadID
respondChan chan bool
}
The Workload Journey Manager does exactly as its name suggests: it manages the journey of a “workload”—also known as a Droplet. We want to keep track of a Droplet’s journey from server to server, so each time Dolphin moves a Droplet to a new home, we add an update to our record of that Droplet’s journey.
Think of the Workload Journey Manager as a travel agent: it makes sure a Droplet’s journey isn’t too difficult, busy, or complicated. To protect a Droplet’s journey, the Workload Journey Manager enforces certain rules that may prevent a Droplet from being migrated for a certain period of time.
Some of these rules are static:
-
A Droplet can’t be moved more than N times per hour
-
If a Droplet is brand new, don’t move it (internally, we refer to new Droplets as “Baby Droplets” 👶💧)
Other rules are more dynamic:
-
If a Droplet has had N failed migrations in X hours, mark it as “unmovable”
-
If a Droplet has moved around a bunch of times in X hours, prevent it from bouncing around too much by marking it as “bouncing”
const (
// Unmovable represents a journey.Filter that filters workloads
// that have failed too many migrations.
Unmovable FilterTag = iota + 1
// Bouncing represents a journey.Filter that filters workloads
// that have migrated successfully too many times over a window of
// time.
Bouncing
// Baby represents a journey.Filter that filters workloads that filters workloads that
// have a small age.
Baby
)
In short, Dolphin consists of a bunch of state machines that constantly watch our fleet of servers, and rebalances Droplets it thinks should be moved.
Dolphin does Ops
After successfully tackling the anti-affinity challenge, we realized that we could extend the “Monitor” mechanism beyond anti-affinity. Maybe, just maybe, we could use a Monitor for other prevalent challenges we face while managing our ever-growing fleet of servers.
One such challenge was a classic operational issue—full disks. At DigitalOcean, we use local server storage for all Droplet root volumes, which means we take some placement bets. Sometimes, we’re wrong, and server storage starts running perilously low—traditionally, our lovely cloud operations folks would remediate this issue by hand, but it made us wonder, “What if Dolphin could remediate this type of operational issue automatically?”
Given Dolphin’s capacity for understanding Prometheus metrics, we took the query typically used to alert our CloudOps team for a full disk and used it as the detection query for a new Dolphin Monitor. This “Full Disk Monitor” helps us detect when a server is close to the disk fill threshold and automatically moves some Droplets away, alleviating the issue without needing CloudOps to manually intervene.
This new capability made Dolphin multi-functional. It went from being an anti-affinity machine to a sort of fleetwide swiss army knife Droplet-moving machine. Our next step was to take that mindset and extend it outwards to benefit external customers.
Dolphin protects customers
If you’ve ever rented an apartment in a building with other tenants, you know how important it is to be a considerate neighbor. There’s inevitably that one upstairs neighbor, though, who thinks they’re the only tenant in the building. They’re loud, they leave their belongings in the hallway, and they’re generally unpleasant to live with. So what do you do? Move.
Sharing resources in the cloud is like living in a rental building with other tenants. You purchase a certain space, but sometimes a neighbor makes it unbearable for you to live there.
While customers purchase products with a given set of resources, we’ve observed that most usage profiles are relatively light. As such, to maximize efficiency, DigitalOcean packs as many Droplets as possible onto our servers, with the understanding that most customers will be unaffected by this sharing of resources. However, certain customers—“busy users”—use as many resources as possible.
Because we overcommit our resources, these busy users can impact other users, causing problems like CPU Steal and High PSI. In the case of CPU Steal, a Droplet uses so much CPU that performance is degraded for all customers on the same server. On the other hand, High PSI occurs when a Droplet uses so much disk I/O that file access performance is degraded for all customers using the same disk.
So what do you do when you have a Droplet that’s unhappy because of a noisy neighbor? Like any savvy renter, Dolphin will notice the Droplet is having a less than optimal experience, and find somewhere better to place it.
Here’s an example of Dolphin automatically rebalancing Droplets that are impacted by High PSI:
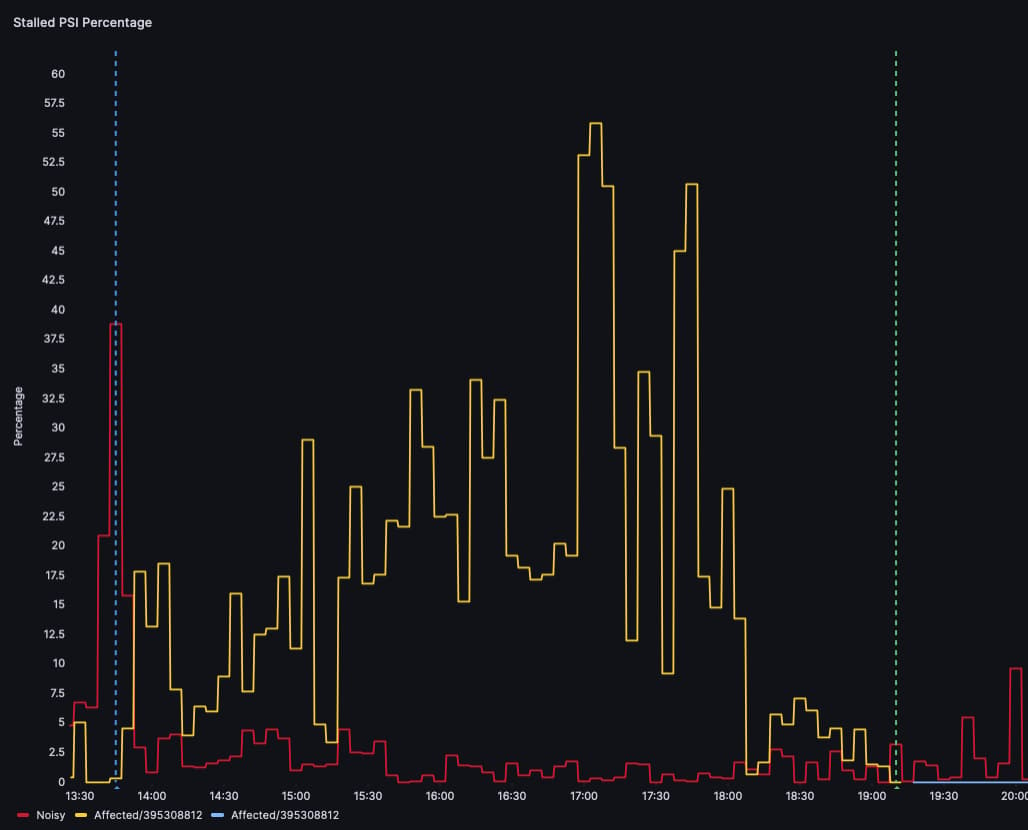
The red Droplet and the yellow Droplet are both noisy neighbors, performing high read/write operations that affect other Droplets using the same underlying disk. The blue dashed line indicates when Dolphin’s rebalance starts and the green dashed line indicates the end of the rebalance. We can see that Droplets previously affected by high PSI are no longer being impacted: the yellow Droplet becomes a light blue Droplet after it starts running on a different server.
In the past, this situation was (and, in some instances, still is) remediated with manual intervention from our CloudOps team as a reactive measure. As a proactive system, Dolphin dynamically protects customers from experiencing poor performance, moving Droplets when they’re impacted by the activities of other customers. Sometimes it’s necessary to break your lease!
Future state
We tried to wrap up this blog post with a vision for the future of Dolphin. What’s next? How can we make Dolphin solve the world’s problems? Can it bake cookies? Can it solve the 2008 financial crisis? Honestly, we’re still figuring that out. The beauty and success of Dolphin has been our ability to continuously iterate as we build upon the system’s foundations.
We’re excited to figure out what’s next for Dolphin, and we hope you’ll feel the impact of our hard work!
Thanks! 🐬
None of this work would be possible without the constant support of Roman Gonzalez, Lucy Berman, James Brennan, Geoff Hickey, Mike Pontillo, and the Fleet Optimization Engineering Team. We also want to shout out Julien Desfossez and Vishal Verma from the Performance Team for providing us with the statistics and numbers that helped make Dolphin a reality. We are also grateful for the contributions of Michael Bullock and Billie Cleek on the anti-affinity work.
We’d also like to thank Becca Robb and Roman Gonzalez for running the Fleet Optimization Engineering Team’s Book Club, where we have read and discussed books that have taught us how to make reliable systems and work with domain-driven software design.
Finally, thanks to Jes Olson and the marketing team for working with us on this blog post and helping us share Dolphin’s story!
Ready to bring a new workload to DigitalOcean? Enjoy three months of the new workload cost on us. Yes, it’s that easy. Contact Sales at DigitalOcean today for more details and next steps.
About the author(s)
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read
