How a Kubernetes high availability control plane maximizes uptime and fortifies reliability
By Abhimanyu Selvan
- Published:
- 4 min read
A high availability (HA) Kubernetes control plane is crucial for maintaining the efficient operation and reliability of applications and services. The control plane is the brain of a Kubernetes cluster; without it, your distributed system can degrade or break. Savvy organizations fortify the uptime and performance of their customers with a highly available control plane. A control plane failure will prevent you from administering your cluster and could stop existing workloads from reacting to new events, data loss, and cluster failure. First, we’ll briefly cover what HA is for DigitalOcean Kubernetes, then answer your questions on what happens when your control plane fails and why it’s vital for production and business-critical apps.
DOKS high availability control plane
DigitalOcean Kubernetes (DOKS) offers a High Availability (HA) option for its control plane; it’s designed to be durable with a 99.95% Service Level Agreement (SLA).
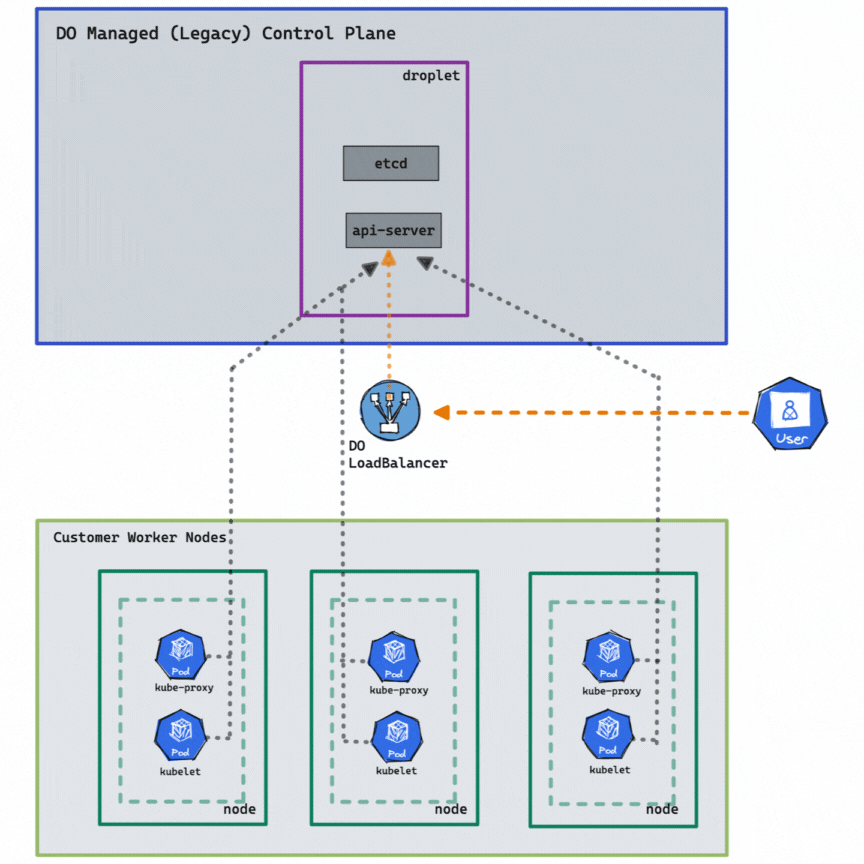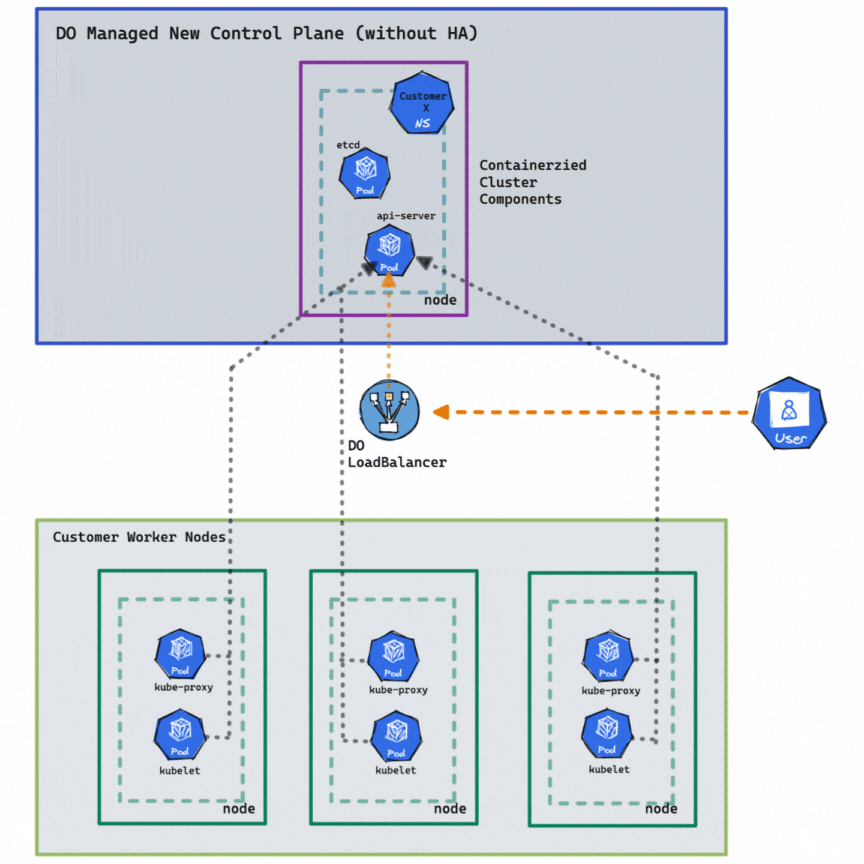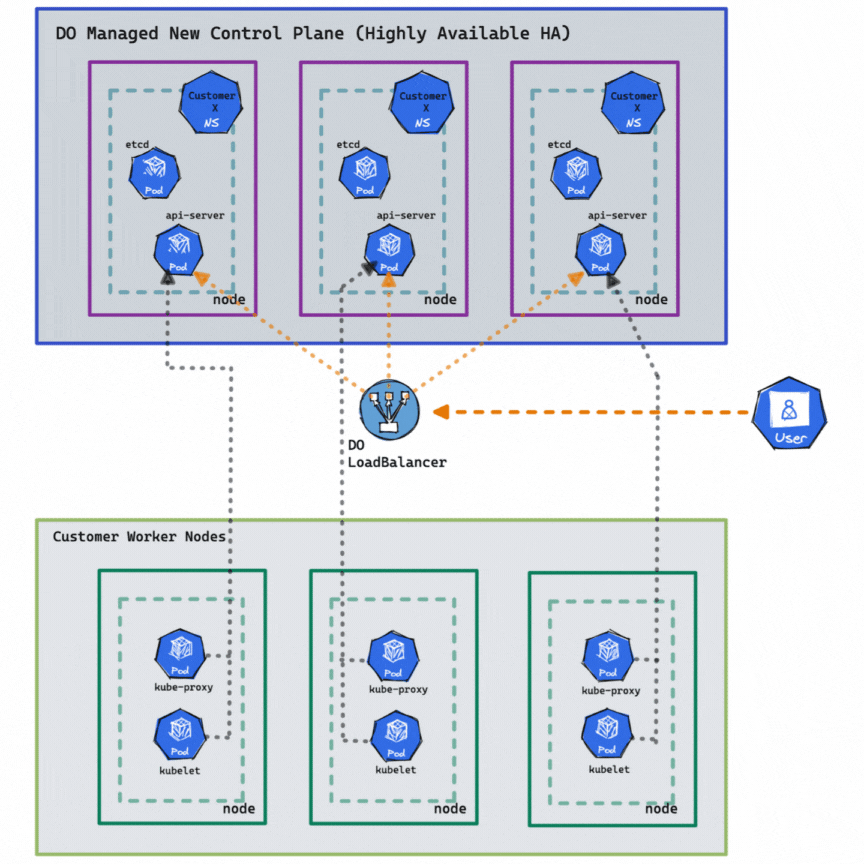
The HA control plane allows faster cluster creation and recovery because it is containerized, leveraging the latest cloud-native and open-source technologies. It automatically detects and replaces unhealthy components and dynamically allocates CPU and memory resources on demand. In addition, the improved DOKS HA control plane allows for faster feature updates and bug fixes, making it easier to maintain and roll back. The above diagram depicts the new and improved DOKS HA control plane. You can enable HA on a cluster for only $40 monthly with a click, the CLI, or the API. Once HA is enabled on a cluster, it can’t be disabled.
What happens when your Kubernetes control plane fails?
To examine why HA is so important, let’s look at what happens when a control plane fails—take the example of a gaming app running on Kubernetes. In this scenario, the control plane of the Kubernetes cluster is responsible for managing and orchestrating the various components of the game application, such as the game servers, databases, and load balancers. If a control plane fails, it can lead to the game becoming unavailable or unstable. As a result, players may experience server crashes, long load times, or even complete game outages. This can result in unhappy users and potentially lost revenue for the gaming company.
Let’s take a few components in your control plane and follow what happens if they fail. When the API server fails, it prevents your cluster from receiving new API requests, making it impossible to perform new deployments, updates, and scaling operations until the issue is resolved. The etcd is a key-value store that Kubernetes uses to store configuration data, state information, and metadata for all cluster resources. If the etcd fails, the cluster will no longer be able to access this data, resulting in a wide range of issues such as loss of control plane functionality, inability to deploy new workloads, and potential data loss. If the scheduler fails, new pods won’t be allocated to nodes, making your services inaccessible. Lastly, when the controller manager fails, changes applied to the cluster won’t be picked up, so your workloads will appear to retain their previous state.
What happens to your worker nodes during a control plane failure?
The control plane and workers are independent, so a control plane failure won’t knock out workloads already in a healthy state. Fortunately, nodes are among the least often changing objects; once they are provisioned, they need minor modifications. You can access existing services even when you can’t connect to your API server. Users won’t notice a short-term control plane outage. However, more extended periods of downtime increase the probability that worker nodes will also face issues.
For example, extended periods of downtime will prevent the user from changing their existing functioning workloads. If a worker node has problems while the control plane is down, it’ll be impossible to reschedule the pods to another node. This event will cause your workload to drop offline. At this point, a control plane failure can impact your customers.
Enable HA for critical workloads and environments
Enabling High Availability (HA) in DigitalOcean Kubernetes is recommended for workloads and environments requiring optimal availability and resilience. This includes mission-critical apps and websites, and services requiring continuous operation with minimal downtime. HA Kubernetes cluster ensures a resilient infrastructure that can withstand control plane outages better—resulting in improved performance and uptime for users, making it an essential feature for businesses that require continuous operation of their apps and services.
Scaling and growing your business
As workloads grow, a resilient infrastructure becomes increasingly important. A minor failure can have cascading effects at scale, leaving you at risk.
Improve uptime and performance
Enabling High Availability in the Kubernetes control plane can mitigate the impact of a control plane failure. It improves performance and reliability for users while reducing the risk of outages.
Meet customer expectations
When the stakes are high and customers demand near-perfect uptime, a highly available control plane helps organizations meet their obligations.
To enjoy the benefits of a highly available control plane, you can easily add it to your DigitalOcean Kubernetes cluster at the push of a button. In addition, you can enable HA DOKS with CLI, API, or UI. Contact us if you would like expert help with DigitalOcean Kubernetes to modernize your infrastructure.
Further Reading
About the author
Related Articles

Introducing langchain-gradient: Seamless LangChain Integration with DigitalOcean Gradient™ AI Platform
Narasimha Badrinath
- August 19, 2025
- 2 min read

Agentic Cloud: Reinventing the Cloud with AI Agents
Bratin Saha, Chief Product & Technology Officer
- May 19, 2025
- 5 min read

How to optimize your cloud architecture for business growth
- May 9, 2025
- 5 min read